Best AI tools for< Audio Broadcaster >
Infographic
20 - AI tool Sites
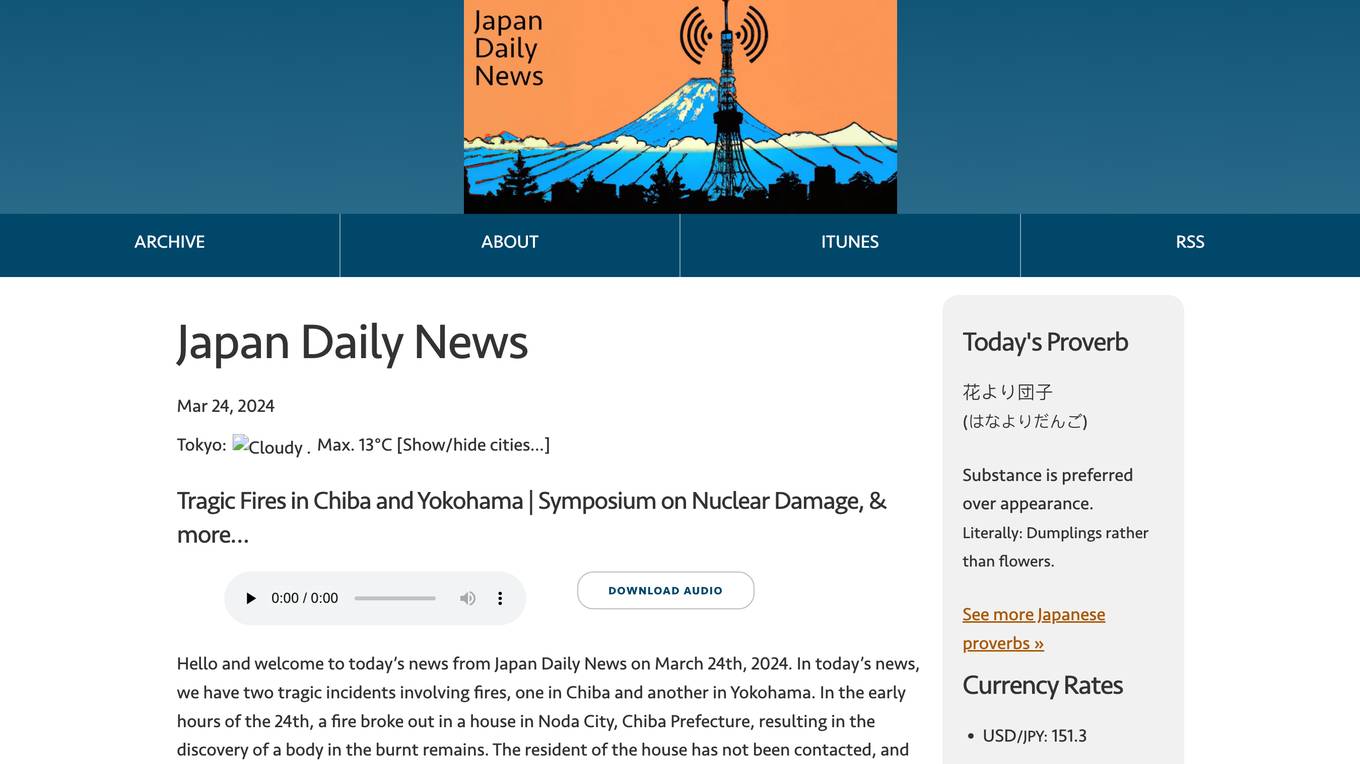
Japan Daily News
Japan Daily News is a comprehensive online platform providing daily news updates from Japan. Covering a wide range of topics including current events, legal news, public health initiatives, and weather forecasts, the website aims to keep readers informed about the latest developments in Japan. With a focus on delivering accurate and timely information, Japan Daily News serves as a valuable resource for individuals interested in staying up-to-date with news from Japan.
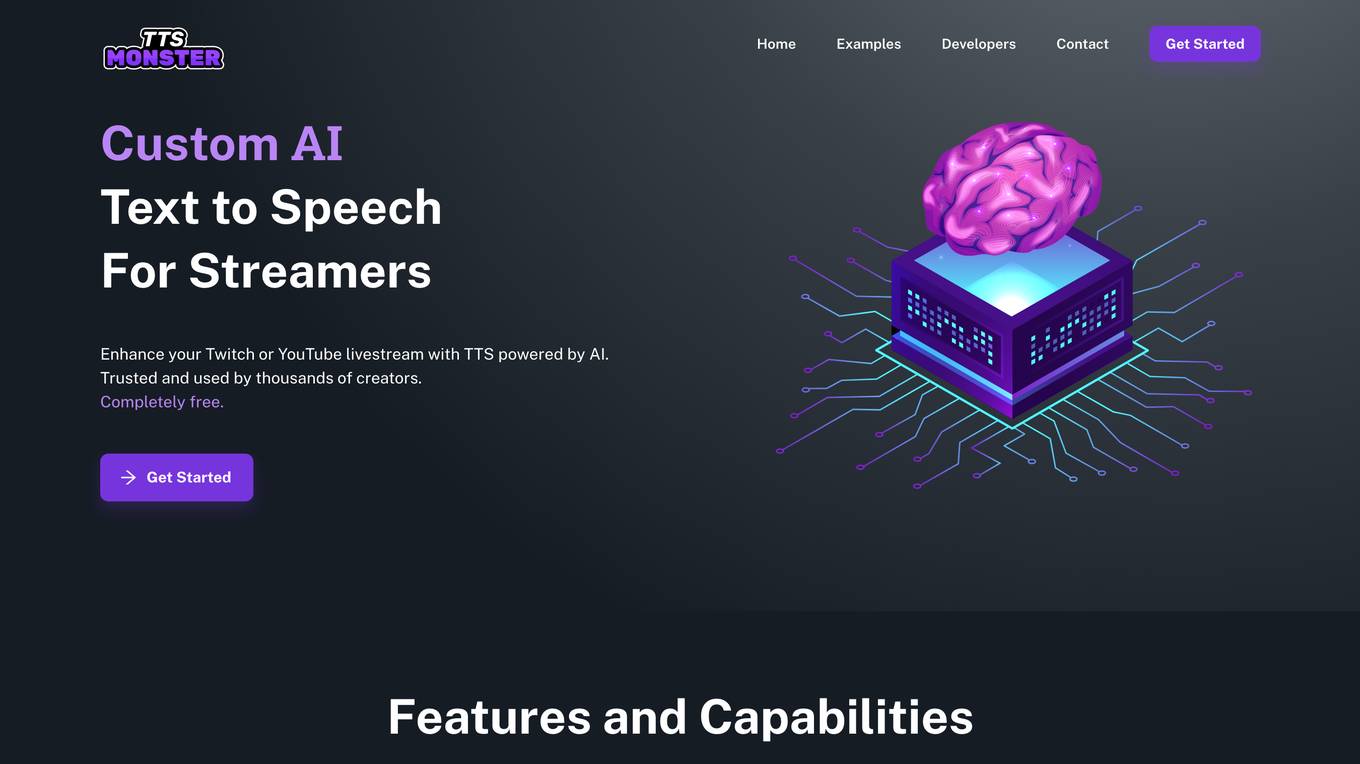
TTS.Monster
TTS.Monster is an AI text-to-speech tool designed specifically for Twitch users. It utilizes advanced AI technology to convert text into natural-sounding speech, enhancing the streaming experience for content creators and viewers alike. With TTS.Monster, users can easily generate high-quality voiceovers for their Twitch streams, chat interactions, and more. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to individual preferences. Whether for entertainment or accessibility purposes, TTS.Monster provides a seamless and engaging audio solution for Twitch broadcasters.
