Best AI tools for< Cuda Engineer >
Infographic
3 - AI tool Sites
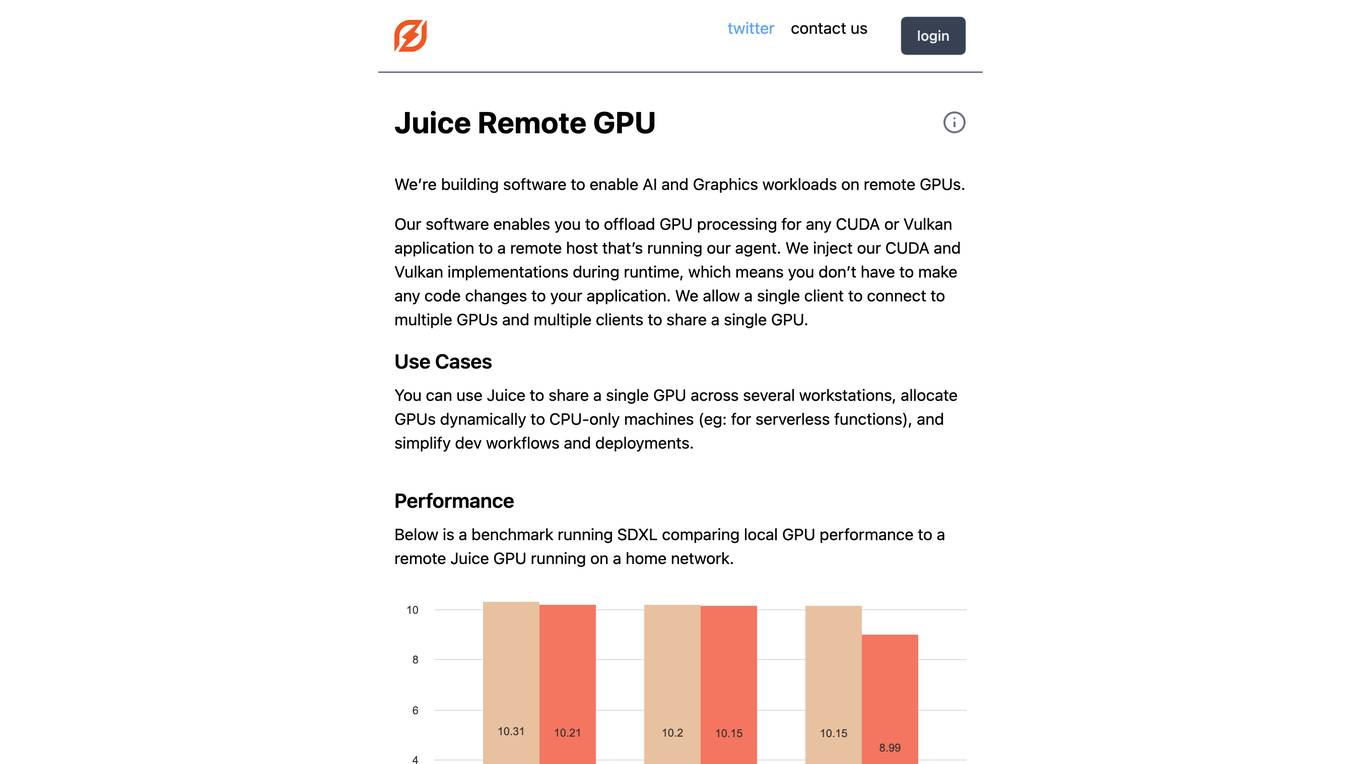
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Deep Live Cam
Deep Live Cam is a cutting-edge AI tool that enables real-time face swapping and one-click video deepfakes. It harnesses advanced AI algorithms to deliver high-quality face replacement with just a single image. The tool supports multiple execution platforms, including CPU, NVIDIA CUDA, and Apple Silicon, providing users with flexibility and optimized performance. Deep Live Cam promotes ethical use by incorporating safeguards to prevent processing of inappropriate content. Additionally, it benefits from an active open-source community, ensuring ongoing support and improvements to stay at the forefront of technology.

