
code-interpreter
Python & JS/TS SDK for running AI-generated code/code interpreting in your AI app
Stars: 2211
This Code Interpreter SDK allows you to run AI-generated Python code and each run share the context. That means that subsequent runs can reference to variables, definitions, etc from past code execution runs. The code interpreter runs inside the E2B Sandbox - an open-source secure micro VM made for running untrusted AI-generated code and AI agents. - ✅ Works with any LLM and AI framework - ✅ Supports streaming content like charts and stdout, stderr - ✅ Python & JS SDK - ✅ Runs on serverless and edge functions - ✅ 100% open source (including infrastructure)
README:


E2B is an open-source infrastructure that allows you to run AI-generated code in secure isolated sandboxes in the cloud. To start and control sandboxes, use our JavaScript SDK or Python SDK.
JavaScript / TypeScript
npm i @e2b/code-interpreter
Python
pip install e2b-code-interpreter
E2B_API_KEY=e2b_***
JavaScript / TypeScript
import { Sandbox } from '@e2b/code-interpreter'
const sbx = await Sandbox.create()
await sbx.runCode('x = 1')
const execution = await sbx.runCode('x+=1; x')
console.log(execution.text) // outputs 2Python
from e2b_code_interpreter import Sandbox
with Sandbox.create() as sandbox:
sandbox.run_code("x = 1")
execution = sandbox.run_code("x+=1; x")
print(execution.text) # outputs 2Visit E2B documentation.
