
exllamav3
An optimized quantization and inference library for running LLMs locally on modern consumer-class GPUs
Stars: 511
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.
README:
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. Headline features:
- New EXL3 quantization format based on QTIP
- Flexible tensor-parallel and expert-parallel inference for consumer hardware setups
- OpenAI-compatible server provided via TabbyAPI
- Continuous, dynamic batching
- HF Transformers plugin (see here)
- HF model support (see supported architectures)
- Speculative decoding
- 2-8 bit cache quantization
- Multimodal support
The official and recommended backend server for ExLlamaV3 is TabbyAPI, which provides an OpenAI-compatible API for local or remote inference, with extended features like HF model downloading, embedding model support and support for HF Jinja2 chat templates.
- Qwen3-Next support is currently experimental and still requires profiling and optimization, so don't expect optimal performance just yet. Flash Linear Attention is required and this in turn requires Triton. causal-conv1d is supported and recommended but not required.
- AFM (ArceeForCausalLM)
- Apertus (ApertursForCausalLM)
- Command-R etc. (CohereForCausalLM)
- Command-A, Command-R7B, Command-R+ etc. (Cohere2ForCausalLM)
- DeciLM, Nemotron (DeciLMForCausalLM)
- dots.llm1 (Dots1ForCausalLM)
- ERNIE 4.5 (Ernie4_5_ForCausalLM, Ernie4_5_MoeForCausalLM)
- EXAONE 4.0 (Exaone4ForCausalLM)
- Gemma 2 (Gemma2ForCausalLM)
- Gemma 3 (Gemma3ForCausalLM, Gemma3ForConditionalGeneration) - multimodal
- GLM 4, GLM 4.5, GLM 4.5-Air, (Glm4ForCausalLM, Glm4MoeForCausalLM)
- Llama, Llama 2, Llama 3, Llama 3.1-Nemotron etc. (LlamaForCausalLM)
- MiMo-RL (MiMoForCausalLM)
- Mistral, Mistral 3 etc. (MistralForCausalLM, Mistral3ForConditionalGeneration) - multimodal
- Mixtral (MixtralForCausalLM)
- Phi3, Phi4 (Phi3ForCausalLM)
- Qwen 2, Qwen 2.5 (Qwen2ForCausalLM)
- Qwen 3 (Qwen3ForCausalLM, Qwen3MoeForCausalLM)
- Qwen 3-Next (Qwen3NextForCausalLM)
- Seed-OSS (SeedOssForCausalLM)
- SmolLM (SmolLM3ForCausalLM)
Always adding more, stay tuned.
Currently on the to-do list:
- Lots of optimization
- LoRA support
- ROCm support
- More sampling functions
- More quantization modes (FP4 etc.)
As for what is implemented, expect that some things may be a little broken at first. Please be patient, raise issues and/or contribute. 👉👈
TabbyAPI has a startup script that manages and installs prerequisites if you want to get started quickly with inference in an OAI-compatible client.
Otherwise, start by making sure you have the appropriate version of PyTorch installed (CUDA 12.4 or later) since the Torch dependency is not automatically handled by pip. Then pick a method below:
Pick a wheel from the releases page, then e.g.:
pip install https://github.com/turboderp-org/exllamav3/releases/download/v0.0.6/exllamav3-0.0.6+cu128.torch2.8.0-cp313-cp313-linux_x86_64.whlpip install exllamav3Note that the PyPi package does not contain a prebuilt extension and requires the CUDA toolkit and build prerequisites (i.e. VS Build Tools on Windows, gcc on Linux, python-dev headers etc.).
# Clone the repo
git clone https://github.com/turboderp-org/exllamav3
cd exllamav3
# (Optional) switch to dev branch for latest in-progress features
git checkout dev
# Install requirements (make sure you install Torch separately)
pip install -r requirements.txtAt this point you should be able to run the conversion, eval and example scripts from the main repo directory, e.g. python convert.py -i ...
To install the library for the active venv, run from the repo directory:
pip install .Relevant env variables for building:
-
MAX_JOBS: by default ninja may launch too many processes and run out of system memory for compilation. Set this to a reasonable value like 4 in that case. -
EXLLAMA_NOCOMPILE: set to install the library without compiling the C++/CUDA extension. Torch will build/load it at runtime instead.
