Best AI tools for< audio transcription >
20 - AI tool Sites

Vscoped
Vscoped is an AI-powered audio to text transcribing service that provides fast and accurate transcriptions in over 90 languages. It also offers transcription insights and translation services. Vscoped is suitable for various types of audio content, including business meetings, interviews, sales calls, and videos. With its exceptional accuracy, multilingual capabilities, and intuitive user experience, Vscoped helps businesses and individuals boost productivity and gain insights from their audio data.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio files using domain-specific speech recognition technology. The platform supports various file formats, transcribes in multiple languages, and provides domain-optimized models for increased recognition accuracy. Users can edit and export transcriptions, benefit from automatic punctuation, and utilize a speaker identification service. With a word error rate of 3.8%, SpeechText.AI's speech recognition technology rivals human transcriptionists, making it a valuable tool for various industries.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.
Transkriptor
Transkriptor is an online transcription software that converts audio or video to text using state-of-the-art AI. It offers a range of features such as automatic meeting notes generation, AI-powered conversation assistant, transcription in over 100 languages, remote collaboration, and file format conversion. Transkriptor is trusted by over 100,000 customers worldwide and has received positive reviews for its accuracy, affordability, and ease of use.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
Otter.ai
Otter.ai is an AI meeting assistant application that provides users with the ability to record audio, write notes, automatically capture slides, and generate meeting summaries. Users can collaborate with teammates in real-time, add comments, highlight key points, and assign action items. Otter.ai helps companies and organizations to write notes and summarize meetings 30 times faster. The application also offers features like automated slide capture and automated meeting notes, which can be connected to Google or Microsoft calendar to join and record meetings on platforms like Zoom, Microsoft Teams, and Google Meet. Otter.ai aims to streamline meeting processes and enhance productivity by leveraging AI technology.
Whisper API
Whisper API is an affordable transcription API that can be used to transcribe audio and video files. It is a cloud-based service that is easy to use and can be integrated with a variety of applications. Whisper API is powered by artificial intelligence, which allows it to transcribe audio and video files with high accuracy.
Bytecap
Bytecap is an AI tool that allows users to immerse their videos with custom AI captions. With advanced speech recognition, users can auto-create 99% accurate captions quickly. The tool offers customization options for fonts, colors, emojis, effects, music, and highlights. Additionally, Bytecap provides AI-generated hook titles, descriptions, and keyword highlights to boost engagement. Users can download captions in various formats and choose from expertly crafted caption themes. Bytecap caters to video editors, content creators, podcasters, and streamers, making custom captioning accessible to all without requiring video editing skills.
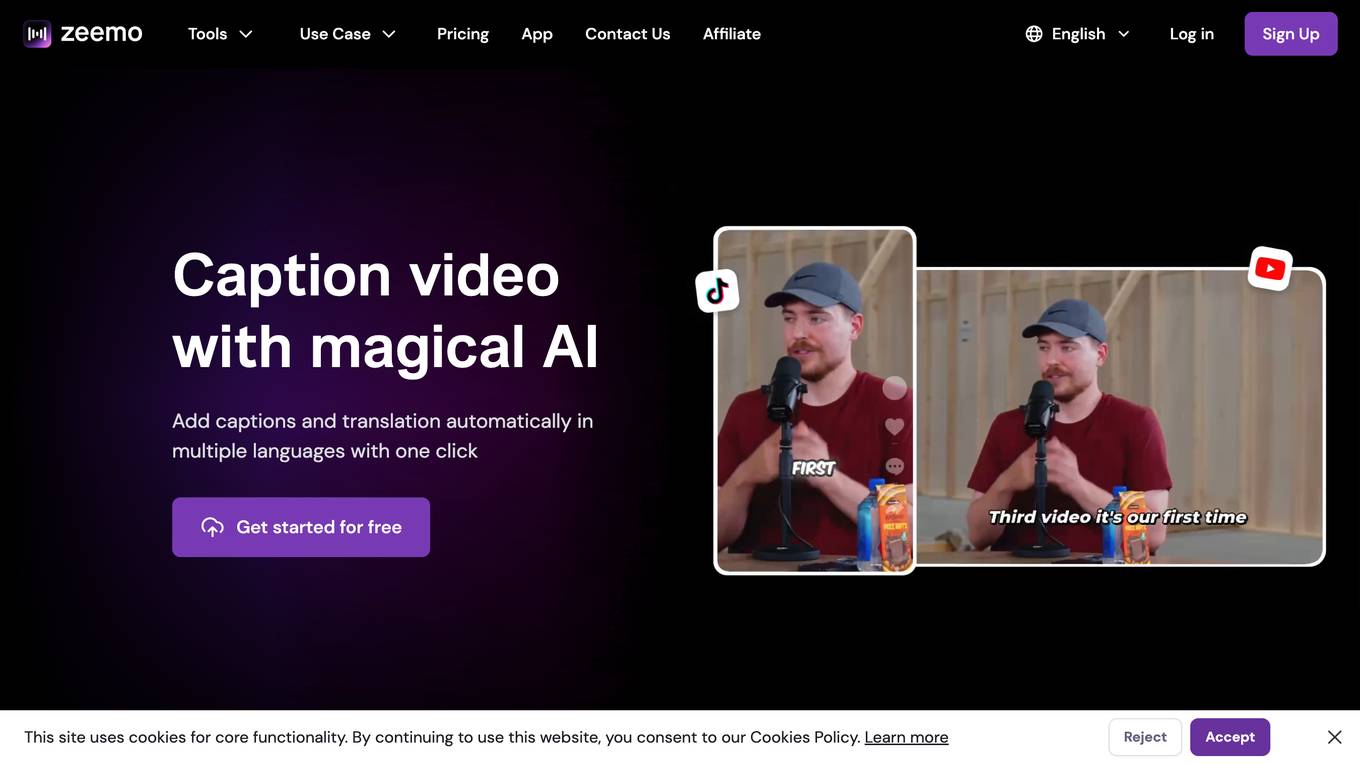
Zeemo AI
