
Thinkless
[NeurIPS 2025] Thinkless: LLM Learns When to Think
Stars: 230
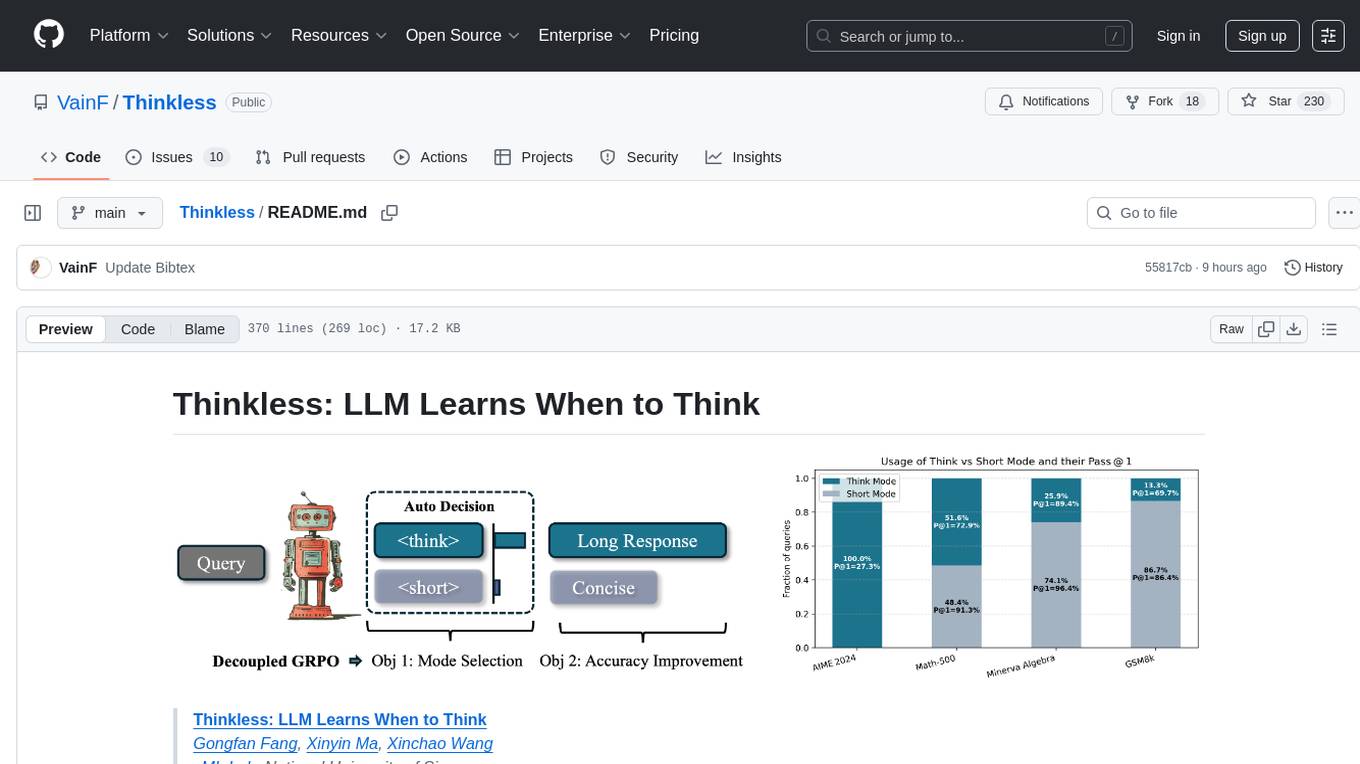
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.
README:

Thinkless: LLM Learns When to Think
Gongfan Fang, Xinyin Ma, Xinchao Wang
xML Lab, National University of Singapore
| 📄 Paper Link | ArXiv |
| 💻 SFT Code | VainF/Reasoning-SFT |
| 🤖 RL Model | Thinkless-1.5B-RL-DeepScaleR |
| 🐣 Warmup Model | Thinkless-1.5B-Warmup |
| 📊 Data for Warmup | Hybrid-OpenThoughts2-1M-1.5B |
| 📊 Data for RL | agentica-org/DeepScaleR-Preview-Dataset |
Can LLMs learn when to think?
