
ai-explorables
https://pair.withgoogle.com/explorables/
Stars: 53
The ai-explorables repository contains code for AI Explorables, a tool that allows users to make changes in the source code and view the changes locally. It is not an officially supported Google product.
README:
Code for AI Explorables
Make changes in source and view locally with:
yarn && yarn start
open http://localhost:2344/
This is not an officially supported Google product
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-explorables
Similar Open Source Tools
ai-explorables
The ai-explorables repository contains code for AI Explorables, a tool that allows users to make changes in the source code and view the changes locally. It is not an officially supported Google product.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.
aiortc
aiortc is a Python library for Web Real-Time Communication (WebRTC) and Object Real-Time Communication (ORTC). It provides a simple and readable implementation for programmers to understand and tinker with WebRTC internals. The library allows for exchanging audio, video, and data channels, supports SDP generation/parsing, ICE, DTLS, SRTP, SCTP, and various audio/video codecs. It also enables creating innovative products by leveraging Python ecosystem modules, such as computer vision algorithms with OpenCV. Extensive testing ensures high code quality.

studio-b3
Studio B3 (B-3 Bomber) is a sophisticated editor designed for content creation, catering to various formats such as blogs, articles, user stories, and more. It provides an immersive content generation experience with local AI capabilities for intelligent search and recommendation functions. Users can define custom actions and variables for flexible content generation. The editor includes interactive tools like Bubble Menu, Slash Command, and Quick Insert for enhanced user experience in editing, searching, and navigation. The design principles focus on intelligent embedding of AI, local optimization for efficient writing experience, and context flexibility for better control over AI-generated content.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.
aiexe
aiexe is a cutting-edge command-line interface (CLI) and graphical user interface (GUI) tool that integrates powerful AI capabilities directly into your terminal or desktop. It is designed for developers, tech enthusiasts, and anyone interested in AI-powered automation. aiexe provides an easy-to-use yet robust platform for executing complex tasks with just a few commands. Users can harness the power of various AI models from OpenAI, Anthropic, Ollama, Gemini, and GROQ to boost productivity and enhance decision-making processes.
devika
Devika is an advanced AI software engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika utilizes large language models, planning and reasoning algorithms, and web browsing abilities to intelligently develop software. Devika aims to revolutionize the way we build software by providing an AI pair programmer who can take on complex coding tasks with minimal human guidance. Whether you need to create a new feature, fix a bug, or develop an entire project from scratch, Devika is here to assist you.

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.
loras-dev
Loras is an open source real-time AI image generator powered by Flux through Together.ai. It utilizes Flux Dev from BFL for the image model, Together AI for inference, Next.js app router with Tailwind, Helicone for observability, and Plausible for website analytics. Users can clone the repository, add their Together AI API key to a .env.local file, install dependencies, and run the tool locally to generate AI images in real-time.
ChatLab
ChatLab is a free, open-source, and local-first application dedicated to analyzing chat records. Through an AI Agent and a flexible SQL engine, you can freely dissect, query, and even reconstruct your social data. It provides ultimate performance, privacy protection, an intelligent AI Agent, multi-dimensional data visualization, and format standardization. The tool supports chat record analysis for various platforms like LINE, WeChat, QQ, WhatsApp, Instagram, and Discord. Users can export chat records, troubleshoot, and access standardized format specifications. The system architecture includes Electron Main Process, Worker and Data Pipeline, and Rendering Process. Local development setup steps are provided for Node.js environment. Contributions are welcome following specific guidelines. Users are advised to read the Privacy Policy & User Agreement before using the software. The tool is licensed under AGPL-3.0 License.
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.
stagehand
Stagehand is an AI web browsing framework that simplifies and extends web automation using three simple APIs: act, extract, and observe. It aims to provide a lightweight, configurable framework without complex abstractions, allowing users to automate web tasks reliably. The tool generates Playwright code based on atomic instructions provided by the user, enabling natural language-driven web automation. Stagehand is open source, maintained by the Browserbase team, and supports different models and model providers for flexibility in automation tasks.
For similar tasks
Interview-for-Algorithm-Engineer
This repository provides a collection of interview questions and answers for algorithm engineers. The questions are organized by topic, and each question includes a detailed explanation of the answer. This repository is a valuable resource for anyone preparing for an algorithm engineering interview.
PythonPark
PythonPark is a paradise for learning Python, providing babysitter-level tutorials on AI labs, treasure videos, data structures, study guides, machine learning practicals, deep learning practicals, Python basics, web scraping, big company interview experiences, programming life, and resource sharing. Original articles are published at least twice a week, with the latest articles being first released on WeChat and videos on Bilibili. Join the WeChat group for technical discussions or to provide feedback. Continuously improving and outputting content!
ai-explorables
The ai-explorables repository contains code for AI Explorables, a tool that allows users to make changes in the source code and view the changes locally. It is not an officially supported Google product.
