
rllm
Democratizing Reinforcement Learning for LLMs
Stars: 4332
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
README:
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads.
[2025/09/16] rLLM v0.2 is now in development and available in preview. It comes integrated with verl-0.5.0, featuring support for Megatron training. Stay tuned for more updates!
[2025/07/01] We release DeepSWE-Preview, a 32B software engineering agent (SWE) trained with purely RL that achieves 59% on SWEBench-Verified with test-time scaling,(42.2% Pass@1), topping the SWEBench leaderboard for open-weight models.
- 🍽️ An In-Depth Blog Post on our SWE Agents and RL Training Recipes
- 🤗 HF Model
DeepSWE-Preview - 🤗 HF Dataset
R2E-Gym-Subset - 📄 Training Scripts
- 📈 Wandb Training Logs—All training runs and ablations.
- 🔎 Evaluation Logs—16 passes over SWE-Bench-Verified.
[2025/04/08] We release DeepCoder-14B-Preview, a 14B coding model that achieves an impressive 60.6% Pass@1 accuracy on LiveCodeBench (+8% improvement), matching the performance of o3-mini-2025-01-031 (Low) and o1-2024-12-17.
[2025/02/10] We release DeepScaleR-1.5B-Preview, a 1.5B model that surpasses O1-Preview and achieves 43.1% Pass@1 on AIME. We achieve this by iteratively scaling Deepseek's GRPO algorithm from 8K→16K->24K context length for thinking.
# Clone the repository
git clone --recurse-submodules https://github.com/rllm-org/rllm.git
cd rllm
# create a conda environment
conda create -n rllm python=3.10 (use python=3.11 for MacOS)
conda activate rllm
# Install all dependencies
pip install -e ./verl
pip install -e .
**Note:** On macOS, GPU features (flash-attn, deepspeed, vllm) are automatically excluded for compatibility. For GPU support on macOS, you can install with: `pip install -e .[gpu]`.For a containerized setup, you can use Docker:
# Build the Docker image
docker build -t rllm .
# Create and start the container
docker create --runtime=nvidia --gpus all --net=host --shm-size="10g" --cap-add=SYS_ADMIN -v .:/workspace/rllm -v /tmp:/tmp --name rllm-container rllm sleep infinity
docker start rllm-container
# Enter the container
docker exec -it rllm-container bash-
Tongyi DeepResearch: A New Era of Open-Source AI Researchers
-
Terminal-Bench-RL: Training Long-Horizon Terminal Agents with Reinforcement Learning


- Our training experiments are powered by our heavily modified fork of verl, an open-source RLHF library.
- Our models are trained on top of
DeepSeek-R1-Distill-Qwen-1.5B,DeepSeek-R1-Distill-Qwen-14B, andQwen3-32B. - Our work is done as part of Berkeley Sky Computing Lab, Berkeley AI Research, and a successful collaboration with Together AI.