Visit our Cookbook to get inspired by examples with different LLMs and AI frameworks.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for code-interpreter
Similar Open Source Tools
code-interpreter
This Code Interpreter SDK allows you to run AI-generated Python code and each run share the context. That means that subsequent runs can reference to variables, definitions, etc from past code execution runs. The code interpreter runs inside the E2B Sandbox - an open-source secure micro VM made for running untrusted AI-generated code and AI agents. - ✅ Works with any LLM and AI framework - ✅ Supports streaming content like charts and stdout, stderr - ✅ Python & JS SDK - ✅ Runs on serverless and edge functions - ✅ 100% open source (including infrastructure)
E2B
E2B Sandbox is a secure sandboxed cloud environment made for AI agents and AI apps. Sandboxes allow AI agents and apps to have long running cloud secure environments. In these environments, large language models can use the same tools as humans do. For example: * Cloud browsers * GitHub repositories and CLIs * Coding tools like linters, autocomplete, "go-to defintion" * Running LLM generated code * Audio & video editing The E2B sandbox can be connected to any LLM and any AI agent or app.
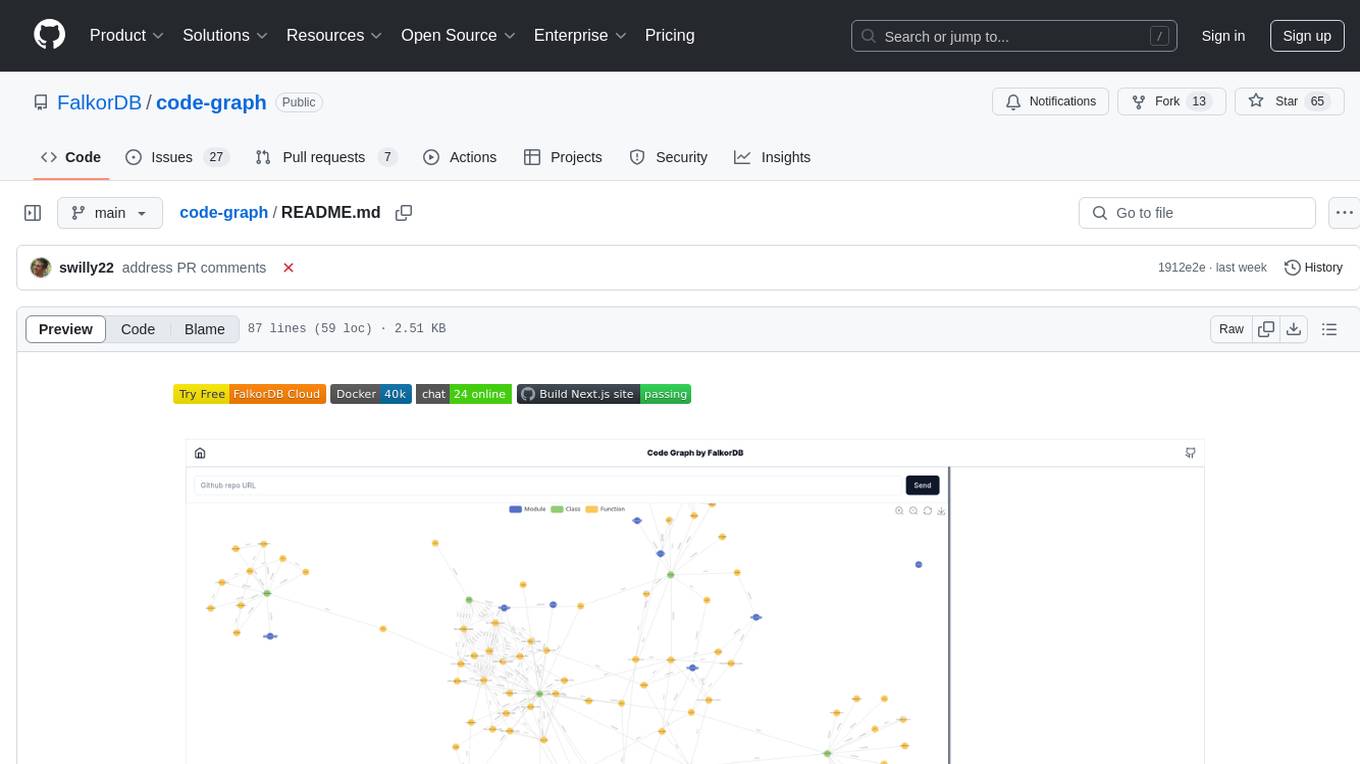
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.
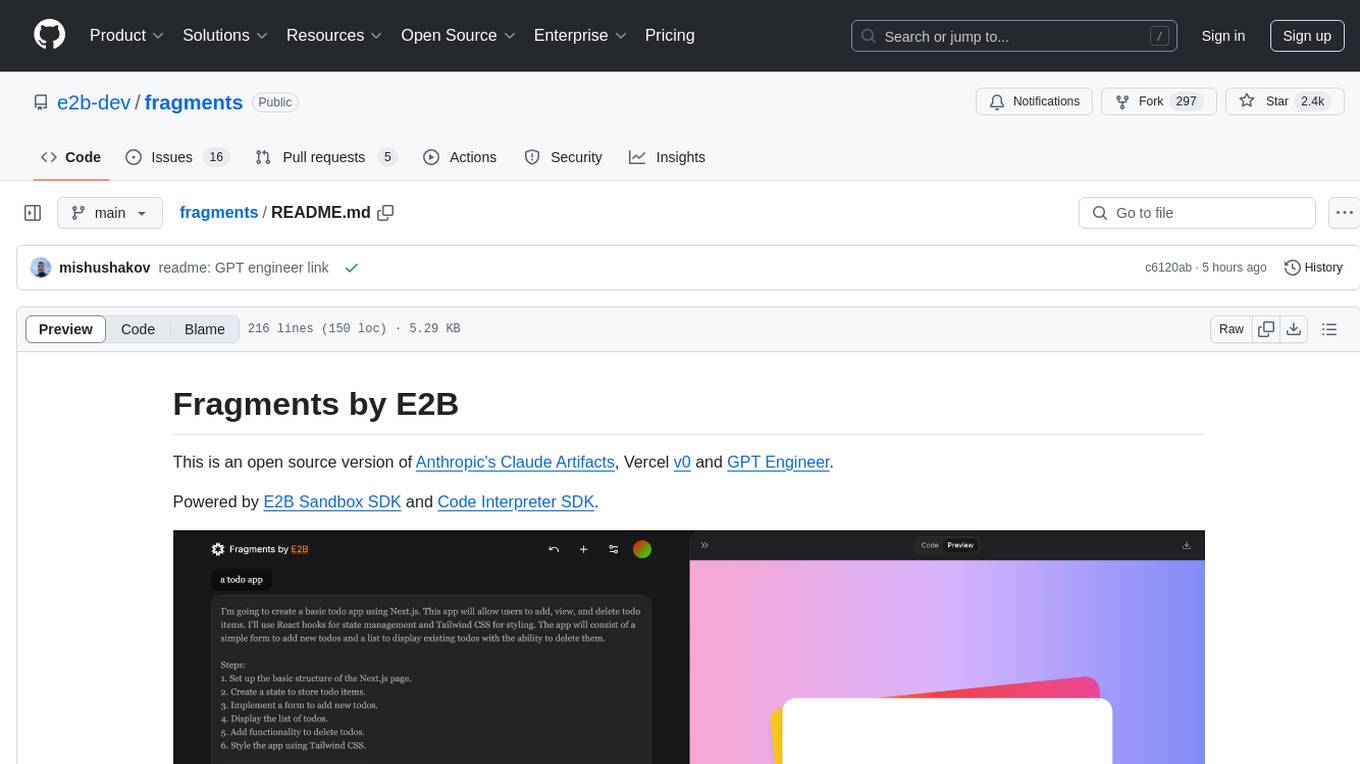
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.
