Best AI tools for< Voice Audiobooks >
20 - AI tool Sites
Wondercraft
Wondercraft is an AI-powered audio studio that enables users to create various audio content such as ads, podcasts, audiobooks, meditations, and more, simply by typing. The platform offers a wide range of features and tools to streamline the audio production process, catering to marketers, entrepreneurs, writers, educators, and content creators. With a user-friendly interface and advanced AI technology, Wondercraft revolutionizes audio content creation by providing high-quality results efficiently and cost-effectively.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.
Voice AI Note
Voice AI Note is a web-based application that allows users to quickly and easily create voice notes using advanced AI. With Voice AI Note, you can create voice notes that are fluent, accurate, and sound natural. The application is easy to use and requires no prior experience with AI or voice recording. Simply enter the text you want to convert to speech, and Voice AI Note will do the rest.

Novels AI
Novels AI is an innovative application that allows users to immerse themselves in personalized AI-generated audiobooks. The app utilizes artificial intelligence to create captivating stories where the user is the main character. With state-of-the-art AI narration and voice synthesis technology, Novels AI offers a unique listening experience across various genres. Users can customize their character, make choices that shape the plot, and explore endless storytelling possibilities. Whether you seek to unwind with an engaging story or experience the future of audiobooks, Novels AI provides a gateway to a new world of AI-powered storytelling.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
MyVocal.ai
MyVocal.ai is a text-to-speech and voice cloning tool that allows users to create realistic-sounding voices from text. With MyVocal.ai, you can clone your own voice or choose from a variety of pre-recorded voices. You can then use these voices to create songs, audiobooks, podcasts, and other audio content. MyVocal.ai also offers a variety of features to help you customize your voice, including the ability to change the pitch, speed, and volume. Additionally, MyVocal.ai offers a variety of features to help you create high-quality audio content, including the ability to add background music and sound effects.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
SpeechEasy
SpeechEasy is a high-quality text-to-speech tool that harnesses the power of AI and machine learning to convert text into natural-sounding audio. With SpeechEasy, you can generate studio-grade synthetic voices that are easy to understand and consume, making it perfect for on-the-go listening, home or office use, and e-learning content.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.

SRVO
SRVO is a voice over service that provides high-quality, professional voice overs for a variety of purposes, including commercials, e-learning, and audiobooks. With a team of experienced voice actors and a state-of-the-art recording studio, SRVO can create custom voice overs that meet the specific needs of each client. SRVO also offers a variety of additional services, such as scriptwriting, audio editing, and mixing.
Acryl
Acryl is an AI-powered tool that helps parents create audiobooks for their children. With Acryl, parents can take photos of any book and have Acryl generate an audiobook from it. Acryl's audiobooks are dynamic and use a unique voice for each character in the book. Acryl also offers a variety of features to help parents manage their children's listening time, such as the ability to set time limits and track how much time their child has spent listening.
Replica Studios
Replica Studios is an AI tool that provides cutting-edge text-to-speech and speech-to-speech solutions in multiple languages for creative professionals. It offers fully licensed AI models safe for commercial use, allowing users to customize voices for various creative and professional use cases, such as gaming, animation, film, audiobooks, e-learning, and social media. The tool enables users to generate voice overs and dialogue instantly, manage scripts, and create unique voices using Voice Lab. Replica Studios prioritizes ethical voice AI by collaborating with voice actors and ensuring commercial use compliance.
Create AI Voiceovers
Create AI Voiceovers is an online text-to-speech generator that allows users to convert text into realistic-sounding AI voices. With over 530 AI voices available in 220+ languages and dialects, users can create voiceovers for various purposes, including marketing, eLearning, explainer videos, and animations. The platform offers a range of features, including the ability to adjust voice attributes such as pitch, emphasis, and speed, as well as add background music and sound effects. Create AI Voiceovers also provides a library of pre-recorded sound effects and music that users can incorporate into their voiceovers.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.
Speechify
Speechify is the #1 rated AI text to speech app in its category with over 250,000 5 star reviews. It is available as a Chrome extension, iOS app, Android app, Microsoft Edge Add-on, and web app. Speechify can convert any text into natural-sounding AI voice in over 50 languages and accents. It can also read aloud any PDF, doc, or web page. Speechify is used by students, professionals, readers, and those who struggle to read. It can help with reading comprehension, focus, and retention. Speechify is also a great tool for people with disabilities such as dyslexia, ADHD, and dry eyes.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
20 - Open Source AI Tools
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
AI.Labs
AI.Labs is an open-source project that integrates advanced artificial intelligence technologies to create a powerful AI platform. It focuses on integrating AI services like large language models, speech recognition, and speech synthesis for functionalities such as dialogue, voice interaction, and meeting transcription. The project also includes features like a large language model dialogue system, speech recognition for meeting transcription, speech-to-text voice synthesis, integration of translation and chat, and uses technologies like C#, .Net, SQLite database, XAF, OpenAI API, TTS, and STT.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.


amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
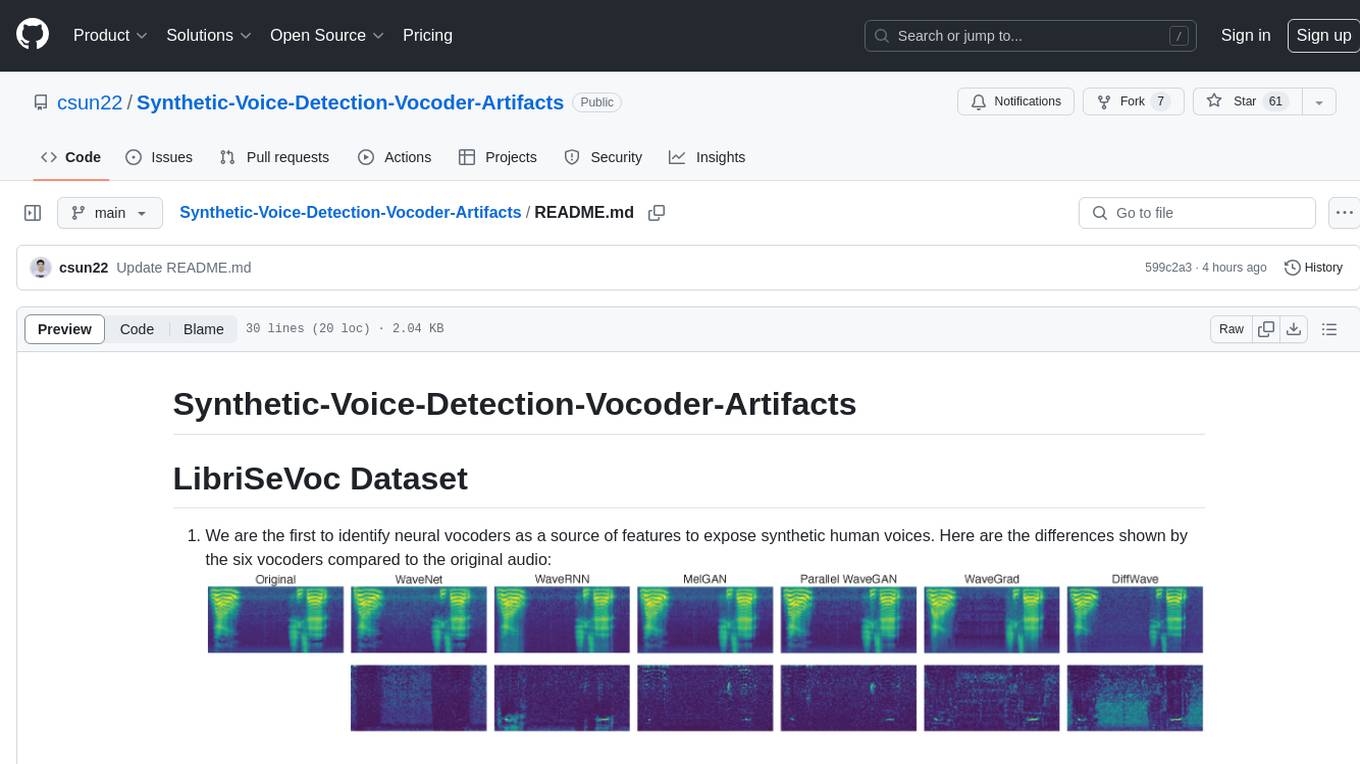
Synthetic-Voice-Detection-Vocoder-Artifacts
The Synthetic-Voice-Detection-Vocoder-Artifacts repository provides the LibriSeVoc dataset containing self-vocoding samples created with six state-of-the-art vocoders to expose and exploit vocoder artifacts. It also introduces a new approach for detecting synthetic human voices by identifying signal artifacts left by neural vocoders and enhancing the RawNet2 baseline. The repository includes a paper and dataset for further reference and offers instructions for training the model and testing it in the wild.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
20 - OpenAI Gpts
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.