
mcp-server-chart
🤖 A visualization mcp contains 25+ visual charts using @antvis. Using for chart generation and data analysis.
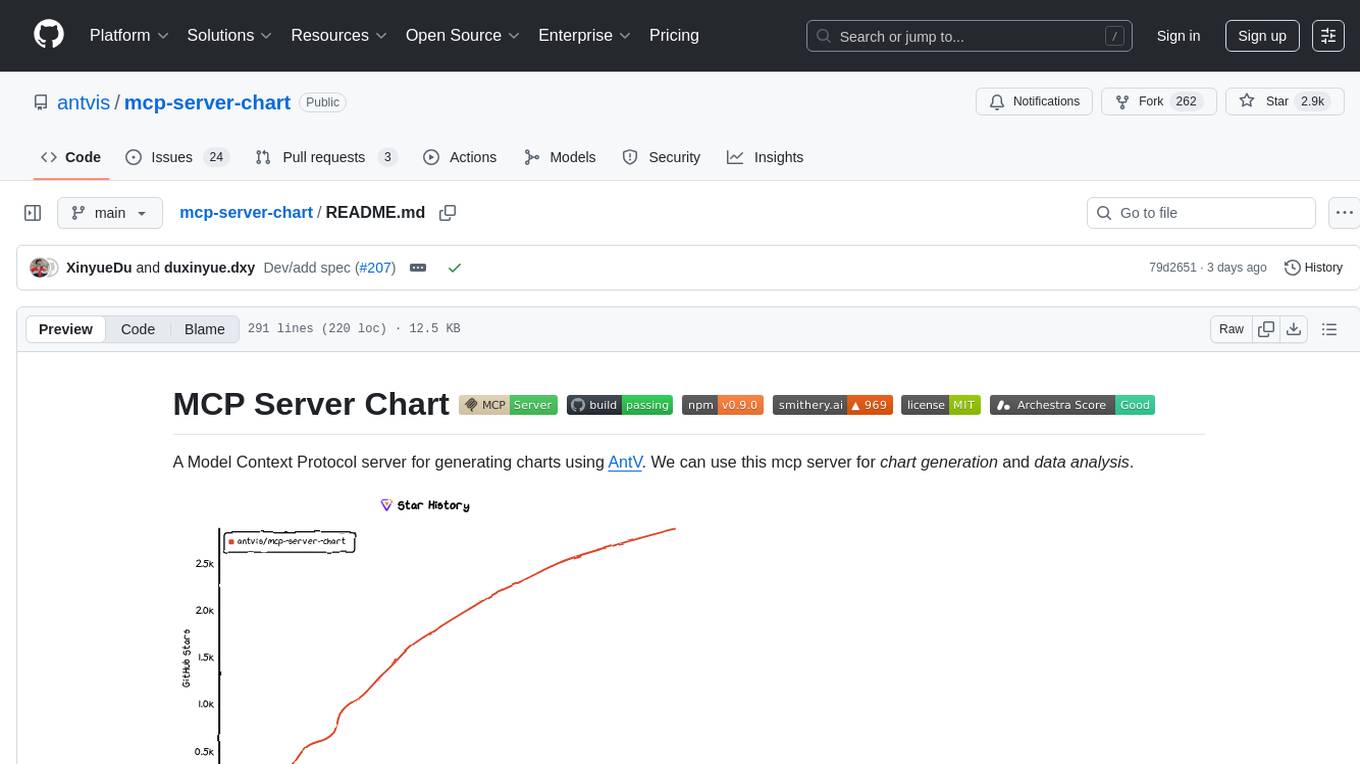
Stars: 2885
mcp-server-chart is a Helm chart for deploying a Minecraft server on Kubernetes. It simplifies the process of setting up and managing a Minecraft server in a Kubernetes environment. The chart includes configurations for specifying server settings, resource limits, and persistent storage options. With mcp-server-chart, users can easily deploy and scale Minecraft servers on Kubernetes clusters, ensuring high availability and performance for multiplayer gaming experiences.
