
reasoning-from-scratch
Implement a reasoning LLM in PyTorch from scratch, step by step
Stars: 1203
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.
README:
This repository contains the code for developing an LLM reasoning model and is the official code repository for the book Build a Reasoning Model (From Scratch).

(Printed in color.)
In Build a Reasoning Model (From Scratch), you will learn and understand how a reasoning large language model (LLM) works.
Reasoning is one of the most exciting and important recent advances in improving LLMs, but it’s also one of the easiest to misunderstand if you only hear the term reasoning and read about it in theory. This is why this book takes a hands-on approach. We will start with a pre-trained base LLM and then add reasoning capabilities ourselves, step by step in code, so you can see exactly how it works.
The methods described in this book walk you through the process of developing your own small-but-functional reasoning model for educational purposes. It mirrors the approaches used in creating large-scale reasoning models such as DeepSeek R1, GPT-5 Thinking, and others. In addition, this book includes code for loading the weights of existing, pretrained models.
- Link to the official source code repository
- Link to the book at Manning (the publisher's website)
- Link to the book page on Amazon.com (TBD)
- ISBN 9781633434677
To download a copy of this repository, click on the Download ZIP button or execute the following command in your terminal:
git clone --depth 1 https://github.com/rasbt/reasoning-from-scratch.gitTip: Chapter 2 provides additional tips on installing Python, managing Python packages, and setting up your coding environment.
![]()
![]()
![]()
| Chapter Title | Main Code |
|---|---|
| Ch 1: Understanding reasoning models | No code |
| Ch 2: Generating text with a pre-trained LLM | - ch02_main.ipynb - ch02_exercise-solutions.ipynb |
| Ch 3: Evaluating reasoning models | TBA |
| Ch 4: Improving reasoning with inference-time scaling | TBA |
| Ch 5: Training reasoning models with reinforcement learning | TBA |
| Ch 6: Distilling reasoning models for efficient reasoning | TBA |
| Ch 7: Improving the reasoning pipeline and future directions | TBA |
| Appendix A: References and further reading | No code |
| Appendix B: Exercise solutions | Code and solutions are in each chapter's subfolder |
| Appendix C: Qwen3 LLM source code | - chC_main.ipynb |
The mental model below summarizes the main techniques covered in this book.

Please note that Build A Reasoning Model (From Scratch) is a standalone book focused on methods to improve LLM reasoning.
In this book, we work with a pre-trained open-source base LLM (Qwen3) on top of which we code apply reasoning methods from scratch. This includes inference-time scaling, reinforcement learning, and distillation.
However, if you are interested in understanding how a conventional base LLM is implemented, you may like my previous book, Build a Large Language Model (From Scratch).

The code in the main chapters of this book is designed to mostly run on consumer hardware within a reasonable timeframe and does not require specialized server hardware. This approach ensures that a wide audience can engage with the material. Additionally, the code automatically utilizes GPUs if they are available. That being said, chapters 2-4 will work well on CPUs and GPUs. For chapters 5 and 6, it is recommended to use a GPU if you want to replicate the results in the chapter.
(Please see the setup_tips doc for additional recommendations.)
Each chapter of the book includes several exercises. The solutions are summarized in Appendix B, and the corresponding code notebooks are available in the main chapter folders of this repository (for example, ch02/01_main-chapter-code/ch02_exercise-solutions.ipynb).
I welcome all sorts of feedback, best shared via the Manning Discussion Forum or GitHub Discussions. Likewise, if you have any questions or just want to bounce ideas off others, please don't hesitate to post these in the forum as well.
Please note that since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book. Keeping it consistent helps ensure a smooth experience for everyone.
If you find this book or code useful for your research, please consider citing it.
Chicago-style citation:
Raschka, Sebastian. Build A Reasoning Model (From Scratch). Manning, 2025. ISBN: 9781633434677.
BibTeX entry:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Reasoning Model (From Scratch)},
publisher = {Manning},
year = {2025},
isbn = {9781633434677},
url = {https://mng.bz/lZ5B},
github = {https://github.com/rasbt/reasoning-from-scratch}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for reasoning-from-scratch
Similar Open Source Tools
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.
rag-cookbooks
Welcome to the comprehensive collection of advanced + agentic Retrieval-Augmented Generation (RAG) techniques. This repository covers the most effective advanced + agentic RAG techniques with clear implementations and explanations. It aims to provide a helpful resource for researchers and developers looking to use advanced RAG techniques in their projects, offering ready-to-use implementations and guidance on evaluation methods. The RAG framework addresses limitations of Large Language Models by using external documents for in-context learning, ensuring contextually relevant and accurate responses. The repository includes detailed descriptions of various RAG techniques, tools used, and implementation guidance for each technique.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

