
Mapperatorinator
An AI-driven framework for generating and modding osu! beatmaps for all gamemodes from spectrogram inputs.
Stars: 327

Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
README:
Try the generative model here, or MaiMod here. Check out a video showcase here.
Mapperatorinator is multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The goal of this project is to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability.
This project is built upon osuT5 and osu-diffusion. In developing this, I spent about 2500 hours of GPU compute across 142 runs on my 4060 Ti and rented 4090 instances on vast.ai.
The instruction below allows you to generate beatmaps on your local machine, alternatively you can run it in the cloud with the colab notebook.
git clone https://github.com/OliBomby/Mapperatorinator.git
cd MapperatorinatorUse Python 3.10, later versions will might not be compatible with the dependencies.
python -m venv .venv
# In cmd.exe
.venv\Scripts\activate.bat
# In PowerShell
.venv\Scripts\Activate.ps1
# In Linux or MacOS
source .venv/bin/activate-
Python 3.10
-
PyTorch: Make sure to follow the Get Started guide so you install
torchandtorchaudiowith GPU support. -
and the remaining Python dependencies:
pip install -r requirements.txtFor a more user-friendly experience, consider using the Web UI. It provides a graphical interface to configure generation parameters, start the process, and monitor the output.
Navigate to the cloned Mapperatorinator directory in your terminal and run:
python web-ui.pyThis will start a local web server and automatically open the UI in a new window.
-
Configure: Set input/output paths using the form fields and "Browse" buttons. Adjust generation parameters like gamemode, difficulty, style (year, mapper ID, descriptors), timing, specific features (hitsounds, super timing), and more, mirroring the command-line options. (Note: If you provide a
beatmap_path, the UI will automatically determine theaudio_pathandoutput_pathfrom it, so you can leave those fields blank) - Start: Click the "Start Inference" button to begin the beatmap generation.
- Cancel: You can stop the ongoing process using the "Cancel Inference" button.
- Open Output: Once finished, use the "Open Output Folder" button for quick access to the generated files.
The Web UI acts as a convenient wrapper around the inference.py script. For advanced options or troubleshooting, refer to the command-line instructions.
For users who prefer the command line or need access to advanced configurations, follow the steps below. Note: For a simpler graphical interface, please see the Web UI (Recommended) section above.
Run inference.py and pass in some arguments to generate beatmaps. For this use Hydra override syntax. See configs/inference_v29.yaml for all available parameters.
python inference.py \
audio_path [Path to input audio] \
output_path [Path to output directory] \
beatmap_path [Path to .osu file to autofill metadata, and output_path, or use as reference] \
gamemode [Game mode to generate 0=std, 1=taiko, 2=ctb, 3=mania] \
difficulty [Difficulty star rating to generate] \
mapper_id [Mapper user ID for style] \
year [Upload year to simulate] \
hitsounded [Whether to add hitsounds] \
slider_multiplier [Slider velocity multiplier] \
circle_size [Circle size] \
keycount [Key count for mania] \
hold_note_ratio [Hold note ratio for mania 0-1] \
scroll_speed_ratio [Scroll speed ratio for mania and ctb 0-1] \
descriptors [List of beatmap user tags for style] \
negative_descriptors [List of beatmap user tags for classifier-free guidance] \
add_to_beatmap [Whether to add generated content to the reference beatmap instead of making a new beatmap] \
start_time [Generation start time in milliseconds] \
end_time [Generation end time in milliseconds] \
in_context [List of additional context to provide to the model [NONE,TIMING,KIAI,MAP,GD,NO_HS]] \
output_type [List of content types to generate] \
cfg_scale [Scale of the classifier-free guidance] \
super_timing [Whether to use slow accurate variable BPM timing generator] \
seed [Random seed for generation] \
Example:
python inference.py beatmap_path="'C:\Users\USER\AppData\Local\osu!\Songs\1 Kenji Ninuma - DISCO PRINCE\Kenji Ninuma - DISCOPRINCE (peppy) [Normal].osu'" gamemode=0 difficulty=5.5 year=2023 descriptors="['jump aim','clean']" in_context=[TIMING,KIAI]
For those who prefer a terminal-based workflow but want a guided setup, the interactive CLI script is an excellent alternative to the Web UI.
Navigate to the cloned directory. You may need to make the script executable first.