Zeemo AI is a powerful caption generator and subtitle tool that enables users to add subtitles to videos effortlessly. It offers AI-powered caption editing, translation to multiple languages, dynamic visual effects, video resizing for different platforms, and target video platform customization. Zeemo AI saves time for video creators, enhances video accessibility and engagement, and provides benefits to content creators, product sellers, educators, and cross-platform users. The application supports over 113 languages, offers accurate transcription, and is user-friendly for various professionals across different industries.
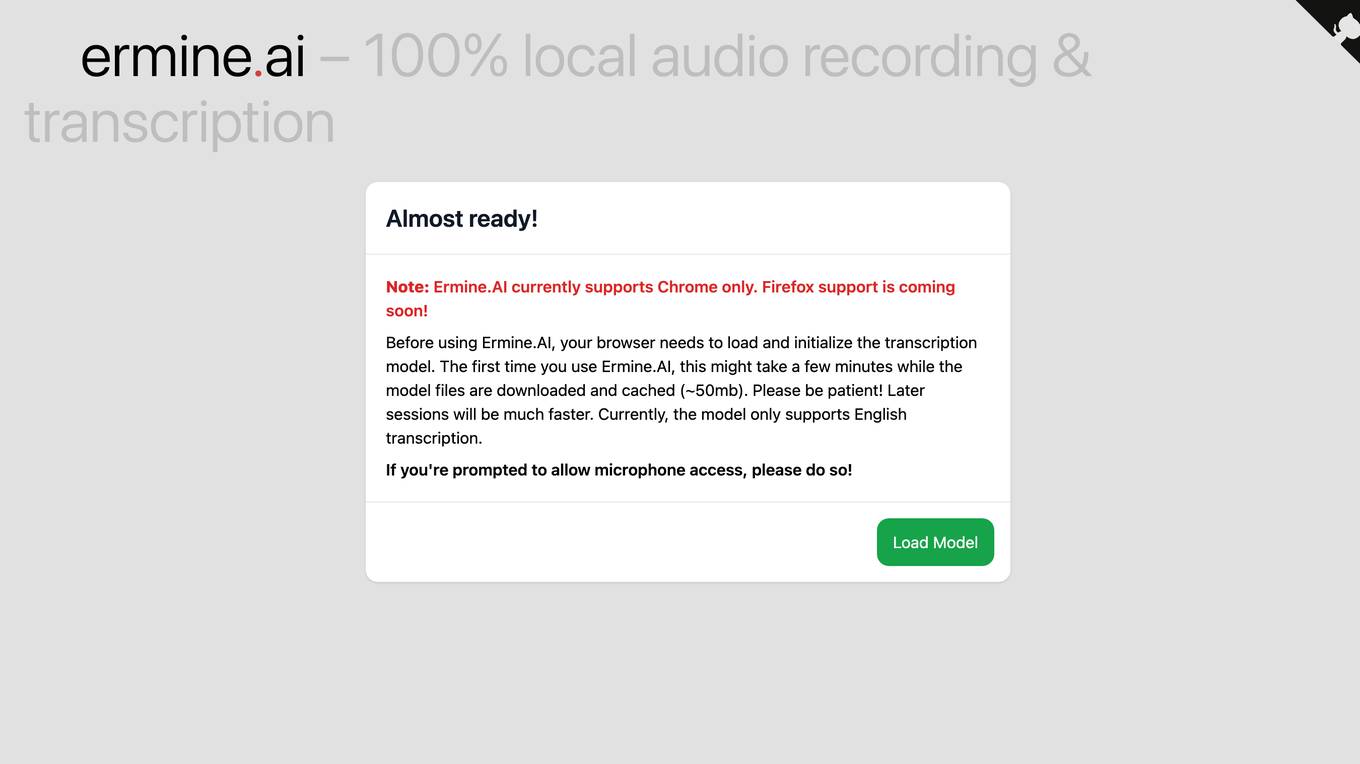
Ermine.ai
Ermine.ai is an AI-powered tool for local audio recording and transcription. It allows users to transcribe audio files in real-time using their web browser. The tool currently supports Chrome browser and is working on adding support for Firefox. Users can easily transcribe audio files into text with high accuracy and efficiency. Ermine.AI utilizes a transcription model that needs to be loaded and initialized in the browser before use, which may take a few minutes for the first session. The tool is designed to streamline the transcription process and improve productivity for users requiring transcription services.
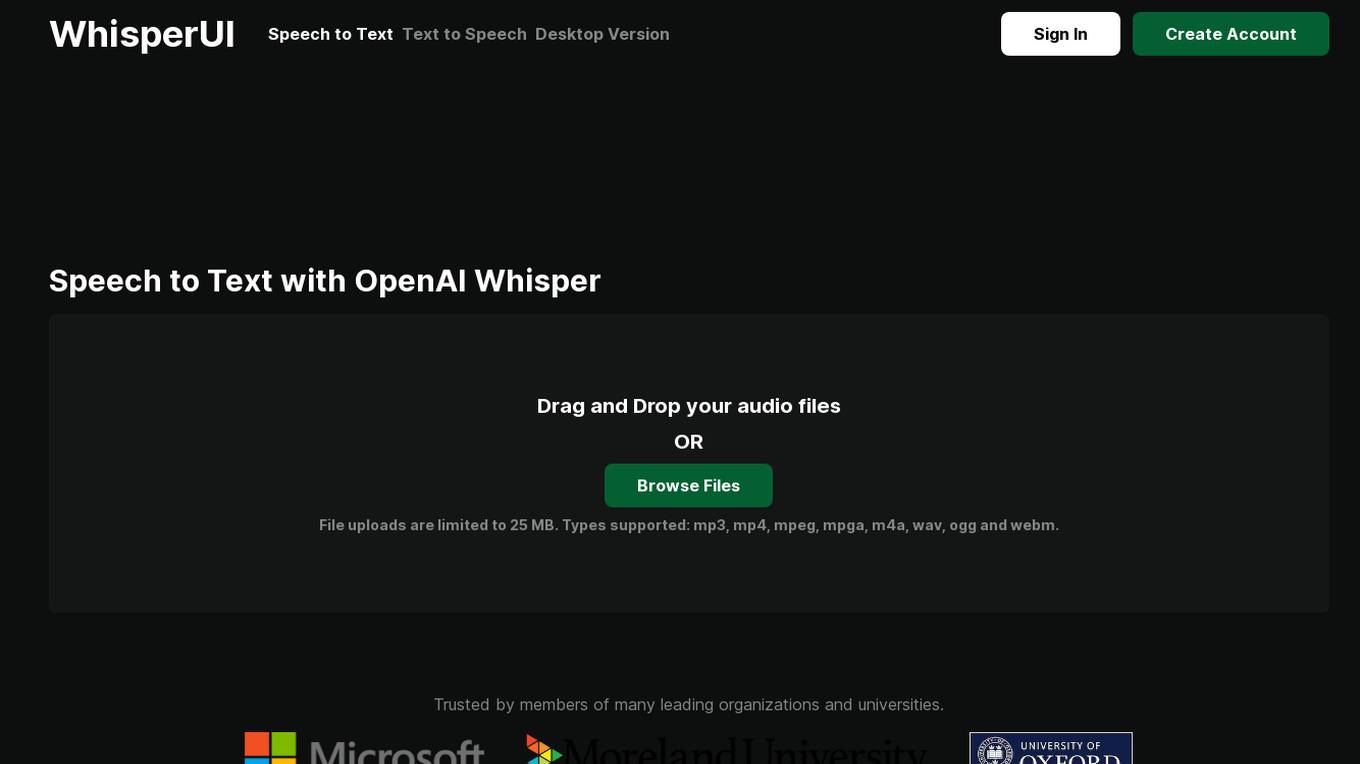
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
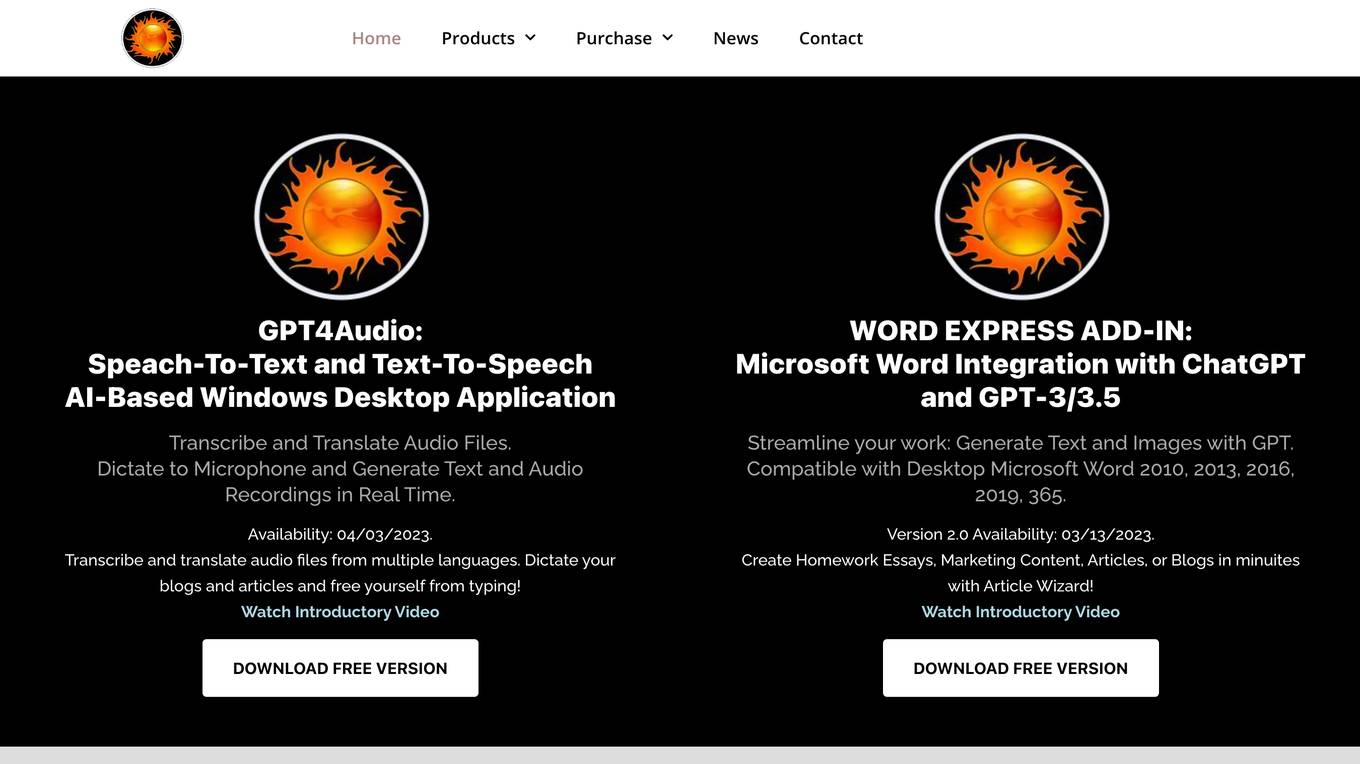
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
GoWhisper
GoWhisper is a privacy-first, cross-platform desktop application for local audio transcription. It allows users to transcribe audio files on their local machine without the need for monthly subscriptions. With support for up to 99 languages and various file formats, users can easily transcribe their audio content and export the results in different formats. The application is ideal for researchers, podcasters, content creators, journalists, small business owners, and legal professionals looking for accurate and efficient transcription services.