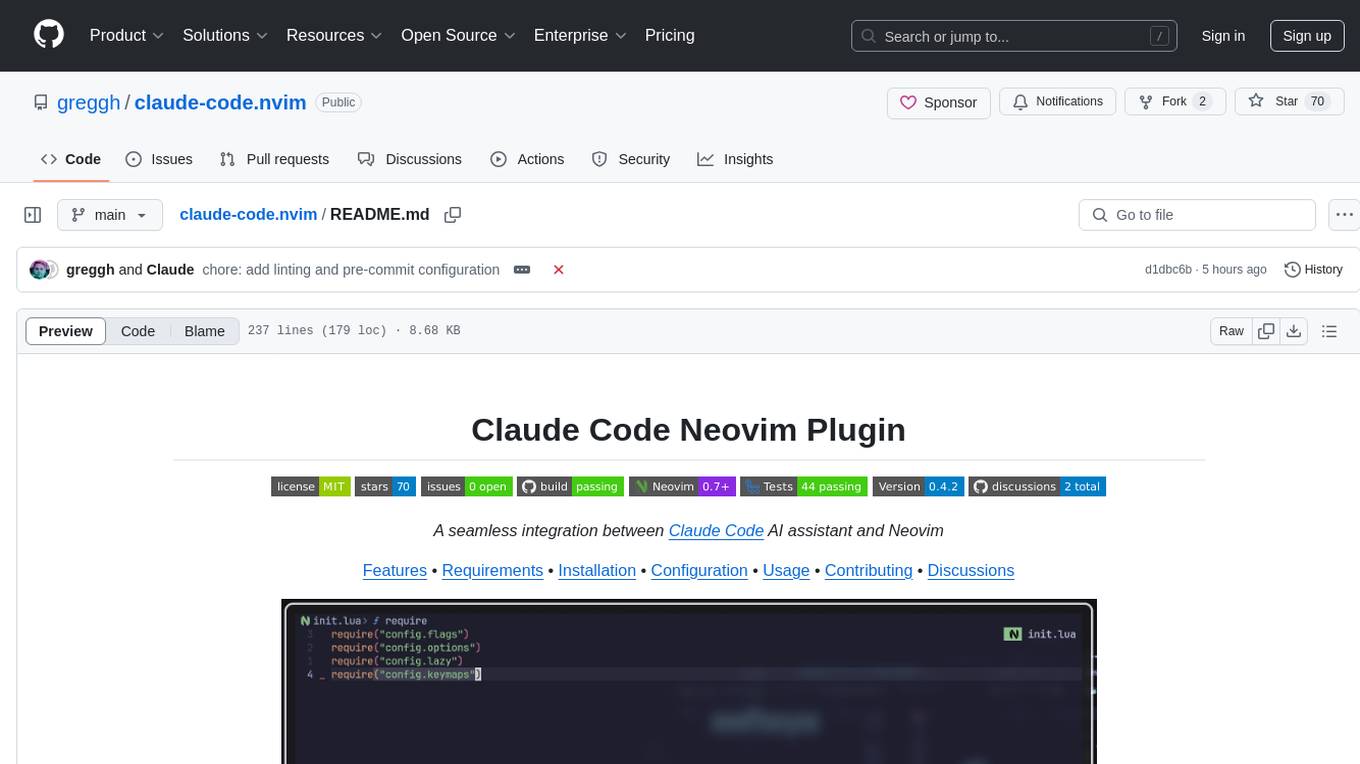
claude-code.nvim
Claude Code Neovim Plugin is a seamless integration between Claude Code AI assistant and Neovim. It allows users to toggle Claude Code in a terminal window with a single key press, automatically detect and reload files modified by Claude Code, provide real-time buffer updates when files are changed externally, offer customizable window position and size, integrate with which-key, use git project root as working directory, maintain a modular code structure, provide type annotations with LuaCATS for better IDE support, offer configuration validation, and include a testing framework for reliability. The plugin creates a terminal buffer running the Claude Code CLI, sets up autocommands to detect file changes on disk, automatically reloads files modified by Claude Code, provides keymaps and commands for toggling the terminal, and detects git repositories to set the working directory to the git root.

pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
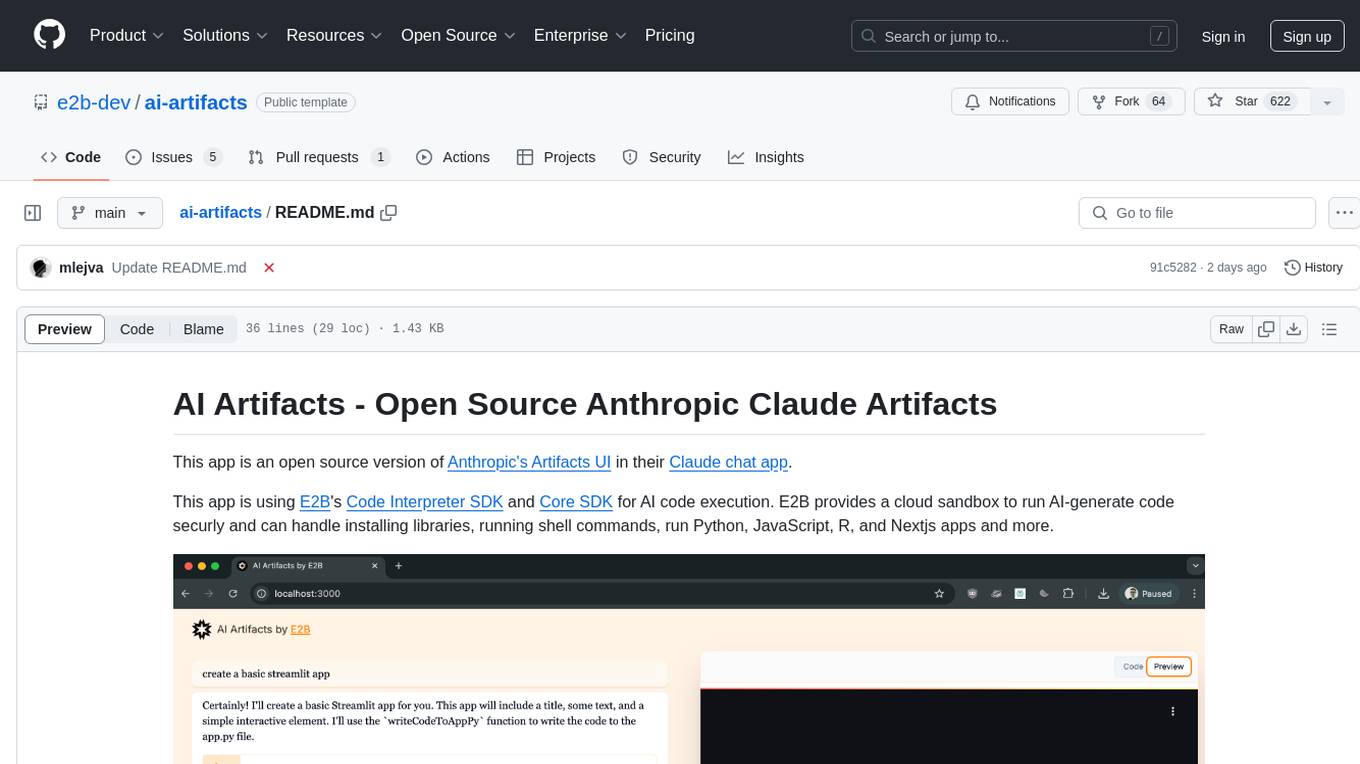
ai-artifacts
AI Artifacts is an open source tool that replicates Anthropic's Artifacts UI in the Claude chat app. It utilizes E2B's Code Interpreter SDK and Core SDK for secure AI code execution in a cloud sandbox environment. Users can run AI-generated code in various languages such as Python, JavaScript, R, and Nextjs apps. The tool also supports running AI-generated Python in Jupyter notebook, Next.js apps, and Streamlit apps. Additionally, it offers integration with Vercel AI SDK for tool calling and streaming responses from the model.
