Best AI tools for< Extract Structured Data >
20 - AI tool Sites
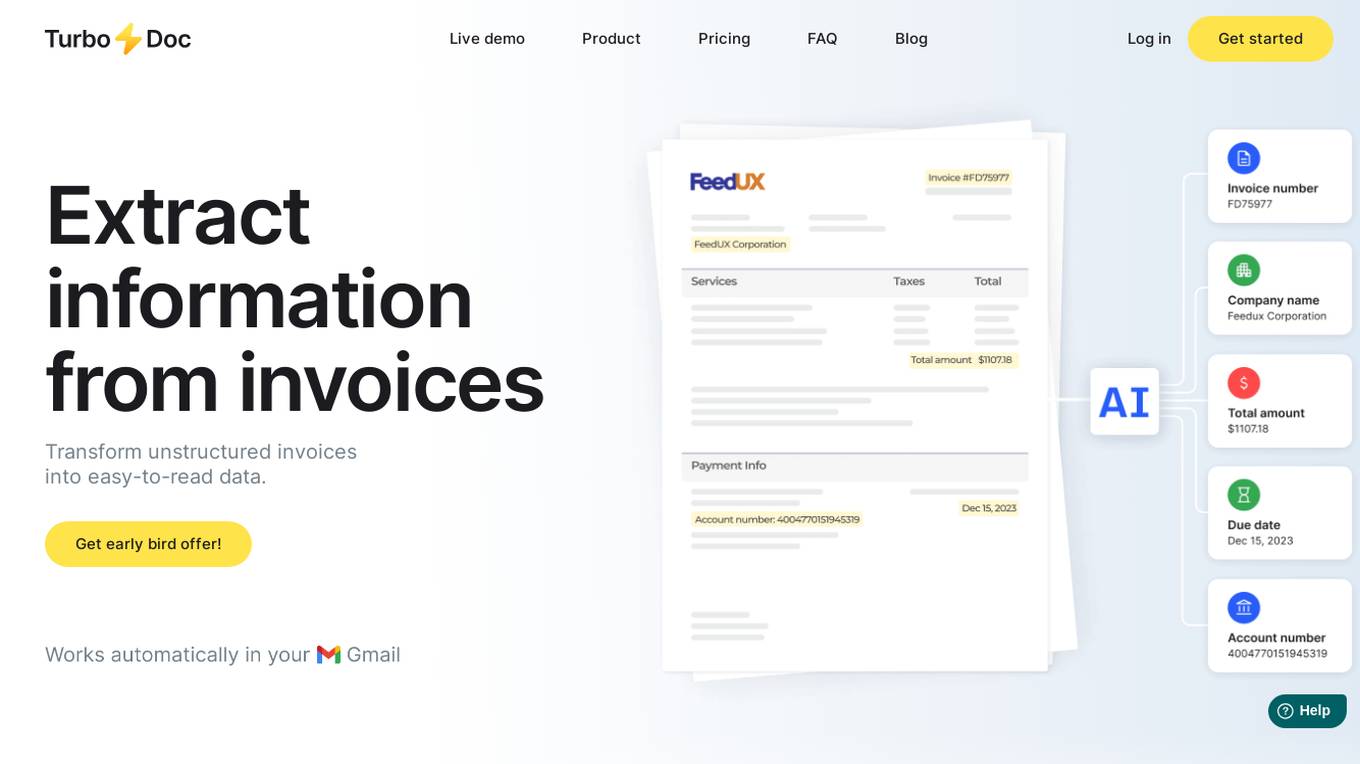
TurboDoc
TurboDoc is an AI-powered tool designed to extract information from invoices and transform unstructured data into easy-to-read structured data. It offers a user-friendly interface for efficient work with accounts payable, budget planning, and control. The tool ensures high accuracy through advanced AI models and provides secure data storage with AES256 encryption. Users can automate invoice processing, link Gmail for seamless integration, and optimize workflow with various applications.
Airparser
Airparser is an AI-powered email and document parser tool that revolutionizes data extraction by utilizing the GPT parser engine. It allows users to automate the extraction of structured data from various sources such as emails, PDFs, documents, and handwritten texts. With features like automatic extraction, export to multiple platforms, and support for multiple languages, Airparser simplifies data extraction processes for individuals and businesses. The tool ensures data security and offers seamless integration with other applications through APIs and webhooks.