Easy-Peasy.AI
Easy-Peasy.AI is an AI-powered content creation and copywriting assistant that helps users generate high-quality content, images, and audio transcriptions quickly and easily. With over 200 templates and a user-friendly interface, Easy-Peasy.AI is perfect for individuals and businesses looking to improve their writing skills, create engaging content, and save time.
Origlio
Origlio is an audio message transcribing service that helps you manage and transcribe audio messages. It can transcribe audio messages into text, translate audio messages, and even help you manage your audio messages. Origlio is available on WhatsApp and Telegram.
Cockatoo
Cockatoo is an AI-powered transcription service that converts audio and video files into text in seconds. It offers high accuracy, blazing speed, and support for over 90 languages. Cockatoo is easy to use, with a simple drag-and-drop interface and seamless export options. It is suitable for a wide range of users, from students and journalists to businesses and professionals.
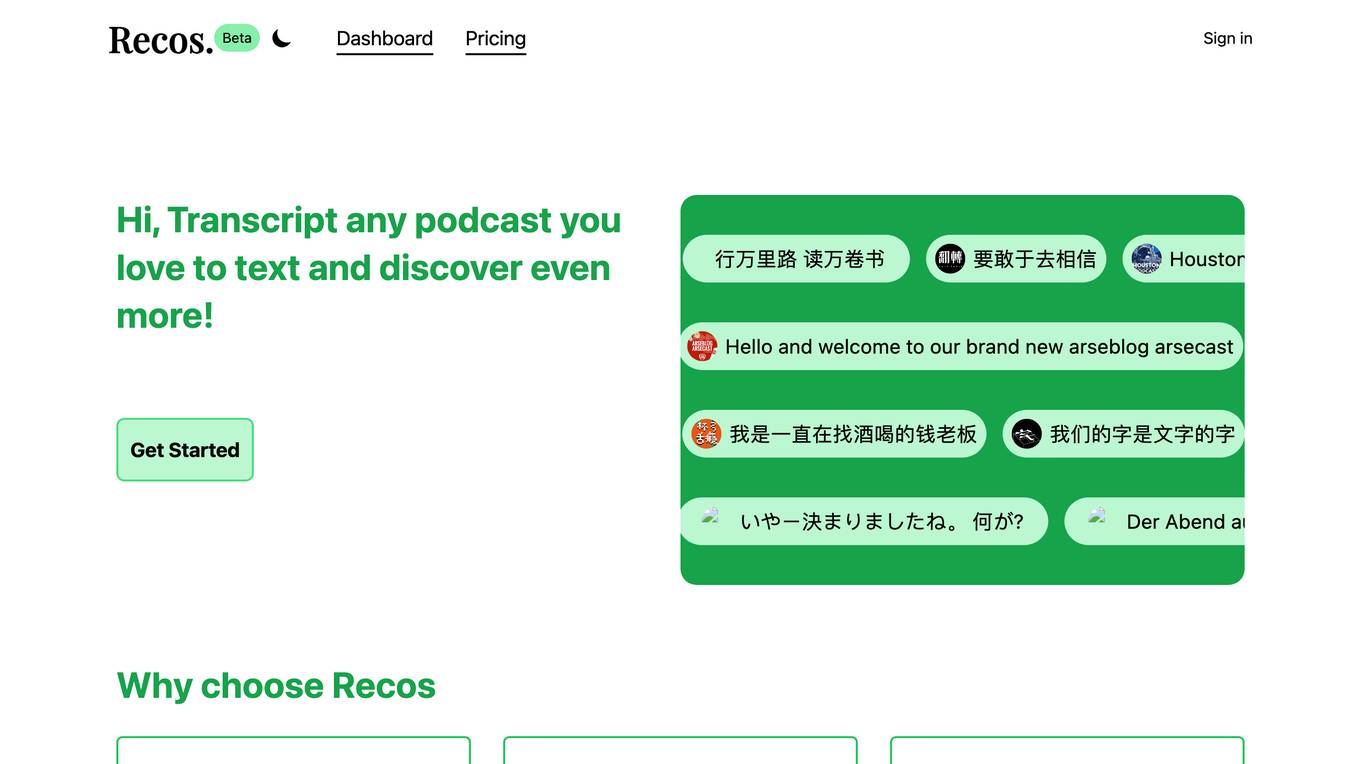
Recos
Recos is a web application that transcribes audio content into text using OpenAI's Whisper API. It offers stability, scalability, and privacy features. Recos supports various audio file formats and provides accurate transcriptions. Users can generate one minute of audio transcription per credit.
Prolific
