New AI tools - Open Source
Website-Crawler
Website-Crawler is a tool designed to extract data from websites in an automated manner. It allows users to scrape information such as text, images, links, and more from web pages. The tool provides functionalities to navigate through websites, handle different types of content, and store extracted data for further analysis. Website-Crawler is useful for tasks like web scraping, data collection, content aggregation, and competitive analysis. It can be customized to extract specific data elements based on user requirements, making it a versatile tool for various web data extraction needs.
mdream
Mdream is a lightweight and user-friendly markdown editor designed for developers and writers. It provides a simple and intuitive interface for creating and editing markdown files with real-time preview. The tool offers syntax highlighting, markdown formatting options, and the ability to export files in various formats. Mdream aims to streamline the writing process and enhance productivity for individuals working with markdown documents.

SpecForge
SpecForge is a powerful tool for generating API specifications from code. It helps developers to easily create and maintain accurate API documentation by extracting information directly from the codebase. With SpecForge, users can streamline the process of documenting APIs, ensuring consistency and reducing manual effort. The tool supports various programming languages and frameworks, making it versatile and adaptable to different development environments. By automating the generation of API specifications, SpecForge enhances collaboration between developers and stakeholders, improving overall project efficiency and quality.
pentest-agent
Pentest Agent is a lightweight and versatile tool designed for conducting penetration testing on network systems. It provides a user-friendly interface for scanning, identifying vulnerabilities, and generating detailed reports. The tool is highly customizable, allowing users to define specific targets and parameters for testing. Pentest Agent is suitable for security professionals and ethical hackers looking to assess the security posture of their systems and networks.
falkordb-browser
FalkorDB Browser is a user-friendly web application for browsing and managing databases. It provides an intuitive interface for users to interact with their databases, allowing them to view, edit, and query data easily. With FalkorDB Browser, users can perform various database operations without the need for complex commands or scripts, making database management more accessible and efficient.
mcp-server-chart
mcp-server-chart is a Helm chart for deploying a Minecraft server on Kubernetes. It simplifies the process of setting up and managing a Minecraft server in a Kubernetes environment. The chart includes configurations for specifying server settings, resource limits, and persistent storage options. With mcp-server-chart, users can easily deploy and scale Minecraft servers on Kubernetes clusters, ensuring high availability and performance for multiplayer gaming experiences.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.
verifiers
Verifiers is a tool designed to verify the correctness of data and information. It provides a set of functions to validate and check the accuracy of various types of data, such as text, numbers, dates, and more. With Verifiers, users can easily ensure the quality and integrity of their data by performing checks and validations according to predefined rules and criteria. The tool is versatile and can be used in a wide range of applications, including data processing, quality control, error detection, and data analysis. Verifiers simplifies the process of data verification and helps users identify and correct errors and inconsistencies in their datasets, leading to improved data quality and reliability.
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.
exllamav3
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.
golitex
Litex is a simple, intuitive, and open-source formal language for coding reasoning. It ensures correctness in every step of reasoning and can be learned by anyone in 1–2 hours, even without a math or programming background. Litex scales formal reasoning by making it accessible to more people, applicable to complex problems, and usable by large-scale AI systems. It aims to lower the entrance barrier and reduce the cost of constructing formalized proofs, making formal reasoning as natural as writing.
binglish
binglish is a desktop English learning tool that automatically changes the Bing daily wallpaper while helping users learn new words through AI-generated images, example sentences, and translations. Users can enjoy beautiful scenery, acquire knowledge, and build vocabulary towers. The tool excludes bad words and offers words ranging from CET-4 to GRE difficulty levels. It refreshes every 3 hours and is designed for Windows 10 and above with a resolution of 1920x1080. The AI-generated content may not be completely accurate.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
bigtop-manager
Apache Bigtop Manager is a modern, AI-driven web application designed to simplify the complexity of bigdata cluster management. It provides an easy deployment solution not only for Apache Bigtop components, but also other community version bigdata components. The platform aims to streamline the management of bigdata clusters by leveraging AI technology and user-friendly interfaces.
gitmesh
GitMesh is an AI-powered Git collaboration network designed to address contributor dropout in open source projects. It offers real-time branch-level insights, intelligent contributor-task matching, and automated workflows. The platform transforms complex codebases into clear contribution journeys, fostering engagement through gamified rewards and integration with open source support programs. GitMesh's mascot, Meshy/Mesh Wolf, symbolizes agility, resilience, and teamwork, reflecting the platform's ethos of efficiency and power through collaboration.
nsfw_ai_model_server
This project is dedicated to creating and running AI models that can automatically select appropriate tags for images and videos, providing invaluable information to help manage content and find content without manual effort. The AI models deliver highly accurate time-based tags, enhance searchability, improve content management, and offer future content recommendations. The project offers a free open source AI model supporting 10 tags and several paid Patreon models with 151 tags and additional variations for different tradeoffs between accuracy and speed. The project has limitations related to usage restrictions, hardware requirements, performance on CPU, complexity, and model access.
innoshop
InnoShop is an innovative open-source e-commerce system based on Laravel 12. It supports multiple languages, multiple currencies, and is integrated with OpenAI. The system features plugin mechanisms and theme template development for enhanced user experience and system extensibility. It is globally oriented, user-friendly, and based on the latest technology with deep AI integration.
fastapi-langgraph-agent-production-ready-template
A production-ready FastAPI template for building AI agent applications with LangGraph integration. This template provides a robust foundation for building scalable, secure, and maintainable AI agent services. It includes features like FastAPI for high-performance async API endpoints, LangGraph integration, structured logging, rate limiting, PostgreSQL for data persistence, Docker support, security measures like JWT-based authentication and input sanitization, developer-friendly features like environment-specific configuration and type hints, a model evaluation framework with automated metric-based evaluation and detailed JSON reports, and a configuration system with environment-specific settings.
Awesome-Trustworthy-Embodied-AI
The Awesome Trustworthy Embodied AI repository focuses on the development of safe and trustworthy Embodied Artificial Intelligence (EAI) systems. It addresses critical challenges related to safety and trustworthiness in EAI, proposing a unified research framework and defining levels of safety and resilience. The repository provides a comprehensive review of state-of-the-art solutions, benchmarks, and evaluation metrics, aiming to bridge the gap between capability advancement and safety mechanisms in EAI development.
aiocron
aiocron is a Python library that provides crontab functionality for asyncio. It allows users to schedule functions to run at specific times using a decorator or as an object. Users can also await a crontab, use it as a sleep coroutine, and customize functions without decorator magic. aiocron has switched from croniter to cronsim for cron expression parsing since Dec 31, 2024.

enthusiast
Enthusiast is a production-ready agentic AI framework for E-commerce, offering tools like Retrieval-Argumented Generation (RAG), vector search, and workflow orchestrator. It helps in building AI-powered tools with customized agents for tasks like smart information search, customer support, content generation, and knowledge base automation. Enthusiast provides validation and evaluation components to ensure responses are grounded in actual data, reducing time, cost, and complexity in AI development.
BMAD-METHOD
BMAD-METHOD™ is a universal AI agent framework that revolutionizes Agile AI-Driven Development. It offers specialized AI expertise across various domains, including software development, entertainment, creative writing, business strategy, and personal wellness. The framework introduces two key innovations: Agentic Planning, where dedicated agents collaborate to create detailed specifications, and Context-Engineered Development, which ensures complete understanding and guidance for developers. BMAD-METHOD™ simplifies the development process by eliminating planning inconsistency and context loss, providing a seamless workflow for creating AI agents and expanding functionality through expansion packs.
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
Whimbox
Whimbox is a game AI agent based on large language models and image recognition technology, providing users with a new gaming experience. It automates daily tasks such as mining, material collection, and wish checking, as well as features like route recording, image recognition, and AI dialogue. The tool does not modify game files or memory, only captures screenshots and simulates mouse and keyboard actions. It is designed for games running in a 1920x1080 windowed mode on mid to high-end PCs, with plans for future cloud gaming support. Whimbox is grateful to open-source projects like GIA and BetterGI, as well as AI models and programming tools like chatgpt and cursor. Developers interested in contributing to the project can join the development community and explore various functionalities that need development and adaptation.
ComfyUI-TBG-ETUR
ComfyUI-TBG-ETUR is a repository for TBG Enhanced Tiled Upscaler and Refiner Pro, offering advanced enhancement suite for tiled image generation and refinement in ComfyUI. It introduces neuro generative tile fusion, interactive tile-based editing, and multi-path processing pipelines designed for extreme resolution workflows up to 100MP. The tool applies advanced algorithms for AI image enhancement, high-resolution generation, image polishing, and seamless tile fusion. It features a user-friendly interface and offers PRO features for Patreon supporters. The repository provides tutorials, installation guides, and API access for testing PRO features. Users can enhance images, generate high-resolution visuals, and refine images with fine detail using TBG Enhanced Tiled Upscaler and Refiner Pro.