KAG
KAG is a logical reasoning and Q&A framework based on the OpenSPG engine and large language models. It is used to build logical reasoning and Q&A solutions for vertical domain knowledge bases. KAG supports logical reasoning, multi-hop fact Q&A, and integrates knowledge and chunk mutual indexing structure, conceptual semantic reasoning, schema-constrained knowledge construction, and logical form-guided hybrid reasoning and retrieval. The framework includes kg-builder for knowledge representation and kg-solver for logical symbol-guided hybrid solving and reasoning engine. KAG aims to enhance LLM service framework in professional domains by integrating logical and factual characteristics of KGs.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.
air-script
AirScript is a domain-specific language for expressing AIR constraints for STARKs, with the goal of enabling writing and auditing constraints without the need to learn a specific programming language. It also aims to perform automated optimizations and output constraint evaluator code in multiple target languages. The project is organized into several crates including Parser, MIR, AIR, Winterfell code generator, ACE code generator, and AirScript CLI for transpiling AIRs to target languages.
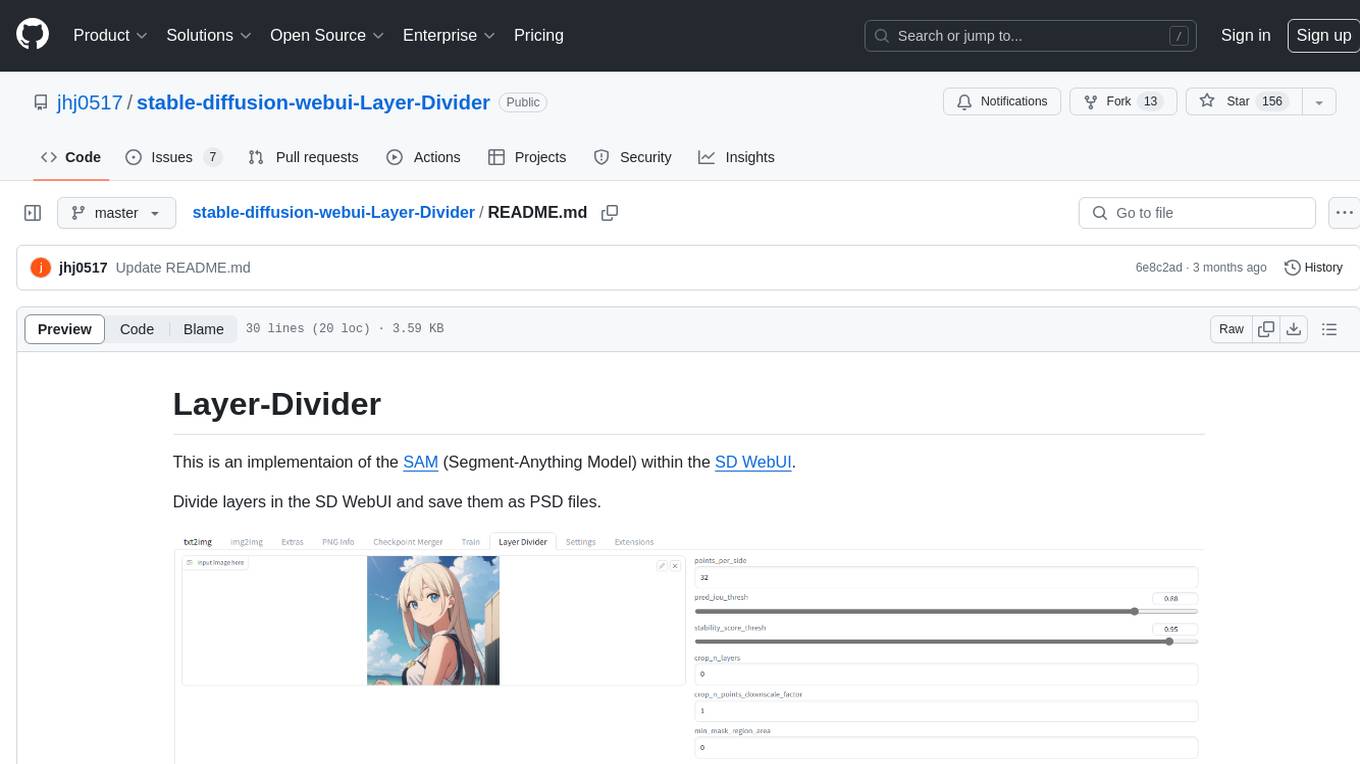
stable-diffusion-webui-Layer-Divider
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.

datasets
Datasets is a repository that provides a collection of various datasets for machine learning and data analysis projects. It includes datasets in different formats such as CSV, JSON, and Excel, covering a wide range of topics including finance, healthcare, marketing, and more. The repository aims to help data scientists, researchers, and students access high-quality datasets for training models, conducting experiments, and exploring data analysis techniques.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
BESSER
BESSER is a low-modeling low-code open-source platform funded by an FNR Pearl grant. It is built on B-UML, a Python-based interpretation of a 'Universal Modeling Language'. Users can specify their software application using B-UML and generate executable code for various applications like Django models or SQLAlchemy-compatible database structures. BESSER is available on PyPi and can be installed with pip. It supports popular Python IDEs and encourages contributions from the community.
For similar tasks
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.