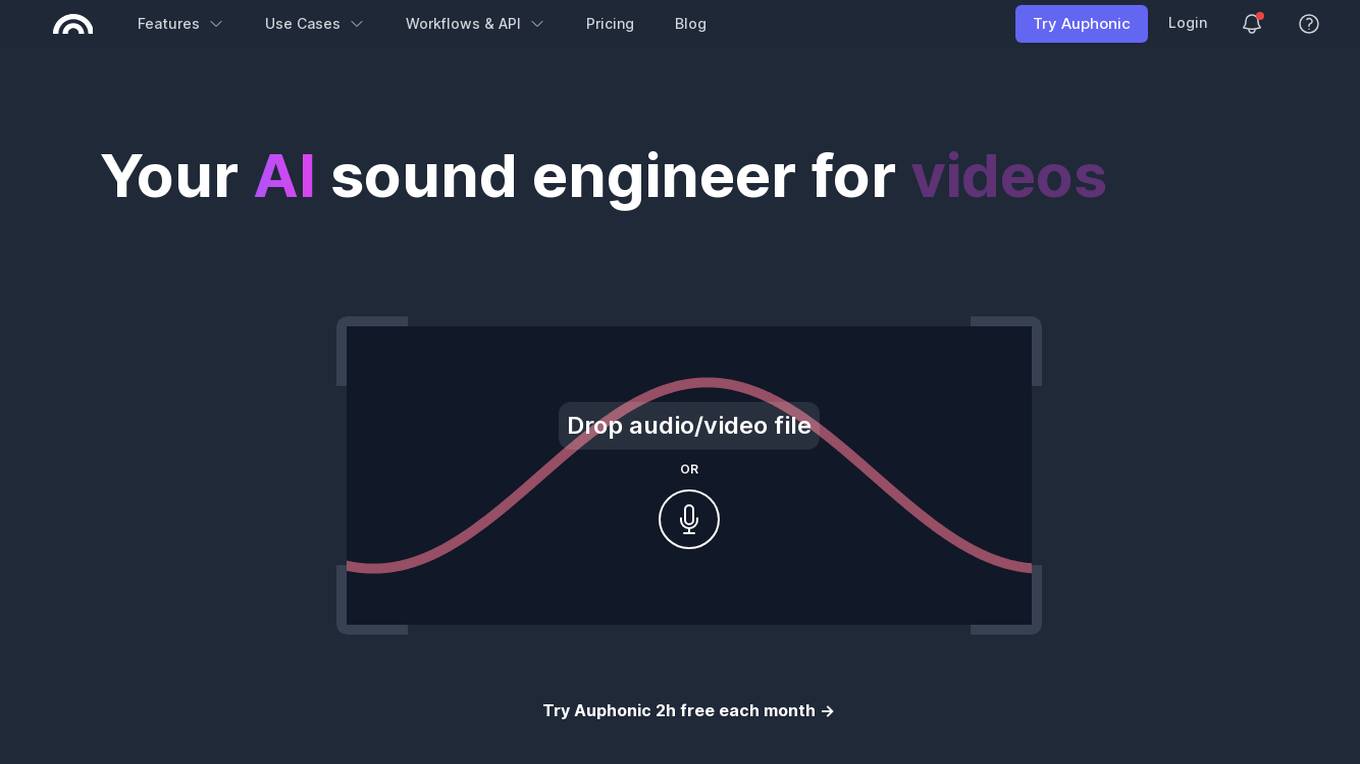
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.
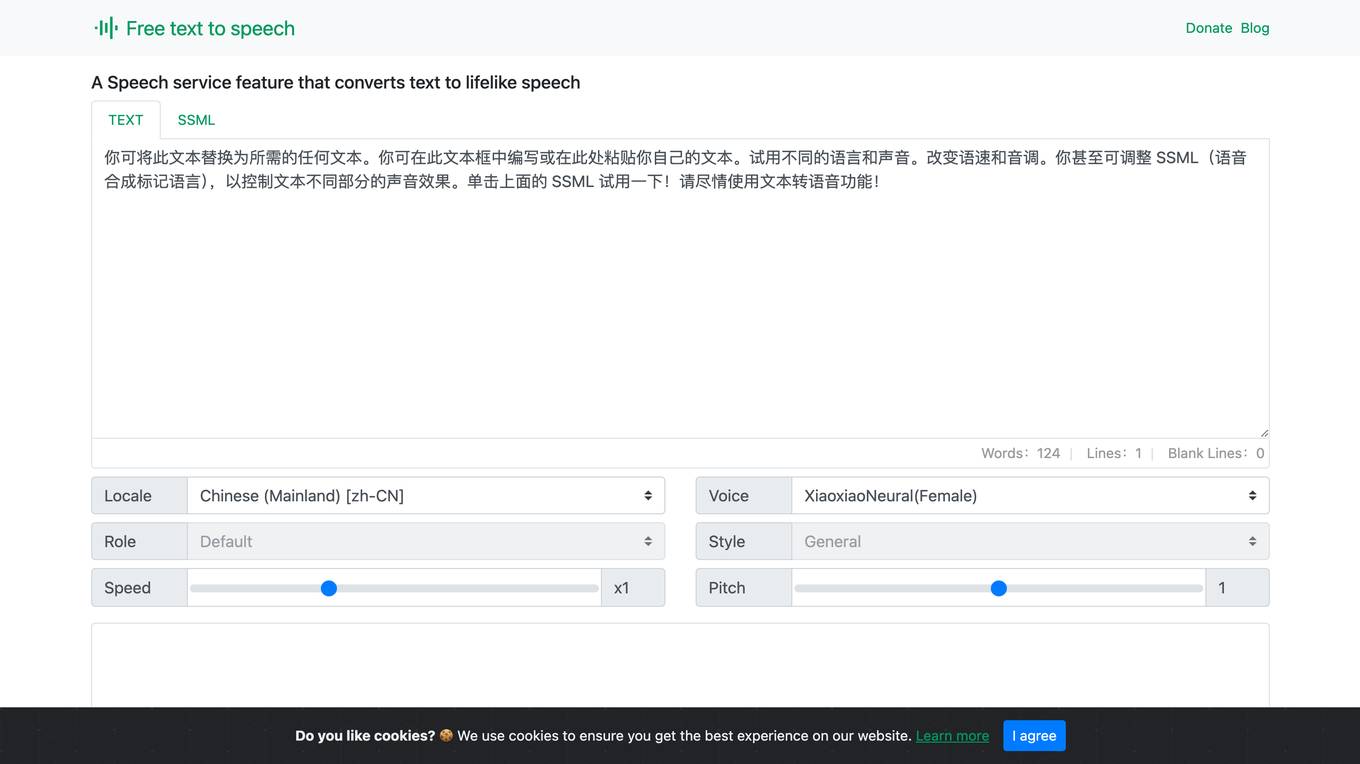
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Vatis Tech
Vatis Tech is an AI-powered speech-to-text infrastructure that offers transcription software to help teams and individuals streamline their workflow. The platform provides accurate, accessible, and affordable speech-to-text API, caption generator, and audio intelligence solutions. It caters to various industries such as contact centers, broadcasting, medical, legal, media, newsrooms, and more. Vatis Tech's technology is powered by state-of-the-art AI, enabling near-human accuracy in transcribing speech with fast turnaround times. The platform also offers features like real-time transcription, custom AI models, and support for multiple languages.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
EdMon.AI
EdMon.AI is an AI-powered application that specializes in audio and video transcription. It consists of two main components - EdMon Producer, a content viewing and video editing tool for post-production teams, and EdMon Transcriber, an AI-powered transcription tool for media managers. The