To convert a model to EXL3 format, use:
# Convert model
python convert.py -i <input_dir> -o <output_dir> -w <working_dir> -b <bitrate>
# Resume an interrupted quant job
python convert.py -w <working_dir> -r
# More options
python convert.py -hThe working directory is temporary storage for state checkpoints and for storing quantized tensors until the converted model can be compiled. It should have enough free space to store an entire copy of the output model. Note that while EXL2 conversion by default resumes an interrupted job when pointed to an existing folder, EXL3 needs you to explicitly resume with the -r/--resume argument.
See here for more information.
A number of example scripts are provided to showcase the features of the backend and generator. Some of them have hardcoded model paths and should be edited before you run them, but there is a simple CLI chatbot that you can start with:
python examples/chat.py -m <input_dir> -mode <prompt_mode>
# E.g.:
python examples/chat.py -m /mnt/models/llama3.1-8b-instruct-exl3 -mode llama3
# Wealth of options
python examples/chat.py -h
Despite their amazing achievements, most SOTA quantization techniques remain cumbersome or even prohibitively expensive to use. For instance, AQLM quantization of a 70B model takes around 720 GPU-hours on an A100 server, costing $850 US at the time of writing. ExLlamaV3 aims to address this with the EXL3 format, which is a streamlined variant of QTIP from Cornell RelaxML. The conversion process is designed to be simple and efficient and requires only an input model (in HF format) and a target bitrate. By computing Hessians on the fly and thanks to a fused Viterbi kernel, the quantizer can convert a model in a single step, taking a couple of minutes for smaller models, up to a few hours for larger ones (70B+) (on a single RTX 4090 or equivalent GPU.)
The Marlin-inspired GEMM kernel achieves roughly memory-bound latency under optimal conditions (4bpw, RTX 4090), though it still needs some work to achieve the same efficiency on Ampere GPUs and to remain memory-bound at lower bitrates.
Since converted models largely retain the original file structure (unlike EXL2 which renames some tensors in its quest to turn every model into a Llama variant), it will be possible to extend EXL3 support to other frameworks like HF Transformers and vLLM.
There are some benchmark results here, and a full writeup on the format is coming soon.
Fun fact: Llama-3.1-70B-EXL3 is coherent at 1.6 bpw. With the output layer quantized to 3 bpw and a 4096-token cache, inference is possible in under 16 GB of VRAM.
You are always welcome to join the ExLlama discord server ←🎮
A selection of EXL3-quantized models is available here. Also shout out the following lovely people:
This project owes its existence to a wonderful community of FOSS developers and some very generous supporters (🐈❤️!) The following projects in particular deserve a special mention:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for exllamav3
Similar Open Source Tools
exllamav3
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
FunGen-AI-Powered-Funscript-Generator
FunGen is a Python-based tool that uses AI to generate Funscript files from VR and 2D POV videos. It enables fully automated funscript creation for individual scenes or entire folders of videos. The tool includes features like automatic system scaling support, quick installation guides for Windows, Linux, and macOS, manual installation instructions, NVIDIA GPU setup, AMD GPU acceleration, YOLO model download, GUI settings, GitHub token setup, command-line usage, modular systems for funscript filtering and motion tracking, performance and parallel processing tips, and more. The project is still in early development stages and is not intended for commercial use.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
kheish
Kheish is an open-source, multi-role agent designed for complex tasks that require structured, step-by-step collaboration with Large Language Models (LLMs). It acts as an intelligent agent that can request modules on demand, integrate user feedback, switch between specialized roles, and deliver refined results. By harnessing multiple 'sub-agents' within one framework, Kheish tackles tasks like security audits, file searches, RAG-based exploration, and more.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.
restai
RestAI is an AIaaS (AI as a Service) platform that allows users to create and consume AI agents (projects) using a simple REST API. It supports various types of agents, including RAG (Retrieval-Augmented Generation), RAGSQL (RAG for SQL), inference, vision, and router. RestAI features automatic VRAM management, support for any public LLM supported by LlamaIndex or any local LLM supported by Ollama, a user-friendly API with Swagger documentation, and a frontend for easy access. It also provides evaluation capabilities for RAG agents using deepeval.