snipkit
SnipKit is a CLI tool designed to manage snippets efficiently, allowing users to execute saved scripts or generate new ones with the help of AI directly from the terminal. It supports loading snippets from various sources, parameter substitution, different parameter types, themes, and customization options. The tool includes an interactive chat-style interface called SnipKit Assistant for generating parameterized scripts. Users can also work with different AI providers like OpenAI, Anthropic, Google Gemini, and more. SnipKit aims to streamline script execution and script generation workflows for developers and users who frequently work with code snippets.
WilliamButcherBot
WilliamButcherBot is a Telegram Group Manager Bot and Userbot written in Python using Pyrogram. It provides features for managing Telegram groups and users, with ready-to-use methods available. The bot requires Python 3.9, Telegram API Key, Telegram Bot Token, and MongoDB URI. Users can install it locally or on a VPS, run it directly, generate Pyrogram session for Heroku, or use Docker for deployment. Additionally, users can write new modules to extend the bot's functionality by adding them to the wbb/modules/ directory.
onefilellm
OneFileLLM is a command-line tool that streamlines the creation of information-dense prompts for large language models (LLMs). It aggregates and preprocesses data from various sources, compiling them into a single text file for quick use. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, token count reporting, and XML encapsulation of output for improved LLM performance. Users can easily access private GitHub repositories by generating a personal access token. The tool's output is encapsulated in XML tags to enhance LLM understanding and processing.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
ai-code-fusion
AI Code Fusion is a desktop application designed to streamline the preparation of code repositories for AI workflows. It features a visual directory explorer for selecting code files, file filtering with custom patterns and .gitignore support, token counting support for selected files, and processed output ready for copying or exporting to AI tools. The tool offers cross-platform support for Windows, macOS, and Linux, making it a versatile solution for developers working on AI projects.

comp
Comp AI is an open-source compliance automation platform designed to assist companies in achieving compliance with standards like SOC 2, ISO 27001, and GDPR. It transforms compliance into an engineering problem solved through code, automating evidence collection, policy management, and control implementation while maintaining data and infrastructure control.
maclocal-api
MacLocalAPI is a macOS server application that exposes Apple's Foundation Models through OpenAI-compatible API endpoints. It allows users to run Apple Intelligence locally with full OpenAI API compatibility. The tool supports MLX local models, API gateway mode, LoRA adapter support, Vision OCR, built-in WebUI, privacy-first processing, fast and lightweight operation, easy integration with existing OpenAI client libraries, and provides token consumption metrics. Users can install MacLocalAPI using Homebrew or pip, and it requires macOS 26 or later, an Apple Silicon Mac, and Apple Intelligence enabled in System Settings. The tool is designed for easy integration with Python, JavaScript, and open-webui applications.
For similar tasks
code-interpreter
This Code Interpreter SDK allows you to run AI-generated Python code and each run share the context. That means that subsequent runs can reference to variables, definitions, etc from past code execution runs. The code interpreter runs inside the E2B Sandbox - an open-source secure micro VM made for running untrusted AI-generated code and AI agents. - ✅ Works with any LLM and AI framework - ✅ Supports streaming content like charts and stdout, stderr - ✅ Python & JS SDK - ✅ Runs on serverless and edge functions - ✅ 100% open source (including infrastructure)

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.
go-stock
Go-stock is a tool for analyzing stock market data using the Go programming language. It provides functionalities for fetching stock data, performing technical analysis, and visualizing trends. With Go-stock, users can easily retrieve historical stock prices, calculate moving averages, and plot candlestick charts. This tool is designed to help investors and traders make informed decisions based on data-driven insights.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.