application is designed to revolutionize efficiency in collaborative content creation by managing and utilizing large volumes of video content. Developed by a team with extensive experience in the broadcast and post-production industry, EdMon.AI offers seamless integration with industry-standard software like Avid Media Composer and Adobe Premiere Pro.
Audio Enhancer
Audio Enhancer is an AI-powered tool that helps users enhance the quality of their audio files by removing background noise, improving clarity, and adjusting levels. It is designed to be easy to use, with a simple drag-and-drop interface and a variety of presets to choose from. Audio Enhancer is suitable for a wide range of audio applications, including podcasts, videos, music, and more.
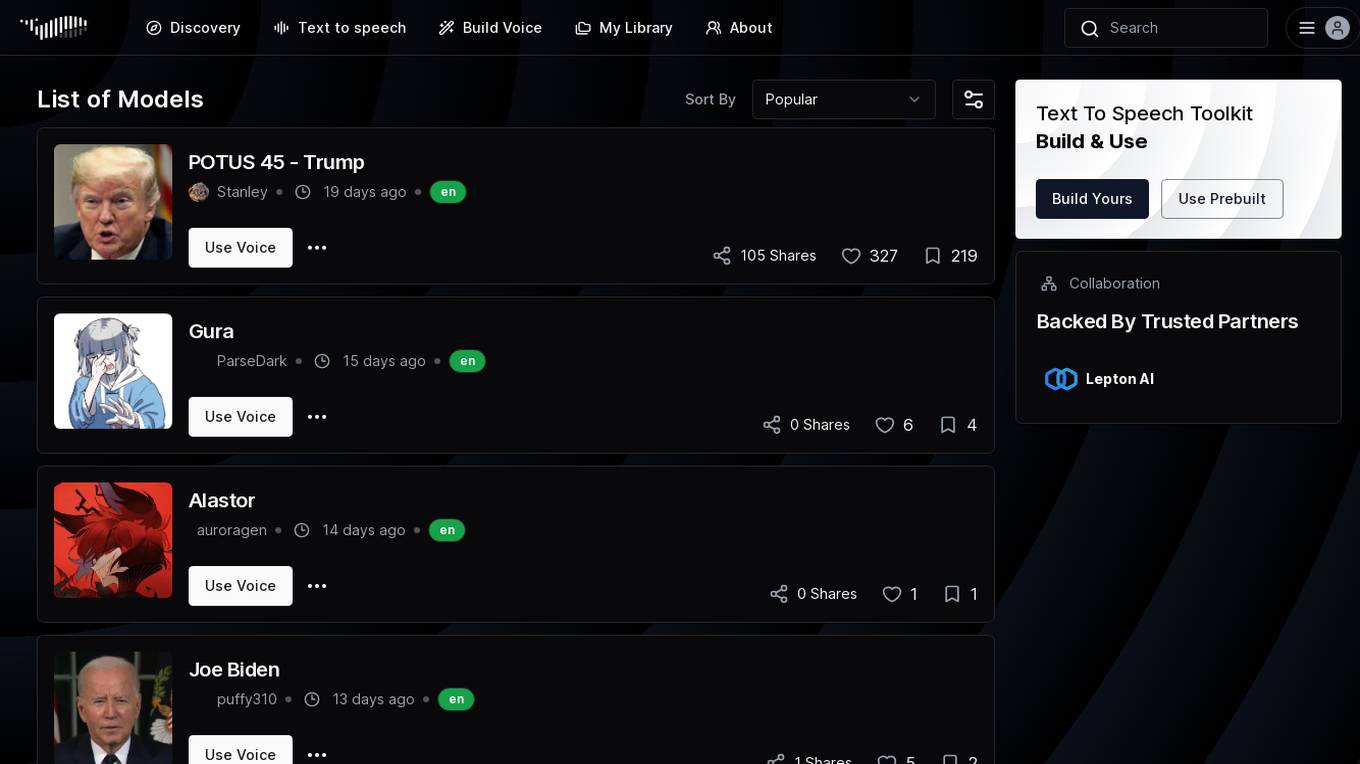
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.

TRINITY Audio
TRINITY Audio is an AI tool designed for serving audio content. It specializes in providing audio solutions for various purposes. The platform offers advanced features to enhance the audio experience for users across different domains. TRINITY Audio is a reliable and efficient tool for managing and delivering audio content seamlessly.
