
awesome-llm-planning-reasoning
A curated collection of LLM reasoning and planning resources, including key papers, limitations, benchmarks, and additional learning materials.
Stars: 117
The 'Awesome LLMs Planning Reasoning' repository is a curated collection focusing on exploring the capabilities of Large Language Models (LLMs) in planning and reasoning tasks. It includes research papers, code repositories, and benchmarks that delve into innovative techniques, reasoning limitations, and standardized evaluations related to LLMs' performance in complex cognitive tasks. The repository serves as a comprehensive resource for researchers, developers, and enthusiasts interested in understanding the advancements and challenges in leveraging LLMs for planning and reasoning in real-world scenarios.
README:
Welcome to the Awesome LLMs Planning Reasoning repository! This collection is dedicated to exploring the rapidly evolving field of Large Language Models (LLMs) and their capabilities in planning and reasoning.
As LLMs continue to demonstrate remarkable success in Natural Language Understanding (NLU) and Natural Language Generation (NLG), researchers are increasingly interested in assessing their abilities beyond traditional NLP tasks. One of the most promising and challenging areas of study is understanding how well LLMs can perform tasks that require planning and reasoning. These capabilities are essential for leveraging LLMs in more complex, real-world scenarios, such as autonomous decision-making, problem-solving, and strategic thinking. However, recent research suggests that LLMs often struggle with reasoning tasks that are relatively simple for most humans, highlighting the limitations of these models in this critical area.
This repository is a curated list of research papers, code repositories, and benchmarks that focus on the intersection of LLMs with planning and reasoning tasks. Here, you'll find:
- Techniques: Innovative methods that enable LLMs to reason and plan effectively, such as Chain-of-Thought prompting and Tree of Thoughts.
- Reasoning Limitations: Critical investigations that explore the limitations and challenges LLMs face in planning and reasoning tasks.
- Benchmarks: Standardized tests and evaluations designed to measure the performance of LLMs in these complex tasks.
- Miscellaneous Papers: Papers related to the field of LLMs and reasoning, but not directly focused on planning tasks.
- Additional Resources: Supplementary materials such as slides, dissertations, and other resources that provide further insights into LLM planning and reasoning.
Whether you're a researcher, developer, or enthusiast, this repository serves as a comprehensive resource for staying updated on the latest advancements and understanding the current challenges in the domain of LLMs' planning and reasoning abilities. Dive in and explore the fascinating world where language models meet high-level cognitive tasks!
| Paper | Link | Code | Venue | Date | Other |
|---|---|---|---|---|---|
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | arXiv | -- | NeurIPS 22 | 28 Jan 2022 | Video |
| Self-Consistency Improves Chain of Thought Reasoning in Language Models | arXiv | -- | ICLR 23 | 7 Mar 2023 | Video |
| REACT: Synergizing Reasoning and Acting in Language Models | arXiv | GitHub | ICLR 23 | 10 Mar 2023 | Project Video |
| LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models | arXiv | GitHub | ICCV 23 | 30 Mar 2023 | Project |
| Least-To-Most Prompting Enables Complex Reasoning In Large Language Models | arXiv | -- | ICLR 23 | 16 Apr 2023 | |
| Chain-of-Symbol Prompting Elicits Planning in Large Language Models | arXiv | GitHub | ICLR 24 | 17 May 2023 | |
| PlaSma: Procedural Knowledge Models for Language based Planning and Re-Planning | arXiv | GitHub | ICLR 24 | 26 Jul 2023 | |
| Better Zero-Shot Reasoning with Role-Play Prompting | arXiv | GitHub | NAACL 24 | 15 Aug 2023 | |
| LLM+P: Empowering Large Language Models with Optimal Planning Proficiency | arXiv | GitHub | arXiv | 27 Sep 2023 | |
| Reasoning with Language Model is Planning with World Model | arXiv | GitHub | EMNLP 23 | 23 Oct 2023 | |