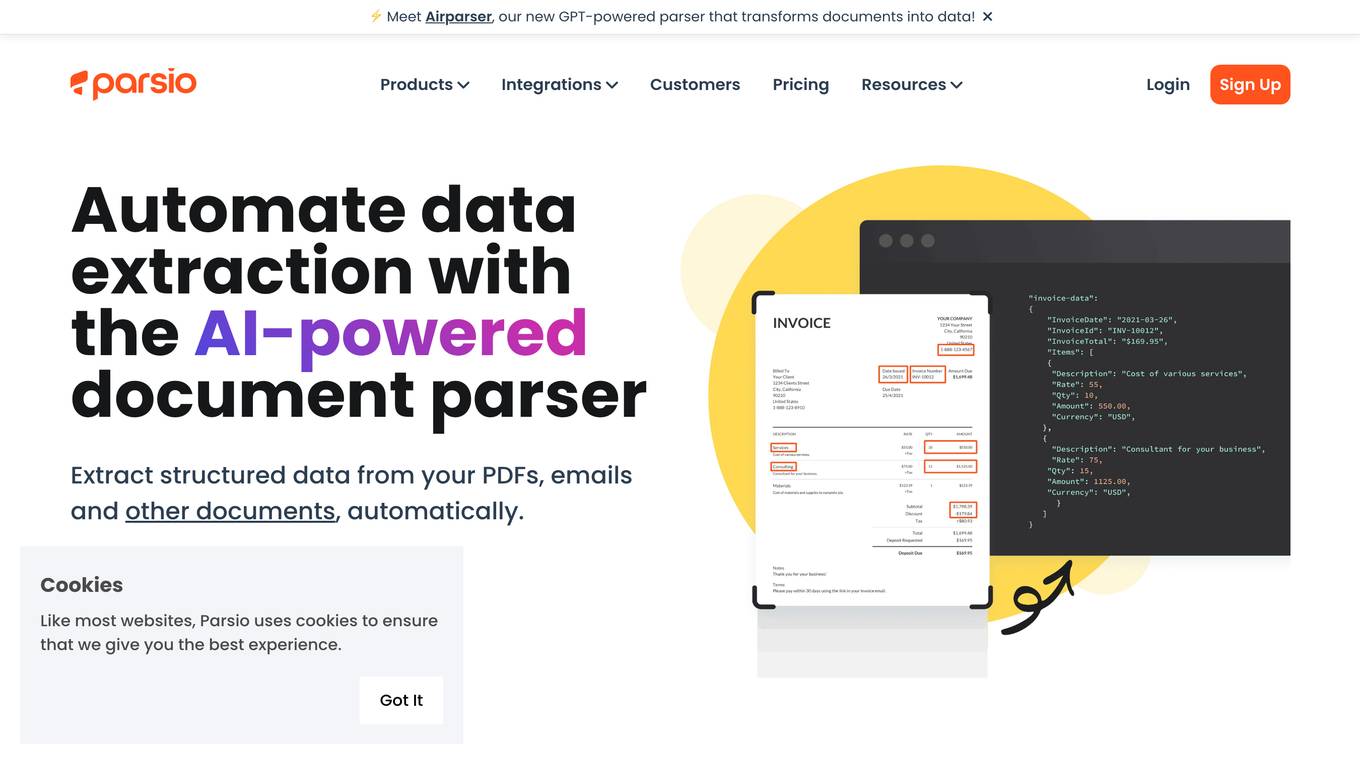
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.
Jsonify
Jsonify is an AI tool that automates the process of exploring and understanding websites to find, filter, and extract structured data at scale. It uses AI-powered agents to navigate web content, replacing traditional data scrapers and providing data insights with speed and precision. Jsonify integrates with leading data analysis and business intelligence suites, allowing users to visualize and gain insights into their data easily. The tool offers a no-code dashboard for creating workflows and easily iterating on data tasks. Jsonify is trusted by companies worldwide for its ability to adapt to page changes, learn as it runs, and provide technical and non-technical integrations.
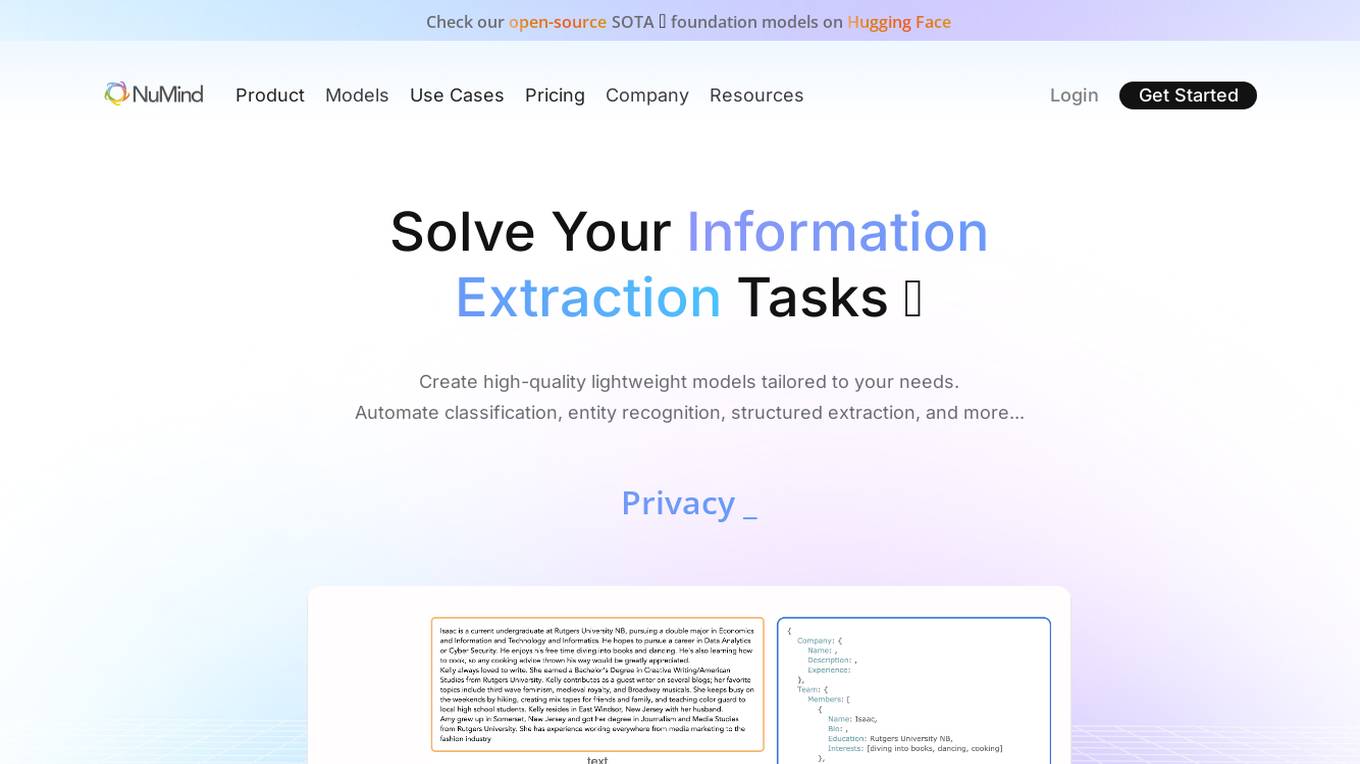
NuMind
NuMind is an AI tool designed to solve information extraction tasks efficiently. It offers high-quality lightweight models tailored to users' needs, automating classification, entity recognition, and structured extraction. The tool is powered by task-specific and domain-agnostic foundation models, outperforming GPT-4 and similar models. NuMind provides solutions for various industries such as insurance and healthcare, ensuring privacy, cost-effectiveness, and faster NLP projects.
