AI tools for aquilax
Related Tools:
AquilaX
AquilaX is an AI-powered DevSecOps platform that simplifies security and accelerates development processes. It offers a comprehensive suite of security scanning tools, including secret identification, PII scanning, SAST, container scanning, and more. AquilaX is designed to integrate seamlessly into the development workflow, providing fast and accurate results by leveraging AI models trained on extensive datasets. The platform prioritizes developer experience by eliminating noise and false positives, making it a go-to choice for modern Secure-SDLC teams worldwide.
Scribool
Scribool is an AI-powered writing assistant that can help you with a variety of writing tasks, from generating creative content to checking grammar and plagiarism. It is designed to be easy to use, with a simple interface and a variety of features to help you get the most out of your writing.
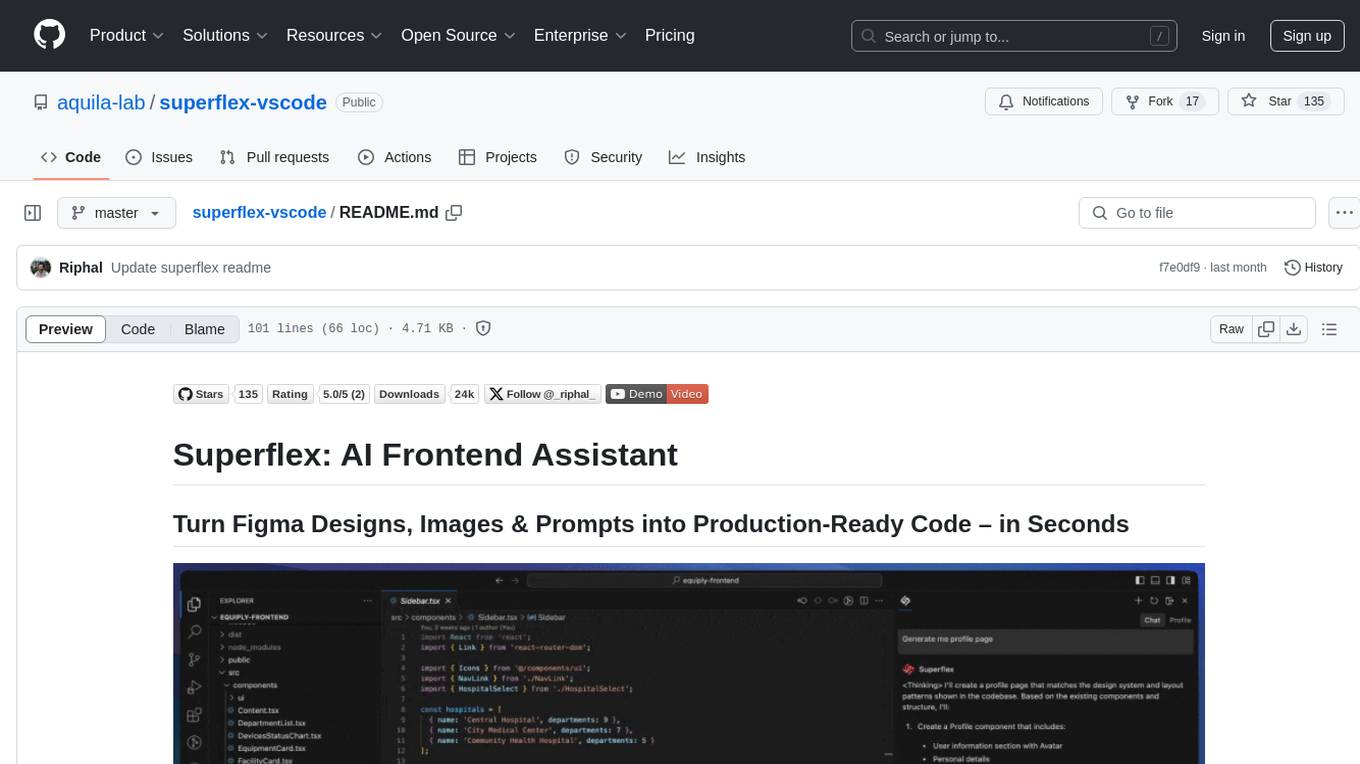
superflex-vscode
Superflex is an AI frontend assistant that streamlines frontend development by converting Figma designs, images, and prompts into production-ready code in seconds. It ensures design standards and coding style are maintained, offering features like generating entire page layouts from Figma, a new chat UI, enhanced usability with shortcuts and profiles, and the ability to add code snippets or files to the chat context seamlessly. Superflex saves time by automating repetitive coding tasks, promotes code consistency, and is beginner-friendly for designers or developers new to front-end work.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.
Awesome-Chinese-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, ,'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in less than 3 words,Verb + noun form,in daily spoken language,in lowercase letters).Answer in english languagesname:Awesome-Chinese-LLM readme:# Awesome Chinese LLM   An Awesome Collection for LLM in Chinese 收集和梳理中文LLM相关    自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个! 如果本项目能给您带来一点点帮助,麻烦点个⭐️吧~ 同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~
DeepSparkHub
DeepSparkHub is a repository that curates hundreds of application algorithms and models covering various fields in AI and general computing. It supports mainstream intelligent computing scenarios in markets such as smart cities, digital individuals, healthcare, education, communication, energy, and more. The repository provides a wide range of models for tasks such as computer vision, face detection, face recognition, instance segmentation, image generation, knowledge distillation, network pruning, object detection, 3D object detection, OCR, pose estimation, self-supervised learning, semantic segmentation, super resolution, tracking, traffic forecast, GNN, HPC, methodology, multimodal, NLP, recommendation, reinforcement learning, speech recognition, speech synthesis, and 3D reconstruction.