heurist-agent-framework
Heurist Agent Framework is a flexible multi-interface AI agent framework that allows processing text and voice messages, generating images and videos, interacting across multiple platforms, fetching and storing information in a knowledge base, accessing external APIs and tools, and composing complex workflows using Mesh Agents. It supports various platforms like Telegram, Discord, Twitter, Farcaster, REST API, and MCP. The framework is built on a modular architecture and provides core components, tools, workflows, and tool integration with MCP support.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
clearml-server
ClearML Server is a backend service infrastructure for ClearML, facilitating collaboration and experiment management. It includes a web app, RESTful API, and file server for storing images and models. Users can deploy ClearML Server using Docker, AWS EC2 AMI, or Kubernetes. The system design supports single IP or sub-domain configurations with specific open ports. ClearML-Agent Services container allows launching long-lasting jobs and various use cases like auto-scaler service, controllers, optimizer, and applications. Advanced functionality includes web login authentication and non-responsive experiments watchdog. Upgrading ClearML Server involves stopping containers, backing up data, downloading the latest docker-compose.yml file, configuring ClearML-Agent Services, and spinning up docker containers. Community support is available through ClearML FAQ, Stack Overflow, GitHub issues, and email contact.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.
For similar tasks
exllamav3
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
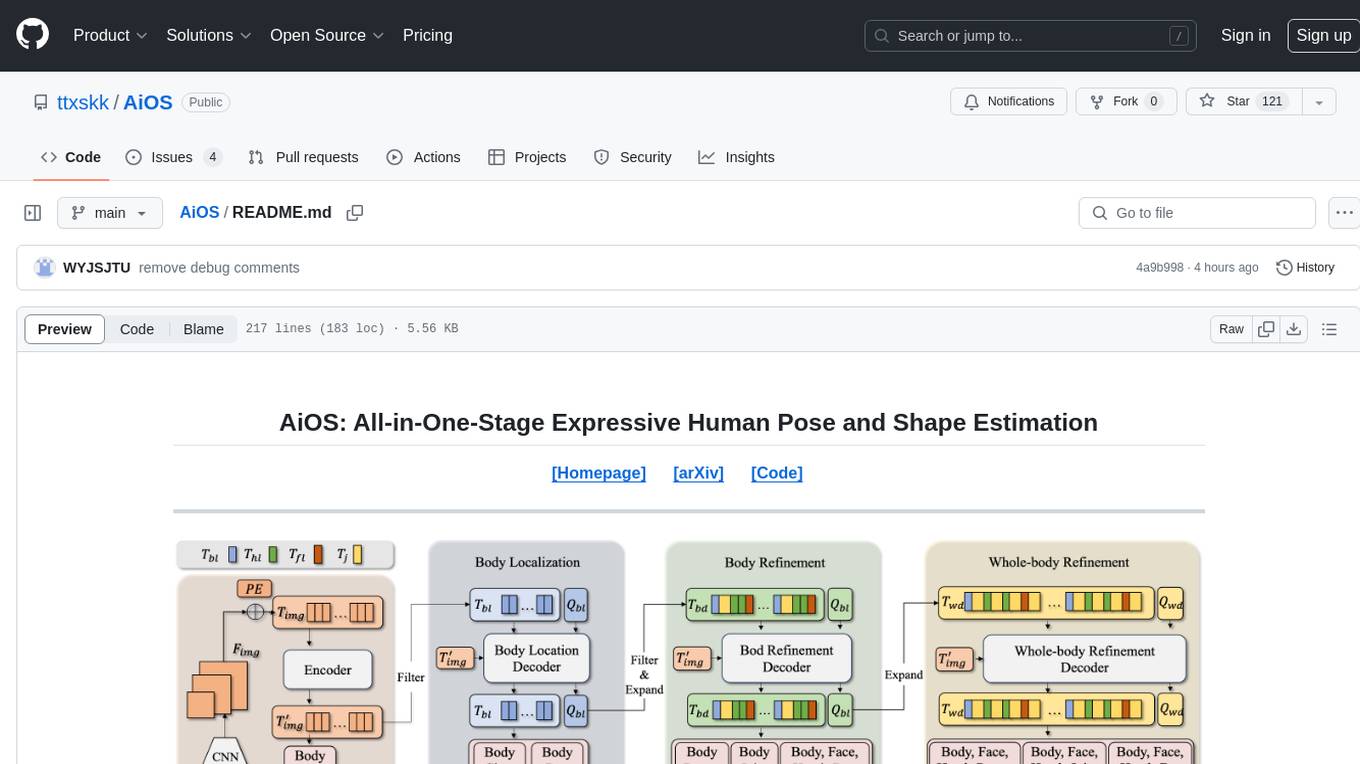
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.