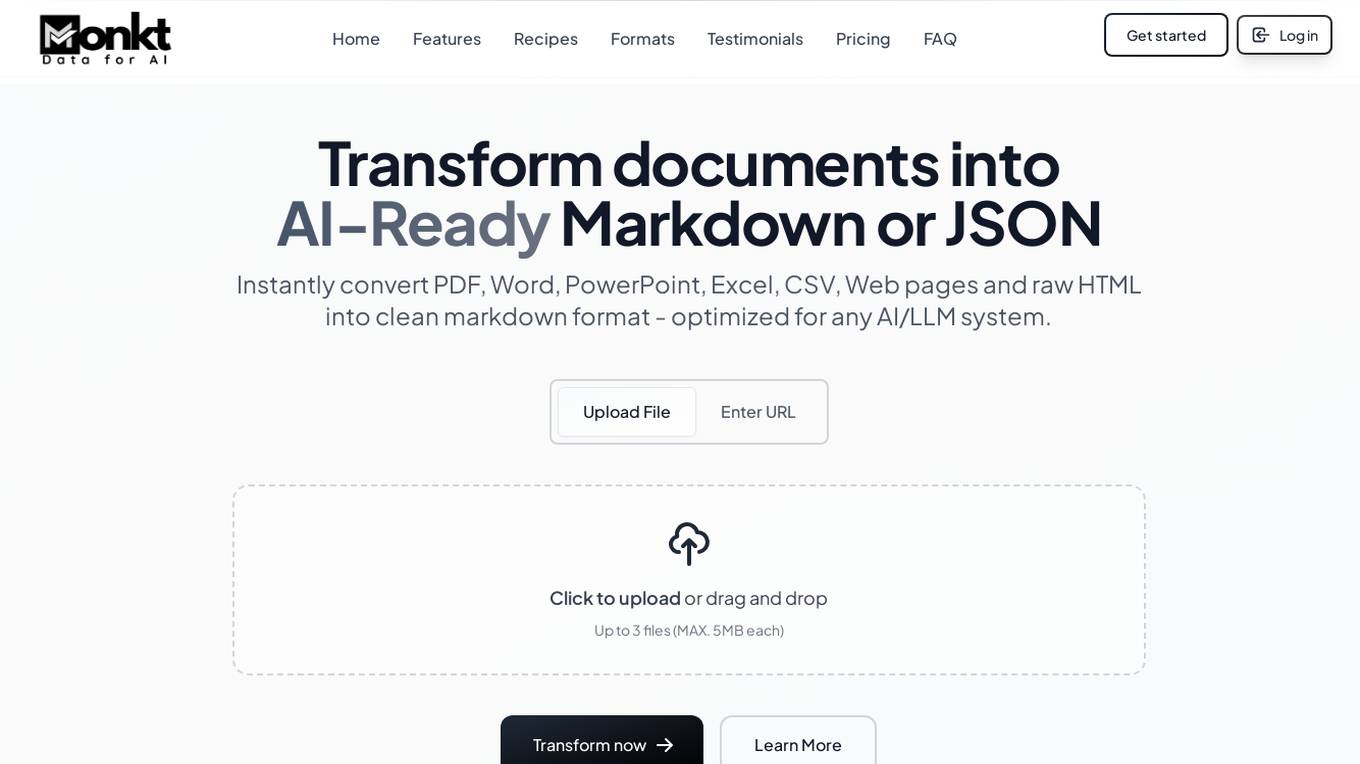
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
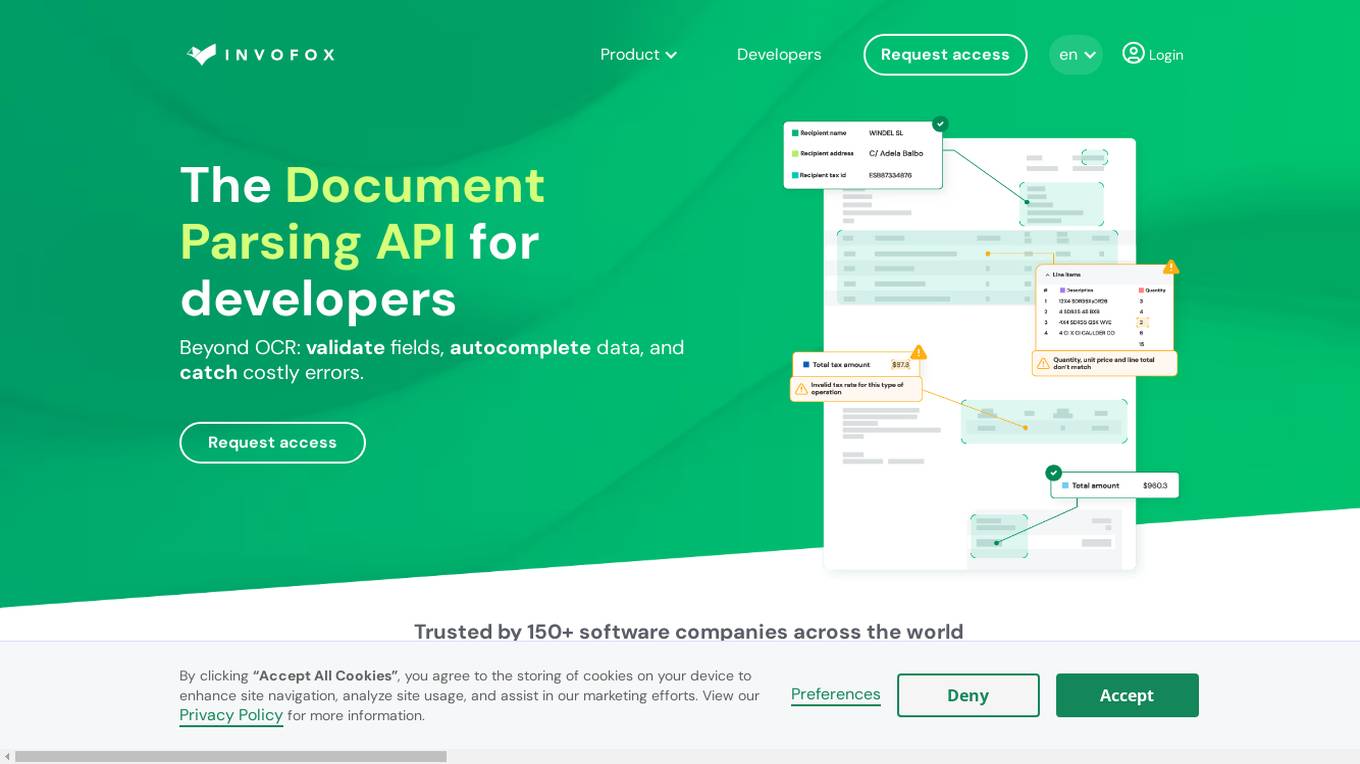
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
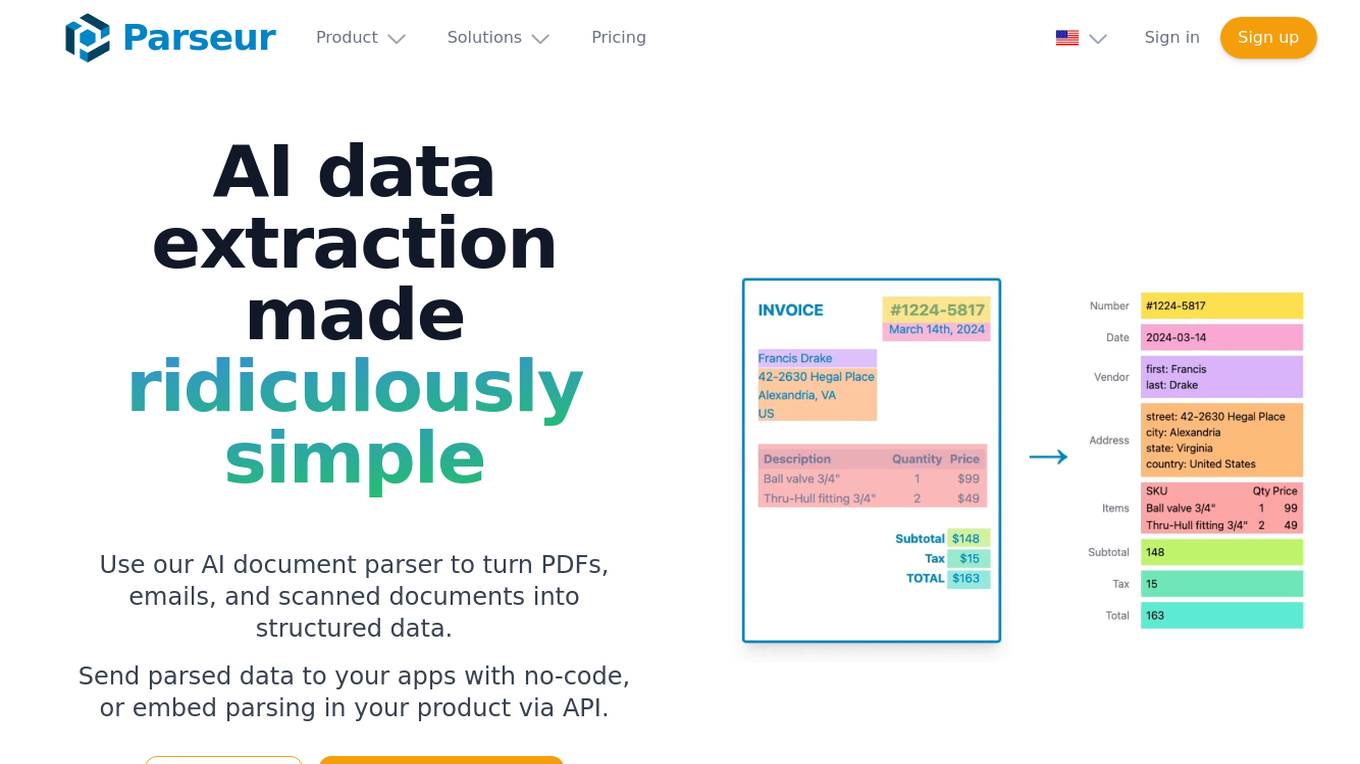
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
