
PulsarRPAPro
PulsarRPA Pro Edition: Empower Your Workflows with AI-Driven Web Data Extraction.
Stars: 102
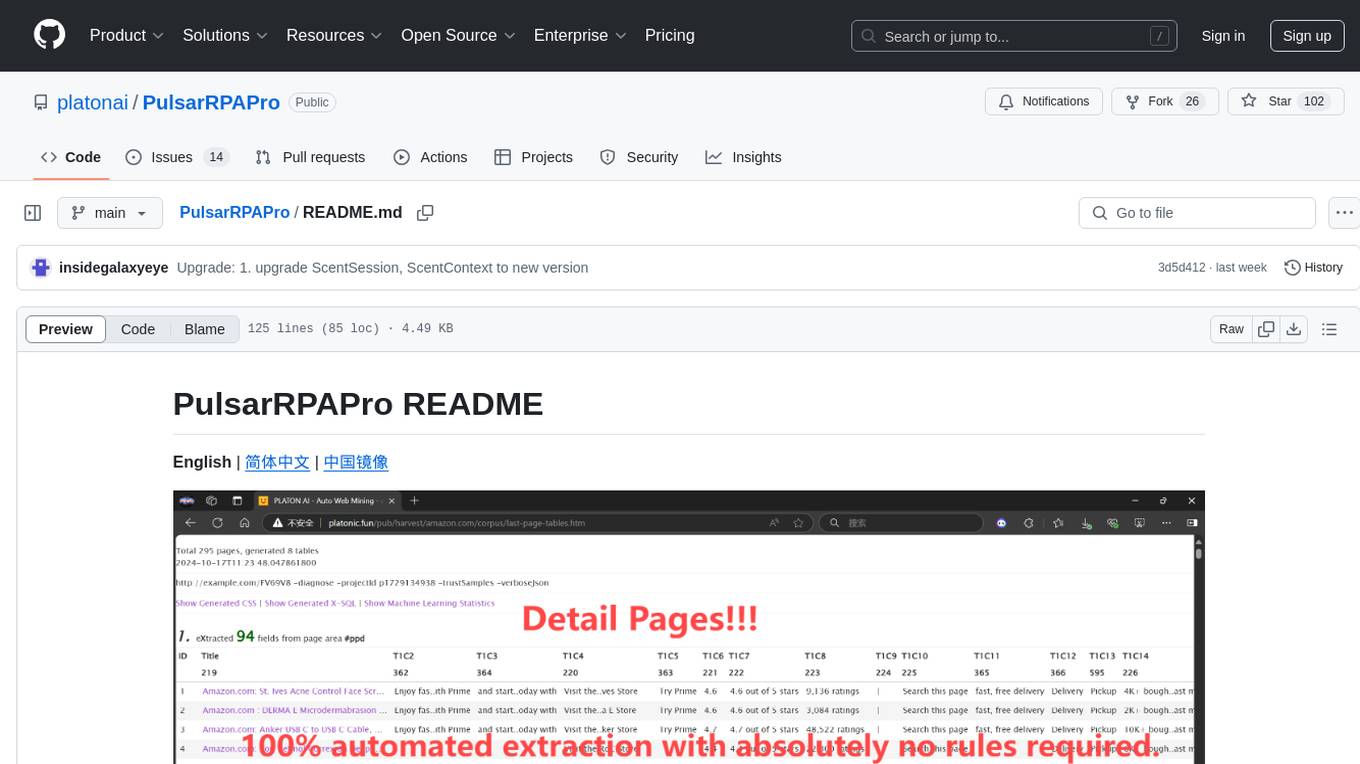
PulsarRPAPro is a powerful robotic process automation (RPA) tool designed to automate repetitive tasks and streamline business processes. It offers a user-friendly interface for creating and managing automation workflows, allowing users to easily automate tasks without the need for extensive programming knowledge. With features such as task scheduling, data extraction, and integration with various applications, PulsarRPAPro helps organizations improve efficiency and productivity by reducing manual work and human errors. Whether you are a small business looking to automate simple tasks or a large enterprise seeking to optimize complex processes, PulsarRPAPro provides the flexibility and scalability to meet your automation needs.