We propose Thinkless, a learnable framework that empowers an LLM to adaptively select between short-form and long-form reasoning, based on both task complexity and the model's ability. Thinkless is trained under a reinforcement learning paradigm and employs two control tokens, <short> for concise responses and <think> for detailed reasoning. At the core of our method is a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm, which decomposes the learning objective of hybrid reasoning into two components: (1) a control token loss that governs the selection of the reasoning mode, and (2) a response loss that improves the accuracy of the generated answers. This decoupled formulation enables fine-grained control over the contributions of each objective, stabilizing training and effectively preventing collapse observed in vanilla GRPO. Empirically, on several benchmarks such as Minerva Algebra, MATH-500, and GSM8K, Thinkless is able to reduce the usage of long-chain thinking by 50% - 90%, significantly improving the computational efficiency of Reasoning Language Models.
conda create -n thinkless python==3.10
conda activate thinkless
# For training
cd Thinkless
pip install torch==2.4.0 lm_eval==0.4.8 ray==2.45.0 # install lm_eval before verl to avoid conflict
pip install -e ./verl
pip install -e .
# https://github.com/vllm-project/vllm/issues/4392
pip install nvidia-cublas-cu12==12.4.5.8from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Vinnnf/Thinkless-1.5B-RL-DeepScaleR"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
instruction = "Please reason step by step, and put your final answer within \\boxed{}."
prompt = "The arithmetic mean of 7, 2, $x$ and 10 is 9. What is the value of $x$?"
#prompt = "What is the smallest positive perfect cube that can be written as the sum of three consecutive integers?"
# prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": f"{instruction}\n{prompt}"},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
do_sample=True,
temperature=0.6,
top_p=0.95
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
num_tokens = len(generated_ids[0])
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
think_mode = ("<think>" in response)
print(text+response)
print(f"\nThink Mode: {think_mode}")
print(f"Number of tokens: {num_tokens}")This script will repeat the generation for 5 times using lm_eval. All results will be saved in ./eval_results.
bash run_eval.shWe only use LM-Eval for generation but do not use the built-in answer extractor. Instead, we developed an evaluation tool based on the prompts in openai/simple-evals. To obtain the final metrics, please run the following command:
bash scripts/eval/eval_all.sh YOUR_MODEL_PATH THE_EVAL_RESULTS_PATHFor example, to evaluate the results under eval_results/Vinnnf__Thinkless-1.5B-RL-DeepScaleR, run the following command:
bash scripts/eval/eval_all.sh Vinnnf/Thinkless-1.5B-RL-DeepScaleR eval_results/Vinnnf__Thinkless-1.5B-RL-DeepScaleRscripts/data/prepare_deepscaler_for_RL.pyAIME-24 val data size: 30
DeepScaler data size: 40315
bash run_train_rl.shWe can tune the following hyperparameters in scripts/rl/thinkless_1.5b_deepscaler.sh to obtain a good performance.
# Whether to enable std normalization in advantage computing (False for Dr. GRPO)
algorithm.std_normalizer=False \
# The weight of decoupled control token loss. A higher value will lead to rapid convergence of mode selection.
actor_rollout_ref.actor.thinkless_alpha=0.001 \
# Increase this if you want to encourage thinking mode
thinkless_rewards.correct_think_reward=0.5 \ You can resume training from a checkpoint by modifying the run_train_rl.sh:
export MODEL_PATH="PATH_TO_YOUR_MODEL"
./scripts/rl/thinkless_1.5b_deepscaler.sh --model $MODEL_PATHIt's also recommended to have a new exp name in scripts/rl/thinkless_1.5b_deepscaler.sh:
trainer.experiment_name='Thinkless-1.5b-DeepScaleR-Resume' \
[!TIP] We found that this implementation achieves higher accuracy on short responses and favors conciseness. If this happens, consider increasing correct_think_reward (e.g., from 0.5 to 0.7 or 0.8) and resuming training from your latest checkpoint.
The RL script is able to reproduce the U-shape learning curve.
Our reproducing results using 300 steps with correct_think_reward=0.5, followed by 180 steps (Resumed) with correct_think_reward=0.8:
| AIME 2024 | Minerva Algebra | Math-500 | GSM8k | |
|---|---|---|---|---|
| Paper | 0.2733 (100%) | 0.9459 (26%) | 0.8184 (51%) | 0.8418 (13%) |
| This Codebase | 0.2733 (100%) | 0.9483 (23%) | 0.8360 (51%) | 0.8368 (7%) |
- [ ] Add Resume Training
- [ ] RL on larger-scale datasets (In Progress)
- [ ] 7B model
- [ ] Code for warmup
User:
1+1=?
Thinkless-1.5B (99 Tokens):
<short>
To solve the problem \(1 + 1\), we will follow a step-by-step approach:
1. **Identify the numbers involved**: We have the numbers 1 and 1.