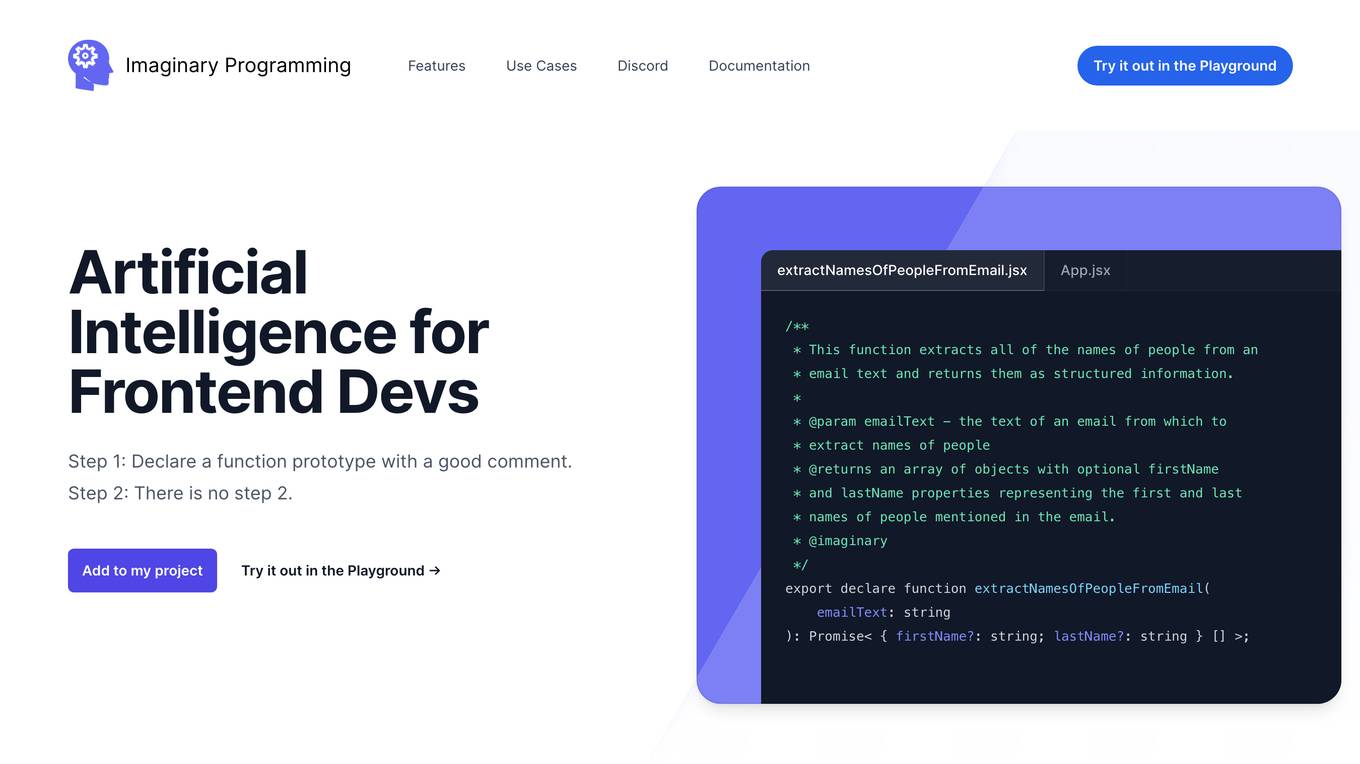
Imaginary Programming
Imaginary Programming is an AI tool that allows frontend developers to leverage OpenAI's GPT engine to add human-like intelligence to their code effortlessly. By defining function prototypes in TypeScript, developers can access GPT's capabilities without the need for AI model training. The tool enables users to extract structured data, generate text, classify data based on intent or emotion, and parse unstructured language. Imaginary Programming is designed to help developers tackle new challenges and enhance their projects with AI intelligence.