README:

PulsarRPAPro is the professional version of PulsarRPA, featuring an upgraded server, a collection of top e-commerce site scraping examples, and an advanced AI-powered applet for automatic data extraction.
Never write another web scraper. PulsarRPAPro learns from the website and delivers web data completely and accurately at scale.
There are already dozens of scraping cases for the most popular websites, and we are constantly adding more.
YouTube:
Bilibili: https://www.bilibili.com/video/BV1Qg4y1d7kA
- Fully Automated Web Data Extraction——No Rules, Just Results!
- Web spider: browser rendering, ajax data crawling
- High performance: optimized for rendering hundreds of pages in parallel on a single machine without being blocked
- Low cost: scrape 100,000 browser-rendered e-commerce webpages or millions of data points daily with only 8-core CPU/32GB memory
- Web UI: a simple yet powerful web interface to manage spiders and download data
- Machine learning: automatically extract every field in webpages using unsupervised machine learning, generating extraction rules and SQLs
- Data quality assurance: smart retry, accurate scheduling, web data lifecycle management
- Large scale: fully distributed, designed for large-scale crawling
- Simple API: a single line of code to scrape, or a single SQL query to turn a website into a table
- X-SQL: extended SQL to manage web data — web crawling, scraping, content mining, and web BI
- Bot stealth: IP rotation, web driver stealth, and anti-ban mechanisms
- RPA: simulate human behaviors, SPA crawling, or perform other advanced tasks
- Big data: supports various backend storage systems like MongoDB, HBase, and Gora
- Logs & metrics: all events are monitored and recorded for detailed tracking
- Memory 4G+
- JDK 17+
- Google Chrome 90+
- MongoDB started
Download the latest executable jar:
wget http://static.platonic.fun/repo/ai/platon/exotic/PulsarRPAPro.jar
# start MongoDB
docker-compose -f docker/docker-compose.yaml up
java -jar PulsarRPAPro.jar
java -jar PulsarRPAPro.jar harvest "https://www.amazon.com/b?node=1292115011" -diagnose -refreshAdd the following lines to your .m2/settings.xml:
<mirrors>
<mirror>
<id>maven-default-http-blocker</id>
<mirrorOf>dummy</mirrorOf>
<name>Dummy mirror to override default blocking mirror that blocks http</name>
<url>http://0.0.0.0/</url>
</mirror>
</mirrors>git clone https://github.com/platonai/PulsarRPAPro.git
cd PulsarRPAPro
./mvnw clean && ./mvnw
cd PulsarRPAPro/target/
# Don't forget to start MongoDB
docker-compose -f docker/docker-compose.yaml upFor Chinese developers, we strongly suggest following this guide to accelerate the build process.
java -jar PulsarRPAPro.jar serveIf PulsarRPAPro is running in GUI mode, the web console should open within a few seconds, or you can open it manually at:
http://localhost:2718/exotic/crawl/
You can use the harvest command to learn from a set of item pages using unsupervised machine learning.
java -jar PulsarRPAPro.jar harvest "https://www.amazon.com/b?node=1292115011" -diagnose -refreshThe URL in the command should be a portal URL, such as a product listing page URL.
PulsarRPAPro will visit the portal, identify the optimal set of links for item pages, retrieve those pages, and analyze them.
Here is the full page of the auto extraction result in HTML format:
Auto Extraction Result of Amazon
Run the executable jar directly for help and to explore more features:
java -jar PulsarRPAPro.jarThis command will print the help message and some of the most useful examples.
Q: How to use proxies?
A: Follow this guide for proxy rotation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for PulsarRPAPro
Similar Open Source Tools
PulsarRPAPro
PulsarRPAPro is a powerful robotic process automation (RPA) tool designed to automate repetitive tasks and streamline business processes. It offers a user-friendly interface for creating and managing automation workflows, allowing users to easily automate tasks without the need for extensive programming knowledge. With features such as task scheduling, data extraction, and integration with various applications, PulsarRPAPro helps organizations improve efficiency and productivity by reducing manual work and human errors. Whether you are a small business looking to automate simple tasks or a large enterprise seeking to optimize complex processes, PulsarRPAPro provides the flexibility and scalability to meet your automation needs.