README:


A Model Context Protocol server for generating charts using AntV. We can use this mcp server for chart generation and data analysis.
This is a TypeScript-based MCP server that provides chart generation capabilities. It allows you to create various types of charts through MCP tools. You can also use it in Dify.
- ✨ Features
- 🤖 Usage
- 🚰 Run with SSE or Streamable transport
- 🎮 CLI Options
- ⚙️ Environment Variables
- 📠 Private Deployment
- 🗺️ Generate Records
- 🎛️ Tool Filtering
- 🔨 Development
- 📄 License
Now 25+ charts supported.

-
generate_area_chart: Generate anareachart, used to display the trend of data under a continuous independent variable, allowing observation of overall data trends. -
generate_bar_chart: Generate abarchart, used to compare values across different categories, suitable for horizontal comparisons. -
generate_boxplot_chart: Generate aboxplot, used to display the distribution of data, including the median, quartiles, and outliers. -
generate_column_chart: Generate acolumnchart, used to compare values across different categories, suitable for vertical comparisons. -
generate_district_map- Generate adistrict-map, used to show administrative divisions and data distribution. -
generate_dual_axes_chart: Generate adual-axeschart, used to display the relationship between two variables with different units or ranges. -
generate_fishbone_diagram: Generate afishbonediagram, also known as an Ishikawa diagram, used to identify and display the root causes of a problem. -
generate_flow_diagram: Generate aflowchart, used to display the steps and sequence of a process. -
generate_funnel_chart: Generate afunnelchart, used to display data loss at different stages. -
generate_histogram_chart: Generate ahistogram, used to display the distribution of data by dividing it into intervals and counting the number of data points in each interval. -
generate_line_chart: Generate alinechart, used to display the trend of data over time or another continuous variable. -
generate_liquid_chart: Generate aliquidchart, used to display the proportion of data, visually representing percentages in the form of water-filled spheres. -
generate_mind_map: Generate amind-map, used to display thought processes and hierarchical information. -
generate_network_graph: Generate anetworkgraph, used to display relationships and connections between nodes. -
generate_organization_chart: Generate anorganizationalchart, used to display the structure of an organization and personnel relationships. -
generate_path_map- Generate apath-map, used to display route planning results for POIs. -
generate_pie_chart: Generate apiechart, used to display the proportion of data, dividing it into parts represented by sectors showing the percentage of each part. -
generate_pin_map- Generate apin-map, used to show the distribution of POIs. -
generate_radar_chart: Generate aradarchart, used to display multi-dimensional data comprehensively, showing multiple dimensions in a radar-like format. -
generate_sankey_chart: Generate asankeychart, used to display data flow and volume, representing the movement of data between different nodes in a Sankey-style format. -
generate_scatter_chart: Generate ascatterplot, used to display the relationship between two variables, showing data points as scattered dots on a coordinate system. -
generate_treemap_chart: Generate atreemap, used to display hierarchical data, showing data in rectangular forms where the size of rectangles represents the value of the data. -
generate_venn_chart: Generate avenndiagram, used to display relationships between sets, including intersections, unions, and differences. -
generate_violin_chart: Generate aviolinplot, used to display the distribution of data, combining features of boxplots and density plots to provide a more detailed view of the data distribution. -
generate_word_cloud_chart: Generate aword-cloud, used to display the frequency of words in textual data, with font sizes indicating the frequency of each word.
[!NOTE] The above geographic visualization chart generation tool uses AMap service and currently only supports map generation within China.
To use with Desktop APP, such as Claude, VSCode, Cline, Cherry Studio, Cursor, and so on, add the MCP server config below. On Mac system:
{
"mcpServers": {
"mcp-server-chart": {
"command": "npx",
"args": [
"-y",
"@antv/mcp-server-chart"
]
}
}
}On Window system:
{
"mcpServers": {
"mcp-server-chart": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@antv/mcp-server-chart"
]
}
}
}Also, you can use it on aliyun, modelscope, glama.ai, smithery.ai or others with HTTP, SSE Protocol.