Pipeless Agents
Pipeless Agents is a platform that allows users to convert any video feed into an actionable data stream, enabling automation of tasks based on visual inputs. It serves as a serverless platform for Vision AI, offering the ability to create projects, connect video sources, and customize agents for specific needs. With a focus on simplicity and efficiency, Pipeless Agents empowers users to extract structured data from various video sources and automate processes with minimal coding requirements.
Altilia
Altilia is a Major Player in the Intelligent Document Processing market, offering a cloud-native, no-code, SaaS platform powered by composite AI. The platform enables businesses to automate complex document processing tasks, streamline workflows, and enhance operational performance. Altilia's solution leverages GPT and Large Language Models to extract structured data from unstructured documents, providing significant efficiency gains and cost savings for organizations of all sizes and industries.
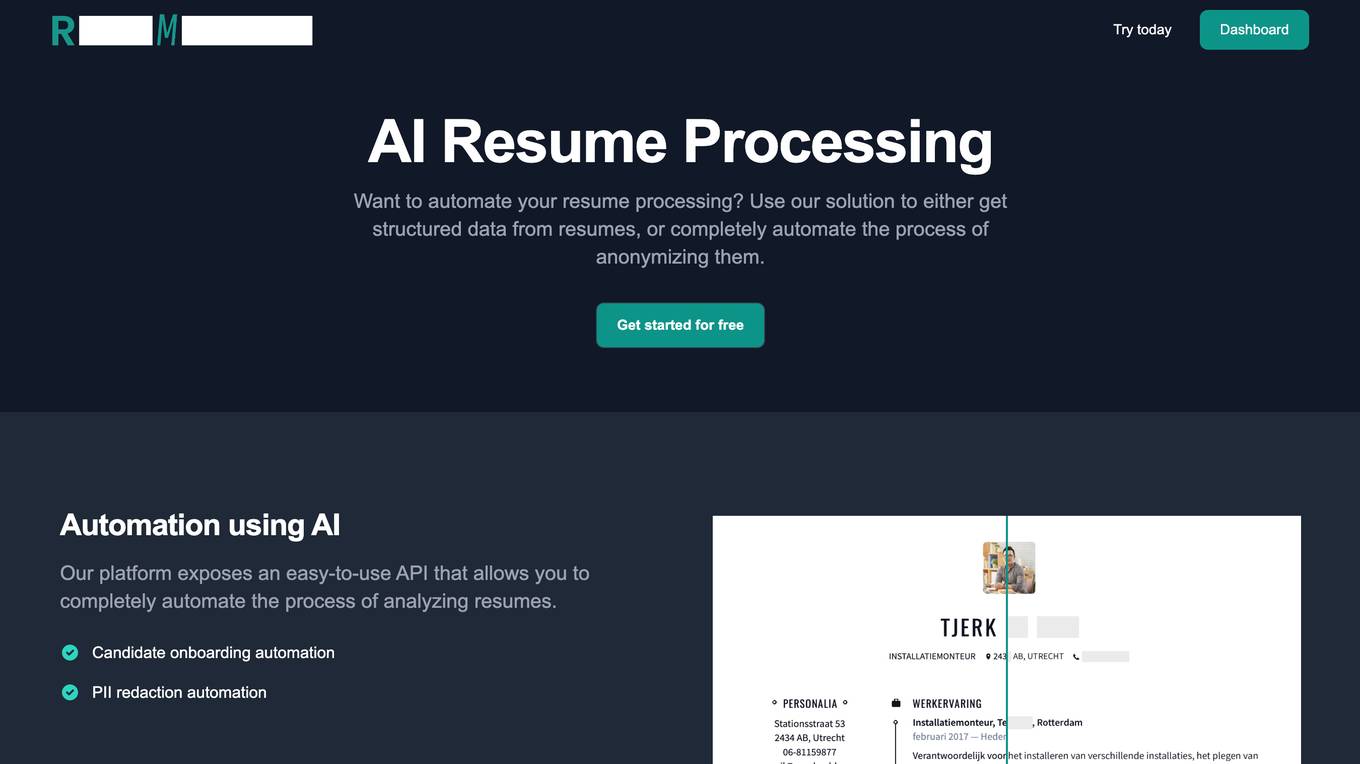
ResuMetrics
ResuMetrics is an AI-powered platform designed to streamline the resume processing workflow. It offers solutions to extract structured data from resumes and automate the anonymization process. The platform provides an easy-to-use API for automating resume analysis, including candidate onboarding and PII redaction. With features like resume scoring and vacancy matching on the roadmap, ResuMetrics aims to enhance the efficiency of resume processing tasks. Users can choose from different subscription plans based on their processing needs, with credits consumed per document page. Overall, ResuMetrics is a comprehensive tool for organizations looking to optimize their resume processing operations.
Shopstory
Shopstory is an AI automation tool designed for marketing teams and agencies to automate, optimize, and save time in building scalable processes. It offers a versatile flow builder, Excel-like formulas, and AI actions to generate content and extract structured data. With over 2,600 integrations and efficient flow management, Shopstory helps users automate at scale and drive results across all clients. The tool provides dedicated onboarding and support, pre-built automations, and guided setups for quick implementation.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.