coreply
Coreply is an open-source Android app that provides texting suggestions while typing, enhancing the typing experience with intelligent, context-aware suggestions. It supports various texting apps and offers real-time AI suggestions, customizable LLM settings, and ensures no data collection. Users can install the app, configure it with an API key, and start receiving suggestions while typing in messaging apps. The tool supports different AI models from providers like OpenAI, Google AI Studio, Openrouter, Groq, and Codestral for chat completion and fill-in-the-middle tasks.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.
ai-toolbox
AI-Toolbox is a collection of automation scripts and tools designed to streamline AI workflows. It simplifies the installation process of various AI applications, making software deployment effortless for data scientists, researchers, and developers. The toolbox offers automated installation of multiple applications, customization for specific workflows, easy-to-use scripts, and receives regular updates and contributions from the community.
app-platform
AppPlatform is an advanced large-scale model application engineering aimed at simplifying the development process of AI applications through integrated declarative programming and low-code configuration tools. This project provides a powerful and scalable environment for software engineers and product managers to support the full-cycle development of AI applications from concept to deployment. The backend module is based on the FIT framework, utilizing a plugin-based development approach, including application management and feature extension modules. The frontend module is developed using React framework, focusing on core modules such as application development, application marketplace, intelligent forms, and plugin management. Key features include low-code graphical interface, powerful operators and scheduling platform, and sharing and collaboration capabilities. The project also provides detailed instructions for setting up and running both backend and frontend environments for development and testing.
AI-windows-whl
AI-windows-whl is a curated collection of pre-compiled Python wheels for difficult-to-install AI/ML libraries on Windows. It addresses the common pain point of building complex Python packages from source on Windows by providing direct links to pre-compiled `.whl` files for essential libraries like PyTorch, Flash Attention, xformers, SageAttention, NATTEN, Triton, bitsandbytes, and other packages. The goal is to save time for AI enthusiasts and developers on Windows, allowing them to focus on creating amazing things with AI.
code-graph-rag
Graph-Code is an accurate Retrieval-Augmented Generation (RAG) system that analyzes multi-language codebases using Tree-sitter. It builds comprehensive knowledge graphs, enabling natural language querying of codebase structure and relationships, along with editing capabilities. The system supports various languages, uses Tree-sitter for parsing, Memgraph for storage, and AI models for natural language to Cypher translation. It offers features like code snippet retrieval, advanced file editing, shell command execution, interactive code optimization, reference-guided optimization, dependency analysis, and more. The architecture consists of a multi-language parser and an interactive CLI for querying the knowledge graph.

llmvision-card
LLM Vision Timeline Card is a custom card designed to display the LLM Vision Timeline on your Home Assistant Dashboard. It requires LLM Vision set up in Home Assistant, Timeline provider set up in LLM Vision, and Blueprint or Automation to add events to the timeline. The card allows users to show events that occurred within a specified number of hours and customize the display based on categories and colors. It supports multiple languages for UI and icon generation.
mcp-router
MCP Router is a desktop application that simplifies the management of Model Context Protocol (MCP) servers. It is a universal tool that allows users to connect to any MCP server, supports remote or local servers, and provides data portability by enabling easy export and import of MCP configurations. The application prioritizes privacy and security by storing all data locally, ensuring secure credentials, and offering complete control over server connections and data. Transparency is maintained through auditable source code, verifiable privacy practices, and community-driven security improvements and audits.
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
wanwu
Wanwu AI Agent Platform is an enterprise-grade one-stop commercially friendly AI agent development platform designed for business scenarios. It provides enterprises with a safe, efficient, and compliant one-stop AI solution. The platform integrates cutting-edge technologies such as large language models and business process automation to build an AI engineering platform covering model full life-cycle management, MCP, web search, AI agent rapid development, enterprise knowledge base construction, and complex workflow orchestration. It supports modular architecture design, flexible functional expansion, and secondary development, reducing the application threshold of AI technology while ensuring security and privacy protection of enterprise data. It accelerates digital transformation, cost reduction, efficiency improvement, and business innovation for enterprises of all sizes.
Awesome-Efficient-MoE
Awesome Efficient MoE is a GitHub repository that provides an implementation of Mixture of Experts (MoE) models for efficient deep learning. The repository includes code for training and using MoE models, which are neural network architectures that combine multiple expert networks to improve performance on complex tasks. MoE models are particularly useful for handling diverse data distributions and capturing complex patterns in data. The implementation in this repository is designed to be efficient and scalable, making it suitable for training large-scale MoE models on modern hardware. The code is well-documented and easy to use, making it accessible for researchers and practitioners interested in leveraging MoE models for their deep learning projects.
bella-openapi
Bella OpenAPI is an API gateway that provides rich AI capabilities, similar to openrouter. In addition to chat completion ability, it also offers text embedding, ASR, TTS, image-to-image, and text-to-image AI capabilities. It integrates billing, rate limiting, and resource management functions. All integrated capabilities have been validated in large-scale production environments. The tool supports various AI capabilities, metadata management, unified login service, billing and rate limiting, and has been validated in large-scale production environments for stability and reliability. It offers a user-friendly experience with Java-friendly technology stack, convenient cloud-based experience service, and Dockerized deployment.
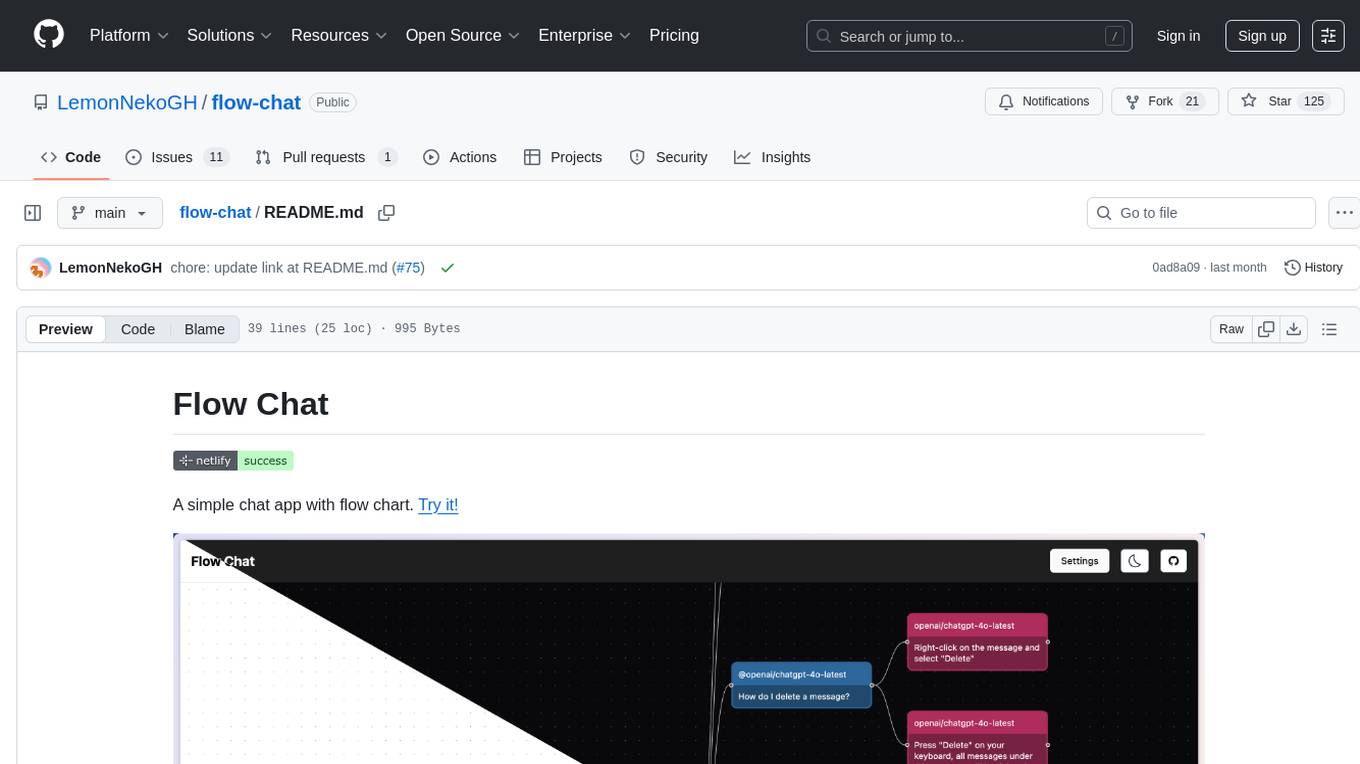
flow-chat
Flow Chat is a simple chat application with flow chart functionality. It allows users to generate text and images, create branches from messages, and switch between different models. The project uses `.tool-versions` for tool version management and provides commands for installation and starting the development server. It also includes a build command and a Star History chart to track repository popularity.