| Large Language Models as Commonsense Knowledge for Large-Scale Task Planning | arXiv | GitHub | NeurIPS 23 | 30 Oct 2023 | Project |
| PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization | arXiv | GitHub | ICLR 24 | 7 Dec 2023 | |
| Tree of Thoughts: Deliberate Problem Solving with Large Language Models | arXiv | GitHub | NeurIPS 23 | 3 Dec 2023 | Video |
| Learning adaptive planning representations with natural language guidance | arXiv | -- | arXiv | 13 Dec 2023 | |
| The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction | arXiv | GitHub | ICLR 24 | 21 Dec 2023 | |
| Large Language Models can Learn Rules | arXiv | -- | arXiv | 24 Apr 2024 | |
| What’s the Plan? Evaluating and Developing Planning-Aware Techniques for Language Models | arXiv | -- | arXiv | 22 May 2024 | |
| Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models | arXiv | GitHub | arxiv | 6 Jun 2024 | |
| Large Language Models Can Learn Temporal Reasoning | arXiv | GitHub | ACL 24 | 11 Jun 2024 | |
| Flow of Reasoning: Efficient Training of LLM Policy with Divergent Thinking | arXiv | GitHub | arXiv | 24 Jun 2024 | |
| Tree Search for Language Model Agents | arXiv | GitHub | arXiv | 1 Jul 2024 | Project |
| Tree-Planner: Efficient Close-loop Task Planning with Large Language Models | arXiv | GitHub | ICLR 24 | 24 Jul 2024 | Project |
| RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning | arXiv | -- | arXiv | 6 Aug 2024 | |
| Automating Thought of Search: A Journey Towards Soundness and Completeness | arXiv | -- | arXiv | 21 Aug 2024 |
| Paper | Link | Code | Venue | Date | Other |
|---|---|---|---|---|---|
| Understanding the Capabilities of Large Language Models for Automated Planning | arXiv | -- | arXiv | 25 May 2023 | |
| Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond | arXiv | GitHub | arXiv | 8 Aug 2023 | |
| Evaluating Cognitive Maps and Planning in Large Language Models with CogEval | arXiv | GitHub | NeurIPS 23 | 2 Nov 2023 | |
| On the Planning Abilities of Large Language Models : A Critical Investigation | arXiv | GitHub | NeurIPS 23 | 6 Nov 2023 | |
| Large Language Models Cannot Self-Correct Reasoning Yet | arXiv | -- | ICLR 24 | 14 Mar 2024 | |
| Dissociating language and thought in large language models | arXiv | -- | Trends in Cognitive Sciences | 23 Mar 2024 | |
| Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks | arXiv | GitHub | NAACL 24 | 28 Mar 2024 | |
| Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? | arXiv | -- | arXiv | 13 May 2024 | Video |
| On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models | arXiv | -- | arXiv | 22 May 2024 | |
| Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models | arXiv | GitHub | EACL 24 | 24 May 2023 | |
| Can Graph Learning Improve Task Planning? | arXiv | GitHub | arXiv | 29 May 2024 | |
| Graph-enhanced Large Language Models in Asynchronous Plan Reasoning | arXiv | GitHub | ICML 24 | 3 Jun 2024 | |
| When is Tree Search Useful for LLM Planning? It Depends on the Discriminator | arXiv | GitHub | ACL 24 | 6 Jun 2024 | |
| Chain of Thoughtlessness? An Analysis of CoT in Planning | arXiv | -- | arXiv | 6 Jun 2024 | |
| Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning | arXiv | GitHub | ACL 24 | 7 Jun 2024 | |
| Can Language Models Serve as Text-Based World Simulators? | arXiv | GitHub | ACL 24 | 10 Jun 2024 | |
| LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks | arXiv | -- | ICML 24 | 12 Jun 2024 | Video |
| Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models | arXiv | GitHub | arXiv | 13 Jul 2024 | |
| On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks | arXiv | -- | arXiv | 3 Aug 2024 | |
| Does Reasoning Emerge? Examining the Probabilities of Causation in Large Language Models | arXiv | -- | arXiv | 15 Aug 2024 |
| Paper | Link | Code | Venue | Date | Other |
|---|---|---|---|---|---|
| Benchmarks for Automated Commonsense Reasoning: A Survey | arXiv | -- | arXiv | 22 Feb 2023 | |
| BioPlanner: Automatic Evaluation of LLMs on Protocol Planning in Biology | arXiv | GitHub | EMNLP 24 | 16 Oct 2023 | |