Audio Writer
Audio Writer is a voice-to-text transcription app that uses AI to refine and rewrite transcripts. It can also be used for journaling, content creation, and more. The app is available for iOS and macOS, and it offers a one-time payment option with no subscription required.
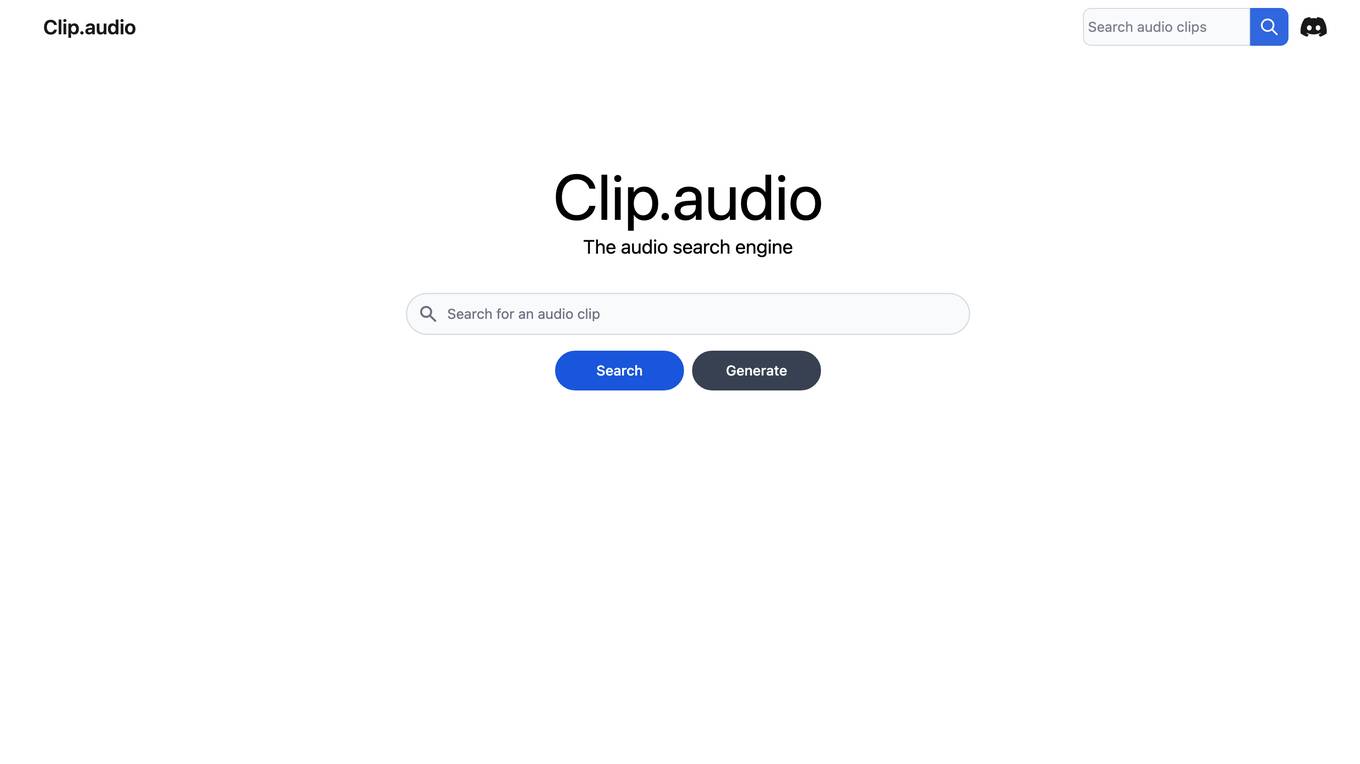
Clip.audio
Clip.audio is an AI-powered audio search engine that allows users to search for and discover audio clips from a variety of sources, including podcasts, music, and sound effects. The platform uses advanced machine learning algorithms to analyze and index audio content, making it easy for users to find the specific audio clips they are looking for.
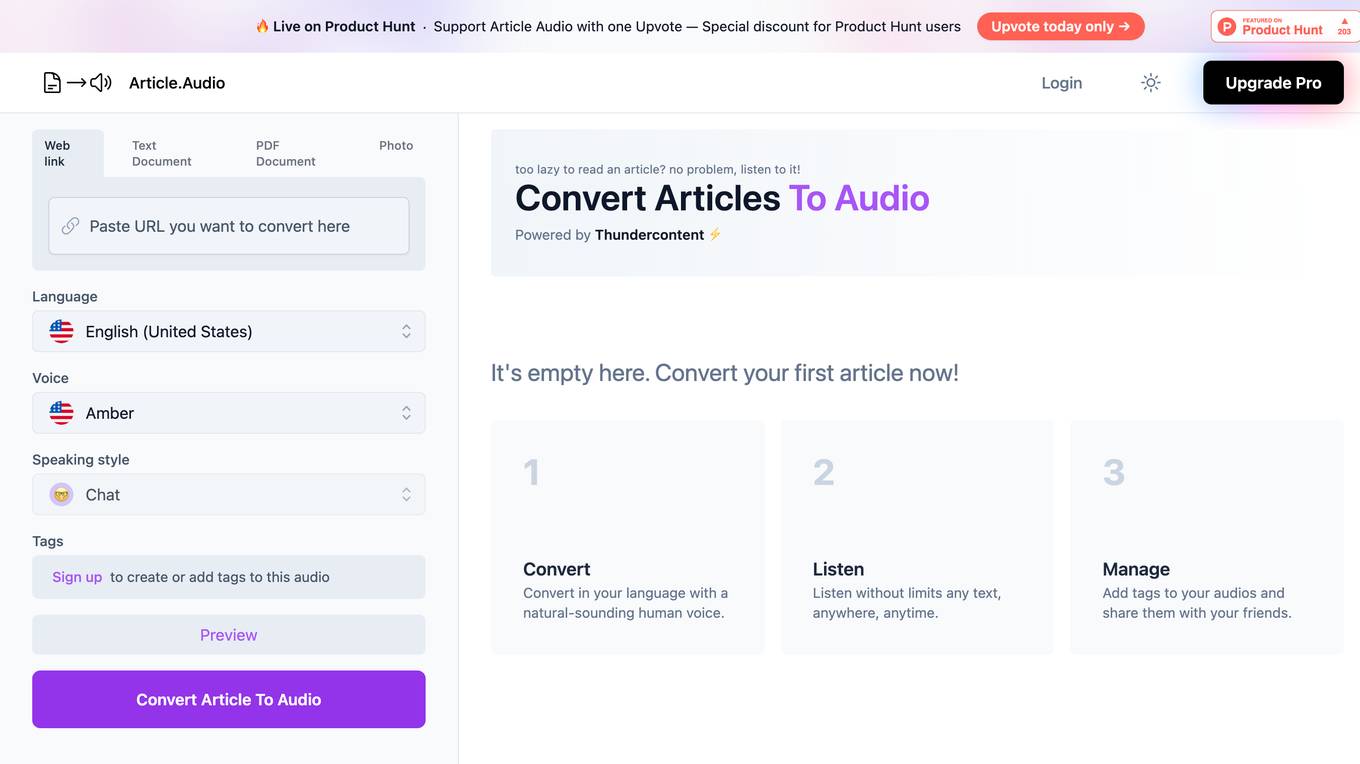
Article.Audio
Article.Audio is a web application that allows users to convert written articles into audio format, enabling them to listen to the content instead of reading it. Users can easily convert text documents, PDFs, and web links into audio files using natural-sounding human voices. The application is powered by Thundercontent and offers features such as multilingual voice options, tag creation for audio files, and seamless integration with Google and email accounts.