Install the package globally.
npm install -g @antv/mcp-server-chartRun the server with your preferred transport option:
# For SSE transport (default endpoint: /sse)
mcp-server-chart --transport sse
# For Streamable transport with custom endpoint
mcp-server-chart --transport streamableThen you can access the server at:
- SSE transport:
http://localhost:1122/sse - Streamable transport:
http://localhost:1122/mcp
Enter the docker directory.
cd dockerDeploy using docker-compose.
docker compose up -dThen you can access the server at:
- SSE transport:
http://localhost:1123/sse - Streamable transport:
http://localhost:1122/mcp
You can also use the following CLI options when running the MCP server. Command options by run cli with -h.
MCP Server Chart CLI
Options:
--transport, -t Specify the transport protocol: "stdio", "sse", or "streamable" (default: "stdio")
--port, -p Specify the port for SSE or streamable transport (default: 1122)
--endpoint, -e Specify the endpoint for the transport:
- For SSE: default is "/sse"
- For streamable: default is "/mcp"
--help, -h Show this help message
| Variable | Description | Default | Example |
|---|---|---|---|
VIS_REQUEST_SERVER |
Custom chart generation service URL for private deployment | https://antv-studio.alipay.com/api/gpt-vis |
https://your-server.com/api/chart |
SERVICE_ID |
Service identifier for chart generation records | - | your-service-id-123 |
DISABLED_TOOLS |
Comma-separated list of tool names to disable | - | generate_fishbone_diagram,generate_mind_map |
MCP Server Chart provides a free chart generation service by default. For users with a need for private deployment, they can try using VIS_REQUEST_SERVER to customize their own chart generation service.
{
"mcpServers": {
"mcp-server-chart": {
"command": "npx",
"args": [
"-y",
"@antv/mcp-server-chart"
],
"env": {
"VIS_REQUEST_SERVER": "<YOUR_VIS_REQUEST_SERVER>"
}
}
}
}You can use AntV's project GPT-Vis-SSR to deploy an HTTP service in a private environment, and then pass the URL address through env VIS_REQUEST_SERVER.
-
Method:
POST -
Parameter: Which will be passed to
GPT-Vis-SSRfor rendering. Such as,{ "type": "line", "data": [{ "time": "2025-05", "value": 512 }, { "time": "2025-06", "value": 1024 }] }. -
Return: The return object of HTTP service.
-
success:
booleanWhether generate chart image successfully. -
resultObj:
stringThe chart image url. -
errorMessage:
stringWhensuccess = false, return the error message.
-
success:
[!NOTE] The private deployment solution currently does not support geographic visualization chart generation include 3 tools:
geographic-district-map,geographic-path-map,geographic-pin-map.
By default, users are required to save the results themselves, but we also provide a service for viewing the chart generation records, which requires users to generate a service identifier for themselves and configure it.
Use Alipay to scan and open the mini program to generate a personal service identifier (click the "My" menu below, enter the "My Services" page, click the "Generate" button, and click the "Copy" button after success):

Next, you need to add the SERVICE_ID environment variable to the MCP server configuration. For example, the configuration for Mac is as follows (for Windows systems, just add the env variable):
{
"mcpServers": {
"AntV Map": {
"command": "npx",
"args": [
"-y",
"@antv/mcp-server-chart"
],
"env": {
"SERVICE_ID": "***********************************"
}
}
}
}After updating the MCP Server configuration, you need to restart your AI client application and check again whether you have started and connected to the MCP Server successfully. Then you can try to generate the map again. After the generation is successful, you can go to the "My Map" page of the mini program to view your map generation records.

You can disable specific chart generation tools using the DISABLED_TOOLS environment variable. This is useful when certain tools have compatibility issues with your MCP client or when you want to limit the available functionality.
{
"mcpServers": {
"mcp-server-chart": {
"command": "npx",
"args": [
"-y",
"@antv/mcp-server-chart"
],
"env": {
"DISABLED_TOOLS": "generate_fishbone_diagram,generate_mind_map"
}
}
}
}Available tool names for filtering See the ✨ Features.
