
ML
A high-level machine learning and deep learning library for the PHP language.
Stars: 1988
Rubix ML is a high-level machine learning and deep learning library for the PHP language. It provides a developer-friendly API with over 40 supervised and unsupervised learning algorithms, support for ETL, preprocessing, and cross-validation. The library is open source and free to use commercially. Rubix ML allows users to build machine learning programs in PHP, covering the entire machine learning life cycle from data processing to training and production. It also offers tutorials and educational content to help users get started with machine learning projects.
README:



![]()

A high-level machine learning and deep learning library for the PHP language.
- Developer-friendly API is delightful to use
- 40+ supervised and unsupervised learning algorithms
- Support for ETL, preprocessing, and cross-validation
- Open source and free to use commercially
Install Rubix ML into your project using Composer:
$ composer require rubix/ml- PHP 7.4 or above
- Tensor extension for fast Matrix/Vector computing
- GD extension for image support
- Mbstring extension for fast multibyte string manipulation
- SVM extension for Support Vector Machine engine (libsvm)
- PDO extension for relational database support
- GraphViz for graph visualization
Read the latest docs here.
Rubix ML is a free open-source machine learning (ML) library that allows you to build programs that learn from your data using the PHP language. We provide tools for the entire machine learning life cycle from ETL to training, cross-validation, and production with over 40 supervised and unsupervised learning algorithms. In addition, we provide tutorials and other educational content to help you get started using ML in your projects.
If you are new to machine learning, we recommend taking a look at the What is Machine Learning? section to get started. If you are already familiar with basic ML concepts, you can browse the basic introduction for a brief look at a typical Rubix ML project. From there, you can browse the official tutorials below which range from beginner to advanced skill level.
Check out these example projects using the Rubix ML library. Many come with instructions and a pre-cleaned dataset.
- CIFAR-10 Image Recognizer
- Color Clusterer
- Credit Default Risk Predictor
- Customer Churn Predictor
- Divorce Predictor
- DNA Taxonomer
- Dota 2 Game Outcome Predictor
- Human Activity Recognizer
- Housing Price Predictor
- Iris Flower Classifier
- MNIST Handwritten Digit Recognizer
- Text Sentiment Analyzer
- Titanic Survival Predictor
See CONTRIBUTING.md for guidelines.
The code is licensed MIT and the documentation is licensed CC BY-NC 4.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ML
Similar Open Source Tools
ML
Rubix ML is a high-level machine learning and deep learning library for the PHP language. It provides a developer-friendly API with over 40 supervised and unsupervised learning algorithms, support for ETL, preprocessing, and cross-validation. The library is open source and free to use commercially. Rubix ML allows users to build machine learning programs in PHP, covering the entire machine learning life cycle from data processing to training and production. It also offers tutorials and educational content to help users get started with machine learning projects.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

kodit
Kodit is a Code Indexing MCP Server that connects AI coding assistants to external codebases, providing accurate and up-to-date code snippets. It improves AI-assisted coding by offering canonical examples, indexing local and public codebases, integrating with AI coding assistants, enabling keyword and semantic search, and supporting OpenAI-compatible or custom APIs/models. Kodit helps engineers working with AI-powered coding assistants by providing relevant examples to reduce errors and hallucinations.