WorkflowAI
WorkflowAI is a powerful tool designed to streamline and automate various tasks within the workflow process. It provides a user-friendly interface for creating custom workflows, automating repetitive tasks, and optimizing efficiency. With WorkflowAI, users can easily design, execute, and monitor workflows, allowing for seamless integration of different tools and systems. The tool offers advanced features such as conditional logic, task dependencies, and error handling to ensure smooth workflow execution. Whether you are managing project tasks, processing data, or coordinating team activities, WorkflowAI simplifies the workflow management process and enhances productivity.
HyperAgent
HyperAgent is a powerful tool for automating repetitive tasks in web scraping and data extraction. It provides a user-friendly interface to create custom web scraping scripts without the need for extensive coding knowledge. With HyperAgent, users can easily extract data from websites, transform it into structured formats, and save it for further analysis. The tool supports various data formats and offers scheduling options for automated data extraction at regular intervals. HyperAgent is suitable for individuals and businesses looking to streamline their data collection processes and improve efficiency in extracting information from the web.

J.A.R.V.I.S.
J.A.R.V.I.S.1.0 is an advanced virtual assistant tool designed to assist users in various tasks. It provides a wide range of functionalities including voice commands, task automation, information retrieval, and communication management. With its intuitive interface and powerful capabilities, J.A.R.V.I.S.1.0 aims to enhance productivity and streamline daily activities for users.
promptl
Promptl is a versatile command-line tool designed to streamline the process of creating and managing prompts for user input in various programming projects. It offers a simple and efficient way to prompt users for information, validate their input, and handle different scenarios based on their responses. With Promptl, developers can easily integrate interactive prompts into their scripts, applications, and automation workflows, enhancing user experience and improving overall usability. The tool provides a range of customization options and features, making it suitable for a wide range of use cases across different programming languages and environments.
verl-tool
The verl-tool is a versatile command-line utility designed to streamline various tasks related to version control and code management. It provides a simple yet powerful interface for managing branches, merging changes, resolving conflicts, and more. With verl-tool, users can easily track changes, collaborate with team members, and ensure code quality throughout the development process. Whether you are a beginner or an experienced developer, verl-tool offers a seamless experience for version control operations.
baibot
Baibot is a versatile chatbot framework designed to simplify the process of creating and deploying chatbots. It provides a user-friendly interface for building custom chatbots with various functionalities such as natural language processing, conversation flow management, and integration with external APIs. Baibot is highly customizable and can be easily extended to suit different use cases and industries. With Baibot, developers can quickly create intelligent chatbots that can interact with users in a seamless and engaging manner, enhancing user experience and automating customer support processes.
trubrics-sdk
Trubrics-sdk is a software development kit designed to facilitate the integration of analytics features into applications. It provides a set of tools and functionalities that enable developers to easily incorporate analytics capabilities, such as data collection, analysis, and reporting, into their software products. The SDK streamlines the process of implementing analytics solutions, allowing developers to focus on building and enhancing their applications' functionality and user experience. By leveraging trubrics-sdk, developers can quickly and efficiently integrate robust analytics features, gaining valuable insights into user behavior and application performance.
context-portal
Context-portal is a versatile tool for managing and visualizing data in a collaborative environment. It provides a user-friendly interface for organizing and sharing information, making it easy for teams to work together on projects. With features such as customizable dashboards, real-time updates, and seamless integration with popular data sources, Context-portal streamlines the data management process and enhances productivity. Whether you are a data analyst, project manager, or team leader, Context-portal offers a comprehensive solution for optimizing workflows and driving better decision-making.
chat.md
This repository contains a chatbot tool that utilizes natural language processing to interact with users. The tool is designed to understand and respond to user input in a conversational manner, providing information and assistance. It can be integrated into various applications to enhance user experience and automate customer support. The chatbot tool is user-friendly and customizable, making it suitable for businesses looking to improve customer engagement and streamline communication.
omnichain
OmniChain is a tool for building efficient self-updating visual workflows using AI language models, enabling users to automate tasks, create chatbots, agents, and integrate with existing frameworks. It allows users to create custom workflows guided by logic processes, store and recall information, and make decisions based on that information. The tool enables users to create tireless robot employees that operate 24/7, access the underlying operating system, generate and run NodeJS code snippets, and create custom agents and logic chains. OmniChain is self-hosted, open-source, and available for commercial use under the MIT license, with no coding skills required.