Install dependencies:
npm installBuild the server:
npm run buildStart the MCP server:
npm run startStart the MCP server with SSE transport:
node build/index.js -t sseStart the MCP server with Streamable transport:
node build/index.js -t streamableMIT@AntV.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mcp-server-chart
Similar Open Source Tools
mcp-server-chart
mcp-server-chart is a Helm chart for deploying a Minecraft server on Kubernetes. It simplifies the process of setting up and managing a Minecraft server in a Kubernetes environment. The chart includes configurations for specifying server settings, resource limits, and persistent storage options. With mcp-server-chart, users can easily deploy and scale Minecraft servers on Kubernetes clusters, ensuring high availability and performance for multiplayer gaming experiences.
context-portal
Context-portal is a versatile tool for managing and visualizing data in a collaborative environment. It provides a user-friendly interface for organizing and sharing information, making it easy for teams to work together on projects. With features such as customizable dashboards, real-time updates, and seamless integration with popular data sources, Context-portal streamlines the data management process and enhances productivity. Whether you are a data analyst, project manager, or team leader, Context-portal offers a comprehensive solution for optimizing workflows and driving better decision-making.
MCP-PostgreSQL-Ops
MCP-PostgreSQL-Ops is a repository containing scripts and tools for managing and optimizing PostgreSQL databases. It provides a set of utilities to automate common database administration tasks, such as backup and restore, performance tuning, and monitoring. The scripts are designed to simplify the operational aspects of running PostgreSQL databases, making it easier for administrators to maintain and optimize their database instances. With MCP-PostgreSQL-Ops, users can streamline their database management processes and improve the overall performance and reliability of their PostgreSQL deployments.

hyper-mcp
hyper-mcp is a fast and secure MCP server that enables adding AI capabilities to applications through WebAssembly plugins. It supports writing plugins in various languages, distributing them via standard OCI registries, and running them in resource-constrained environments. The tool offers sandboxing with WASM for limiting access, cross-platform compatibility, and deployment flexibility. Security features include sandboxed plugins, memory-safe execution, secure plugin distribution, and fine-grained access control. Users can configure the tool for global or project-specific use, start the server with different transport options, and utilize available plugins for tasks like time calculations, QR code generation, hash generation, IP retrieval, and webpage fetching.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
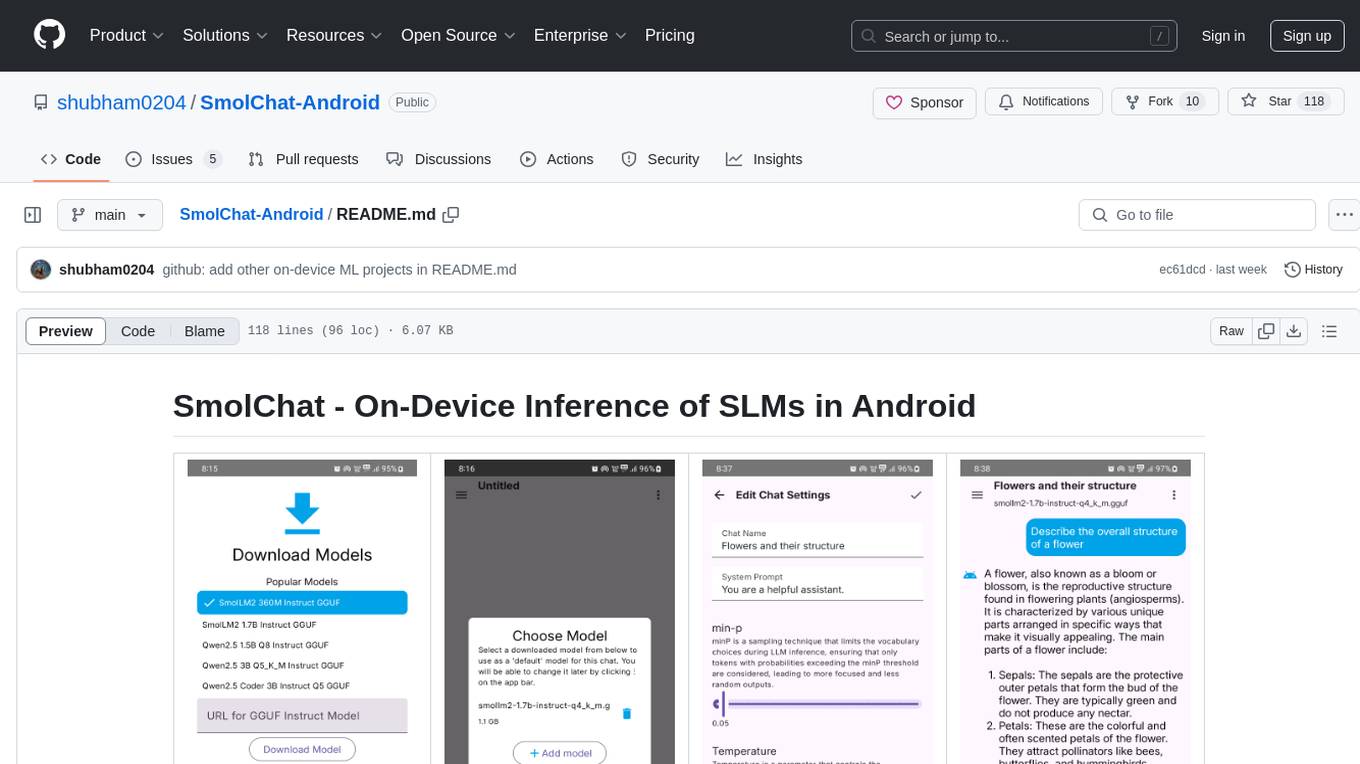
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
spec-workflow-mcp