Citing rLLM:
@misc{rllm2025,
title={rLLM: A Framework for Post-Training Language Agents},
author={Sijun Tan and Michael Luo and Colin Cai and Tarun Venkat and Kyle Montgomery and Aaron Hao and Tianhao Wu and Arnav Balyan and Manan Roongta and Chenguang Wang and Li Erran Li and Raluca Ada Popa and Ion Stoica},
year={2025},
howpublished={\url{https://pretty-radio-b75.notion.site/rLLM-A-Framework-for-Post-Training-Language-Agents-21b81902c146819db63cd98a54ba5f31}},
note={Notion Blog}
year={2025}
}Citing DeepSWE:
@misc{deepswe2025,
title={DeepSWE: Training a State-of-the-Art Coding Agent from Scratch by Scaling RL},
author={Michael Luo and Naman Jain and Jaskirat Singh and Sijun Tan and Ameen Patel and Qingyang Wu and Alpay Ariyak and Colin Cai and Tarun Venkat and Shang Zhu and Ben Athiwaratkun and Manan Roongta and Ce Zhang and Li Erran Li and Raluca Ada Popa and Koushik Sen and Ion Stoica},
howpublished={\url{https://pretty-radio-b75.notion.site/DeepSWE-Training-a-Fully-Open-sourced-State-of-the-Art-Coding-Agent-by-Scaling-RL-22281902c1468193aabbe9a8c59bbe33}},
note={Notion Blog},
year={2025}
}Citing DeepCoder:
@misc{deepcoder2025,
title={DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level},
author={Michael Luo and Sijun Tan and Roy Huang and Ameen Patel and Alpay Ariyak and Qingyang Wu and Xiaoxiang Shi and Rachel Xin and Colin Cai and Maurice Weber and Ce Zhang and Li Erran Li and Raluca Ada Popa and Ion Stoica},