# Make the script executable (only needs to be done once)
chmod +x cli_inference.sh# Run the script
./cli_inference.shThe script will walk you through a series of prompts to configure all generation parameters, just like the Web UI.
It uses a color-coded interface for clarity. It provides an advanced multi-select menu for choosing style descriptors using your arrow keys and spacebar. After you've answered all the questions, it will display the final command for your review. You can then confirm to execute it directly or cancel and copy the command for manual use.
- You can edit
configs/inference_v29.yamland add your arguments there instead of typing them in the terminal every time. - All available descriptors can be found here.
- Always provide a year argument between 2007 and 2023. If you leave it unknown, the model might generate with an inconsistent style.
- Always provide a difficulty argument. If you leave it unknown, the model might generate with an inconsistent difficulty.
- Increase the
cfg_scaleparameter to increase the effectiveness of themapper_idanddescriptorsarguments. - You can use the
negative_descriptorsargument to guide the model away from certain styles. This only works whencfg_scale > 1. Make sure the number of negative descriptors is equal to the number of descriptors. - If your song style and desired beatmap style don't match well, the model might not follow your directions. For example, its hard to generate a high SR, high SV beatmap for a calm song.
- If you already have timing and kiai times done for a song, then you can give this to the model to greatly increase inference speed and accuracy: Use the
beatmap_pathandin_context=[TIMING,KIAI]arguments. - To remap just a part of your beatmap, use the
beatmap_path,start_time,end_time, andadd_to_beatmap=truearguments. - To generate a guest difficulty for a beatmap, use the
beatmap_pathandin_context=[GD,TIMING,KIAI]arguments. - To generate hitsounds for a beatmap, use the
beatmap_pathandin_context=[NO_HS,TIMING,KIAI]arguments. - To generate only timing for a song, use the
super_timing=trueandoutput_type=[TIMING]arguments.
MaiMod is a modding tool for osu! beatmaps that uses Mapperatorinator predictions to find potential faults and inconsistencies which can't be detected by other automatic modding tools like Mapset Verifier. It can detect issues like:
- Incorrect snapping or rhythmic patterns
- Inaccurate timing points
- Inconsistent hit object positions or new combo placements
- Weird slider shapes
- Inconsistent hitsounds or volumes
You can try MaiMod here, or run it locally:
To run MaiMod locally, you'll need to install Mapperatorinator. Then, run the mai_mod.py script, specifying your beatmap's path with the beatmap_path argument.
python mai_mod.py beatmap_path="'C:\Users\USER\AppData\Local\osu!\Songs\1 Kenji Ninuma - DISCO PRINCE\Kenji Ninuma - DISCOPRINCE (peppy) [Normal].osu'"This will print the modding suggestions to the console, which you can then apply to your beatmap manually. Suggestions are ordered chronologically and grouped into categories. The first value in the circle indicates the 'surprisal' which is a measure of how unexpected the model found the issue to be, so you can prioritize the most important issues.
The model can make mistakes, especially on low surprisal issues, so always double-check the suggestions before applying them to your beatmap. The main goal is to help you narrow down the search space for potential issues, so you don't have to manually check every single hit object in your beatmap.
To run the MaiMod Web UI, you'll need to install Mapperatorinator.
Then, run the mai_mod_ui.py script. This will start a local web server and automatically open the UI in a new window:
python mai_mod_ui.pyMapperatorinator converts osu! beatmaps into an intermediate event representation that can be directly converted to and from tokens. It includes hit objects, hitsounds, slider velocities, new combos, timing points, kiai times, and taiko/mania scroll speeds.
Here is a small examle of the tokenization process:
To save on vocabulary size, time events are quantized to 10ms intervals and position coordinates are quantized to 32 pixel grid points.
The model is basically a wrapper around the HF Transformers Whisper model, with custom input embeddings and loss function. Model size amounts to 219M parameters. This model was found to be faster and more accurate than T5 for this task.
The high-level overview of the model's input-output is as follows:

The model uses Mel spectrogram frames as encoder input, with one frame per input position. The model decoder output at each step is a softmax distribution over a discrete, predefined, vocabulary of events. Outputs are sparse, events are only needed when a hit-object occurs, instead of annotating every single audio frame.
Before the SOS token are additional tokens that facilitate conditional generation. These tokens include the gamemode, difficulty, mapper ID, year, and other metadata. During training, these tokens do not have accompanying labels, so they are never output by the model. Also during training there is a random chance that a metadata token gets replaced by an 'unknown' token, so during inference we can use these 'unknown' tokens to reduce the amount of metadata we have to give to the model.