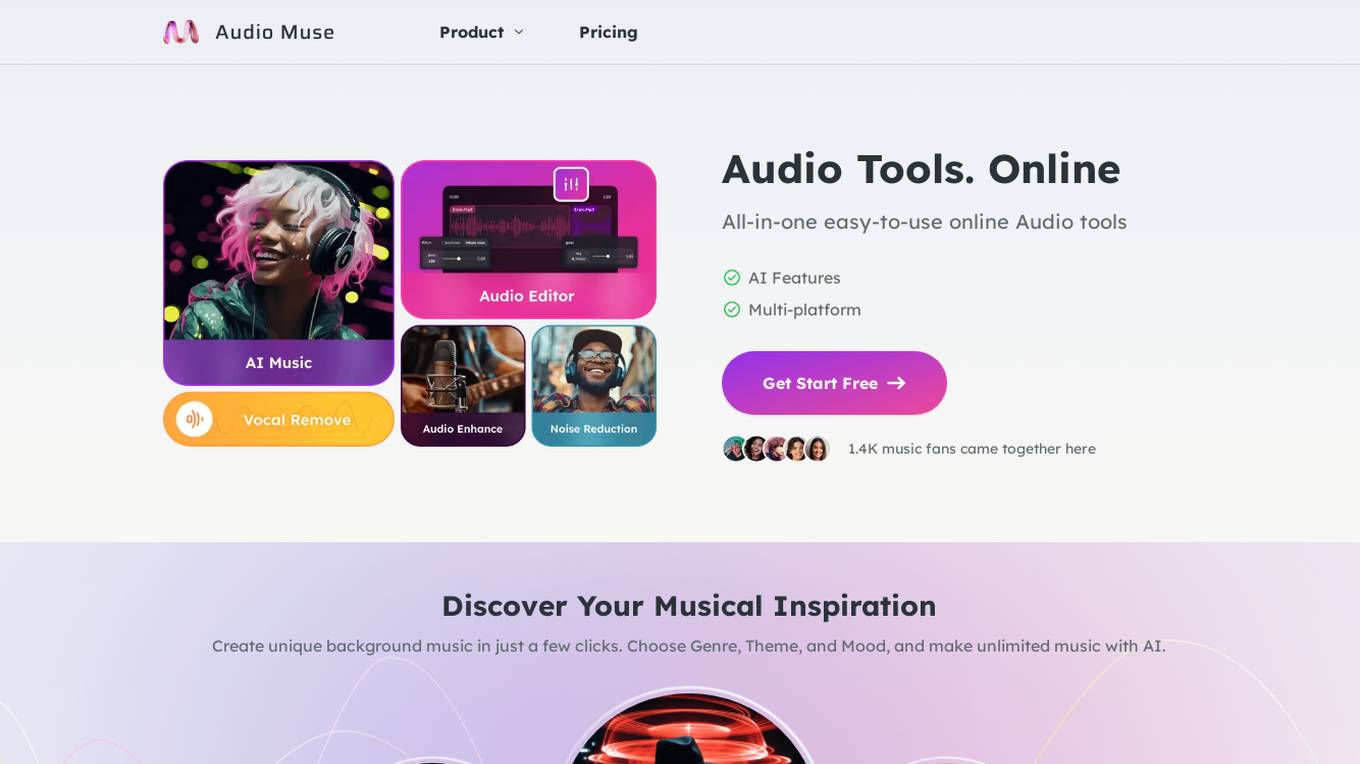
Audio Muse
Audio Muse is an all-in-one online audio tool that leverages AI features to help users create unique background music effortlessly. With a wide range of genres, themes, and moods to choose from, users can generate unlimited tracks with just a few clicks. The platform caters to music fans and creators alike, offering a full suite of audio processing tools in a user-friendly interface. Whether you're looking to compose epic, happy, acoustic, romantic, or hip hop music, Audio Muse provides everything you need in one convenient place.