howpublished={\url{https://pretty-radio-b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini-Level-1cf81902c14680b3bee5eb349a512a51}},
note={Notion Blog},
year={2025}
}Citing DeepScaleR:
@misc{deepscaler2025,
title={DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL},
author={Michael Luo and Sijun Tan and Justin Wong and Xiaoxiang Shi and William Y. Tang and Manan Roongta and Colin Cai and Jeffrey Luo and Li Erran Li and Raluca Ada Popa and Ion Stoica},
year={2025},
howpublished={\url{https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2}},
note={Notion Blog}
year={2025}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rllm
Similar Open Source Tools
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
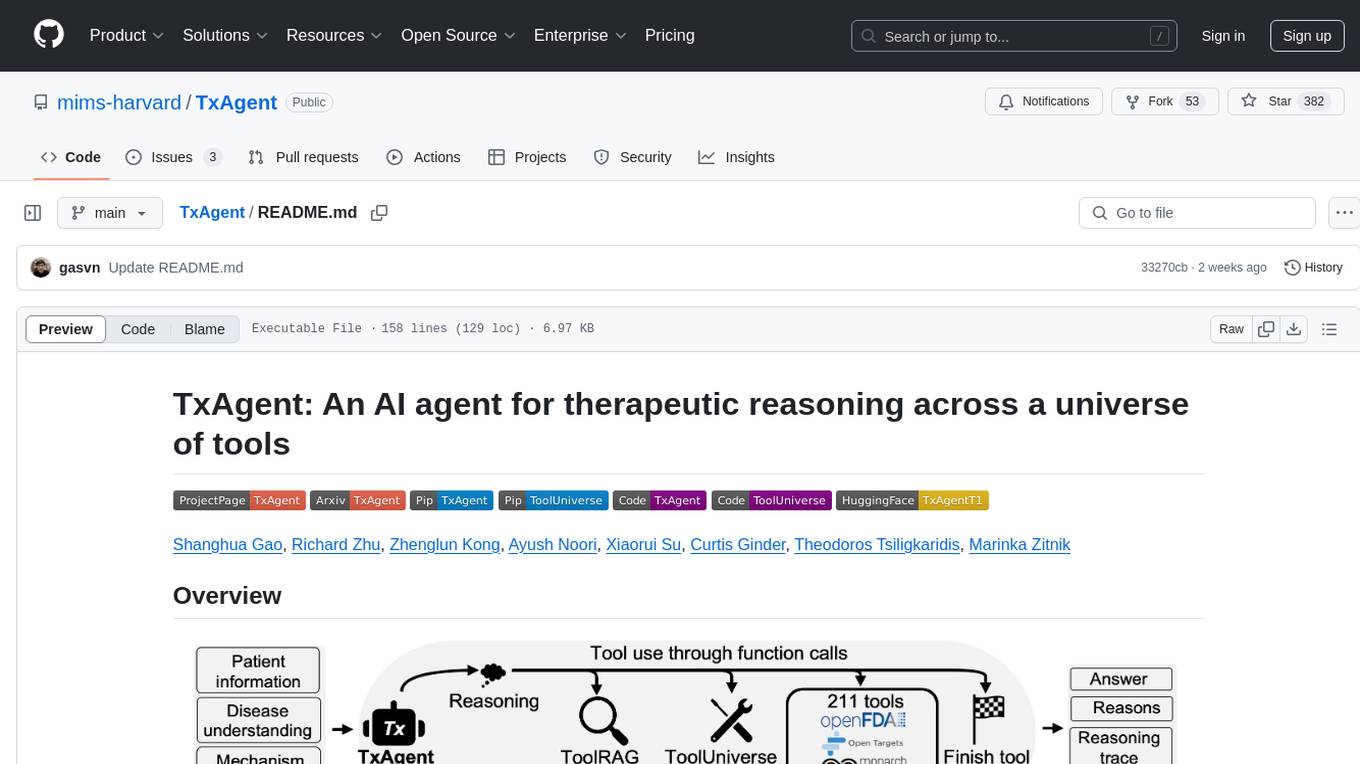
TxAgent
TxAgent is an AI agent designed for precision therapeutics, leveraging multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools. It evaluates drug interactions, contraindications, and tailors treatment strategies to individual patient characteristics. TxAgent outperforms leading models across various drug reasoning tasks and personalized treatment scenarios, ensuring treatment recommendations align with clinical guidelines and real-world evidence.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
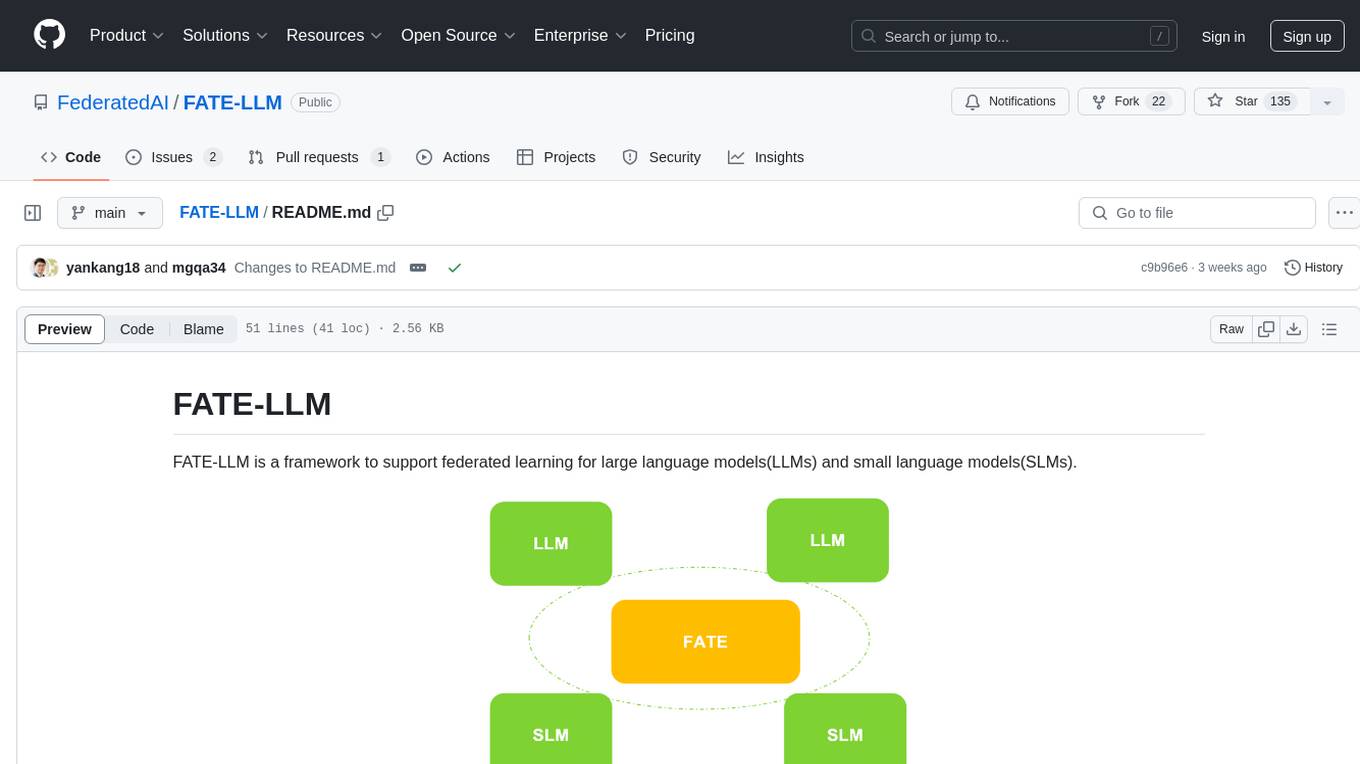
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.