The context length of the model is 8.192 seconds long. This is obviously not enough to generate a full beatmap, so we have to split the song into multiple windows and generate the beatmap in small parts. To make sure that the generated beatmap does not have noticeable seams in between windows, we use a 90% overlap and generate the windows sequentially. Each generation window except the first starts with the decoder pre-filled up to 50% of the generation window with tokens from the previous windows. We use a logit processor to make sure that the model can't generate time tokens that are in the first 50% of the generation window. Additionally, the last 40% of the generation window is reserved for the next window. Any generated time tokens in that range are treated as EOS tokens. This ensures that each generated token is conditioned on at least 4 seconds of previous tokens and 3.3 seconds of future audio to anticipate.
To prevent offset drifting during long generation, random offsets have been added to time events in the decoder during training. This forces it to correct timing errors by listening to the onsets in the audio instead, and results in a consistently accurate offset.
Position coordinates generated by the decoder are quantized to 32 pixel grid points, so afterward we use diffusion to denoise the coordinates to the final positions. For this we trained a modified version of osu-diffusion that is specialized to only the last 10% of the noise schedule, and accepts the more advanced metadata tokens that Mapperatorinator uses for conditional generation.
Since the Mapperatorinator model outputs the SV of sliders, the required length of the slider is fixed regardless of the shape of the control point path. Therefore, we try to guide the diffusion process to create coordinates that fit the required slider lengths. We do this by recalculating the slider end positions after every step of the diffusion process based on the required length and the current control point path. This means that the diffusion process does not have direct control over the slider end positions, but it can still influence them by changing the control point path.
Mapperatorinator does some extra post-processing to improve the quality of the generated beatmap:
- Refine position coordinates with diffusion.
- Resnap time events to the nearest tick using the snap divisors generated by the model.
- Snap near-perfect positional overlaps.
- Convert mania column events to X coordinates.
- Generate slider paths for taiko drumrolls.
- Fix big discrepancies in required slider length and control point path length.
Super timing generator is an algorithm that improves the precision and accuracy of generated timing by infering timing for the whole song 20 times and averaging the results. This is useful for songs with variable BPM, or songs with BPM changes. The result is almost perfect with only sometimes a section that needs manual adjustment.
The instruction below creates a training environment on your local machine.
git clone https://github.com/OliBomby/Mapperatorinator.git
cd MapperatorinatorCreate your own dataset using the Mapperator console app. It requires an osu! OAuth client token to verify beatmaps and get additional metadata. Place the dataset in a datasets directory next to the Mapperatorinator directory.
Mapperator.ConsoleApp.exe dataset2 -t "/Mapperatorinator/datasets/beatmap_descriptors.csv" -i "path/to/osz/files" -o "/datasets/cool_dataset"Create an account on Weight & Biases and get your API key from your account settings.
Then set the WANDB_API_KEY environment variable, so the training process knows to log to this key.
export WANDB_API_KEY=<your_api_key>Training in your venv is also possible, but we recommend using Docker on WSL for better performance.
docker compose up -d --force-recreate
docker attach mapperatorinator_space
cd MapperatorinatorAll configurations are located in ./configs/train/default.yaml.
Make sure to set the correct train_dataset_path and test_dataset_path to your dataset, as well as the start and end mapset indices for train/test split.
The path is local to the docker container, so if you placed your dataset called cool_dataset into the datasets directory, then it should be /workspace/datasets/cool_dataset.
I recommend making a custom config file that overrides the default config, so you have a record of your training config for reproducibility.
data:
train_dataset_path: "/workspace/datasets/cool_dataset"
test_dataset_path: "/workspace/datasets/cool_dataset"
train_dataset_start: 0
train_dataset_end: 90
test_dataset_start: 90
test_dataset_end: 100Begin training by calling python osuT5/train.py or torchrun --nproc_per_node=NUM_GPUS osuT5/train.py for multi-GPU training.
python osuT5/train.py -cn train_v29 train_dataset_path="/workspace/datasets/cool_dataset" test_dataset_path="/workspace/datasets/cool_dataset" train_dataset_end=90 test_dataset_start=90 test_dataset_end=100You can also fine-tune a pre-trained model with LoRA to adapt it to a specific style or gamemode.