repromodel
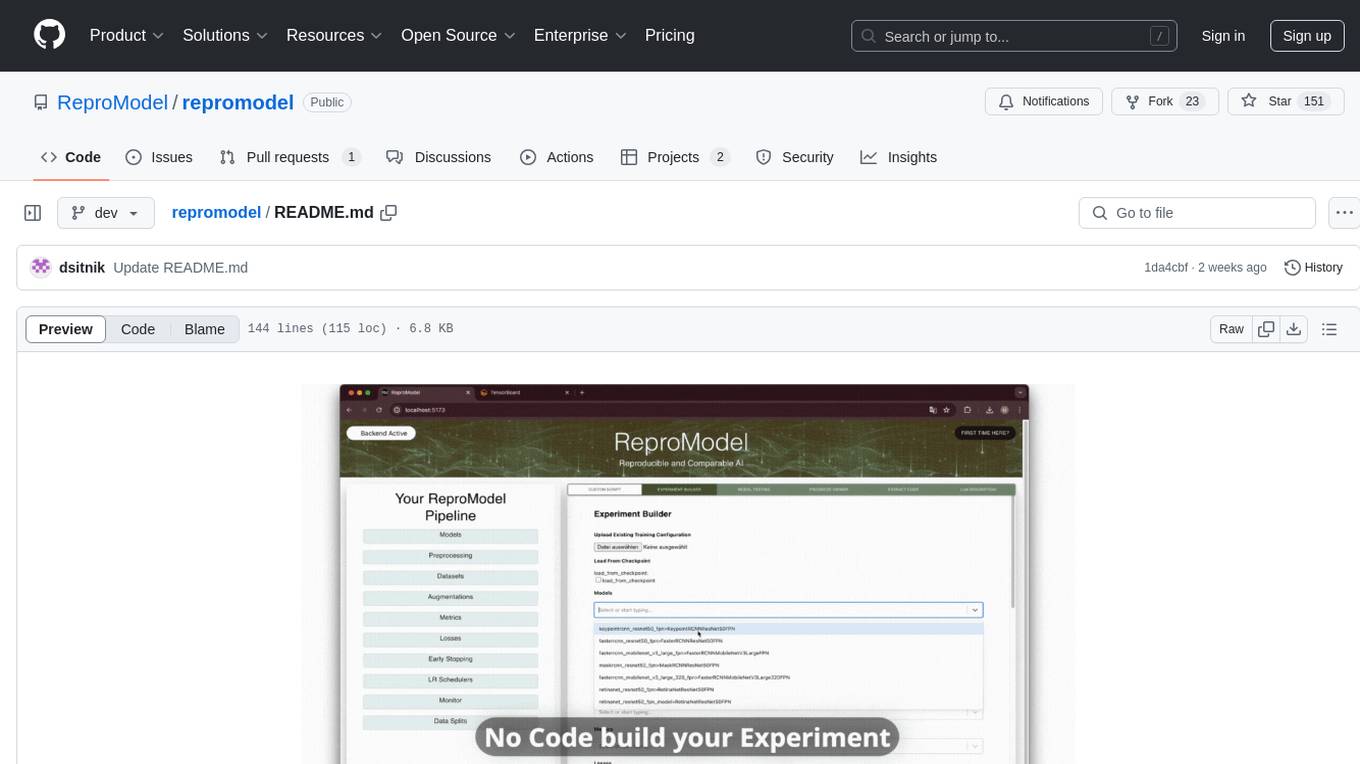
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports Hyperparameter Tuning, Early Stopping and Neural Architecture Search. Katib is the project which is agnostic to machine learning (ML) frameworks. It can tune hyperparameters of applications written in any language of the users’ choice and natively supports many ML frameworks, such as TensorFlow, Apache MXNet, PyTorch, XGBoost, and others. Katib can perform training jobs using any Kubernetes Custom Resources with out of the box support for Kubeflow Training Operator, Argo Workflows, Tekton Pipelines and many more.
