AI tools for Karpathy MinBPE
Related Tools:

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
DecryptPrompt
This repository does not provide a tool, but rather a collection of resources and strategies for academics in the field of artificial intelligence who are feeling depressed or overwhelmed by the rapid advancements in the field. The resources include articles, blog posts, and other materials that offer advice on how to cope with the challenges of working in a fast-paced and competitive environment.
AITreasureBox
AITreasureBox is a comprehensive collection of AI tools and resources designed to simplify and accelerate the development of AI projects. It provides a wide range of pre-trained models, datasets, and utilities that can be easily integrated into various AI applications. With AITreasureBox, developers can quickly prototype, test, and deploy AI solutions without having to build everything from scratch. Whether you are working on computer vision, natural language processing, or reinforcement learning projects, AITreasureBox has something to offer for everyone. The repository is regularly updated with new tools and resources to keep up with the latest advancements in the field of artificial intelligence.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
LLM101n
LLM101n is a course focused on building a Storyteller AI Large Language Model (LLM) from scratch in Python, C, and CUDA. The course covers various topics such as language modeling, machine learning, attention mechanisms, tokenization, optimization, device usage, precision training, distributed optimization, datasets, inference, finetuning, deployment, and multimodal applications. Participants will gain a deep understanding of AI, LLMs, and deep learning through hands-on projects and practical examples.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
llm.mojo
This project is a port of Andrej Karpathy's llm.c to Mojo, currently in beta. It is under active development and subject to changes. Users should expect to encounter bugs and unfinished features.
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.
SmallLanguageModel-project
This repository provides all the necessary items to build a Language Model from scratch, inspired by Karpathy's nanoGPT and Shakespeare generator. It includes data collection tools, data processing scripts, various models like BERT, GPT, and Seq-2-Seq, along with tokenizer and training files.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
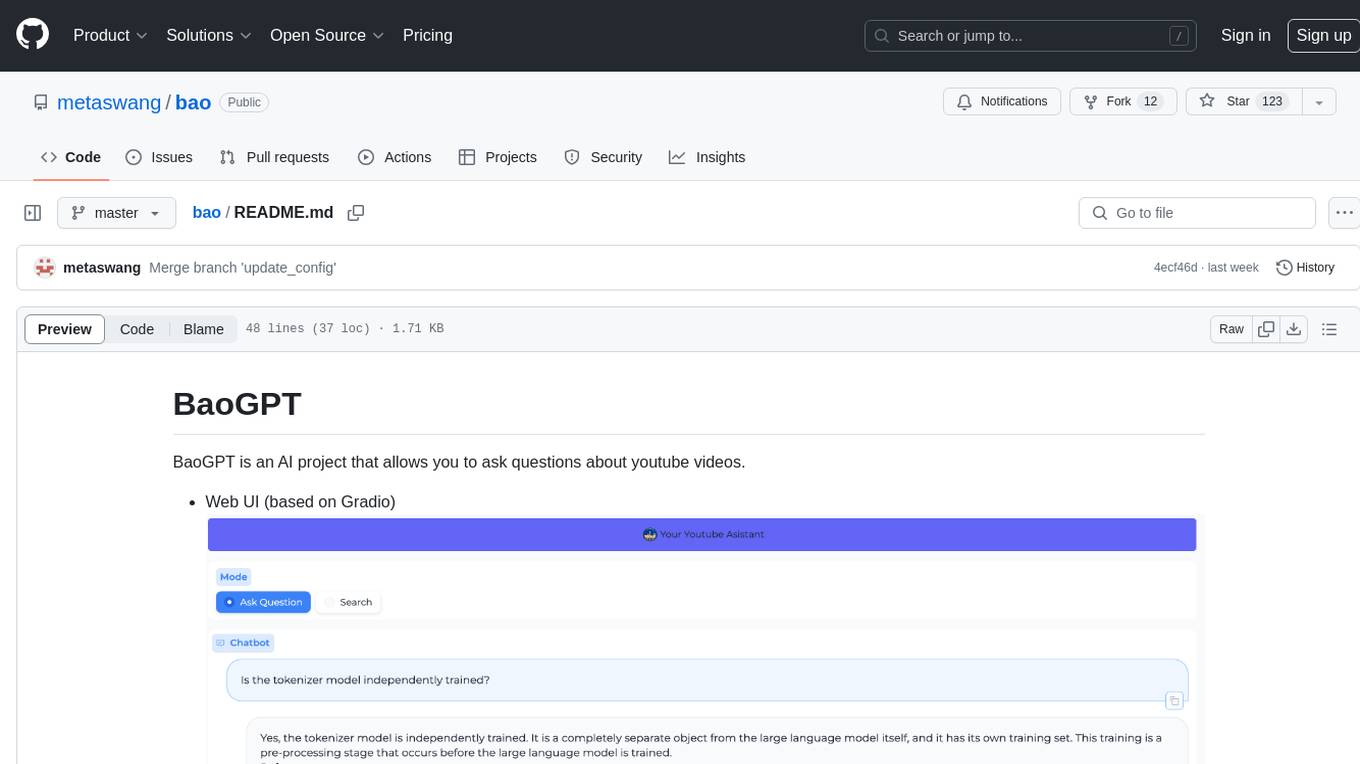
bao
BaoGPT is an AI project designed to facilitate asking questions about YouTube videos. It features a web UI based on Gradio and Discord integration. The tool utilizes a pipeline that routes input questions to either a greeting-like branch or a query & answer branch. The query analysis is performed by the LLM, which extracts attributes as filters and optimizes and rewrites questions for better vector retrieval in the vector DB. The tool then retrieves top-k candidates for grading and outputs final relative documents after grading. Lastly, the LLM performs summarization based on the reranking output, providing answers and attaching sources to the user.
autolabel
Autolabel is a Python library designed to label, clean, and enrich text datasets using Large Language Models (LLMs). It provides a simple 3-step process for labeling data, supports various NLP tasks, and offers features like confidence estimation, explanations, and state management. Users can access Refuel hosted LLMs for labeling and confidence estimation, and the library supports commercial and open source LLMs from providers like OpenAI, Anthropic, HuggingFace, and Google. Autolabel aims to streamline the labeling process for machine learning tasks by leveraging state-of-the-art LLM techniques and minimizing costs and experimentation time.
femtoGPT
femtoGPT is a pure Rust implementation of a minimal Generative Pretrained Transformer. It can be used for both inference and training of GPT-style language models using CPUs and GPUs. The tool is implemented from scratch, including tensor processing logic and training/inference code of a minimal GPT architecture. It is a great start for those fascinated by LLMs and wanting to understand how these models work at deep levels. The tool uses random generation libraries, data-serialization libraries, and a parallel computing library. It is relatively fast on CPU and correctness of gradients is checked using the gradient-check method.