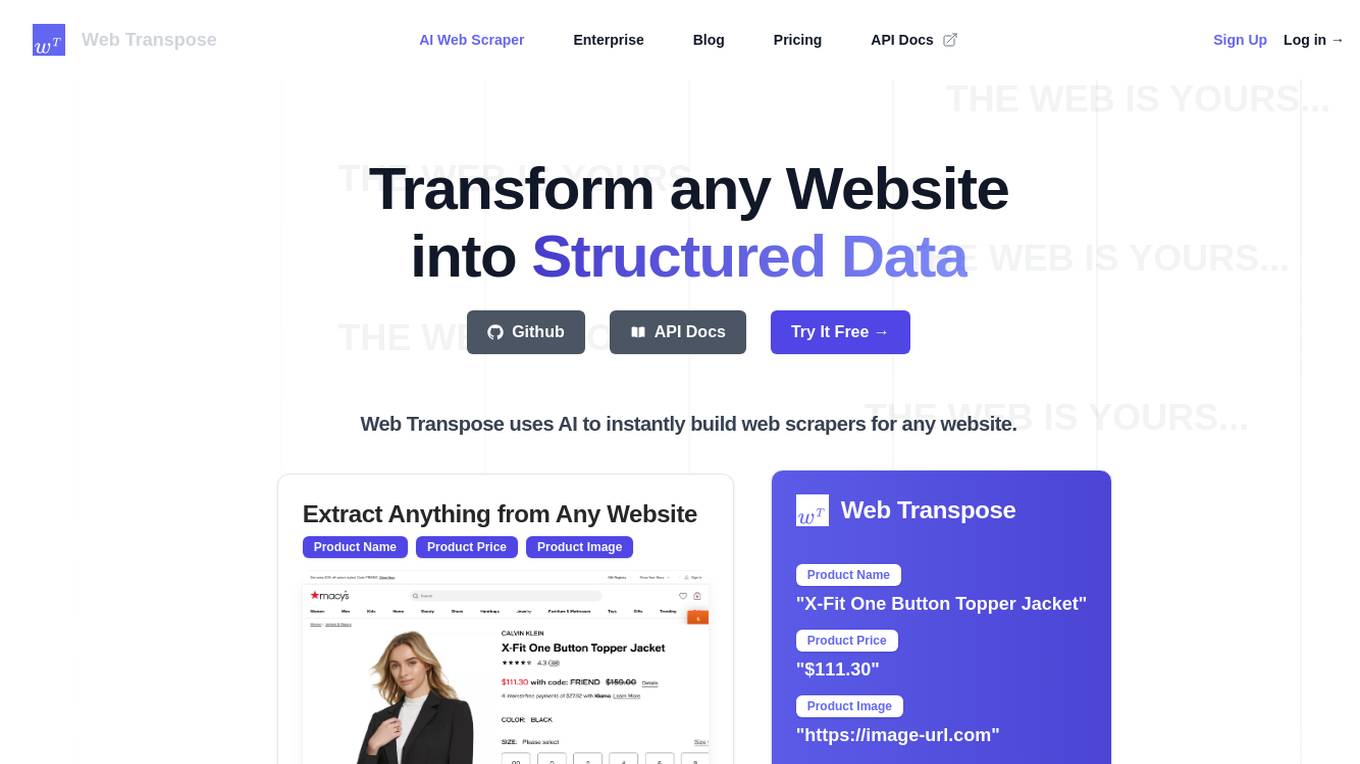
Web Transpose
Web Transpose is an AI-powered web scraping and web crawling API that allows users to transform any website into structured data. By utilizing artificial intelligence, Web Transpose can instantly build web scrapers for any website, enabling users to extract valuable information efficiently and accurately. The tool is designed for production use, offering low latency and effective proxy handling. Web Transpose learns the structure of the target website, reducing latency and preventing hallucinations commonly associated with traditional web scraping methods. Users can query any website like an API and build products quickly using the scraped data.
PDFMerse
PDFMerse is an AI-powered data extraction tool that revolutionizes how users handle document data. It allows users to effortlessly extract information from PDFs with precision, saving time and enhancing workflow. With cutting-edge AI technology, PDFMerse automates data extraction, ensures data accuracy, and offers versatile output formats like CSV, JSON, and Excel. The tool is designed to dramatically reduce processing time and operational costs, enabling users to focus on higher-value tasks.
Extracta.ai
Extracta.ai is an AI data extraction tool for documents and images that automates data extraction processes with easy integration. It allows users to define custom templates for extracting structured data without the need for training. The platform can extract data from various document types, including invoices, resumes, contracts, receipts, and more, providing accurate and efficient results. Extracta.ai ensures data security, encryption, and GDPR compliance, making it a reliable solution for businesses looking to streamline document processing.
Isomeric
Isomeric is an AI tool that utilizes artificial intelligence to semantically understand unstructured text and extract specific data. It transforms messy, unstructured text into machine-readable JSON, enabling users to extract insights, process data, deliver results, and more. From web scraping to browser extensions to general information extraction, Isomeric helps users scale their data gathering pipeline efficiently.
DocuPipe
DocuPipe is an AI-powered document extraction tool that helps businesses convert various types of documents into structured data. It uses artificial intelligence to extract information from documents such as invoices, medical records, insurance claims, and more. DocuPipe offers custom definitions tailored for different businesses to accurately extract required data. The tool ensures security and compliance by encrypting documents and being GDPR and HIPAA compliant. With features like OCR, document standardization, and document splitting, DocuPipe provides accuracy, flexibility, and speed in handling documents.
