
ChatLLM-Web
🗣️ Chat with LLM like Vicuna totally in your browser with WebGPU, safely, privately, and with no server. Powered by web llm.
Stars: 610
ChatLLM Web is a browser-based AI chat tool powered by WebGPU, providing a seamless and private chat experience. It runs models in a web worker, supports model caching, and offers multi-conversation chat with data stored locally. The tool features a well-designed UI with dark mode, PWA support for offline use, and markdown and streaming response capabilities. Users can deploy it easily on Vercel and interact with the AI like Vicuna in their browser.
README:
🚀 Check the AI search engine https://discovai.io, discover top ai tools that best match your need
🗣️ Chat with LLM like Vicuna totally in your browser with WebGPU, safely, privately, and with no server. Powered By web-llm.

-
🤖 Everything runs inside the browser with no server support and is accelerated with WebGPU.
-
⚙️ Model runs in a web worker, ensuring that it doesn't block the user interface and providing a seamless experience.
-
🚀 Easy to deploy for free with one-click on Vercel in under 1 minute, then you get your own ChatLLM Web.
-
💾 Model caching is supported, so you only need to download the model once.
-
💬 Multi-conversation chat, with all data stored locally in the browser for privacy.
-
📝 Markdown and streaming response support: math, code highlighting, etc.
-
🎨 responsive and well-designed UI, including dark mode.
-
💻 PWA supported, download it and run totally offline.
-
🌐 To use this app, you need a browser that supports WebGPU, such as Chrome 113 or Chrome Canary. Chrome versions ≤ 112 are not supported.
-
💻 You will need a GPU with about 6.4GB of memory. If your GPU has less memory, the app will still run, but the response time will be slower.
-
📥 The first time you use the app, you will need to download the model. For the Vicuna-7b model that we are currently using, the download size is about 4GB. After the initial download, the model will be loaded from the browser cache for faster usage.
-
ℹ️ For more details, please visit mlc.ai/web-llm
-
[✅] LLM: using web worker to create an LLM instance and generate answers.
-
[✅] Conversations: Multi-conversation support is available.
-
[✅] PWA
-
[] Settings:
- ui: dark/light theme
- device:
- gpu device choose
- cache usage and manage
- model:
- support multi models: vicuna-7b✅ RedPajama-INCITE-Chat-3B []
- params config: temperature, max-length, etc.
- export & import model
- Click
, follow the instructions, and finish in just 1 minute.
- Enjoy it 😊
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatLLM-Web
Similar Open Source Tools
ChatLLM-Web
ChatLLM Web is a browser-based AI chat tool powered by WebGPU, providing a seamless and private chat experience. It runs models in a web worker, supports model caching, and offers multi-conversation chat with data stored locally. The tool features a well-designed UI with dark mode, PWA support for offline use, and markdown and streaming response capabilities. Users can deploy it easily on Vercel and interact with the AI like Vicuna in their browser.

pyqt-openai
VividNode is a cross-platform AI desktop chatbot application for LLM such as GPT, Claude, Gemini, Llama chatbot interaction and image generation. It offers customizable features, local chat history, and enhanced performance without requiring a browser. The application is powered by GPT4Free and allows users to interact with chatbots and generate images seamlessly. VividNode supports Windows, Mac, and Linux, securely stores chat history locally, and provides features like chat interface customization, image generation, focus and accessibility modes, and extensive customization options with keyboard shortcuts for efficient operations.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.