Prolific is a platform that connects researchers with research participants and AI taskers. It provides a pool of over 120,000 active participants who are fully vetted and verified, so researchers can be sure that they are getting high-quality data. Prolific also has a number of features that make it easy for researchers to design and manage their studies, including a user-friendly interface, a variety of question types, and support for multiple languages. With Prolific, researchers can quickly and easily find the participants they need to conduct their research.
Kensho Solutions
Kensho Solutions is an AI tool that illuminates insights in the world's data by providing AI solutions for audio transcription, entity identification, document classification, data extraction, and company data mapping. Their AI solutions unlock insights, enabling users to make data-driven decisions with conviction. In partnership with S&P Global, Kensho Solutions has access to vast amounts of data, which they use to train and develop machine learning algorithms to address the business world's most pressing challenges.
Robo Translator
Robo Translator is an AI-powered translation assistant that leverages the latest OpenAI models to provide highly accurate localization services. It offers machine translation for audio, video, and text documents, closed caption localization for YouTube videos, audio transcription and translation, as well as software localization for mobile and web applications. With encrypted file uploads and short-lived storage for privacy protection, Robo Translator simplifies the process of reaching a global audience by making content more accessible in multiple languages.
20 - Open Source AI Tools
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.
vibe
Vibe is a tool designed to transcribe audio in multiple languages with features such as offline functionality, user-friendly design, support for various file formats, automatic updates, and translation. It is optimized for different platforms and hardware, offering total freedom to customize models easily. The tool is ideal for transcribing audio and video files, with upcoming features like transcribing system audio and audio from microphone. Vibe is a versatile and efficient transcription tool suitable for various users.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
project-lakechain
Project Lakechain is a cloud-native, AI-powered framework for building document processing pipelines on AWS. It provides a composable API with built-in middlewares for common tasks, scalable architecture, cost efficiency, GPU and CPU support, and the ability to create custom transform middlewares. With ready-made examples and emphasis on modularity, Lakechain simplifies the deployment of scalable document pipelines for tasks like metadata extraction, NLP analysis, text summarization, translations, audio transcriptions, computer vision, and more.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

rivet
Rivet is a desktop application for creating complex AI agents and prompt chaining, and embedding it in your application. Rivet currently has LLM support for OpenAI GPT-3.5 and GPT-4, Anthropic Claude Instant and Claude 2, [Anthropic Claude 3 Haiku, Sonnet, and Opus](https://www.anthropic.com/news/claude-3-family), and AssemblyAI LeMUR framework for voice data. Rivet has embedding/vector database support for OpenAI Embeddings and Pinecone. Rivet also supports these additional integrations: Audio Transcription from AssemblyAI. Rivet core is a TypeScript library for running graphs created in Rivet. It is used by the Rivet application, but can also be used in your own applications, so that Rivet can call into your own application's code, and your application can call into Rivet graphs.