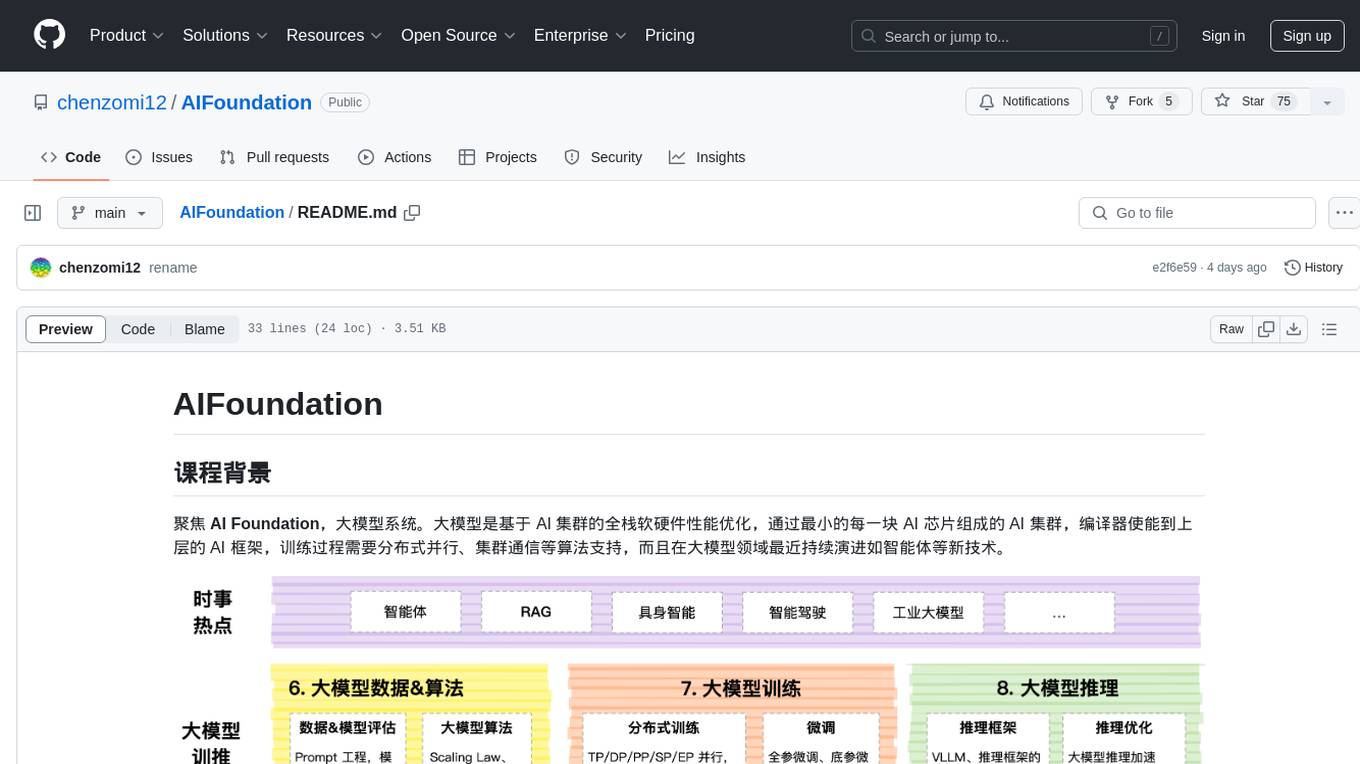
AIFoundation
AIFoundation focuses on AI Foundation, large model systems. Large models optimize the performance of full-stack hardware and software based on AI clusters. The training process requires distributed parallelism, cluster communication algorithms, and continuous evolution in the field of large models such as intelligent agents. The course covers modules like AI chip principles, communication & storage, AI clusters, computing architecture, communication architecture, large model algorithms, training, inference, and analysis of hot technologies in the large model field.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.
Deep-Dive-Into-AI-With-MLX-PyTorch
Deep Dive into AI with MLX and PyTorch is an educational initiative focusing on AI, machine learning, and deep learning using Apple's MLX and Meta's PyTorch frameworks. The repository contains comprehensive guides, in-depth analyses, and resources for learning and exploring AI concepts. It aims to cater to audiences ranging from beginners to experienced individuals, providing detailed explanations, examples, and translations between PyTorch and MLX. The project emphasizes open-source contributions, knowledge sharing, and continuous learning in the field of AI.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.