2. **Understand the operation**: The operation we need to perform is addition.
3. **Perform the addition**: When we add 1 and 1 together, we get 2.
So, the final answer is \(\boxed{2}\).
DeepSeek-R1 671B (376 Tokens):
Okay, so I need to figure out what 1 plus 1 equals. Let me start by thinking about basic addition. When you add two numbers together, you're combining their values. So if I have one apple and someone gives me another apple, how many apples do I have in total? That should be two apples.
Wait, let me make sure I'm not missing something here. In the simplest terms, addition is taking two quantities and putting them together. So 1 plus 1 means combining a single unit with another single unit. If I use my fingers, holding up one finger on my left hand and one on my right, then when I put them together, I have two fingers up. That seems right.
But maybe there's a trick to this question. Sometimes problems that look easy might have a different answer depending on the context. For example, in binary, 1 + 1 equals 10. But the question doesn't specify a number system, so I should assume it's in the decimal system, which is the default. So in decimal, 1 + 1 is definitely 2.
Another way to check is by using the number line. Starting at 1, if I move one unit to the right, I land on 2. That confirms it. Or using basic arithmetic rules: the sum of 1 and 1 is the next number in the sequence after 1, which is 2.
I guess there's no ambiguity here. Unless the question is trying to be philosophical or something, but mathematically, it's straightforward. So the answer should be 2.
The sum of 1 and 1 is calculated as follows:
1 + 1 = 2
In decimal arithmetic, adding the numbers 1 and 1 results in the number 2.
DeepSeek-R1-Distill-Qwen-1.5B (1359 Tokens):
<think>
Okay, so I have this simple math problem here: 1 + 1 = ? Hmm, that seems straightforward, but I guess I should think about it carefully to make sure I'm not missing anything. Let me try to visualize it.
First, I know that 1 is just one unit or object. So if I have one apple and someone gives me another apple, how many apples do I have now? Well, I should count them: one, two. So that would make it 2 apples. So, 1 + 1 equals 2. That seems right.
But wait, is there another way to think about this? Maybe using objects or fingers? Let me try using my fingers. If I hold up one finger and then another finger, how many fingers am I up on? One, two. Yep, that's 2 again. So that's consistent with my earlier thought.
Alternatively, maybe I can use my knowledge of numerals. I know that in the decimal system, each numeral represents a certain value. The numeral 1 represents one, and when you add another 1, you're just moving one more step in the counting sequence. So 1 comes after 0, and then 1 again, and so on. So, 1 plus 1 lands me at 2.
Wait, let me think about this in terms of quantities. If I have a set of objects, say two apples, and someone removes one apple, how many are left? That would be 1. So, if I had 1 apple and someone gave me another, I'd have 2. That seems to confirm it.
Is there a different perspective? Maybe using number lines. If I start at 1 and move one unit to the right on the number line, I end up at 2. So, that's another way to visualize addition. 1 + 1 = 2 because moving from 1 to 2 is adding one more.
I also remember in basic arithmetic, addition is commutative, meaning the order doesn't matter. So 1 + 1 is the same as 1 + 1, which is 2. If I switch them around, 1 + 1 is still 2, so that doesn't change anything.
What about if I use different representations? Like, in Roman numerals, 1 is I, and 2 is II. So, I + I would be II, which is 2. That's another way to confirm it.
Wait, maybe I can think about it in terms of equations. If I have an equation: 1 + 1 = x. To solve for x, I can subtract 1 from both sides, so x = 1 + 1 - 1, which simplifies to x = 1. But that doesn't make sense because 1 + 1 is 2, not 1. Maybe I made a mistake in the algebra.
Let me try again. If I have 1 + 1 = x, then subtracting 1 from both sides would give me x = 1. That can't be right because 1 + 1 is definitely 2. So maybe I can't solve it that way. Maybe I need to use a different approach.
Alternatively, maybe I can use the concept of sets. If I have one set with one object and another set with one object, combining them gives me two objects. So, the union of two single-element sets has two elements. Therefore, 1 + 1 equals 2.
I guess another way to think about it is through counting. If I count one thing and then another, I have two in total. So, 1 (first) + 1 (second) = 2 (total). That makes sense.
Is there a real-world example that could help solidify this? Sure. If I have a dollar and I add another dollar, I have $2. So, 1 dollar plus 1 dollar equals 2 dollars. That's a practical application of addition.
What if I use money again? If I have one quarter and I add another quarter, I have 50 cents plus 50 cents, which is 100 cents, or a dollar. So, 1 + 1 = 2 in terms of value. That works too.