| AgentBench: Evaluating LLMs as Agents | arXiv | GitHub | ICLR 24 | 25 Oct 2023 | |
| PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change | arXiv | GitHub | NeurIPS 23 Track on Datasets and Benchmarks | 23 Nov 2023 | |
| Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena | arXiv | GitHub | arXiv | 3 Apr 2024 | Project |
| WebArena: A Realistic Web Environment for Building Autonomous Agents | arXiv | GitHub | NeurIPS 23 Workshop | 16 Apr 2024 | Project |
| Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning | arXiv | -- | arXiv | 3 Jun 2024 | HuggingFace |
| Open Grounded Planning: Challenges and Benchmark Construction | arXiv | GitHub | ACL 24 | 5 Jun 2024 | |
| NATURAL PLAN: Benchmarking LLMs on Natural Language Planning | arXiv | -- | arXiv | 6 Jun 2024 | |
| ResearchArena: Benchmarking LLMs’ Ability to Collect and Organize Information as Research Agents | arXiv | arXiv | 13 Jun 2024 | ||
| OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI | arXiv | GitHub | arXiv | 22 Jun 2024 | Project |
| TravelPlanner: A Benchmark for Real-World Planning with Language Agents | arXiv | GitHub | ICML 24 | 23 Jun 2024 | Project |
| GraCoRe: Benchmarking Graph Comprehension and Complex Reasoning in Large Language Models | arXiv | GitHub | arXiv | 3 Jul 2024 | |
| AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents | arXiv | GitHub | ACL 24 | 26 Jul 2024 | Project Video |
| Paper | Link | Code | Venue | Date | Other |
|---|---|---|---|---|---|
| Lost in the Middle: How Language Models Use Long Contexts | arXiv | -- | TACL 23 | 20 Nov 2023 | |
| The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4 | arXiv | -- | arXiv | 8 Dec 2023 | Project |
| Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations | arXiv | -- | ACL 24 | 19 Feb 2024 | Project |
| Better & Faster Large Language Models via Multi-token Prediction | arXiv | -- | arXiv | 30 Apr 2024 | Video HuggingFace |
| Learning Iterative Reasoning through Energy Diffusion | arXiv | GitHub | ICML 24 | 17 Jun 2024 | Project |
| Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data | arXiv | GitHub | arXiv | 20 Jun 2024 | |
| What's the Magic Word? A Control Theory of LLM Prompting | arXiv | -- | arXiv | 3 Jul 2024 | |
| AGENTGEN: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation | arXiv | -- | arXiv | 1 Aug 2024 | |
| Generative Verifiers: Reward Modeling as Next-Token Prediction | arXiv | -- | arXiv | 27 Aug 2024 |
| Resource | Link |
|---|---|
| Yochan Tutorials on Large Language Models and Planning | link |
| On The Capabilities and Risks of Large Language Models | link |
| Large Language Models for Reasoning | link |
| LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models | link |
| Physics of Language Models | link |
If you want to say thank you or/and support active development of Awesome LLMs for Planning and Reasoning, add a GitHub Star to the project.
Together, we can make Awesome LLMs for Planning and Reasoning better!
First off, thanks for taking the time to contribute! Contributions are what make the open-source community such an amazing place to learn, inspire, and create. Any contributions you make will benefit everybody else and are greatly appreciated.
The original setup of this repository is by Sambhav Khurana.
For a full list of all authors and contributors, see the contributors page.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-llm-planning-reasoning
Similar Open Source Tools
awesome-llm-planning-reasoning
The 'Awesome LLMs Planning Reasoning' repository is a curated collection focusing on exploring the capabilities of Large Language Models (LLMs) in planning and reasoning tasks. It includes research papers, code repositories, and benchmarks that delve into innovative techniques, reasoning limitations, and standardized evaluations related to LLMs' performance in complex cognitive tasks. The repository serves as a comprehensive resource for researchers, developers, and enthusiasts interested in understanding the advancements and challenges in leveraging LLMs for planning and reasoning in real-world scenarios.