toolhive-studio
ToolHive Studio is an experimental project under active development and testing, providing an easy way to discover, deploy, and manage Model Context Protocol (MCP) servers securely. Users can launch any MCP server in a locked-down container with just a few clicks, eliminating manual setup, security concerns, and runtime issues. The tool ensures instant deployment, default security measures, cross-platform compatibility, and seamless integration with popular clients like GitHub Copilot, Cursor, and Claude Code.
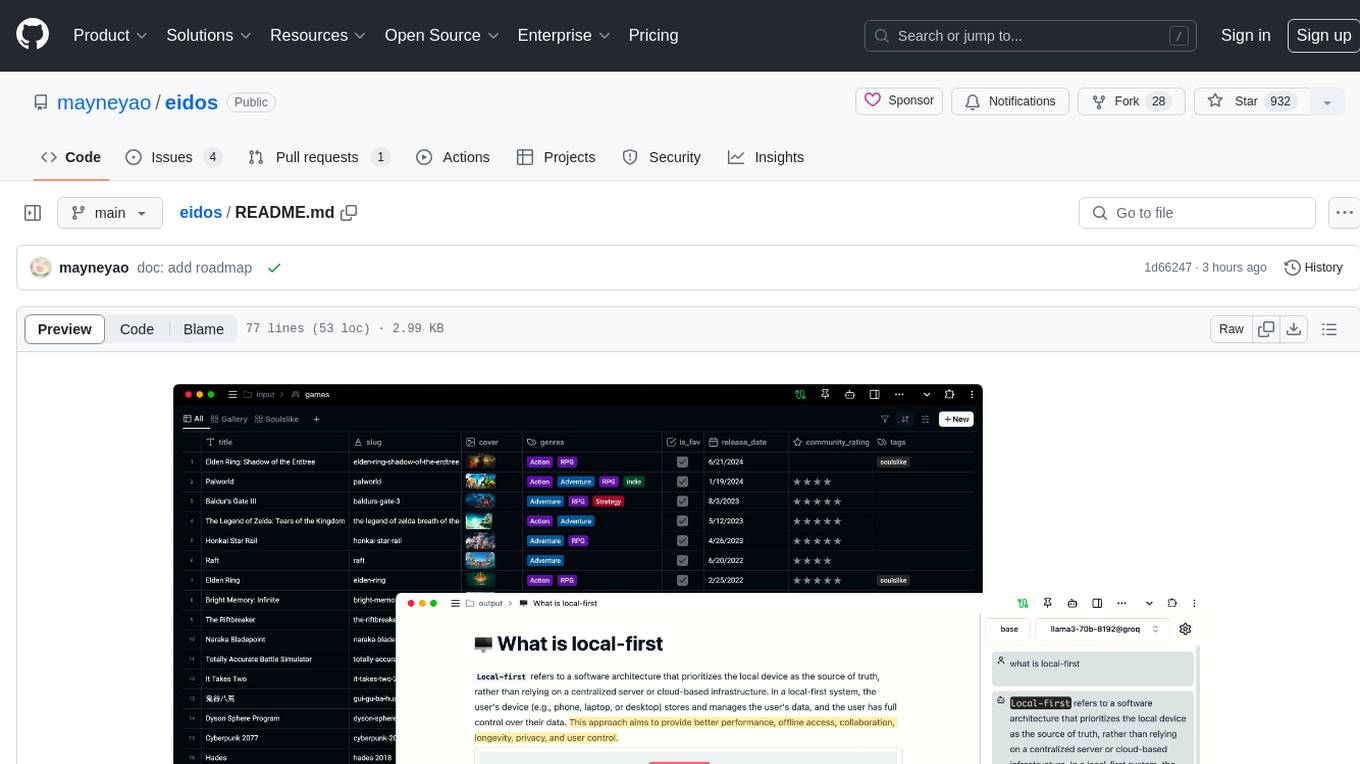
eidos
Eidos is an extensible framework for managing personal data in one place. It runs inside the browser as a PWA with offline support. It integrates AI features for translation, summarization, and data interaction. Users can customize Eidos with Prompt extension, JavaScript for Formula functions, TypeScript/JavaScript for data processing logic, and build apps using any framework. Eidos is developer-friendly with API & SDK, and uses SQLite standardization for data tables.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.
appwrite
Appwrite is a best-in-class, developer-first platform that provides everything needed to create scalable, stable, and production-ready software quickly. It is an end-to-end platform for building Web, Mobile, Native, or Backend apps, packaged as Docker microservices. Appwrite abstracts the complexity of building modern apps and allows users to build secure, full-stack applications faster. It offers features like user authentication, database management, storage, file management, image manipulation, Cloud Functions, messaging, and more services.

ChatGPT
ChatGPT is a desktop application available on Mac, Windows, and Linux that provides a powerful AI wrapper experience. It allows users to interact with AI models for various tasks such as generating text, answering questions, and engaging in conversations. The application is designed to be user-friendly and accessible to both beginners and advanced users. ChatGPT aims to enhance the user experience by offering a seamless interface for leveraging AI capabilities in everyday scenarios.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.