ComputerGYM
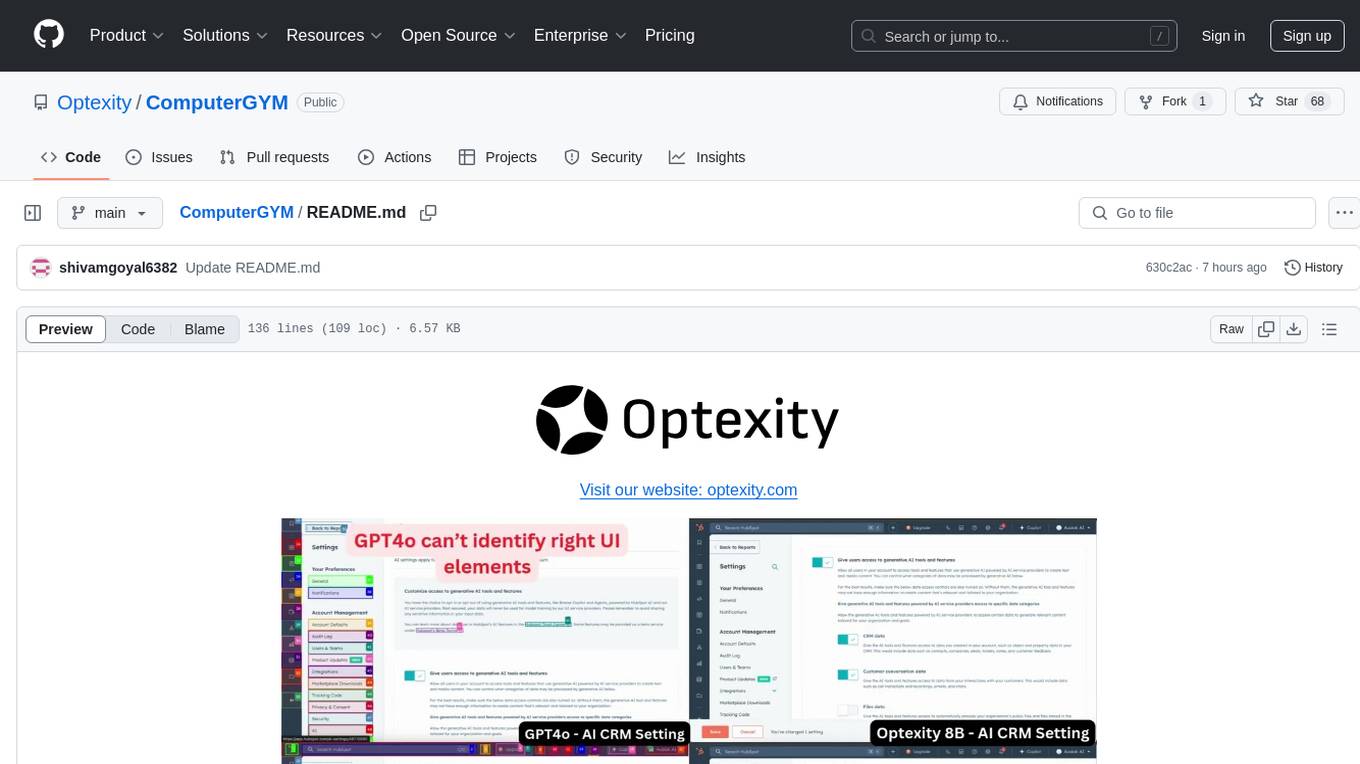
Optexity is a framework for training foundation models using human demonstrations of computer tasks. It enables recording, processing, and utilizing demonstrations to train AI agents for web-based tasks. The tool also plans to incorporate training through self-exploration, software documentations, and YouTube videos in the future.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.

doku
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just a single line of code. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
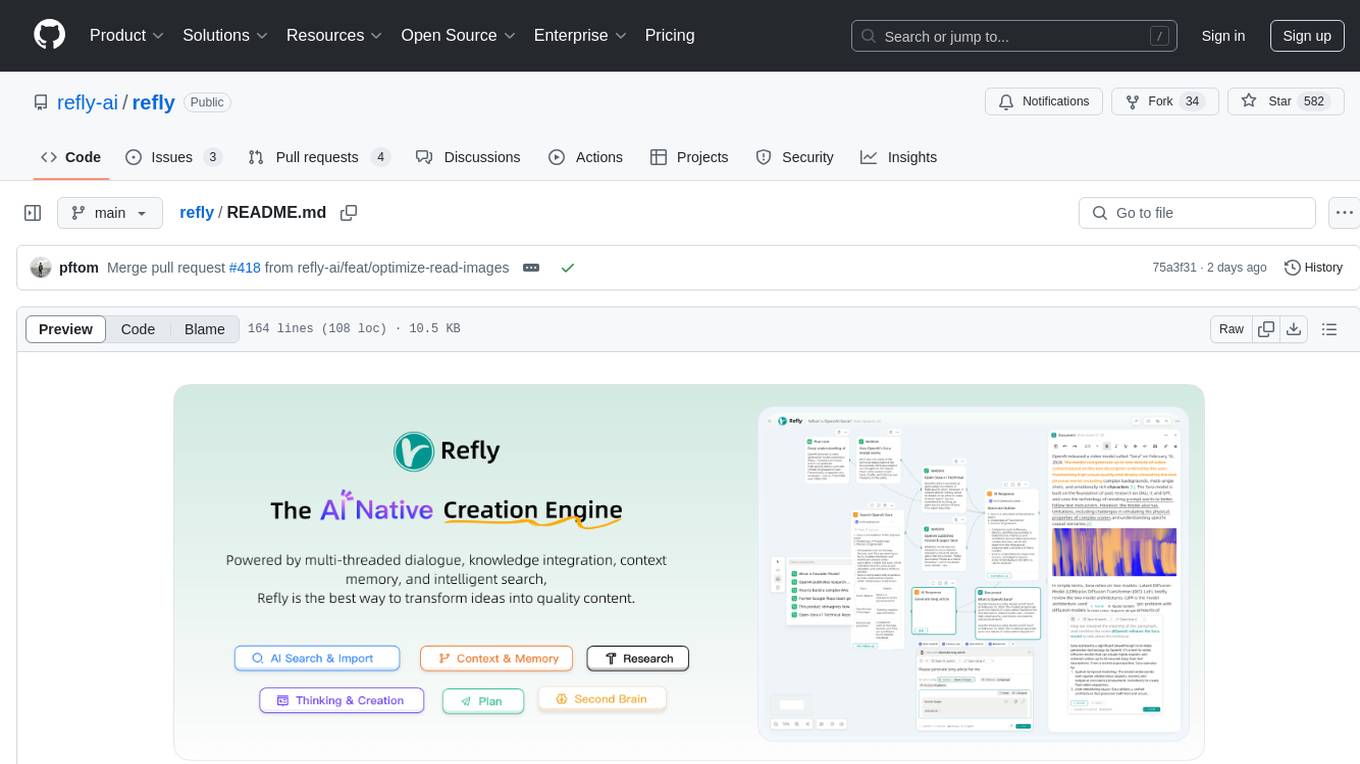
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.

client
DagsHub is a platform for machine learning and data science teams to build, manage, and collaborate on their projects. With DagsHub you can: 1. Version code, data, and models in one place. Use the free provided DagsHub storage or connect it to your cloud storage 2. Track Experiments using Git, DVC or MLflow, to provide a fully reproducible environment 3. Visualize pipelines, data, and notebooks in and interactive, diff-able, and dynamic way 4. Label your data directly on the platform using Label Studio 5. Share your work with your team members 6. Stream and upload your data in an intuitive and easy way, while preserving versioning and structure. DagsHub is built firmly around open, standard formats for your project. In particular: * Git * DVC * MLflow * Label Studio * Standard data formats like YAML, JSON, CSV Therefore, you can work with DagsHub regardless of your chosen programming language or frameworks.
azure-openai-samples
This repository provides resources to understand and utilize GPT (Generative Pre-trained Transformer) by Azure OpenAI. It includes sample solutions, use cases, and quick start guides. Users can explore various applications of GPT, such as chatbots, customer service, and content generation. The repository also offers Langchain, Semantic Kernel, and Prompt Flow samples, along with Serverless SQL GPT for natural language processing in Azure Synapse Analytics. The samples are based on GPT 3.5, with plans to update for GPT-4. Users are encouraged to contribute to keep the repository updated with the latest technologies and solutions.
For similar tasks
ML
Rubix ML is a high-level machine learning and deep learning library for the PHP language. It provides a developer-friendly API with over 40 supervised and unsupervised learning algorithms, support for ETL, preprocessing, and cross-validation. The library is open source and free to use commercially. Rubix ML allows users to build machine learning programs in PHP, covering the entire machine learning life cycle from data processing to training and production. It also offers tutorials and educational content to help users get started with machine learning projects.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.