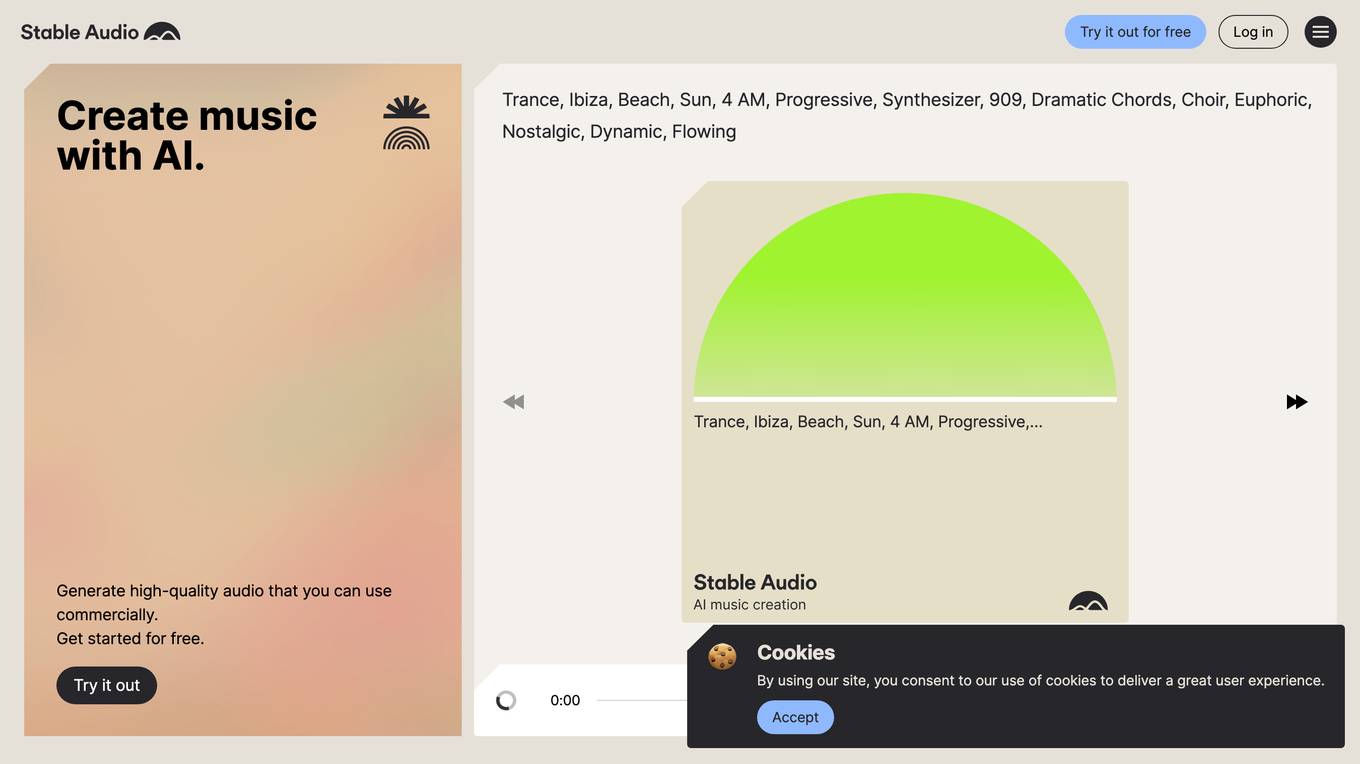
Stable Audio
Stable Audio is a generative AI tool that allows users to create high-quality music and sound effects. It is powered by the latest audio diffusion models and offers a range of features that make it easy to create custom music. With Stable Audio, users can generate music of any length, style, or genre, and they can even use their own voice or instruments to create unique tracks. The generated audio can be downloaded in 44.1 kHz stereo and used in commercial projects.
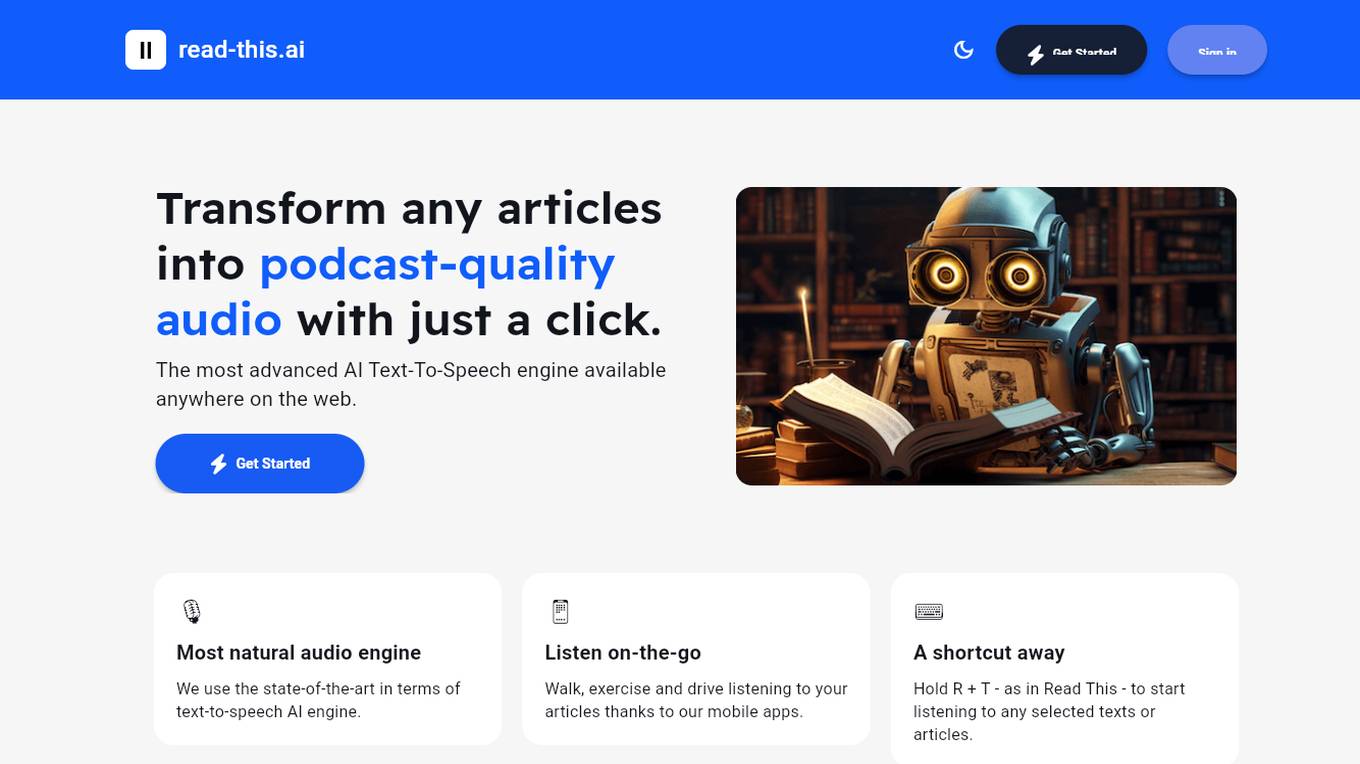
Article to Audio Converter
This AI-powered tool allows you to effortlessly convert written articles into engaging, podcast-quality audio. With just a click, you can transform your content into captivating audio experiences, making it accessible to a wider audience and enhancing its impact.