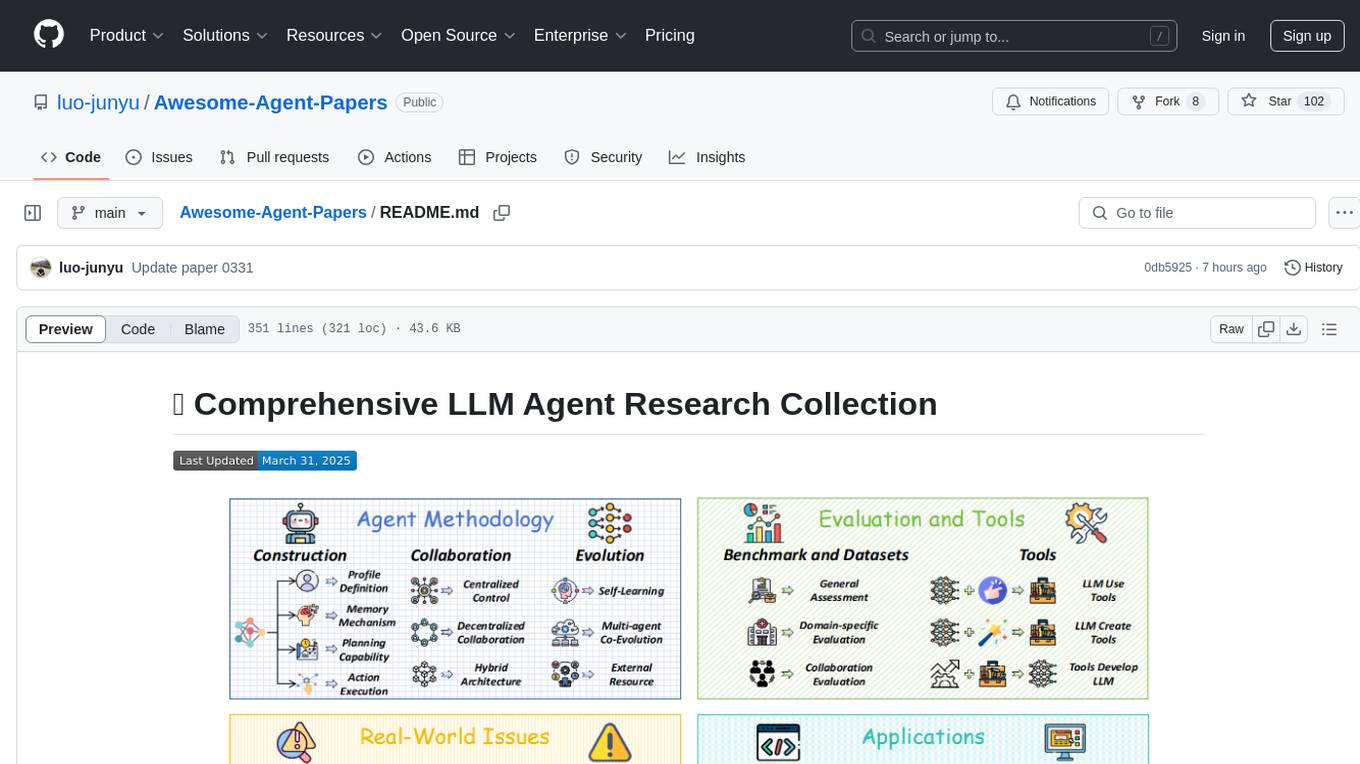
Awesome-Agent-Papers
This repository is a comprehensive collection of research papers on Large Language Model (LLM) agents, organized across key categories including agent construction, collaboration mechanisms, evolution, tools, security, benchmarks, and applications. The taxonomy provides a structured framework for understanding the field of LLM agents, bridging fragmented research threads by highlighting connections between agent design principles and emergent behaviors.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.
watsonx-ai-samples
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.
tamingLLMs
The 'Taming LLMs' repository provides a practical guide to the pitfalls and challenges associated with Large Language Models (LLMs) when building applications. It focuses on key limitations and implementation pitfalls, offering practical Python examples and open source solutions to help engineers and technical leaders navigate these challenges. The repository aims to equip readers with the knowledge to harness the power of LLMs while avoiding their inherent limitations.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
ai-samples
AI Samples for .NET is a repository containing various samples demonstrating how to use AI in .NET applications. It provides quickstarts using Semantic Kernel and Azure OpenAI SDK, covers LLM Core Concepts, End to End Examples, Local Models, Local Embedding Models, Tokenizers, Vector Databases, and Reference Examples. The repository showcases different AI-related projects and tools for developers to explore and learn from.
tiny-llm
tiny-llm is a course on LLM serving using MLX for system engineers. The codebase is focused on MLX array/matrix APIs to build model serving infrastructure from scratch and explore optimizations. The goal is to efficiently serve large language models like Qwen2 models. The course covers implementing components in Python, building an inference system similar to vLLM, and advanced topics on model interaction. The tool aims to provide hands-on experience in serving language models without high-level neural network APIs.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
CS7320-AI
CS7320-AI is a repository containing lecture materials, simple Python code examples, and assignments for the course CS 5/7320 Artificial Intelligence. The code examples cover various chapters of the textbook 'Artificial Intelligence: A Modern Approach' by Russell and Norvig. The repository focuses on basic AI concepts rather than advanced implementation techniques. It includes HOWTO guides for installing Python, working on assignments, and using AI with Python.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.
Telco-AIX
Telco-AIX is a collaborative experimental workspace focusing on data-driven decision-making through open-source AI capabilities and open datasets. It covers various domains such as revenue management, service quality, network operations, sustainability, security, smart infrastructure, IoT security, advanced AI, customer experience, anomaly detection, connectivity, network operations, IT management, and agentic Telco-AI. The repository provides models, datasets, and published works related to telecommunications AI applications.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.