apex
Apex is a powerful and flexible programming language for building cloud-based applications on the Salesforce platform. It allows developers to create custom business logic, automate processes, and integrate with external systems. With its robust features and easy-to-use syntax, Apex empowers developers to extend the capabilities of Salesforce and deliver tailored solutions to meet business requirements.
onlook
Onlook is a web scraping tool that allows users to extract data from websites easily and efficiently. It provides a user-friendly interface for creating web scraping scripts and supports various data formats for exporting the extracted data. With Onlook, users can automate the process of collecting information from multiple websites, saving time and effort. The tool is designed to be flexible and customizable, making it suitable for a wide range of web scraping tasks.

python-sdk
Python SDK is a software development kit that provides tools and resources for developers to interact with Python programming language. It simplifies the process of integrating Python code into applications and services, offering a wide range of functionalities and libraries to streamline development workflows. With Python SDK, developers can easily access and manipulate data, create automation scripts, build web applications, and perform various tasks efficiently. It is designed to enhance the productivity and flexibility of Python developers by providing a comprehensive set of tools and utilities for software development.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.
For similar tasks
open-cuak
Open CUAK (Computer Use Agent) is a platform for managing automation agents at scale, designed to run and manage thousands of automation agents with reliability. It allows for abundant productivity by ensuring scalability and profitability. The project aims to usher in a new era of work with equally distributed productivity, making it open-sourced for real businesses and real people. The core features include running operator-like automation workflows locally, vision-based automation, turning any browser into an operator-companion, utilizing a dedicated remote browser, and more.
PulsarRPAPro
PulsarRPAPro is a powerful robotic process automation (RPA) tool designed to automate repetitive tasks and streamline business processes. It offers a user-friendly interface for creating and managing automation workflows, allowing users to easily automate tasks without the need for extensive programming knowledge. With features such as task scheduling, data extraction, and integration with various applications, PulsarRPAPro helps organizations improve efficiency and productivity by reducing manual work and human errors. Whether you are a small business looking to automate simple tasks or a large enterprise seeking to optimize complex processes, PulsarRPAPro provides the flexibility and scalability to meet your automation needs.
terminator
Terminator is an AI-powered desktop automation tool that is open source, MIT-licensed, and cross-platform. It works across all apps and browsers, inspired by GitHub Actions & Playwright. It is 100x faster than generic AI agents, with over 95% success rate and no vendor lock-in. Users can create automations that work across any desktop app or browser, achieve high success rates without costly consultant armies, and pre-train workflows as deterministic code.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.
For similar jobs
PulsarRPAPro
PulsarRPAPro is a powerful robotic process automation (RPA) tool designed to automate repetitive tasks and streamline business processes. It offers a user-friendly interface for creating and managing automation workflows, allowing users to easily automate tasks without the need for extensive programming knowledge. With features such as task scheduling, data extraction, and integration with various applications, PulsarRPAPro helps organizations improve efficiency and productivity by reducing manual work and human errors. Whether you are a small business looking to automate simple tasks or a large enterprise seeking to optimize complex processes, PulsarRPAPro provides the flexibility and scalability to meet your automation needs.

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
deep-chat
Deep Chat is a fully customizable AI chat component that can be injected into your website with minimal to no effort. Whether you want to create a chatbot that leverages popular APIs such as ChatGPT or connect to your own custom service, this component can do it all! Explore deepchat.dev to view all of the available features, how to use them, examples and more!

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.
chatgpt-web
ChatGPT Web is a web application that provides access to the ChatGPT API. It offers two non-official methods to interact with ChatGPT: through the ChatGPTAPI (using the `gpt-3.5-turbo-0301` model) or through the ChatGPTUnofficialProxyAPI (using a web access token). The ChatGPTAPI method is more reliable but requires an OpenAI API key, while the ChatGPTUnofficialProxyAPI method is free but less reliable. The application includes features such as user registration and login, synchronization of conversation history, customization of API keys and sensitive words, and management of users and keys. It also provides a user interface for interacting with ChatGPT and supports multiple languages and themes.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.