15 - Open Source AI Tools

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

NeMo-Guardrails
NeMo Guardrails is an open-source toolkit for easily adding _programmable guardrails_ to LLM-based conversational applications. Guardrails (or "rails" for short) are specific ways of controlling the output of a large language model, such as not talking about politics, responding in a particular way to specific user requests, following a predefined dialog path, using a particular language style, extracting structured data, and more.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.
awesome-llm-json
This repository is an awesome list dedicated to resources for using Large Language Models (LLMs) to generate JSON or other structured outputs. It includes terminology explanations, hosted and local models, Python libraries, blog articles, videos, Jupyter notebooks, and leaderboards related to LLMs and JSON generation. The repository covers various aspects such as function calling, JSON mode, guided generation, and tool usage with different providers and models.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
stagehand
Stagehand is an AI web browsing framework that simplifies and extends web automation using three simple APIs: act, extract, and observe. It aims to provide a lightweight, configurable framework without complex abstractions, allowing users to automate web tasks reliably. The tool generates Playwright code based on atomic instructions provided by the user, enabling natural language-driven web automation. Stagehand is open source, maintained by the Browserbase team, and supports different models and model providers for flexibility in automation tasks.
azure-ai-document-processing-samples
This repository contains a collection of code samples that demonstrate how to use various Azure AI capabilities to process documents. The samples help engineering teams establish techniques with Azure AI Foundry, Azure OpenAI, Azure AI Document Intelligence, and Azure AI Language services to build solutions for extracting structured data, classifying, and analyzing documents. The techniques simplify custom model training, improve reliability in document processing, and simplify document processing workflows by providing reusable code and patterns that can be easily modified and evaluated for most use cases.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It supports features like scrape, crawl, search, extract, and batch scrape. It provides web scraping with JS rendering, URL discovery, web search with content extraction, automatic retries with exponential backoff, credit usage monitoring, comprehensive logging system, support for cloud and self-hosted FireCrawl instances, mobile/desktop viewport support, and smart content filtering with tag inclusion/exclusion. The server includes configurable parameters for retry behavior and credit usage monitoring, rate limiting and batch processing capabilities, and tools for scraping, batch scraping, checking batch status, searching, crawling, and extracting structured information from web pages.
leettools
LeetTools is an AI search assistant that can perform highly customizable search workflows and generate customized format results based on both web and local knowledge bases. It provides an automated document pipeline for data ingestion, indexing, and storage, allowing users to focus on implementing workflows without worrying about infrastructure. LeetTools can run with minimal resource requirements on the command line with configurable LLM settings and supports different databases for various functions. Users can configure different functions in the same workflow to use different LLM providers and models.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.

instructor
Instructor is a tool that provides structured outputs from Large Language Models (LLMs) in a reliable manner. It simplifies the process of extracting structured data by utilizing Pydantic for validation, type safety, and IDE support. With Instructor, users can define models and easily obtain structured data without the need for complex JSON parsing, error handling, or retries. The tool supports automatic retries, streaming support, and extraction of nested objects, making it production-ready for various AI applications. Trusted by a large community of developers and companies, Instructor is used by teams at OpenAI, Google, Microsoft, AWS, and YC startups.
Documents-Parsing-Lab
A curated collection of Jupyter notebooks for experimenting with state-of-the-art OCR, document parsing, table extraction, and chart understanding techniques. This repository enables easy benchmarking and practical usage of the latest open-source and cloud-based solutions for document image processing.
receipt-ocr
An efficient OCR engine for receipt image processing, providing a comprehensive solution for Optical Character Recognition (OCR) on receipt images. The repository includes a dedicated Tesseract OCR module and a general receipt processing package using LLMs. Users can extract structured data from receipts, configure environment variables for multiple LLM providers, process receipts using CLI or programmatically in Python, and run the OCR engine as a Docker web service. The project also offers direct OCR capabilities using Tesseract and provides troubleshooting tips, contribution guidelines, and license information under the MIT license.
exstruct
ExStruct is an Excel structured extraction engine that reads Excel workbooks and outputs structured data as JSON, including cells, table candidates, shapes, charts, smartart, merged cell ranges, print areas/views, auto page-break areas, and hyperlinks. It offers different output modes, formula map extraction, table detection tuning, CLI rendering options, and graceful fallback in case Excel COM is unavailable. The tool is designed to fit LLM/RAG pipelines and provides benchmark reports for accuracy and utility. It supports various formats like JSON, YAML, and TOON, with optional extras for rendering and full extraction targeting Windows + Excel environments.
20 - OpenAI Gpts
Message Header Analyzer
Analyzes email headers for security insights, presenting data in a structured table view.
Summary of articles by density chain
This prompt is structured to provide an effective methodology in generating progressively more detailed and specific summaries, focused on key entities.
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR
Bio Abstract Expert
Generate a structured abstract for academic papers, primarily in the field of biology, adhering to a specified word count range. Simply upload your manuscript file (without the abstract) and specify the word count (for example, '200-250') to GPT.
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Receipt CSV Formatter
Extract from receipts to CSV: Date of Purchase, Item Purchased, Quantity Purchased, Units
PDF AI
PDFChat : Analyse 1000's of PDF's in seconds, extract and chat with PDFs in any language.
Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!