
pezzo
🕹️ Open-source, developer-first LLMOps platform designed to streamline prompt design, version management, instant delivery, collaboration, troubleshooting, observability and more.
Stars: 2266

Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.
README:
Pezzo is a fully cloud-native and open-source LLMOps platform. Seamlessly observe and monitor your AI operations, troubleshoot issues, save up to 90% on costs and latency, collaborate and manage your prompts in one place, and instantly deliver AI changes.
![]()




Click here to navigate to the Official Pezzo Documentation
In the documentation, you can find information on how to use Pezzo, its architecture, including tutorials and recipes for varius use cases and LLM providers.
| Feature | Node.js • Docs | Python • Docs | LangChain |
|---|---|---|---|
| Prompt Management | ✅ | ✅ | ✅ |
| Observability | ✅ | ✅ | ✅ |
| Caching | ✅ | ✅ | ✅ |
Looking for a client that's not listed here? Open an issue and let us know!
If you simplay want to run the full Pezzo stack locally, check out Running With Docker Compose in the documentation.
If you want to run Pezzo in development mode, continue reading.
- Node.js 18+
- Docker
- (Recommended) GraphQL Language Feature Support VSCode Extension
Install NPM dependencies by running:
npm install
Pezzo uses a .env file to store environment variables. When using docker, you should also create a .env.docker file.
See the .env.example file for reference.
Pezzo is entirely cloud-native and relies solely on open-source technologies such as PostgreSQL, ClickHouse, Redis and Supertokens.
You can run these dependencies via Docker Compose:
docker-compose -f docker-compose.infra.yaml up
Deploy Prisma migrations:
npx dotenv-cli -e apps/server/.env -- npx prisma migrate deploy --schema apps/server/prisma/schema.prisma
Run the server:
npx nx serve server
The server is now running. You can verify that by navigating to http://localhost:3000/api/healthz.
In development mode, you want to run codegen in watch mode, so whenever you make changes to the schema, types are generated automatically. After running the server, run the following in a separate terminal Window:
npm run graphql:codegen:watch
This will connect codegen directly to the server and keep your GraphQL schema up-to-date as you make changes.
Finally, you are ready to run the Pezzo Console:
npx nx serve console
That's it! The Pezzo Console is now accessible at http://localhost:4200 🚀
We welcome contributions from the community! Please feel free to submit pull requests or create issues for bugs or feature suggestions.
If you want to contribute but not sure how, join our Discord and we'll be happy to help you out!
Please check out CONTRIBUTING.md before contributing.
This repository's source code is available under the Apache 2.0 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pezzo
Similar Open Source Tools
pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

Follow
Follow is a content organization tool that creates a noise-free timeline for users, allowing them to share lists, explore collections, and browse distraction-free. It offers features like subscribing to feeds, AI-powered browsing, dynamic content support, an ownership economy with $POWER tipping, and a community-driven experience. Follow is under active development and welcomes feedback from users and developers. It can be accessed via web app or desktop client and offers installation methods for different operating systems. The tool aims to provide a customized information hub, AI-powered browsing experience, and support for various types of content, while fostering a community-driven and open-source environment.
NeMo-Agent-Toolkit
NVIDIA NeMo Agent toolkit is a flexible, lightweight, and unifying library that allows you to easily connect existing enterprise agents to data sources and tools across any framework. It is framework agnostic, promotes reusability, enables rapid development, provides profiling capabilities, offers observability features, includes an evaluation system, features a user interface for interaction, and supports the Model Context Protocol (MCP). With NeMo Agent toolkit, users can move quickly, experiment freely, and ensure reliability across all agent-driven projects.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
OpenHands
OpenDevin is a platform for autonomous software engineers powered by AI and LLMs. It allows human developers to collaborate with agents to write code, fix bugs, and ship features. The tool operates in a secured docker sandbox and provides access to different LLM providers for advanced configuration options. Users can contribute to the project through code contributions, research and evaluation of LLMs in software engineering, and providing feedback and testing. OpenDevin is community-driven and welcomes contributions from developers, researchers, and enthusiasts looking to advance software engineering with AI.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.
kubeai
KubeAI is a highly scalable AI platform that runs on Kubernetes, serving as a drop-in replacement for OpenAI with API compatibility. It can operate OSS model servers like vLLM and Ollama, with zero dependencies and additional OSS addons included. Users can configure models via Kubernetes Custom Resources and interact with models through a chat UI. KubeAI supports serving various models like Llama v3.1, Gemma2, and Qwen2, and has plans for model caching, LoRA finetuning, and image generation.
adk-python
Agent Development Kit (ADK) is an open-source, code-first Python toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control. It is a flexible and modular framework optimized for Gemini and the Google ecosystem, but also compatible with other frameworks. ADK aims to make agent development feel more like software development, enabling developers to create, deploy, and orchestrate agentic architectures ranging from simple tasks to complex workflows.