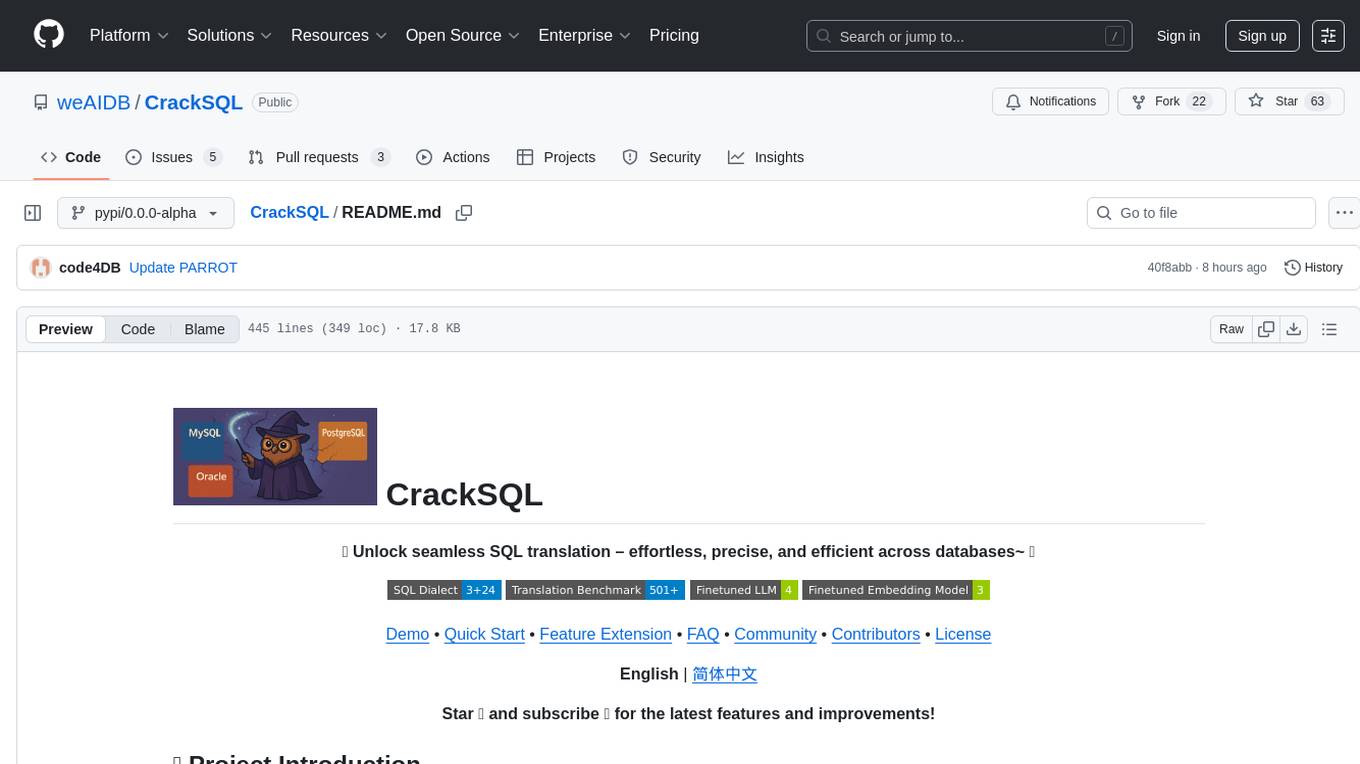
CrackSQL
CrackSQL is a powerful SQL dialect translation tool that integrates rule-based strategies with large language models (LLMs) for high accuracy. It enables seamless conversion between dialects (e.g., PostgreSQL → MySQL) with flexible access through Python API, command line, and web interface. The tool supports extensive dialect compatibility, precision & advanced processing, and versatile access & integration. It offers three modes for dialect translation and demonstrates high translation accuracy over collected benchmarks. Users can deploy CrackSQL using PyPI package installation or source code installation methods. The tool can be extended to support additional syntax, new dialects, and improve translation efficiency. The project is actively maintained and welcomes contributions from the community.
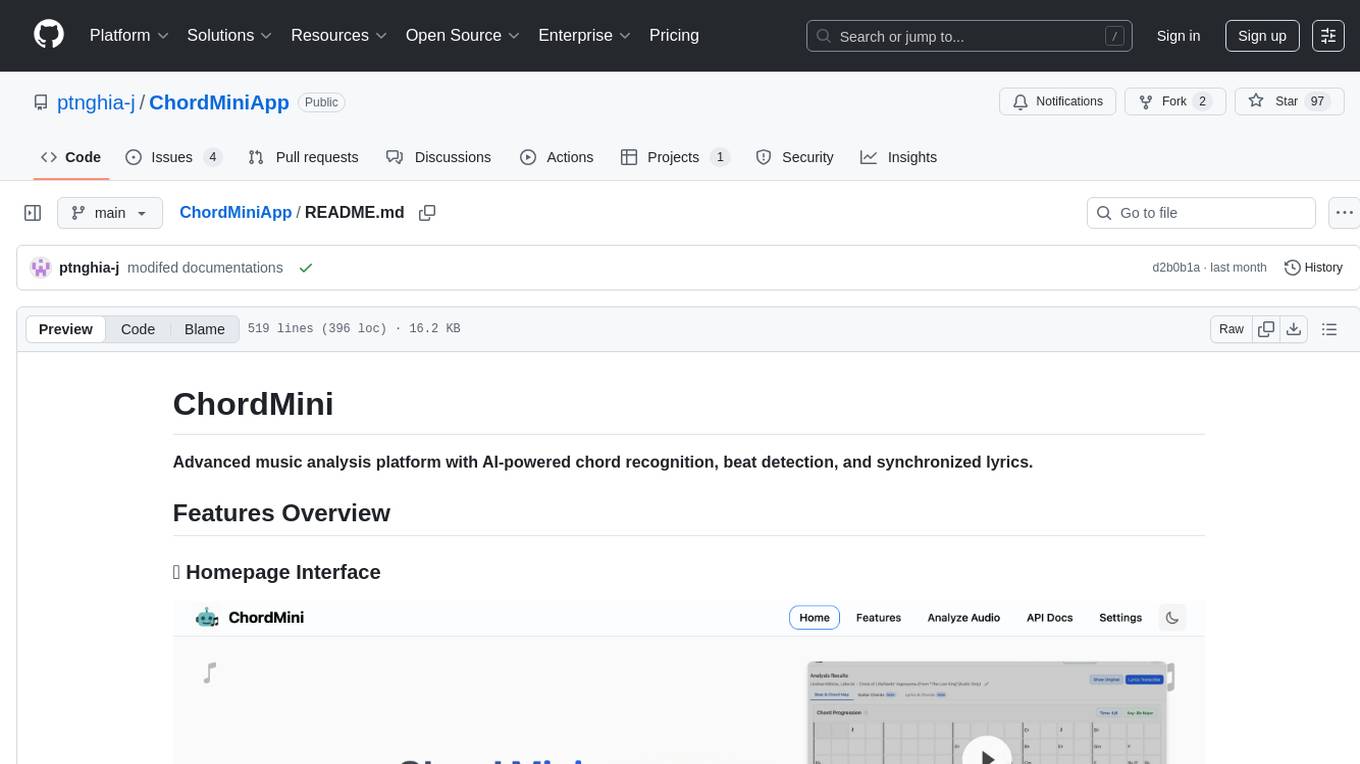
ChordMiniApp
ChordMini is an advanced music analysis platform with AI-powered chord recognition, beat detection, and synchronized lyrics. It features a clean and intuitive interface for YouTube search, chord progression visualization, interactive guitar diagrams with accurate fingering patterns, lead sheet with AI assistant for synchronized lyrics transcription, and various add-on features like Roman Numeral Analysis, Key Modulation Signals, Simplified Chord Notation, and Enhanced Chord Correction. The tool requires Node.js, Python 3.9+, and a Firebase account for setup. It offers a hybrid backend architecture for local development and production deployments, with features like beat detection, chord recognition, lyrics processing, rate limiting, and audio processing supporting MP3, WAV, and FLAC formats. ChordMini provides a comprehensive music analysis workflow from user input to visualization, including dual input support, environment-aware processing, intelligent caching, advanced ML pipeline, and rich visualization options.
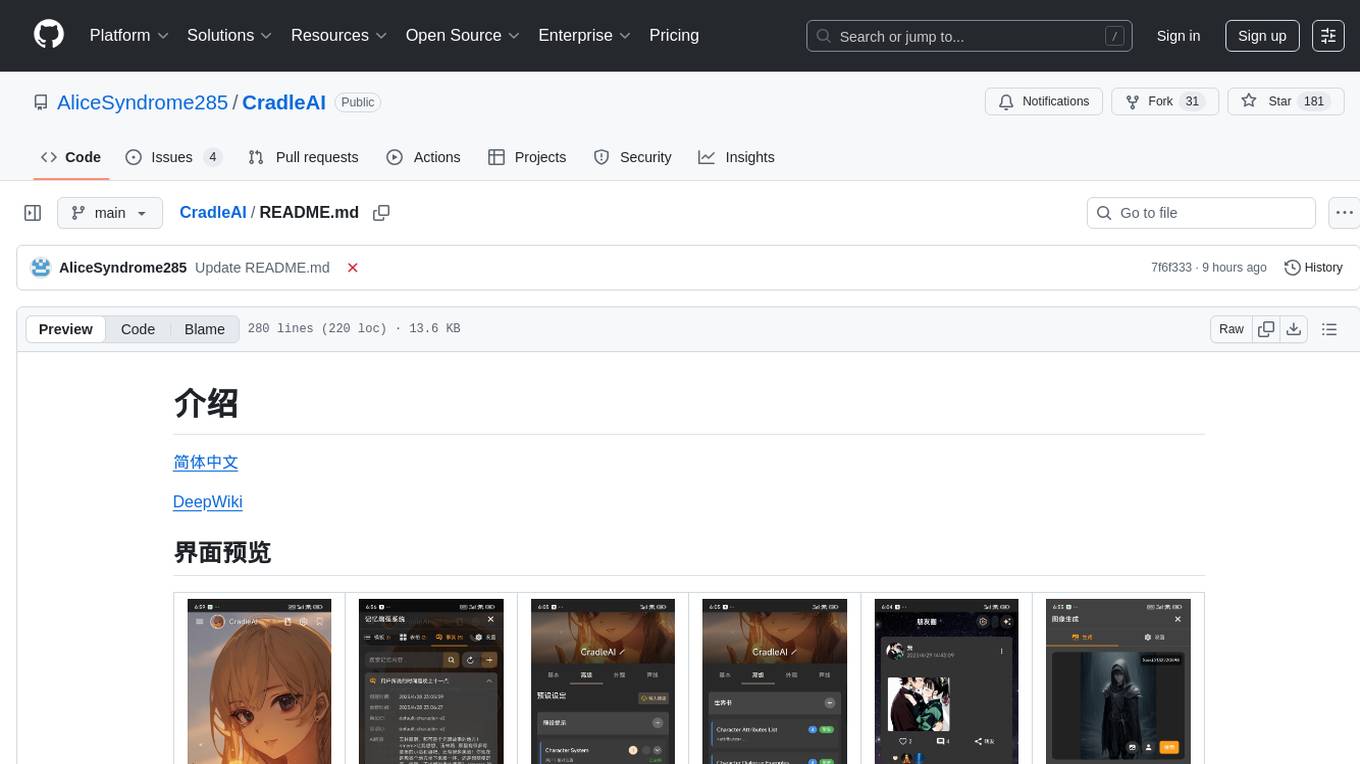
CradleAI
CradleAI is an open-source front-end tool designed for non-commercial purposes. It allows users to create and manage characters, engage in AI roleplay chats, publish dynamic content in a social circle, participate in group chats, and manage memories and knowledge. The tool supports features like author notes, voice interactions, multimedia messaging, visual novel mode, rich text formatting, image generation, TTS enhancement, and more. Users can deploy the tool using Github Action for APK builds or EAS Build for Android and iOS platforms. The project is licensed under CC BY-NC 4.0, prohibiting commercial use and emphasizing proper attribution.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.