To do this, adapt configs/train/lora.yaml to your needs and run the lora training config:
python osuT5/train.py -cn lora train_dataset_path="/workspace/datasets/cool_dataset" test_dataset_path="/workspace/datasets/cool_dataset" train_dataset_end=90 test_dataset_start=90 test_dataset_end=100Important LoRA parameters to consider:
-
pretrained_path: Path or HF repo of the base model to fine-tune. -
r: Rank of the LoRA matrices. Higher values increase model capacity but also memory usage. -
lora_alpha: Scaling factor for the LoRA updates. -
total_steps: Total number of training steps. Balance this according to your dataset size. -
enable_lora: Whether to use LoRA or full model fine-tuning.
During inference, you can specify the LoRA weights to use with the lora_path argument.
This can be a local path or a Hugging Face repo.
Special thanks to:
- The authors of osuT5 for their training code.
- Hugging Face team for their tools.
- Jason Won and Richard Nagyfi for bouncing ideas.
- Marvin for donating training credits.
- The osu! community for the beatmaps.
- osu! Beatmap Generator by Syps (Nick Sypteras)
- osumapper by kotritrona, jyvden, Yoyolick (Ryan Zmuda)
- osu-diffusion by OliBomby (Olivier Schipper), NiceAesth (Andrei Baciu)
- osuT5 by gyataro (Xiwen Teoh)
- Beat Learning by sedthh (Richard Nagyfi)
- osu!dreamer by jaswon (Jason Won)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Mapperatorinator
Similar Open Source Tools
Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
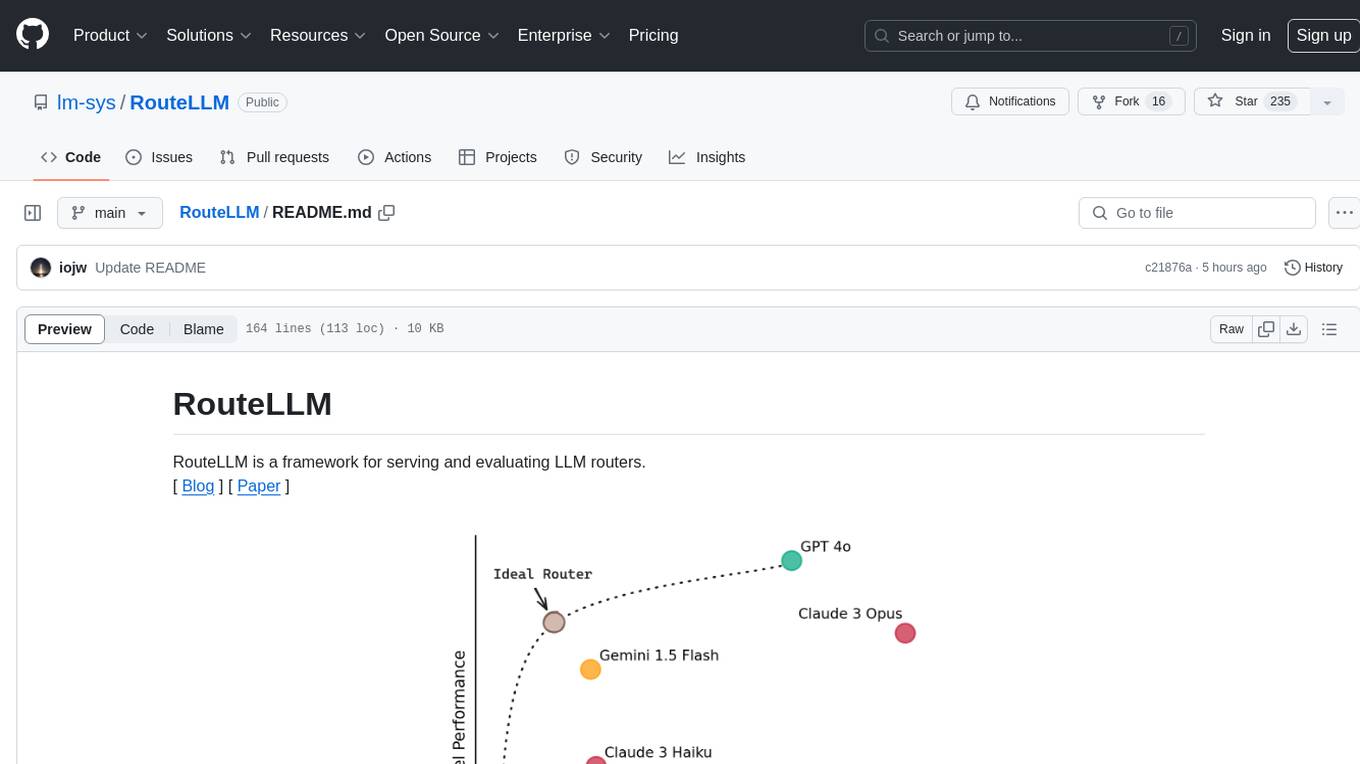
RouteLLM
RouteLLM is a framework for serving and evaluating LLM routers. It allows users to launch an OpenAI-compatible API that routes requests to the best model based on cost thresholds. Trained routers are provided to reduce costs while maintaining performance. Users can easily extend the framework, compare router performance, and calibrate cost thresholds. RouteLLM supports multiple routing strategies and benchmarks, offering a lightweight server and evaluation framework. It enables users to evaluate routers on benchmarks, calibrate thresholds, and modify model pairs. Contributions for adding new routers and benchmarks are welcome.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
