
awesome-artificial-intelligence-research
A curated list of Artificial Intelligence (AI) Research, tracks the cutting edge trending of AI research, including recommender systems, computer vision, machine learning, etc.
Stars: 128
The 'Awesome Artificial Intelligence Research' repository is a curated list of up-to-date research papers in the field of Artificial Intelligence (AI). It aims to help researchers stay informed about cutting-edge research trends and topics in AI by providing a comprehensive collection of research paper lists. The repository covers various subfields of AI, including Machine Learning, Data Mining, Computer Vision, Natural Language Processing, Audio & Speech, and other applications. It also includes tools for research such as public datasets and new paper recommendations.
README:
Artificial Intelligence (AI) has become a vast research area, with tens of thousands of papers published every year. It's more and more difficult to track a specific topic among many top conferences and journals. This list aims to maintain a meta list of up-to-date research paper lists to help researchers get familiar with cutting edge research in a specific area, and (hopefully) provide a large scale picture of the trending of AI research.
-
Federated Learning
-
Graph / Network Learning
-
Incremental Learning / Continual Learning / Lifelong Learning
-
Self Supervised Learning
-
Object Detection
-
Point Cloud
-
Recommender Systems
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-artificial-intelligence-research
Similar Open Source Tools
awesome-artificial-intelligence-research
The 'Awesome Artificial Intelligence Research' repository is a curated list of up-to-date research papers in the field of Artificial Intelligence (AI). It aims to help researchers stay informed about cutting-edge research trends and topics in AI by providing a comprehensive collection of research paper lists. The repository covers various subfields of AI, including Machine Learning, Data Mining, Computer Vision, Natural Language Processing, Audio & Speech, and other applications. It also includes tools for research such as public datasets and new paper recommendations.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.
machine-learning-research
The 'machine-learning-research' repository is a comprehensive collection of resources related to mathematics, machine learning, deep learning, artificial intelligence, data science, and various scientific fields. It includes materials such as courses, tutorials, books, podcasts, communities, online courses, papers, and dissertations. The repository covers topics ranging from fundamental math skills to advanced machine learning concepts, with a focus on applications in healthcare, genetics, computational biology, precision health, and AI in science. It serves as a valuable resource for individuals interested in learning and researching in the fields of machine learning and related disciplines.
awesome-ai-ml-resources
This repository is a collection of free resources and a roadmap designed to help individuals learn Machine Learning and Artificial Intelligence concepts by providing key concepts, building blocks, roles, a learning roadmap, courses, certifications, books, tools & frameworks, research blogs, applied blogs, practice problems, communities, YouTube channels, newsletters, and must-read papers. It covers a wide range of topics from supervised learning to MLOps, offering guidance on learning paths, practical experience, and job interview preparation.

rlhf_thinking_model
This repository is a collection of research notes and resources focusing on training large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). It includes methodologies, techniques, and state-of-the-art approaches for optimizing preferences and model alignment in LLM training. The purpose is to serve as a reference for researchers and engineers interested in reinforcement learning, large language models, model alignment, and alternative RL-based methods.
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
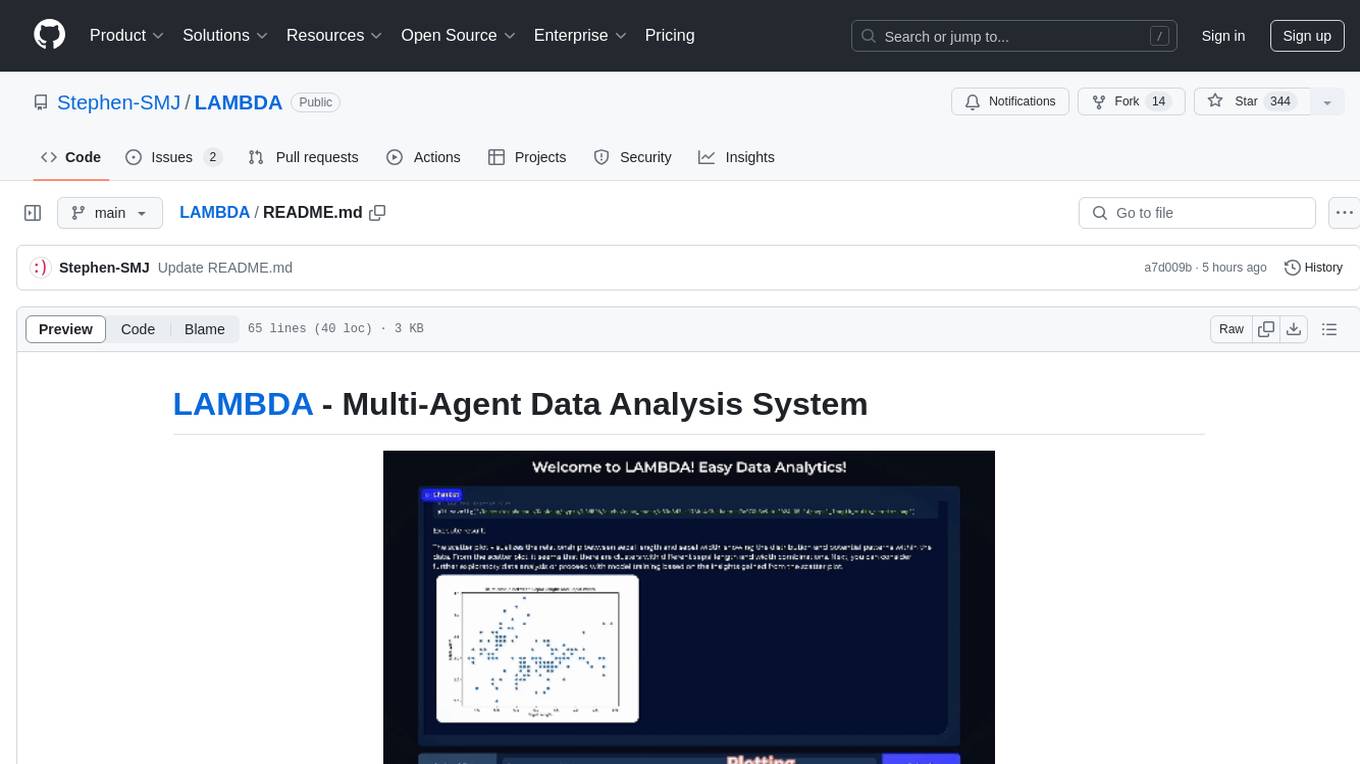
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).
Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.
UltraBr3aks
UltraBr3aks is a repository designed to share strong AI UltraBr3aks of multiple vendors, specifically focusing on Attention-Breaking technique targeting self-attention mechanisms of Transformer-based models. The method disrupts the model's focus on system guardrails by introducing specific token patterns and contextual noise, allowing for unrestricted generation analysis. The repository is created for educational and research purposes only.
AI-Blueprints
This repository hosts a collection of AI blueprint projects for HP AI Studio, providing end-to-end solutions across key AI domains like data science, machine learning, deep learning, and generative AI. The projects are designed to be plug-and-play, utilizing open-source and hosted models to offer ready-to-use solutions. The repository structure includes projects related to classical machine learning, deep learning applications, generative AI, NGC integration, and troubleshooting guidelines for common issues. Each project is accompanied by detailed descriptions and use cases, showcasing the versatility and applicability of AI technologies in various domains.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.