Auditor
TheAuditor is an offline-first, AI-centric SAST & code intelligence platform designed to find security vulnerabilities, track data flow, analyze architecture, detect refactoring issues, run industry-standard tools, and produce AI-ready reports. It is specifically tailored for AI-assisted development workflows, providing verifiable ground truth for developers and AI assistants. The tool orchestrates verifiable data, focuses on AI consumption, and is extensible to support Python and Node.js ecosystems. The comprehensive analysis pipeline includes stages for foundation, concurrent analysis, and final aggregation, offering features like refactoring detection, dependency graph visualization, and optional insights analysis. The tool interacts with antivirus software to identify vulnerabilities, triggers performance impacts, and provides transparent information on common issues and troubleshooting. TheAuditor aims to address the lack of ground truth in AI development workflows and make AI development trustworthy by providing accurate security analysis and code verification.
blog
VNTechies Blog is a platform dedicated to sharing open-source resources and providing knowledge and career guidance for the Cloud and DevOps community. The blog encourages contributions and support through donations. All content on the blog and repository is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
chat-ui
This repository provides a minimalist approach to create a chatbot by constructing the entire front-end UI using a single HTML file. It supports various backend endpoints through custom configurations, multiple response formats, chat history download, and MCP. Users can deploy the chatbot locally, via Docker, Cloudflare pages, Huggingface, or within K8s. The tool also supports image inputs, toggling between different display formats, internationalization, and localization.
Call
Call is an open-source AI-native alternative to Google Meet and Zoom, offering video calling, team collaboration, contact management, meeting scheduling, AI-powered features, security, and privacy. It is cross-platform, web-based, mobile responsive, and supports offline capabilities. The tech stack includes Next.js, TypeScript, Tailwind CSS, Mediasoup-SFU, React Query, Zustand, Hono, PostgreSQL, Drizzle ORM, Better Auth, Turborepo, Docker, Vercel, and Rate Limiting.
Sec-Interview
Sec-Interview is a comprehensive collection of cybersecurity interview questions with reference answers, covering network security, red team, reverse engineering, cryptography, and binary. It is suitable for all cybersecurity positions. The repository contains thousands of security interview questions categorized for easy access. Contributors are welcome to submit interview questions or provide feedback for future versions. Special thanks to various individuals and teams for their valuable contributions and support during the project's organization and improvement.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

blades
Blades is a multimodal AI Agent framework in Go, supporting custom models, tools, memory, middleware, and more. It is well-suited for multi-turn conversations, chain reasoning, and structured output. The framework provides core components like Agent, Prompt, Chain, ModelProvider, Tool, Memory, and Middleware, enabling developers to build intelligent applications with flexible configuration and high extensibility. Blades leverages the characteristics of Go to achieve high decoupling and efficiency, making it easy to integrate different language model services and external tools. The project is in its early stages, inviting Go developers and AI enthusiasts to contribute and explore the possibilities of building AI applications in Go.
CRISS-AI
CRISS-AI is a powerful WhatsApp bot crafted by Criss Vevo, utilizing next-gen AI technology. It offers fast, secure, and reliable solutions for various tasks. The repository provides tools for forking, session management, and deployment on platforms like Heroku and Render. Users can also promote their channels using the available features.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
copilot-lsp
Copilot LSP is a configuration tool for Neovim that enhances the native LSP functionality. It provides features such as text document focusing, inline completion, next edit suggestion, and status notifications. Users can easily integrate Copilot LSP into their Neovim setup to improve their coding experience. The tool offers smart clearing of suggestions, customizable defaults for Next Edit Suggestion (NES), and integration with Blink for inline completions. Copilot LSP requires installation via Mason or system and should be added to the PATH for seamless usage.
GalTransl
GalTransl is an automated translation tool for Galgames that combines minor innovations in several basic functions with deep utilization of GPT prompt engineering. It is used to create embedded translation patches. The core of GalTransl is a set of automated translation scripts that solve most known issues when using ChatGPT for Galgame translation and improve overall translation quality. It also integrates with other projects to streamline the patch creation process, reducing the learning curve to some extent. Interested users can more easily build machine-translated patches of a certain quality through this project and may try to efficiently build higher-quality localization patches based on this framework.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
narratrix
NarratrixAI is an AI-powered tabletop roleplaying platform that leverages AI to create dynamic, responsive, and immersive storytelling experiences. It allows users to create their own stories, use it as character chat, or as a full tabletop RPG experience. The platform features a powerful chat system, flexible AI integration, rich character management, powerful storytelling tools, and developer-friendly customization options. Narratrix supports various AI providers through a manifest system and is built with Tauri for native performance across Windows, macOS, and Linux platforms.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
qwen-tts
Qwen-TTS is a versatile text-to-speech service offering multi-voice support for both Chinese and English, including dialects like Beijing, Shanghai, and Sichuan. It provides real-time synthesis, batch processing, smart segmentation, progress tracking, audio playback, and outputs in WAV format. The application features a modern design, intuitive operation, history tracking, and real-time feedback. It also offers technical features like asynchronous processing, error handling, file management, and API documentation.
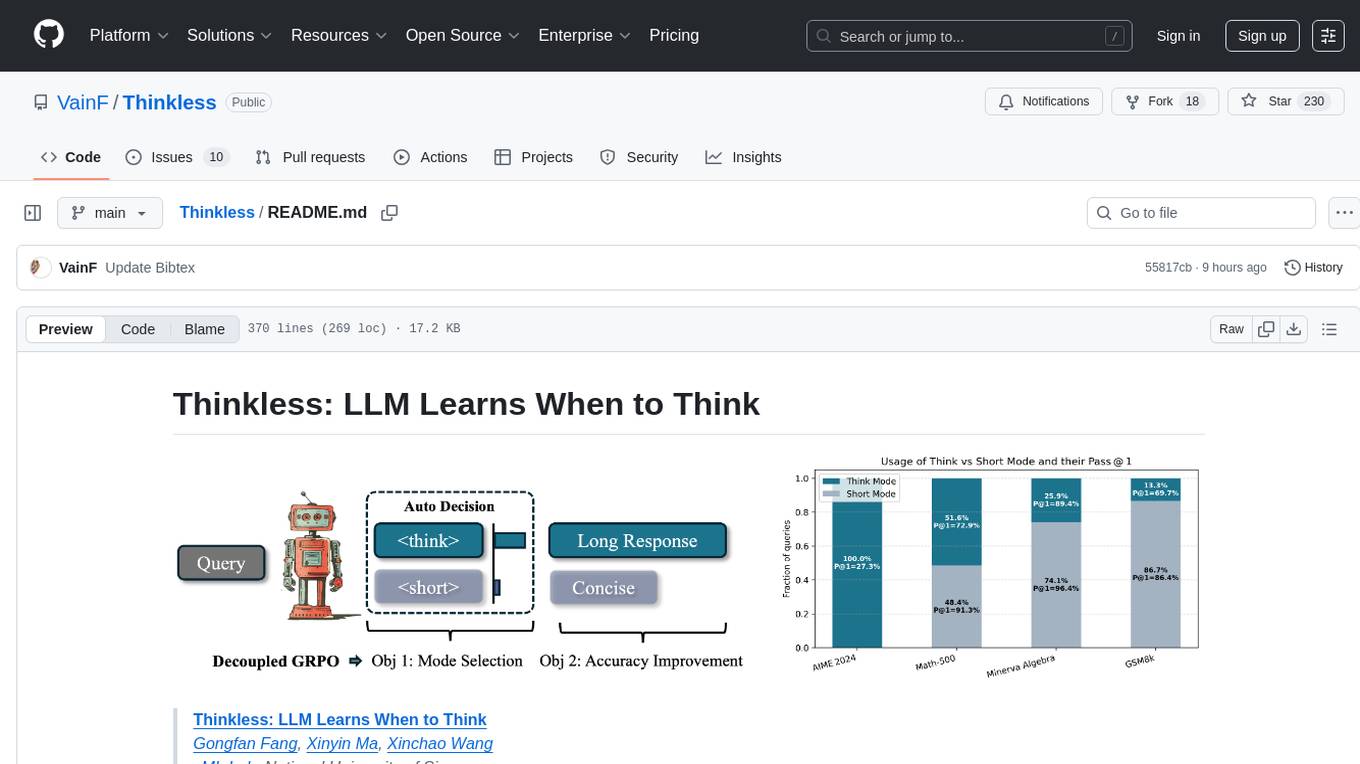
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.
voyant
Voyant Travel Assistant is a meta-agent pipeline designed for fast, trustworthy answers with clear provenance and resilient I/O. It focuses on AI-first planning, strict JSON parsing, non-blocking async I/O, and verification pipelines. The tool analyzes user messages, plans tool calls, executes actions, and blends responses from various tools. It supports tools like weather, country information, attractions, travel search, flight information, and policy extraction. Users can interact with the tool through a CLI interface and benefit from its architecture that ensures reliable responses and observability through stored receipts and verification processes.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.