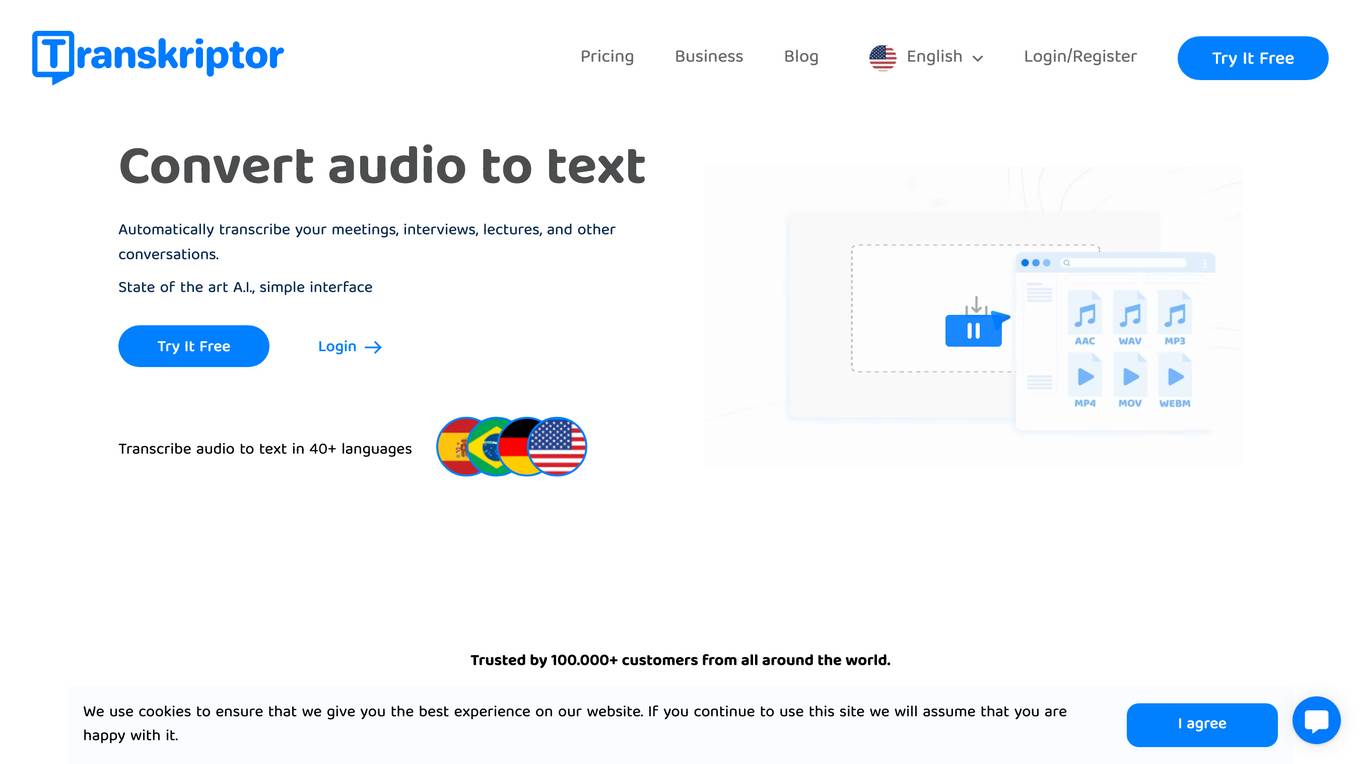
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
Audacity
Audacity is a free and open-source audio editing and recording software that runs on Windows, macOS, GNU/Linux, and other operating systems. It is popular for its ease of use, multi-track editing capabilities, and support for a wide range of audio formats. Audacity can be used for a variety of tasks, including recording and editing podcasts, music, and other audio content. It also supports a variety of plugins, which can extend its functionality even further.
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.
20 - Open Source Tools
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.
kazam
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing, and optical character recognition (OCR). It allows users to capture screen content, broadcast live over the internet, extract text from captured content, record audio, and use a web camera for recording. The tool supports full screen, window, and area modes, and offers features like keyboard shortcuts, live broadcasting with Twitch and YouTube, and tips for recording quality. Users can install Kazam on Ubuntu and use it for various recording and broadcasting needs.
bmf
BMF (Babit Multimedia Framework) is a cross-platform, multi-language, customizable multimedia processing framework developed by ByteDance. It offers native compatibility with Linux, Windows, and macOS, Python, Go, and C++ APIs, and high performance with strong GPU acceleration. BMF allows developers to enhance its features independently and provides efficient data conversion across popular frameworks and hardware devices. BMFLite is a client-side lightweight framework used in apps like Douyin/Xigua, serving over one billion users daily. BMF is widely used in video streaming, live transcoding, cloud editing, and mobile pre/post processing scenarios.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.
Synthalingua
Synthalingua is an advanced, self-hosted tool that leverages artificial intelligence to translate audio from various languages into English in near real time. It offers multilingual outputs and utilizes GPU and CPU resources for optimized performance. Although currently in beta, it is actively developed with regular updates to enhance capabilities. The tool is not intended for professional use but for fun, language learning, and enjoying content at a reasonable pace. Users must ensure speakers speak clearly for accurate translations. It is not a replacement for human translators and users assume their own risk and liability when using the tool.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.
ChopperBot
A multifunctional, intelligent, personalized, scalable, easy to build, and fully automated multi platform intelligent live video editing and publishing robot. ChopperBot is a comprehensive AI tool that automatically analyzes and slices the most interesting clips from popular live streaming platforms, generates and publishes content, and manages accounts. It supports plugin DIY development and hot swapping functionality, making it easy to customize and expand. With ChopperBot, users can quickly build their own live video editing platform without the need to install any software, thanks to its visual management interface.