openrecall
OpenRecall is a fully open-source, privacy-first tool that captures your digital history through snapshots, making it searchable for quick access to specific information. It offers transparency, cross-platform support, privacy focus, and hardware compatibility. Features include time travel, local-first AI, semantic search, and full control over storage. The roadmap includes visual search capabilities and audio transcription. Users can easily install and run OpenRecall to enhance memory and productivity without compromising privacy.
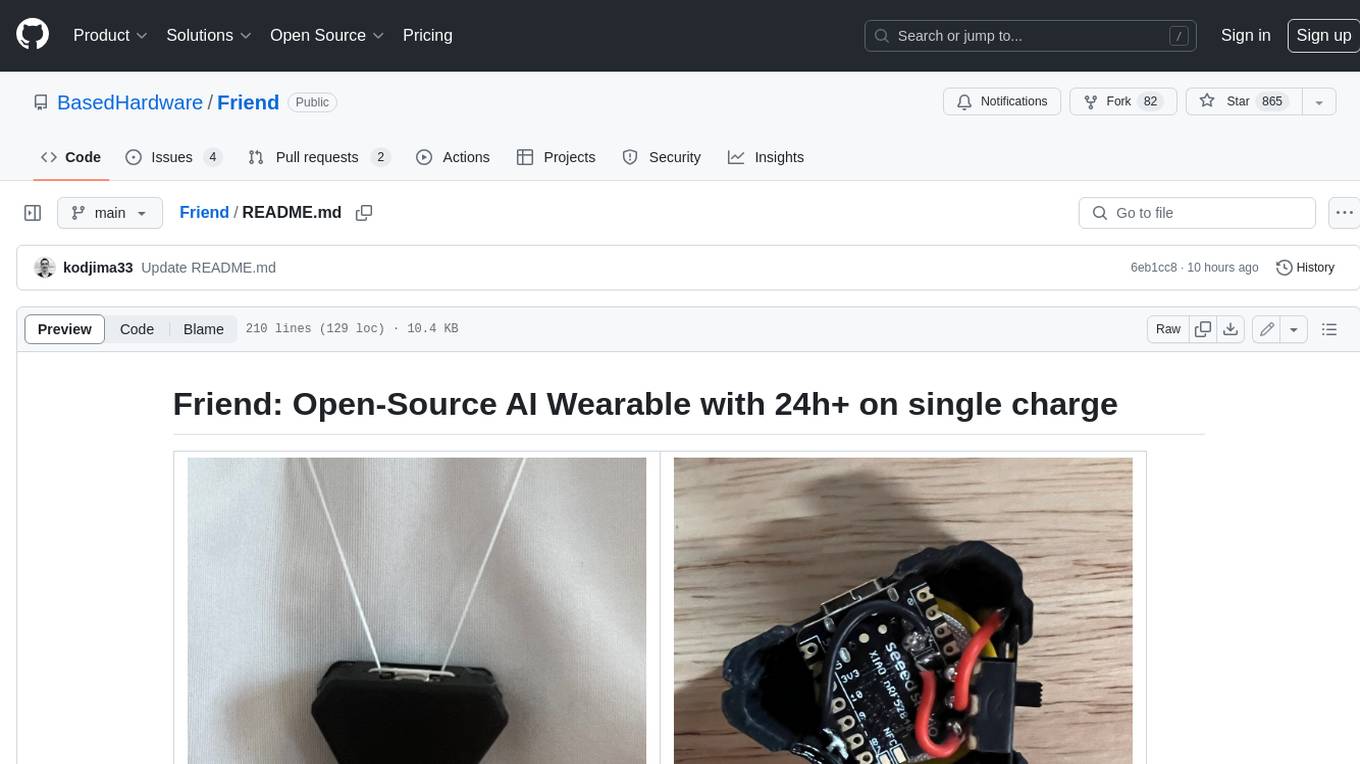
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.
groqnotes
Groqnotes is a streamlit app that helps users generate organized lecture notes from transcribed audio using Groq's Whisper API. It utilizes Llama3-8b and Llama3-70b models to structure and create content quickly. The app offers markdown styling for aesthetic notes, allows downloading notes as text or PDF files, and strategically switches between models for speed and quality balance. Users can access the hosted version at groqnotes.streamlit.app or run it locally with streamlit by setting up the Groq API key and installing dependencies.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.