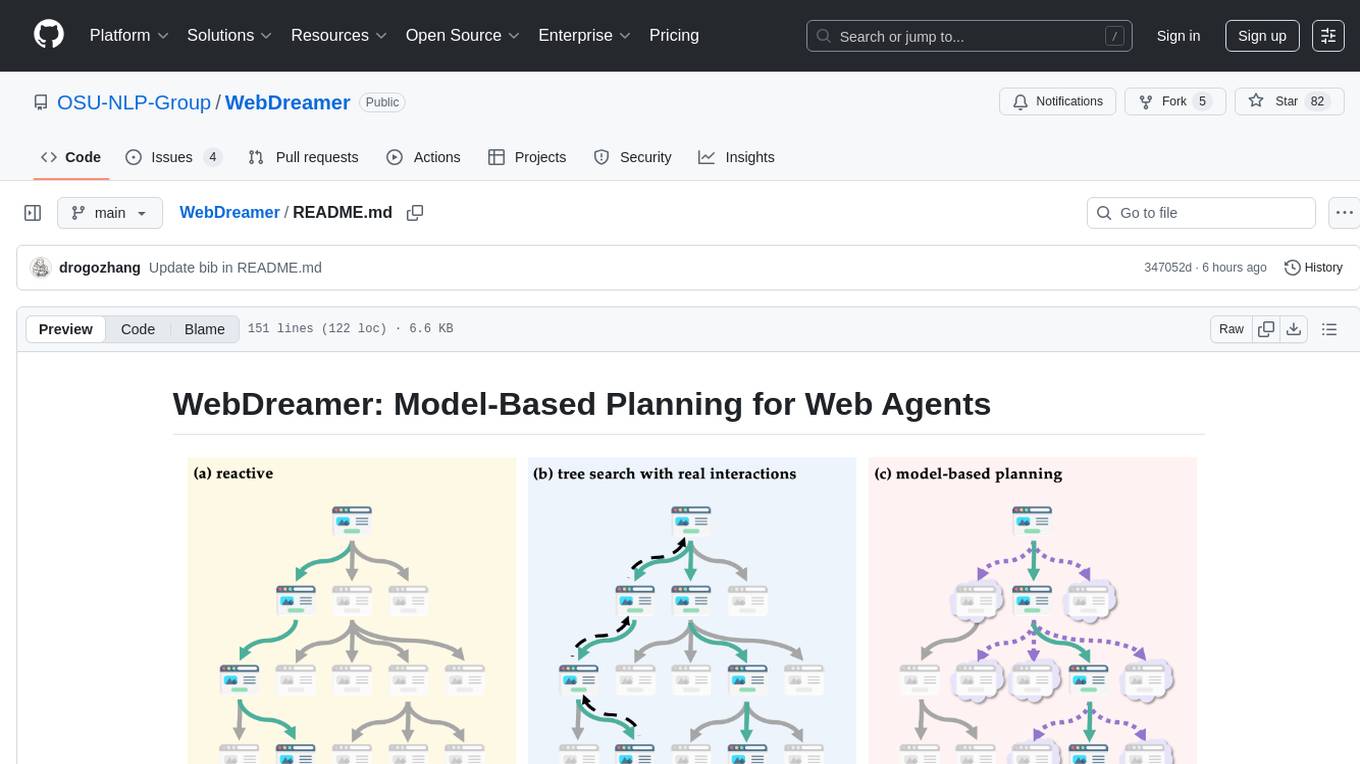
WebDreamer
WebDreamer is a model-based planning tool for web agents that uses large language models (LLMs) as a world model of the internet to predict outcomes of actions on websites. It employs LLM-based simulation for speculative planning on the web, offering greater safety and flexibility compared to traditional tree search methods. The tool provides modules for world model prediction, simulation scoring, and controller actions, enabling users to interact with web pages and achieve specific goals through simulated actions.

LMeterX
LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

agent-sdk-go
Agent Go SDK is a powerful Go framework for building production-ready AI agents that seamlessly integrates memory management, tool execution, multi-LLM support, and enterprise features into a flexible, extensible architecture. It offers core capabilities like multi-model intelligence, modular tool ecosystem, advanced memory management, and MCP integration. The SDK is enterprise-ready with built-in guardrails, complete observability, and support for enterprise multi-tenancy. It provides a structured task framework, declarative configuration, and zero-effort bootstrapping for development experience. The SDK supports environment variables for configuration and includes features like creating agents with YAML configuration, auto-generating agent configurations, using MCP servers with an agent, and CLI tool for headless usage.

a2a-java
A2A Java SDK is a Java library that helps run agentic applications as A2AServers following the Agent2Agent (A2A) Protocol. It provides a Java server implementation of the A2A Protocol, allowing users to create A2A server agents and execute tasks. The SDK also includes a Java client implementation for communication with A2A servers using various transports like JSON-RPC 2.0, gRPC, and HTTP+JSON/REST. Users can configure different transport protocols, handle messages, tasks, push notifications, and interact with server agents. The SDK supports streaming and non-streaming responses, error handling, and task management functionalities.
aiconfigurator
The `aiconfigurator` tool assists in finding a strong starting configuration for disaggregated serving in AI deployments. It helps optimize throughput at a given latency by evaluating thousands of configurations based on model, GPU count, and GPU type. The tool models LLM inference using collected data for a target machine and framework, running via CLI and web app. It generates configuration files for deployment with Dynamo, offering features like customized configuration, all-in-one automation, and tuning with advanced features. The tool estimates performance by breaking down LLM inference into operations, collecting operation execution times, and searching for strong configurations. Supported features include models like GPT and operations like attention, KV cache, GEMM, AllReduce, embedding, P2P, element-wise, MoE, MLA BMM, TRTLLM versions, and parallel modes like tensor-parallel and pipeline-parallel.
EScAIP
EScAIP is an Efficiently Scaled Attention Interatomic Potential that leverages a novel multi-head self-attention formulation within graph neural networks to predict energy and forces between atoms in molecules and materials. It achieves substantial gains in efficiency, at least 10x speed up in inference time and 5x less memory usage compared to existing models. EScAIP represents a philosophy towards developing general-purpose Neural Network Interatomic Potentials that achieve better expressivity through scaling and continue to scale efficiently with increased computational resources and training data.

aderyn
Aderyn is a powerful Solidity static analyzer designed to help protocol engineers and security researchers find vulnerabilities in Solidity code bases. It provides off-the-shelf support for Foundry and Hardhat projects, allows for custom frameworks through a configuration file, and generates reports in Markdown, JSON, and Sarif formats. Users can install Aderyn using Cyfrinup, curl, Homebrew, or npm, and quickly identify vulnerabilities in their Solidity code. The tool also offers a VS Code extension for seamless integration with the IDE.

xpander.ai
xpander.ai is a Backend-as-a-Service for autonomous agents that abstracts the ops layer, allowing AI engineers to focus on behavior and outcomes. It provides managed agent hosting with version control and CI/CD, a fully managed PostgreSQL memory layer, and a library of 2,000+ functions. The platform features an AI native triggering system that processes inputs from various sources and delivers unified messages to agents. With support for any agent framework or SDK, including Agno and OpenAI, xpander.ai enables users to build intelligent, production-ready AI agents without dealing with infrastructure complexity.
inspect_evals
Inspect Evals is a repository of community-contributed LLM evaluations for Inspect AI, created in collaboration by the UK AISI, Arcadia Impact, and the Vector Institute. It supports many model providers including OpenAI, Anthropic, Google, Mistral, Azure AI, AWS Bedrock, Together AI, Groq, Hugging Face, vLLM, and Ollama. Users can contribute evaluations, install necessary dependencies, and run evaluations for various models. The repository covers a wide range of evaluation tasks across different domains such as coding, assistants, cybersecurity, safeguards, mathematics, reasoning, knowledge, scheming, multimodal tasks, bias evaluation, personality assessment, and writing tasks.
chonkie
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
CoDrivingLLM
CoDrivingLLM is a machine learning model for predicting driving behavior based on sensor data collected from vehicles. It utilizes a Long Short-Term Memory (LSTM) neural network to analyze patterns in the data and make predictions about future driving actions. The model is trained on a large dataset of driving scenarios and can be used to improve driver assistance systems, enhance road safety, and optimize vehicle performance. CoDrivingLLM is designed to be easily integrated into existing automotive systems and can provide real-time feedback to drivers to help them make safer and more efficient driving decisions.
promptl
Promptl is a versatile command-line tool designed to streamline the process of creating and managing prompts for user input in various programming projects. It offers a simple and efficient way to prompt users for information, validate their input, and handle different scenarios based on their responses. With Promptl, developers can easily integrate interactive prompts into their scripts, applications, and automation workflows, enhancing user experience and improving overall usability. The tool provides a range of customization options and features, making it suitable for a wide range of use cases across different programming languages and environments.
ome
Ome is a versatile tool designed for managing and organizing tasks and projects efficiently. It provides a user-friendly interface for creating, tracking, and prioritizing tasks, as well as collaborating with team members. With Ome, users can easily set deadlines, assign tasks, and monitor progress to ensure timely completion of projects. The tool offers customizable features such as tags, labels, and filters to streamline task management and improve productivity. Ome is suitable for individuals, teams, and organizations looking to enhance their task management process and achieve better results.