audio-webui
Audio Webui is a tool designed to provide a user-friendly interface for audio processing tasks. It supports automatic installers, Docker deployment, local manual installation, Google Colab integration, and common command line flags. Users can easily download, install, update, and run the tool for various audio-related tasks. The tool requires Python 3.10, Git, and ffmpeg for certain features. It also offers extensions for additional functionalities.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
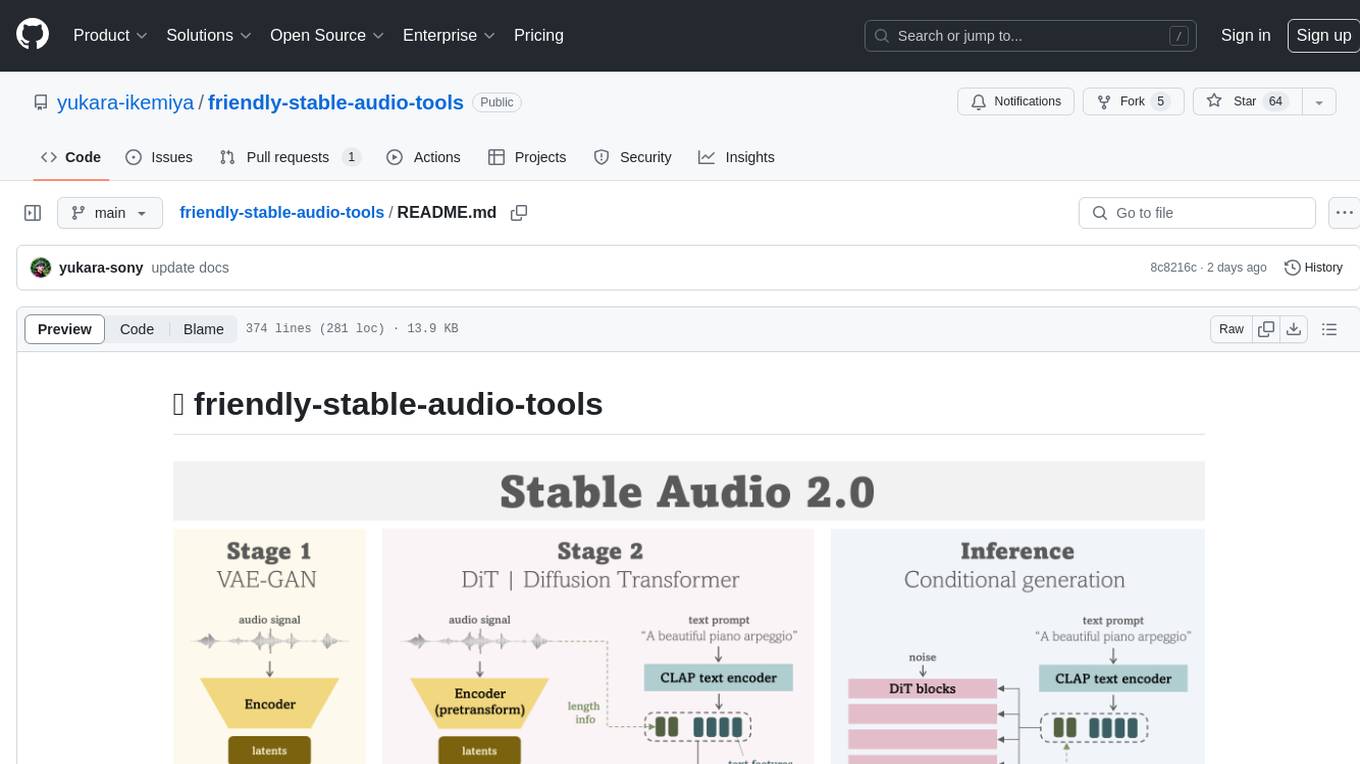
friendly-stable-audio-tools
This repository is a refactored and updated version of `stable-audio-tools`, an open-source code for audio/music generative models originally by Stability AI. It contains refactored codes for improved readability and usability, useful scripts for evaluating and playing with trained models, and instructions on how to train models such as `Stable Audio 2.0`. The repository does not contain any pretrained checkpoints. Requirements include PyTorch 2.0 or later for Flash Attention support and Python 3.8.10 or later for development. The repository provides guidance on installing, building a training environment using Docker or Singularity, logging with Weights & Biases, training configurations, and stages for VAE-GAN and Diffusion Transformer (DiT) training.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.
Audio-Upscaler
Audio Upscaler (AudioSR) is a powerful tool designed to enhance the fidelity of audio files, regardless of type or sampling rates. It leverages cutting-edge super-resolution techniques to upscale audio signals, resulting in superior quality output. The tool is versatile, handling all types of audio content, easy to use with a simple interface, and ensures high fidelity output with enhanced clarity and detail.
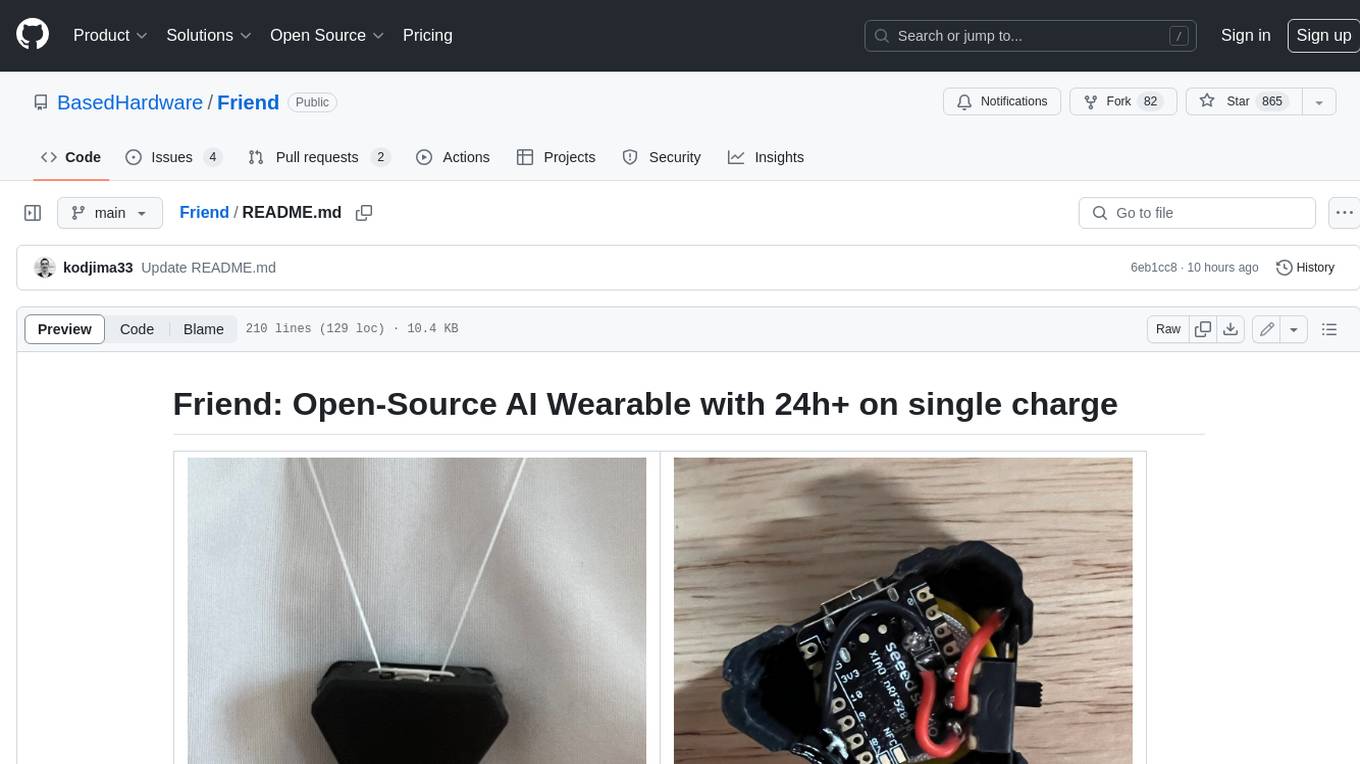
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
20 - OpenAI Gpts
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.

Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.