
LAMBDA
This is the offical repository of paper "LAMBDA: A large Model Based Data Agent". https://www.polyu.edu.hk/ama/cmfai/lambda.html
Stars: 344
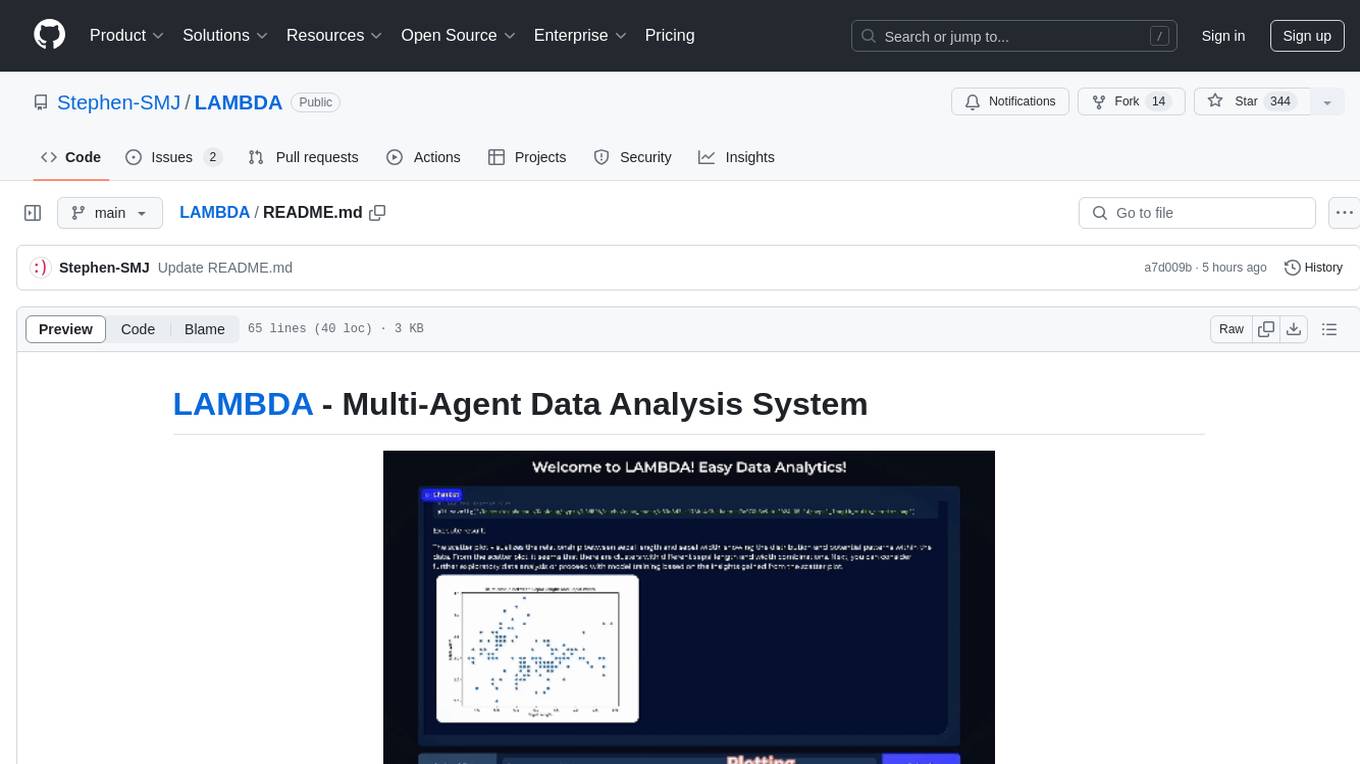
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.
README:
LAMBDA - Multi-Agent Data Analysis System
We introduce LAMBDA, a novel open-source, code-free multi-agent data analysis system that harnesses the power of large models. LAMBDA is designed to address data analysis challenges in complex data-driven applications through the use of innovatively designed data agents that operate iteratively and generatively using natural language.
- Code-Free Data Analysis: Perform complex data analysis tasks through human language instruction.
- Multi-Agent System: Utilizes two key agent roles, the programmer and the inspector, to generate and debug code seamlessly.
- User Interface: This includes a robust user interface that allows direct user intervention in the operational loop.
- Model Integration: Flexibly integrates external models and algorithms to cater to customized data analysis needs.
- Automatic Report Generation: Concentrate on high-value tasks, rather than spending time and resources on report writing and formatting.
LAMBDA has demonstrated strong performance on various machine learning datasets, enhancing data science practice and analysis paradigms by seamlessly integrating human and artificial intelligence.
The performance of LAMBDA in solving data science problems is demonstrated in several case studies including:
Note: All code files will be released soon. We recommend starring this repository to stay updated with the latest developments.
This project is licensed under the MIT License - see the LICENSE file for details.
- Star this repository to stay updated.
We thank the contributors and the community for their support and feedback.
LAMBDA is an open-source project aimed at making data analysis more accessible, effective, and efficient for individuals from diverse backgrounds.
If you find our work useful in your research, consider citing our paper by:
@article{sun2024lambda,
title={LAMBDA: A Large Model Based Data Agent},
author={Sun, Maojun and Han, Ruijian and Jiang, Binyan and Qi, Houduo and Sun, Defeng and Yuan, Yancheng and Huang, Jian},
journal={arXiv preprint arXiv:2407.17535},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LAMBDA
Similar Open Source Tools
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.
agentsociety
AgentSociety is an advanced framework designed for building agents in urban simulation environments. It integrates LLMs' planning, memory, and reasoning capabilities to generate realistic behaviors. The framework supports dataset-based, text-based, and rule-based environments with interactive visualization. It includes tools for interviews, surveys, interventions, and metric recording tailored for social experimentation.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