LLaVA-OneVision-1.5
LLaVA-OneVision 1.5 is a fully open framework for democratized multimodal training, introducing a novel family of large multimodal models achieving state-of-the-art performance at lower cost through training on native resolution images. It offers superior performance across multiple benchmarks, high-quality data at scale with concept-balanced and diverse caption data, and an ultra-efficient training framework with support for MoE, FP8, and long sequence parallelization. The framework is fully open for community access and reproducibility, providing high-quality pre-training & SFT data, complete training framework & code, training recipes & configurations, and comprehensive training logs & metrics.
TermNet
TermNet is an AI-powered terminal assistant that connects a Large Language Model (LLM) with shell command execution, browser search, and dynamically loaded tools. It streams responses in real-time, executes tools one at a time, and maintains conversational memory across steps. The project features terminal integration for safe shell command execution, dynamic tool loading without code changes, browser automation powered by Playwright, WebSocket architecture for real-time communication, a memory system to track planning and actions, streaming LLM output integration, a safety layer to block dangerous commands, dual interface options, a notification system, and scratchpad memory for persistent note-taking. The architecture includes a multi-server setup with servers for WebSocket, browser automation, notifications, and web UI. The project structure consists of core backend files, various tools like web browsing and notification management, and servers for browser automation and notifications. Installation requires Python 3.9+, Ollama, and Chromium, with setup steps provided in the README. The tool can be used via the launcher for managing components or directly by starting individual servers. Additional tools can be added by registering them in `toolregistry.json` and implementing them in Python modules. Safety notes highlight the blocking of dangerous commands, allowed risky commands with warnings, and the importance of monitoring tool execution and setting appropriate timeouts.

bagel
Bagel is a tool that allows users to chat with their robotics and drone data similar to using ChatGPT. It generates deterministic and auditable DuckDB SQL queries to analyze data, supporting various robotics and sensor log formats. Users can interact with Bagel through a Discord server, and it can be integrated with different language models. Bagel provides tutorials, Docker images for easy deployment, and a roadmap for upcoming features like Computer Vision Module, Anomaly Detection, and more.
sparql-llm
This project provides tools to enhance the capabilities of Large Language Models (LLMs) in generating SPARQL queries for specific endpoints. It includes reusable components, a chat web service, and an experimental MCP server. The system integrates Retrieval-Augmented Generation (RAG) and SPARQL query validation through endpoint schemas to ensure accurate query generation on large-scale knowledge graphs. Components can work independently or as part of a chat-based system requiring endpoint metadata. Features include metadata extraction, SPARQL query validation, deployable chat system, and live example chat system at chat.expasy.org.
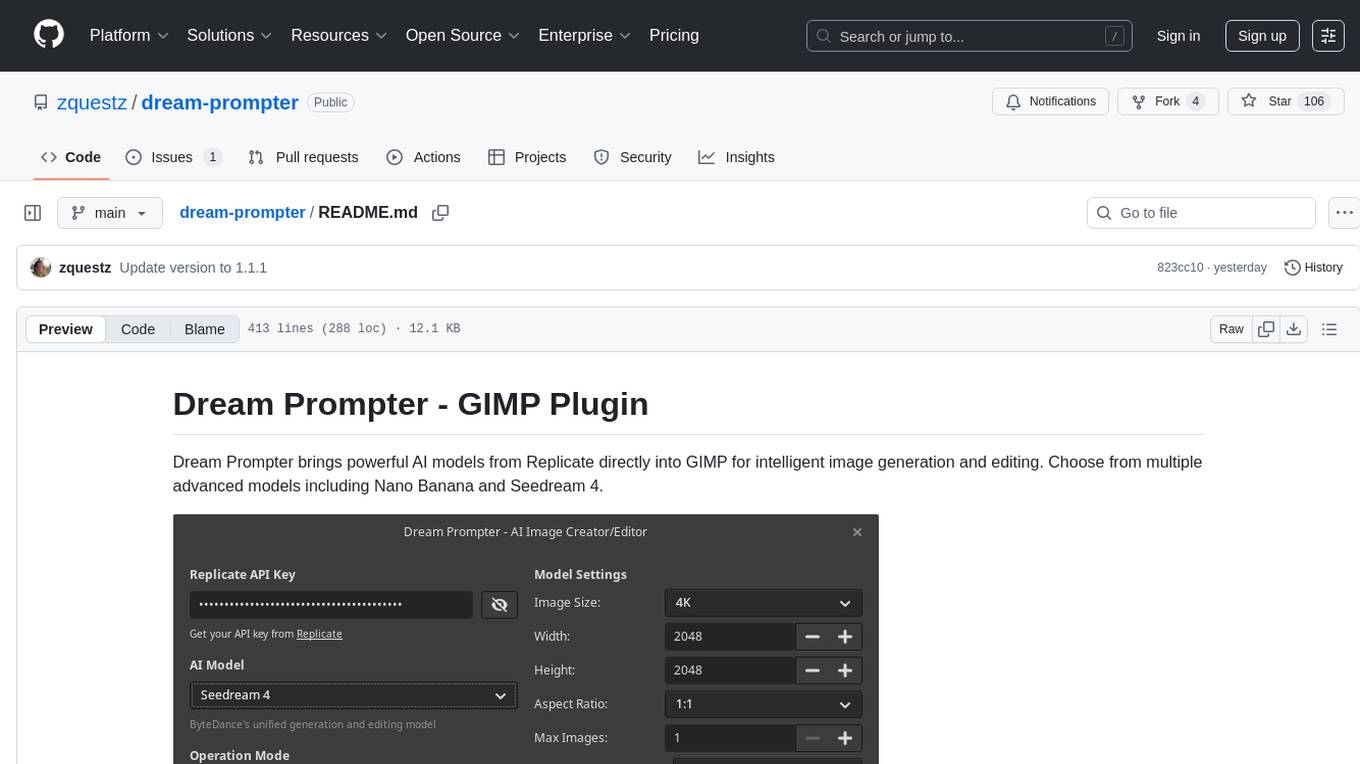
dream-prompter
Dream Prompter is a tool designed to help users generate creative writing prompts for their stories, essays, or any other creative projects. It uses a database of various elements such as characters, settings, and plot twists to randomly generate unique prompts that can inspire writers and spark their creativity. With Dream Prompter, users can easily overcome writer's block and find new ideas to develop their writing skills and produce engaging content.
dranet
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.

zeus
Zeus is a library for measuring the energy consumption of Deep Learning workloads and optimizing their energy consumption. It provides functionalities for energy and power measurement, time and energy optimization, device abstraction, utility functions, and more. Zeus is part of The ML.ENERGY Initiative and has been recognized in various research papers and conferences. It offers a Docker image with all dependencies, working examples for integration, and ongoing research to enhance its capabilities.
