Best AI tools for< Cdo >
Infographic
1 - AI tool Sites
TextMine
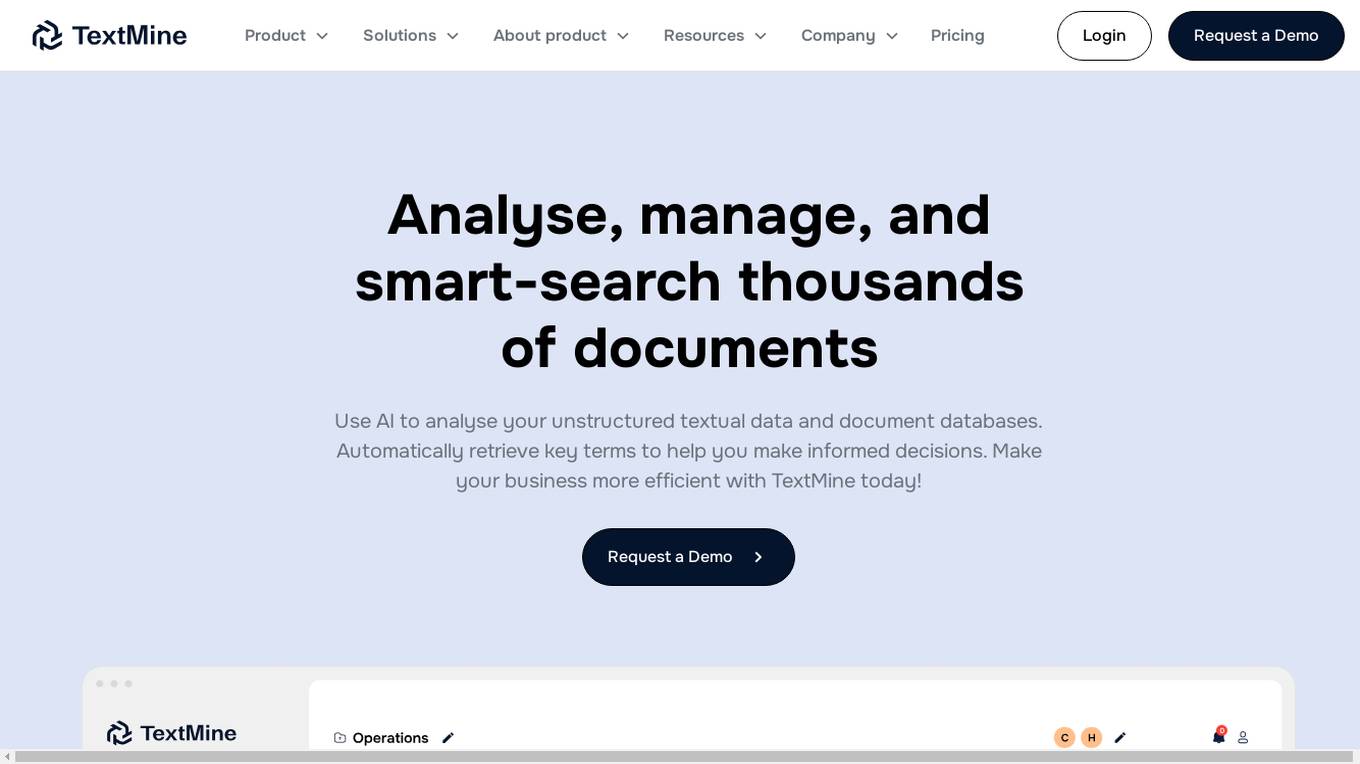
TextMine is an AI-powered knowledge base designed for businesses to manage and analyze critical documents efficiently. It offers features such as document analysis, smart-search capabilities, automated data extraction, and structured dataset transformation. TextMine helps businesses save time and money by streamlining document management processes and enabling informed decision-making. The application caters to various industries like Technology, Legal Services, and Financial Services, providing solutions for teams in Procurement, Finance, Compliance, CIOs, and CDOs.
site
: 0
0 - Open Source Tools
No tools available