crab
CRAB is a framework for building LLM agent benchmark environments in a Python-centric way. It is cross-platform and multi-environment, allowing the creation of agent environments supporting various deployment options. The framework offers easy-to-use configuration with the ability to add new actions and define environments seamlessly. CRAB also provides a novel benchmarking suite with tasks and evaluators defined in Python, along with a unique graph evaluator method for detailed metrics.
understand-r1-zero
The 'understand-r1-zero' repository focuses on understanding R1-Zero-like training from a critical perspective. It provides insights into base models and reinforcement learning components, highlighting findings and proposing solutions for biased optimization. The repository offers a minimalist recipe for R1-Zero training, detailing the RL-tuning process and achieving state-of-the-art performance with minimal compute resources. It includes codebase, models, and paper related to R1-Zero training implemented with the Oat framework, emphasizing research-friendly and efficient LLM RL techniques.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.

Vision-LLM-Alignment
Vision-LLM-Alignment is a repository focused on implementing alignment training for visual large language models (LLMs), including SFT training, reward model training, and PPO/DPO training. It supports various model architectures and provides datasets for training. The repository also offers benchmark results and installation instructions for users.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
For similar tasks
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
multi-agent-orchestrator
Multi-Agent Orchestrator is a flexible and powerful framework for managing multiple AI agents and handling complex conversations. It intelligently routes queries to the most suitable agent based on context and content, supports dual language implementation in Python and TypeScript, offers flexible agent responses, context management across agents, extensible architecture for customization, universal deployment options, and pre-built agents and classifiers. It is suitable for various applications, from simple chatbots to sophisticated AI systems, accommodating diverse requirements and scaling efficiently.

WindowsAgentArena
Windows Agent Arena (WAA) is a scalable Windows AI agent platform designed for testing and benchmarking multi-modal, desktop AI agents. It provides researchers and developers with a reproducible and realistic Windows OS environment for AI research, enabling testing of agentic AI workflows across various tasks. WAA supports deploying agents at scale using Azure ML cloud infrastructure, allowing parallel running of multiple agents and delivering quick benchmark results for hundreds of tasks in minutes.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.
agent-starter-pack
The agent-starter-pack is a collection of production-ready Generative AI Agent templates built for Google Cloud. It accelerates development by providing a holistic, production-ready solution, addressing common challenges in building and deploying GenAI agents. The tool offers pre-built agent templates, evaluation tools, production-ready infrastructure, and customization options. It also provides CI/CD automation and data pipeline integration for RAG agents. The starter pack covers all aspects of agent development, from prototyping and evaluation to deployment and monitoring. It is designed to simplify project creation, template selection, and deployment for agent development on Google Cloud.

kagent
Kagent is a Kubernetes native framework for building AI agents, designed to be easy to understand and use. It provides a flexible and powerful way to build, deploy, and manage AI agents in Kubernetes. The framework consists of agents, tools, and model configurations defined as Kubernetes custom resources, making them easy to manage and modify. Kagent is extensible, flexible, observable, declarative, testable, and has core components like a controller, UI, engine, and CLI.

motia
Motia is an AI agent framework designed for software engineers to create, test, and deploy production-ready AI agents quickly. It provides a code-first approach, allowing developers to write agent logic in familiar languages and visualize execution in real-time. With Motia, developers can focus on business logic rather than infrastructure, offering zero infrastructure headaches, multi-language support, composable steps, built-in observability, instant APIs, and full control over AI logic. Ideal for building sophisticated agents and intelligent automations, Motia's event-driven architecture and modular steps enable the creation of GenAI-powered workflows, decision-making systems, and data processing pipelines.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.