llama.cpp
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware - locally and in the cloud. It provides a Plain C/C++ implementation without any dependencies, optimized for Apple silicon via ARM NEON, Accelerate and Metal frameworks, and supports various architectures like AVX, AVX2, AVX512, and AMX. It offers integer quantization for faster inference, custom CUDA kernels for NVIDIA GPUs, Vulkan and SYCL backend support, and CPU+GPU hybrid inference. llama.cpp is the main playground for developing new features for the ggml library, supporting various models and providing tools and infrastructure for LLM deployment.
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.
rtp-llm
**rtp-llm** is a Large Language Model (LLM) inference acceleration engine developed by Alibaba's Foundation Model Inference Team. It is widely used within Alibaba Group, supporting LLM service across multiple business units including Taobao, Tmall, Idlefish, Cainiao, Amap, Ele.me, AE, and Lazada. The rtp-llm project is a sub-project of the havenask.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
DecryptPrompt
This repository does not provide a tool, but rather a collection of resources and strategies for academics in the field of artificial intelligence who are feeling depressed or overwhelmed by the rapid advancements in the field. The resources include articles, blog posts, and other materials that offer advice on how to cope with the challenges of working in a fast-paced and competitive environment.
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
llm-course
The llm-course repository is a collection of resources and materials for a course on Legal and Legislative Drafting. It includes lecture notes, assignments, readings, and other educational materials to help students understand the principles and practices of drafting legal documents. The course covers topics such as statutory interpretation, legal drafting techniques, and the role of legislation in the legal system. Whether you are a law student, legal professional, or someone interested in understanding the intricacies of legal language, this repository provides valuable insights and resources to enhance your knowledge and skills in legal drafting.
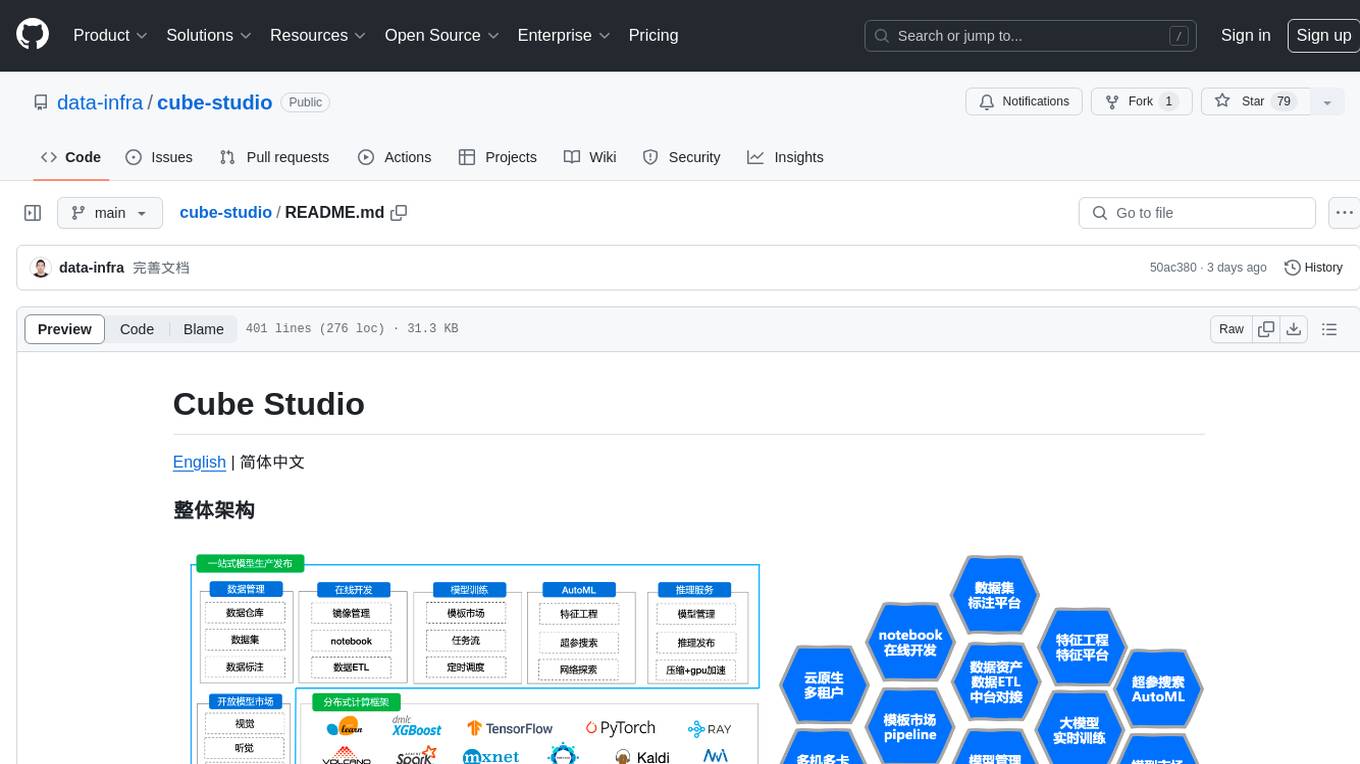
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.

FlagPerf
FlagPerf is an integrated AI hardware evaluation engine jointly built by the Institute of Intelligence and AI hardware manufacturers. It aims to establish an industry-oriented metric system to evaluate the actual capabilities of AI hardware under software stack combinations (model + framework + compiler). FlagPerf features a multidimensional evaluation metric system that goes beyond just measuring 'whether the chip can support specific model training.' It covers various scenarios and tasks, including computer vision, natural language processing, speech, multimodal, with support for multiple training frameworks and inference engines to connect AI hardware with software ecosystems. It also supports various testing environments to comprehensively assess the performance of domestic AI chips in different scenarios.