Spec Workflow MCP is a Model Context Protocol (MCP) server that offers structured spec-driven development workflow tools for AI-assisted software development. It includes a real-time web dashboard and a VSCode extension for monitoring and managing project progress directly in the development environment. The tool supports sequential spec creation, real-time monitoring of specs and tasks, document management, archive system, task progress tracking, approval workflow, bug reporting, template system, and works on Windows, macOS, and Linux.

mcp-server-motherduck
The mcp-server-motherduck repository is a server-side application that provides a centralized platform for managing and monitoring multiple Minecraft servers. It allows server administrators to easily control various aspects of their Minecraft servers, such as player management, world backups, and server performance monitoring. The application is designed to streamline server management tasks and enhance the overall gaming experience for both server administrators and players.
cb-tumblebug
CB-Tumblebug (CB-TB) is a system for managing multi-cloud infrastructure consisting of resources from multiple cloud service providers. It provides an overview, features, and architecture. The tool supports various cloud providers and resource types, with ongoing development and localization efforts. Users can deploy a multi-cloud infra with GPUs, enjoy multiple LLMs in parallel, and utilize LLM-related scripts. The tool requires Linux, Docker, Docker Compose, and Golang for building the source. Users can run CB-TB with Docker Compose or from the Makefile, set up prerequisites, contribute to the project, and view a list of contributors. The tool is licensed under an open-source license.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
free-chat
Free Chat is a forked project from chatgpt-demo that allows users to deploy a chat application with various features. It provides branches for different functionalities like token-based message list trimming and usage demonstration of 'promplate'. Users can control the website through environment variables, including setting OpenAI API key, temperature parameter, proxy, base URL, and more. The project welcomes contributions and acknowledges supporters. It is licensed under MIT by Muspi Merol.
checkpoint-engine
Checkpoint-engine is a middleware tool designed for updating model weights in LLM inference engines efficiently. It provides implementations for both Broadcast and P2P weight update methods, orchestrating the transfer process and controlling the inference engine through ZeroMQ socket. The tool optimizes weight broadcast by arranging data transfer into stages and organizing transfers into a pipeline for performance. It supports flexible installation options and is tested with various models and device setups. Checkpoint-engine also allows reusing weights from existing instances and provides a patch for FP8 quantization in vLLM.
For similar tasks
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.