vulcan-sql
VulcanSQL is an Analytical Data API Framework for AI agents and data apps. It aims to help data professionals deliver RESTful APIs from databases, data warehouses or data lakes much easier and secure. It turns your SQL into APIs in no time!

ai-data-science-team
The AI Data Science Team of Copilots is an AI-powered data science team that uses agents to help users perform common data science tasks 10X faster. It includes agents specializing in data cleaning, preparation, feature engineering, modeling, and interpretation of business problems. The project is a work in progress with new data science agents to be released soon. Disclaimer: This project is for educational purposes only and not intended to replace a company's data science team. No warranties or guarantees are provided, and the creator assumes no liability for financial loss.

GenAI_Agents
GenAI Agents is a comprehensive repository for developing and implementing Generative AI (GenAI) agents, ranging from simple conversational bots to complex multi-agent systems. It serves as a valuable resource for learning, building, and sharing GenAI agents, offering tutorials, implementations, and a platform for showcasing innovative agent creations. The repository covers a wide range of agent architectures and applications, providing step-by-step tutorials, ready-to-use implementations, and regular updates on advancements in GenAI technology.

LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.
seatunnel
SeaTunnel is a high-performance, distributed data integration tool trusted by numerous companies for synchronizing vast amounts of data daily. It addresses common data integration challenges by seamlessly integrating with diverse data sources, supporting multimodal data integration, complex synchronization scenarios, resource efficiency, and quality monitoring. With over 100 connectors, SeaTunnel offers batch-stream integration, distributed snapshot algorithm, multi-engine support, JDBC multiplexing, and log parsing. It provides high throughput, low latency, real-time monitoring, and supports two job development methods. Users can configure jobs, select execution engines, and parallelize data using source connectors. SeaTunnel also supports multimodal data integration, Apache SeaTunnel tools, real-world use cases, and visual management of jobs through the SeaTunnel Web Project.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.
apo
AutoPilot Observability (APO) is an out-of-the-box observability platform that provides one-click installation and ready-to-use capabilities. APO's OneAgent supports one-click configuration-free installation of Tracing probes, collects application fault scene logs, infrastructure metrics, network metrics of applications and downstream dependencies, and Kubernetes events. It supports collecting causality metrics based on eBPF implementation. APO integrates OpenTelemetry probes, otel-collector, Jaeger, ClickHouse, and VictoriaMetrics, reducing user configuration work. APO innovatively integrates eBPF technology with the OpenTelemetry ecosystem, significantly reducing data storage volume. It offers guided troubleshooting using eBPF technology to assist users in pinpointing fault causes on a single page.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.