Maybe I can also think about it in terms of shapes or objects. If I have one square and another square, how many squares do I have? Two squares. So, 1 + 1 = 2. That's another visual confirmation.
I guess I'm overcomplicating it, but better safe than sorry. Let me try to recall if I've heard this problem before. I think it's a basic arithmetic problem that's been used in various educational settings. It's often used to introduce the concept of addition for young learners.
In summary, through multiple perspectives—counting, using number lines, Roman numerals, set theory, real-world examples, and even different mathematical concepts like commutativity—it consistently points to 1 + 1 = 2. I can't see any other possible answer because the fundamental operations of addition and counting lead to that result.
So, after thinking it through in so many different ways, I feel confident that 1 + 1 equals 2.
**Final Answer**
The result of 1 + 1 is \boxed{2}.
</think>
To solve the problem \(1 + 1\), we can approach it from various perspectives:
1. **Counting Objects**: If we have one object and add another, we count them: one, two. Thus, \(1 + 1 = 2\).
2. **Number Lines**: Starting at 1 and moving one unit to the right on the number line lands us at 2. Hence, \(1 + 1 = 2\).
3. **Roman Numerals**: In Roman numerals, I (1) + I (1) equals II (2).
4. **Set Theory**: Combining two single-element sets results in a set with two elements, so \(1 + 1 = 2\).
5. **Real-World Examples**: Adding two dollars gives a total of two dollars, demonstrating \(1 + 1 = 2\).
6. **Commutative Property**: Since addition is commutative, \(1 + 1 = 1 + 1 = 2\).
Through multiple perspectives, the result is consistently 2.
### Final Answer
The result of \(1 + 1\) is \boxed{2}.
User:
What is the smallest positive perfect cube that can be written as the sum of three consecutive integers?
Thinkless-1.5B:
Note: The long reasoning process is omitted.
<think>
Okay, let's try to figure out the smallest positive perfect cube that can be written as the sum of three consecutive integers. Hmm, let's start by understanding the problem step by step.
First, a perfect cube is a number raised to the power of 3. So, we need to find the smallest positive integer \( n \) such that \( n = a + (a+1) + (a+2) \), where \( a \) is an integer. Then, \( n \) should also be a perfect cube. Let me write that down:
\( n = a + (a+1) + (a+2) \)
...
Next, 27:
Is 27 a perfect cube? Yes, \( 3^3 = 27 \). Let's check:
...
**Final Answer**
The smallest positive perfect cube that can be written as the sum of three consecutive integers is \boxed{27}.
</think>
To find the smallest positive perfect cube that can be written as the sum of three consecutive integers, we start by expressing the sum of three consecutive integers. Let the three consecutive integers be \( a \), \( a+1 \), and \( a+2 \). Their sum is:
\[
a + (a+1) + (a+2) = 3a + 3
\]
This sum must be a perfect cube. Let \( n \) be the perfect cube, so we have:
\[
n = 3(a + 1)
\]
Thus, \( n \) must be a multiple of 3. The smallest perfect cubes are 1, 8, 27, 64, 125, etc. We check each of these to see if they can be written as \( 3(a + 1) \):
- For \( n = 1 \): \( 3(a + 1) = 1 \) gives \( a = -\frac{2}{3} \), not an integer.
- For \( n = 8 \): \( 3(a + 1) = 8 \) gives \( a = \frac{5}{3} \), not an integer.
- For \( n = 27 \): \( 3(a + 1) = 27 \) gives \( a = 8 \), which is an integer. The three consecutive integers are 8, 9, and 10, and their sum is \( 8 + 9 + 10 = 27 \).
Checking the next perfect cubes (64, 125, etc.) confirms they do not yield integer values for \( a \). Therefore, the smallest positive perfect cube that can be written as the sum of three consecutive integers is:
\[
\boxed{27}
\]
- The RL part is based on the agentica-project/rllm (Previously named DeepScaleR).
- The warmup training is powered by Megatron-LM. We will release the a llama-factory version in the future.
- The following datasets are used in our experiments:
- DeepScaleR: For RL training.
- OpenThoughts2-1M: For warmup training.