macOS-use
macOS-use is a project that enables AI agents to interact with a MacBook across any app. It aims to build an AI agent for the MLX by Apple framework to perform actions on Apple devices. The project is under active development and allows users to prompt the agent to perform various tasks on their MacBook. Users need to be cautious as the tool can interact with apps, UI components, and use private credentials. The project is open source and welcomes contributions from the community.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.
thread
Thread is an AI-powered Jupyter alternative that integrates an AI copilot into your editing experience. It offers a familiar Jupyter Notebook editing experience with features like natural language code edits, generating cells to answer questions, context-aware chat sidebar, and automatic error explanations or fixes. The tool aims to enhance code editing and data exploration by providing a more interactive and intuitive experience for users. Thread can be used for free with Ollama or your own API key, and it runs locally for convenience and privacy.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
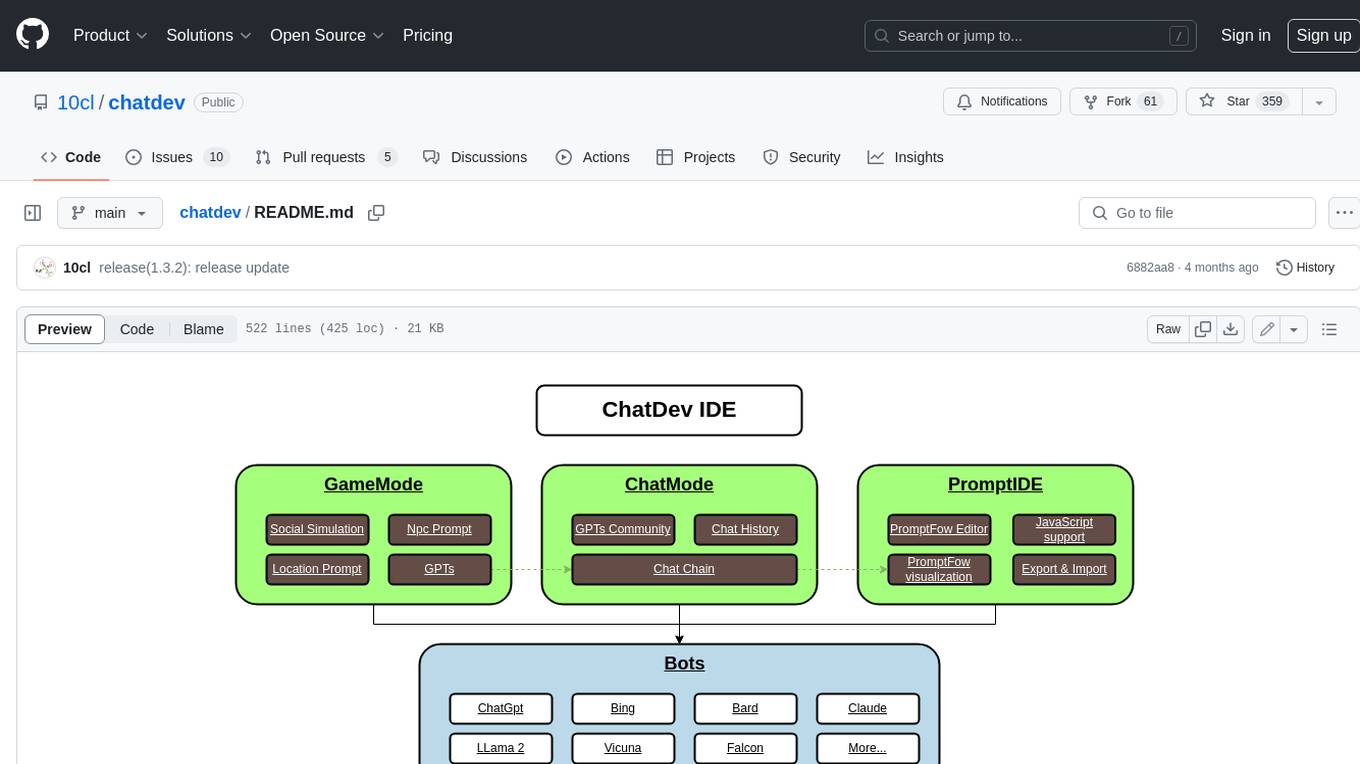
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.

beehave
Beehave is a powerful addon for Godot Engine that enables users to create robust AI systems using behavior trees. It simplifies the design of complex NPC behaviors, challenging boss battles, and other advanced setups. Beehave allows for the creation of highly adaptive AI that responds to changes in the game world and overcomes unexpected obstacles, catering to both beginners and experienced developers. The tool is currently in development for version 3.0.
For similar tasks
pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.
openssa
OpenSSA is an open-source framework for creating efficient, domain-specific AI agents. It enables the development of Small Specialist Agents (SSAs) that solve complex problems in specific domains. SSAs tackle multi-step problems that require planning and reasoning beyond traditional language models. They apply OODA for deliberative reasoning (OODAR) and iterative, hierarchical task planning (HTP). This "System-2 Intelligence" breaks down complex tasks into manageable steps. SSAs make informed decisions based on domain-specific knowledge. With OpenSSA, users can create agents that process, generate, and reason about information, making them more effective and efficient in solving real-world challenges.

llm_qlora
LLM_QLoRA is a repository for fine-tuning Large Language Models (LLMs) using QLoRA methodology. It provides scripts for training LLMs on custom datasets, pushing models to HuggingFace Hub, and performing inference. Additionally, it includes models trained on HuggingFace Hub, a blog post detailing the QLoRA fine-tuning process, and instructions for converting and quantizing models. The repository also addresses troubleshooting issues related to Python versions and dependencies.
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
For similar jobs
pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.