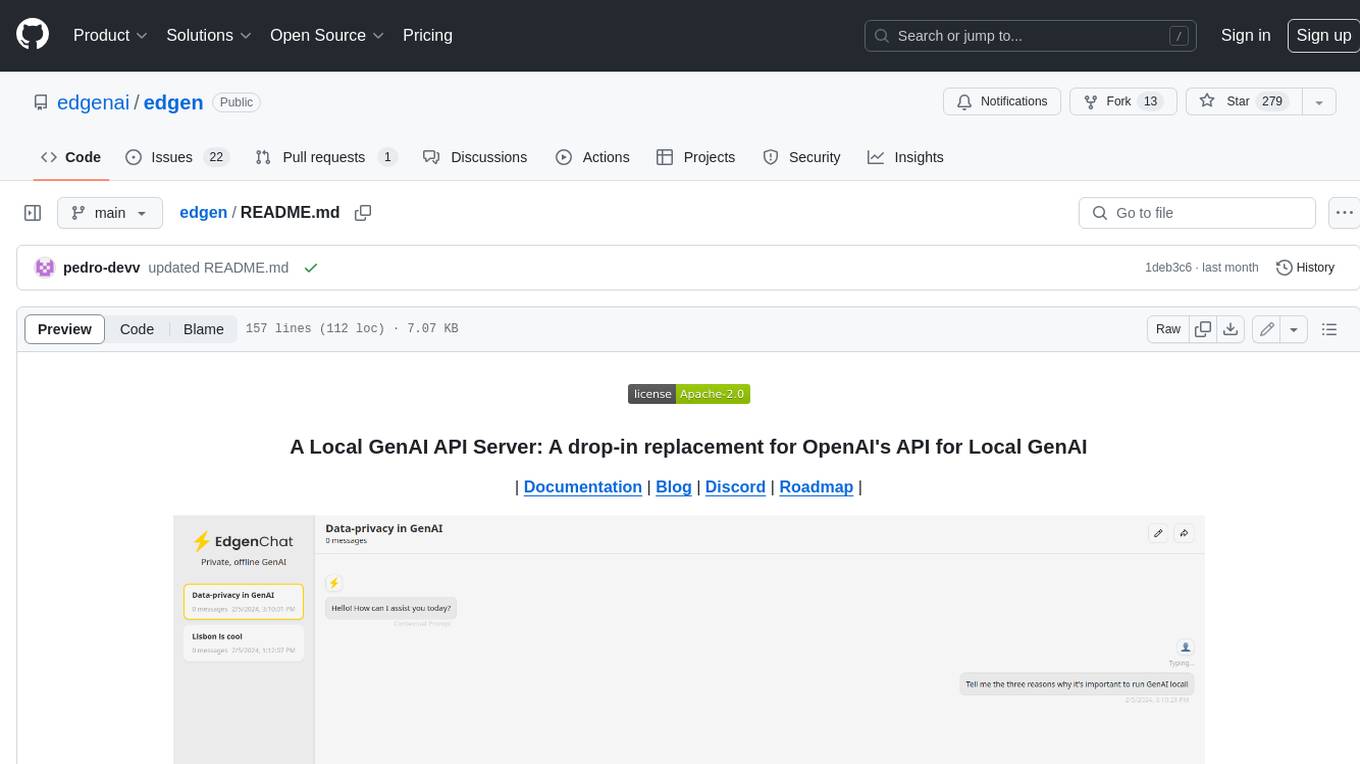
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.

20 - OpenAI Gpts

Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)



DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.