If you find this repository helpful, please consider citing our work:
@article{fang2025thinkless,
title={Thinkless: LLM Learns When to Think},
author={Fang, Gongfan and Ma, Xinyin and Wang, Xinchao},
journal={Advances in neural information processing systems},
year={2025}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Thinkless
Similar Open Source Tools
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.
skyrim
Skyrim is a weather forecasting tool that enables users to run large weather models using consumer-grade GPUs. It provides access to state-of-the-art foundational weather models through a well-maintained infrastructure. Users can forecast weather conditions, such as wind speed and direction, by running simulations on their own GPUs or using modal volume or cloud services like s3 buckets. Skyrim supports various large weather models like Graphcast, Pangu, Fourcastnet, and DLWP, with plans for future enhancements like ensemble prediction and model quantization.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.
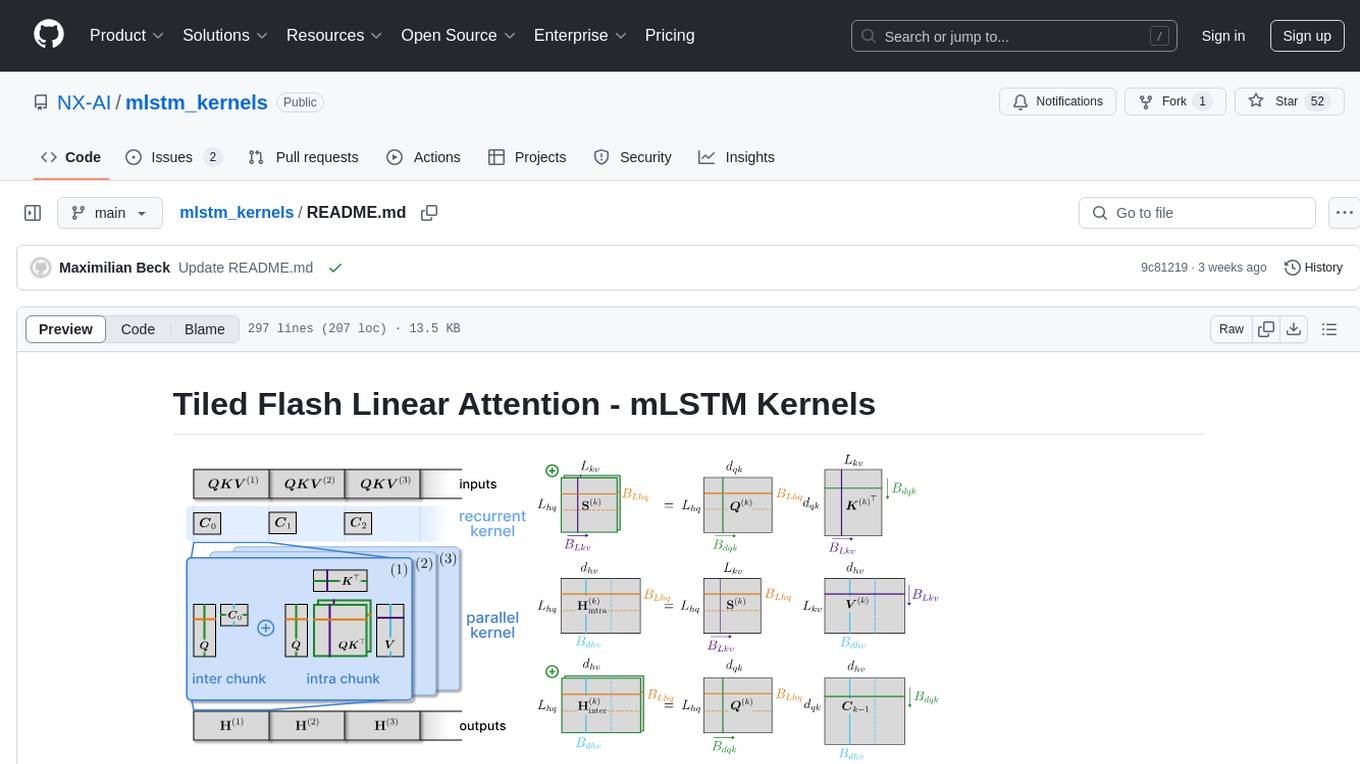
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.

instructor-php
Instructor for PHP is a library designed for structured data extraction in PHP, powered by Large Language Models (LLMs). It simplifies the process of extracting structured, validated data from unstructured text or chat sequences. Instructor enhances workflow by providing a response model, validation capabilities, and max retries for requests. It supports classes as response models and provides features like partial results, string input, extracting scalar and enum values, and specifying data models using PHP type hints or DocBlock comments. The library allows customization of validation and provides detailed event notifications during request processing. Instructor is compatible with PHP 8.2+ and leverages PHP reflection, Symfony components, and SaloonPHP for communication with LLM API providers.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
For similar tasks
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.