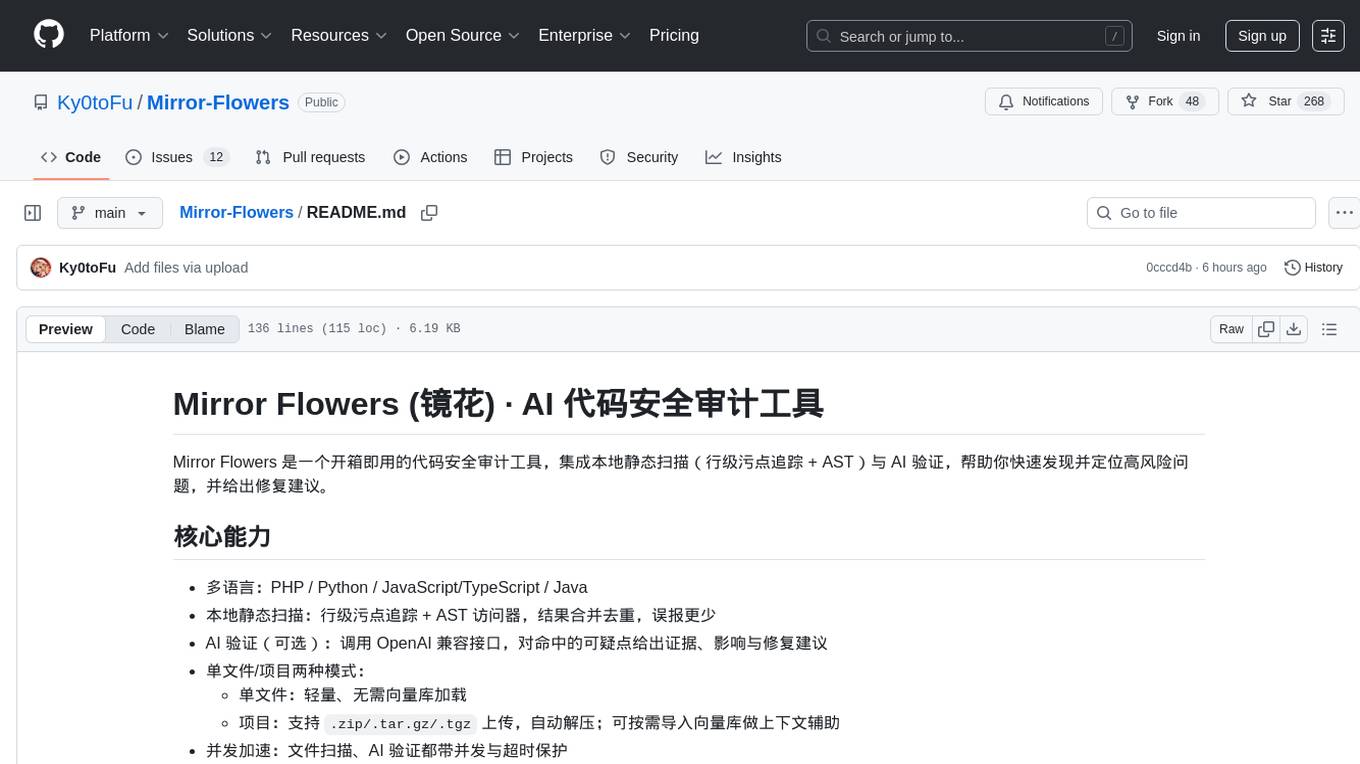
Mirror-Flowers
Mirror Flowers is an out-of-the-box code security auditing tool that integrates local static scanning (line-level taint tracking + AST) with AI verification to help quickly discover and locate high-risk issues, providing repair suggestions. It supports multiple languages such as PHP, Python, JavaScript/TypeScript, and Java. The tool offers both single-file and project modes, with features like concurrent acceleration, integrated UI for visual results, and compatibility with multiple OpenAI interface providers. Users can configure the tool through environment variables or API, and can utilize it through a web UI or HTTP API for tasks like single-file auditing or project auditing.
OpenSpec
OpenSpec is a tool for spec-driven development, aligning humans and AI coding assistants to agree on what to build before any code is written. It adds a lightweight specification workflow that ensures deterministic, reviewable outputs without the need for API keys. With OpenSpec, stakeholders can draft change proposals, review and align with AI assistants, implement tasks based on agreed specs, and archive completed changes for merging back into the source-of-truth specs. It works seamlessly with existing AI tools, offering shared visibility into proposed, active, or archived work.
open-edison
OpenEdison is a secure MCP control panel that connects AI to data/software with additional security controls to reduce data exfiltration risks. It helps address the lethal trifecta problem by providing visibility, monitoring potential threats, and alerting on data interactions. The tool offers features like data leak monitoring, controlled execution, easy configuration, visibility into agent interactions, a simple API, and Docker support. It integrates with LangGraph, LangChain, and plain Python agents for observability and policy enforcement. OpenEdison helps gain observability, control, and policy enforcement for AI interactions with systems of records, existing company software, and data to reduce risks of AI-caused data leakage.
coding-agent-template
Coding Agent Template is a versatile tool for building AI-powered coding agents that support various coding tasks using Claude Code, OpenAI's Codex CLI, Cursor CLI, and opencode with Vercel Sandbox. It offers features like multi-agent support, Vercel Sandbox for secure code execution, AI Gateway integration, AI-generated branch names, task management, persistent storage, Git integration, and a modern UI built with Next.js and Tailwind CSS. Users can easily deploy their own version of the template to Vercel and set up the tool by cloning the repository, installing dependencies, configuring environment variables, setting up the database, and starting the development server. The tool simplifies the process of creating tasks, monitoring progress, reviewing results, and managing tasks, making it ideal for developers looking to automate coding tasks with AI agents.
mslearn-ai-studio
The mslearn-ai-studio repository provides hands-on exercises for building generative AI solutions on Microsoft Azure. Users can explore common tasks related to generative AI models and Azure resources. The exercises are designed to complement Microsoft Learn modules and require an Azure subscription for completion.
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.
shai
shai is a coding agent written in Rust that serves as a pair programming buddy in the terminal. It can be used to run code, provide suggestions, and act as a shell assistant. Users can configure providers, run headless, create custom agents, and interact with OVHCloud endpoints for AI capabilities.
mcp-apache-spark-history-server
The MCP Server for Apache Spark History Server is a tool that connects AI agents to Apache Spark History Server for intelligent job analysis and performance monitoring. It enables AI agents to analyze job performance, identify bottlenecks, and provide insights from Spark History Server data. The server bridges AI agents with existing Apache Spark infrastructure, allowing users to query job details, analyze performance metrics, compare multiple jobs, investigate failures, and generate insights from historical execution data.
slack-mcp-server
Slack MCP Server is a Model Context Protocol server for Slack Workspaces, offering powerful features like Stealth and OAuth Modes, Enterprise Workspaces Support, Channel and Thread Support, Smart History, Search Messages, Safe Message Posting, DM and Group DM support, Embedded user information, Cache support, and multiple transport options. It provides tools like conversations_history, conversations_replies, conversations_add_message, conversations_search_messages, and channels_list for managing messages, threads, adding messages, searching messages, and listing channels. The server also exposes directory resources for workspace metadata access. The tool is designed to enhance Slack workspace functionality and improve user experience.
ai-dj
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
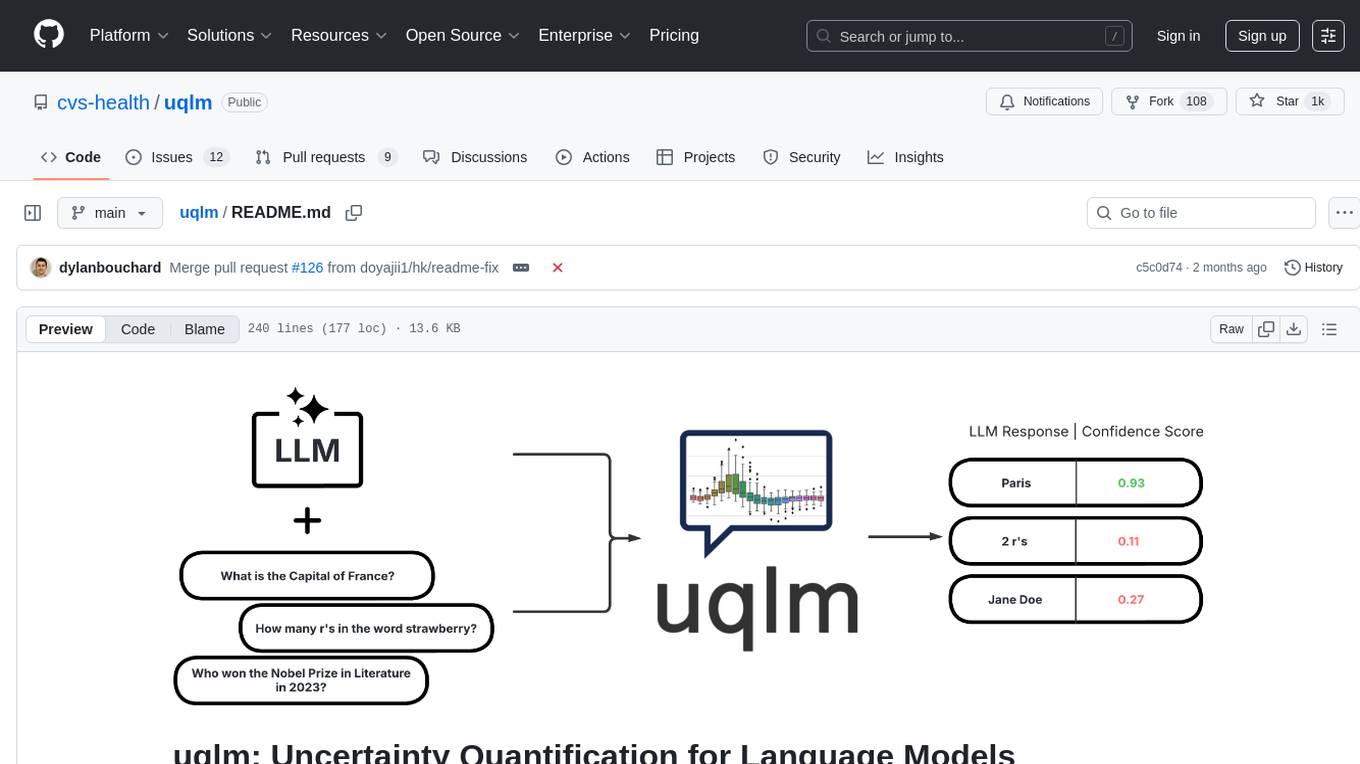
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.