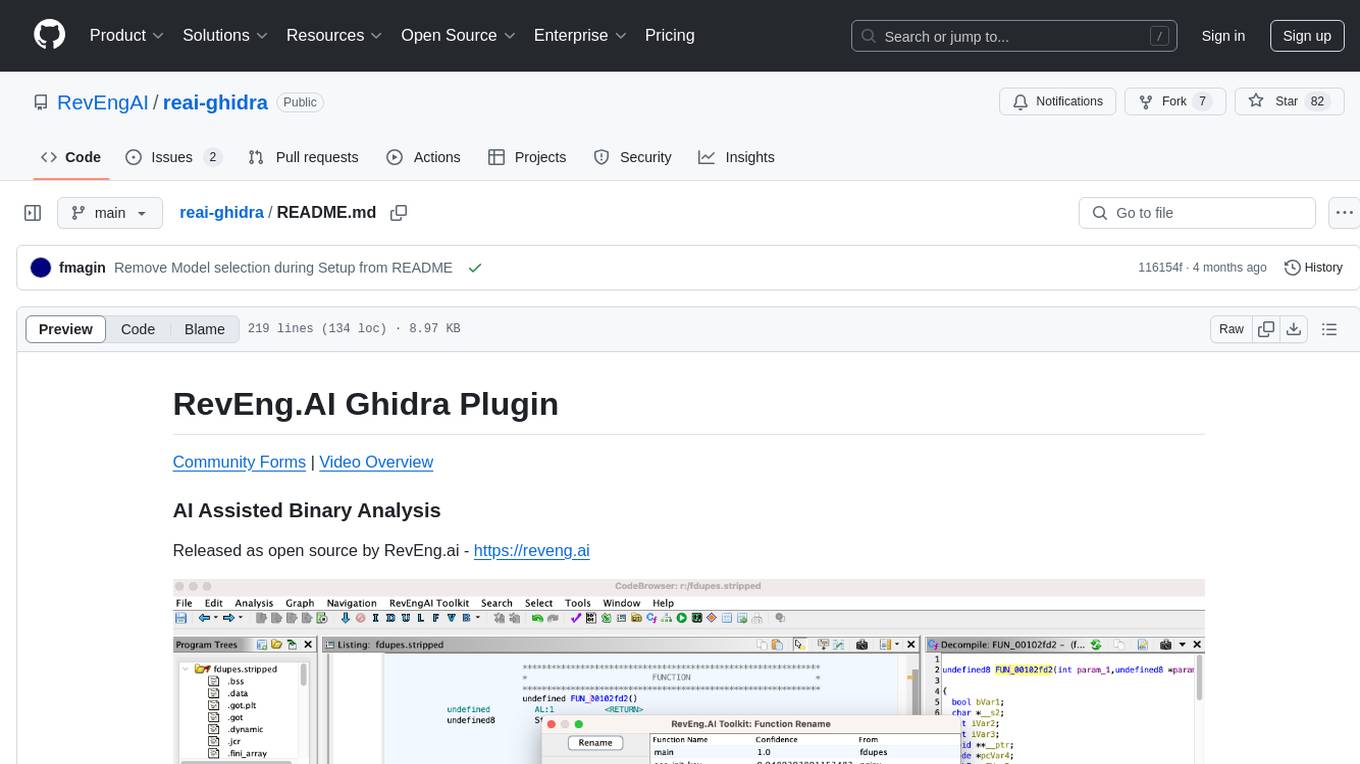
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
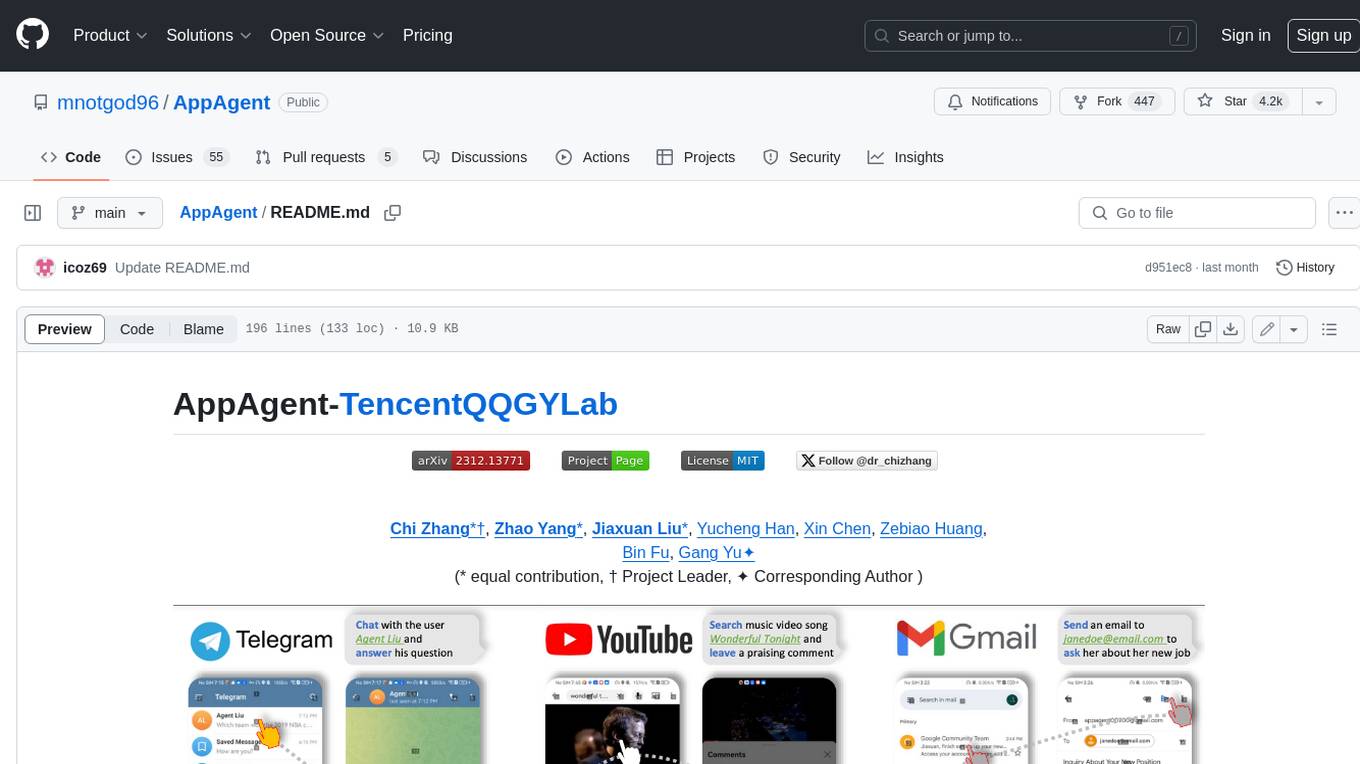
AppAgent
AppAgent is a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.
langgraph-studio
LangGraph Studio is a specialized agent IDE that enables visualization, interaction, and debugging of complex agentic applications. It offers visual graphs and state editing to better understand agent workflows and iterate faster. Users can collaborate with teammates using LangSmith to debug failure modes. The tool integrates with LangSmith and requires Docker installed. Users can create and edit threads, configure graph runs, add interrupts, and support human-in-the-loop workflows. LangGraph Studio allows interactive modification of project config and graph code, with live sync to the interactive graph for easier iteration on long-running agents.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
For similar tasks
Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.