tunix
Tunix is a JAX-based library designed for post-training Large Language Models. It provides efficient support for supervised fine-tuning, reinforcement learning, and knowledge distillation. Tunix leverages JAX for accelerated computation and integrates seamlessly with the Flax NNX modeling framework. The library is modular, efficient, and designed for distributed training on accelerators like TPUs. Currently in early development, Tunix aims to expand its capabilities, usability, and performance.
| Screenshot | Name | Type | Metrics | Entry Date |
|---|---|---|---|---|
|
|
Website-Crawler | github | 61 | 2025-09-29 00:14:38.461000 |
|
|
mdream | github | 604 | 2025-09-29 00:14:32.214000 |
|
|
SpecForge | github | 407 | 2025-09-29 00:14:30.583000 |
|
|
pentest-agent | github | 71 | 2025-09-29 00:14:13.789000 |
|
|
falkordb-browser | github | 55 | 2025-09-29 00:13:51.824000 |
|
|
mcp-server-chart | github | 2.9k | 2025-09-29 00:13:12.644000 |
|
|
lemonai | github | 994 | 2025-09-29 00:13:11.076000 |
|
|
DelhiLM | github | 101 | 2025-09-29 00:13:00.878000 |
|
|
verifiers | github | 3.2k | 2025-09-29 00:12:42.309000 |
|
|
Awesome-LLM-Causal-Reasoning | github | 78 | 2025-09-29 00:11:54.681000 |
|
|
OSA | github | 94 | 2025-09-29 00:11:35.548000 |
|
|
exllamav3 | github | 511 | 2025-09-29 00:09:16.454000 |
|
|
golitex | github | 478 | 2025-09-29 00:08:51.366000 |
|
|
binglish | github | 67 | 2025-09-29 00:08:34.294000 |
|
|
saga-reader | github | 367 | 2025-09-29 00:08:04.207000 |
|
|
bigtop-manager | github | 97 | 2025-09-29 00:07:48.976000 |
|
|
gitmesh | github | 104 | 2025-09-29 00:07:30.560000 |
|
|
nsfw_ai_model_server | github | 87 | 2025-09-29 00:07:20.134000 |
|
|
innoshop | github | 537 | 2025-09-29 00:07:15.110000 |
|
|
fastapi-langgraph-agent-production-ready-template | github | 1.3k | 2025-09-29 00:06:48.467000 |
|
|
Awesome-Trustworthy-Embodied-AI | github | 63 | 2025-09-29 00:06:22.526000 |
|
|
aiocron | github | 371 | 2025-09-29 00:06:16.374000 |
|
|
enthusiast | github | 81 | 2025-09-29 00:05:52.169000 |
|
|
BMAD-METHOD | github | 16.4k | 2025-09-29 00:05:27.799000 |
|
|
Feishu-MCP | github | 159 | 2025-09-29 00:05:24.171000 |
|
|
Whimbox | github | 72 | 2025-09-29 00:05:18.576000 |
|
|
ComfyUI-TBG-ETUR | github | 63 | 2025-09-29 00:05:15.088000 |
|
|
coreply | github | 95 | 2025-09-29 00:04:45.861000 |
|
|
ModelGenerator | github | 94 | 2025-09-29 00:04:32.933000 |
|
|
ai-toolbox | github | 68 | 2025-09-29 00:04:29.502000 |
|
|
app-platform | github | 1.3k | 2025-09-29 00:03:57.197000 |
|
|
AI-windows-whl | github | 147 | 2025-09-29 00:03:21.933000 |
|
|
code-graph-rag | github | 1.2k | 2025-09-29 00:03:13.427000 |
|
|
llmvision-card | github | 68 | 2025-09-28 00:14:16.200000 |
|
|
mcp-router | github | 549 | 2025-09-28 00:14:08.618000 |
|
|
rllm | github | 4.3k | 2025-09-28 00:13:43.539000 |
|
|
wanwu | github | 1.4k | 2025-09-28 00:13:41.806000 |
|
|
Awesome-Efficient-MoE | github | 131 | 2025-09-28 00:13:35.541000 |
|
|
bella-openapi | github | 120 | 2025-09-28 00:12:31.901000 |
|
|
flow-chat | github | 125 | 2025-09-28 00:11:46.845000 |
|
|
CrackSQL | github | 63 | 2025-09-28 00:10:46.893000 |
|
|
ChordMiniApp | github | 97 | 2025-09-28 00:09:08.190000 |
|
|
CradleAI | github | 181 | 2025-09-28 00:07:23.802000 |
|
|
volga | github | 70 | 2025-09-28 00:07:10.110000 |
|
|
Auditor | github | 199 | 2025-09-28 00:06:51.311000 |
|
|
blog | github | 74 | 2025-09-28 00:06:46.327000 |
|
|
chat-ui | github | 76 | 2025-09-28 00:06:09.168000 |
|
|
Call | github | 395 | 2025-09-28 00:05:48.582000 |
|
|
Sec-Interview | github | 248 | 2025-09-28 00:05:46.794000 |
|
|
aigverse | github | 65 | 2025-09-28 00:05:39.046000 |
|
|
blades | github | 393 | 2025-09-28 00:05:25.746000 |
|
|
CRISS-AI | github | 92 | 2025-09-28 00:05:20.529000 |
|
|
ApeRAG | github | 780 | 2025-09-28 00:05:12.938000 |
|
|
copilot-lsp | github | 357 | 2025-09-28 00:05:11.333000 |
|
|
GalTransl | github | 1.8k | 2025-09-28 00:04:54.061000 |
|
|
AirGym | github | 82 | 2025-09-28 00:04:32.268000 |
|
|
prisma-ai | github | 300 | 2025-09-28 00:03:56.194000 |
|
|
ai-performance-engineering | github | 135 | 2025-09-28 00:03:40.307000 |
|
|
conduit | github | 429 | 2025-09-28 00:03:32.415000 |
|
|
narratrix | github | 53 | 2025-09-28 00:03:17.346000 |
|
|
ash_ai | github | 130 | 2025-09-28 00:03:05.360000 |
|
|
maxheadbox | github | 87 | 2025-09-27 00:14:29.826000 |
|
|
qwen-tts | github | 60 | 2025-09-27 00:13:58.548000 |
|
|
Thinkless | github | 230 | 2025-09-27 00:13:54.858000 |
|
|
voyant | github | 66 | 2025-09-27 00:12:30.381000 |
|
|
MegatronApp | github | 67 | 2025-09-27 00:11:33.600000 |
|
|
WebDreamer | github | 82 | 2025-09-27 00:09:25.516000 |
|
|
LMeterX | github | 59 | 2025-09-27 00:08:16.862000 |
|
|
Mapperatorinator | github | 327 | 2025-09-27 00:08:15.519000 |
|
|
agent-sdk-go | github | 248 | 2025-09-27 00:08:10.625000 |
|
|
a2a-java | github | 226 | 2025-09-27 00:07:23.008000 |
|
|
aiconfigurator | github | 68 | 2025-09-27 00:07:06.133000 |
|
|
EScAIP | github | 52 | 2025-09-27 00:07:04.145000 |
|
|
aderyn | github | 618 | 2025-09-27 00:06:45.836000 |
|
|
xpander.ai | github | 728 | 2025-09-27 00:06:23.923000 |
|
|
inspect_evals | github | 236 | 2025-09-27 00:04:53.867000 |
|
|
chonkie | github | 2.4k | 2025-09-27 00:03:45.434000 |
|
|
CoDrivingLLM | github | 54 | 2025-09-26 00:13:32.749000 |
|
|
promptl | github | 71 | 2025-09-26 00:13:23.629000 |
|
|
ome | github | 277 | 2025-09-26 00:12:50.199000 |
|
|
LLaVA-OneVision-1.5 | github | 368 | 2025-09-26 00:12:18.274000 |
|
|
TermNet | github | 61 | 2025-09-26 00:12:08.222000 |
|
|
bagel | github | 335 | 2025-09-26 00:11:47.974000 |
|
|
sparql-llm | github | 63 | 2025-09-26 00:11:46.669000 |
|
|
dream-prompter | github | 106 | 2025-09-26 00:08:19.025000 |
|
|
dranet | github | 111 | 2025-09-26 00:08:08.461000 |
|
|
strwythura | github | 173 | 2025-09-26 00:06:23.826000 |
|
|
zeus | github | 293 | 2025-09-26 00:06:21.882000 |
|
|
Mirror-Flowers | github | 268 | 2025-09-26 00:06:16.092000 |
|
|
OpenSpec | github | 195 | 2025-09-26 00:05:52.391000 |
|
|
open-edison | github | 187 | 2025-09-26 00:05:41.591000 |
|
|
coding-agent-template | github | 275 | 2025-09-26 00:05:35.657000 |
|
|
mslearn-ai-studio | github | 144 | 2025-09-26 00:04:46.579000 |
|
|
tuff | github | 139 | 2025-09-26 00:04:34.850000 |
|
|
shai | github | 349 | 2025-09-26 00:03:45.781000 |
|
|
mcp-apache-spark-history-server | github | 81 | 2025-09-26 00:03:13.711000 |
|
|
slack-mcp-server | github | 696 | 2025-09-25 00:13:42.342000 |
|
|
ai-dj | github | 117 | 2025-09-25 00:13:27.396000 |
|
|
uqlm | github | 1.0k | 2025-09-25 00:13:03.520000 |
|
|
tunix | github | 161 | 2025-09-25 00:12:35.346000 |