
AIRS
Artificial Intelligence Research for Science (AIRS)
Stars: 588
AIRS is a collection of open-source software tools, datasets, and benchmarks focused on Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. The goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources to advance the field of AI for Science. The current resources include tools for Quantum Mechanics, Density Functional Theory, Small Molecules, Protein Science, Materials Science, Molecular Interactions, and Partial Differential Equations.
README:
![]()

AIRS is a collection of open-source software tools, datasets, and benchmarks associated with our paper entitled “Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems”. Our focus here is on AI for Science, including AI for quantum, atomistic, and continuum systems. Our goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources in order to propel the emerging and rapidly growing field of AI for Science. The list of resources will grow as our research progresses. The current list includes:
- OpenQM: AI for Quantum Mechanics
- OpenDFT: AI for Density Functional Theory
- OpenMol: AI for Small Molecules
- OpenProt: AI for Protein Science
- OpenMat: AI for Materials Science
- OpenMI: AI for Molecular Interactions
- OpenBio: AI for Biological Science
- OpenPDE: AI for Partial Differential Equations

Here is the summary of methods we have in AIRS. More methods will be included as our research progresses.
| Quantum | Atomistic | Continuum | |
|---|---|---|---|
|
|
|
|
|
We released our survey paper about artificial intelligence for science in quantum, atomistic, and continuum systems. Please check our paper and website for more details!
To cite the survey paper, please use the BibTeX entry provided below.
@article{zhang2023artificial,
title={Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems},
author={Xuan Zhang and Limei Wang and Jacob Helwig and Youzhi Luo and Cong Fu and Yaochen Xie and Meng Liu and Yuchao Lin and Zhao Xu and Keqiang Yan and Keir Adams and Maurice Weiler and Xiner Li and Tianfan Fu and Yucheng Wang and Haiyang Yu and YuQing Xie and Xiang Fu and Alex Strasser and Shenglong Xu and Yi Liu and Yuanqi Du and Alexandra Saxton and Hongyi Ling and Hannah Lawrence and Hannes St{\"a}rk and Shurui Gui and Carl Edwards and Nicholas Gao and Adriana Ladera and Tailin Wu and Elyssa F. Hofgard and Aria Mansouri Tehrani and Rui Wang and Ameya Daigavane and Montgomery Bohde and Jerry Kurtin and Qian Huang and Tuong Phung and Minkai Xu and Chaitanya K. Joshi and Simon V. Mathis and Kamyar Azizzadenesheli and Ada Fang and Al{\'a}n Aspuru-Guzik and Erik Bekkers and Michael Bronstein and Marinka Zitnik and Anima Anandkumar and Stefano Ermon and Pietro Li{\`o} and Rose Yu and Stephan G{\"u}nnemann and Jure Leskovec and Heng Ji and Jimeng Sun and Regina Barzilay and Tommi Jaakkola and Connor W. Coley and Xiaoning Qian and Xiaofeng Qian and Tess Smidt and Shuiwang Ji},
journal={arXiv preprint arXiv:2307.08423},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIRS
Similar Open Source Tools
AIRS
AIRS is a collection of open-source software tools, datasets, and benchmarks focused on Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. The goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources to advance the field of AI for Science. The current resources include tools for Quantum Mechanics, Density Functional Theory, Small Molecules, Protein Science, Materials Science, Molecular Interactions, and Partial Differential Equations.
OmniGibson
OmniGibson is a platform for accelerating Embodied AI research built upon NVIDIA's Omniverse platform. It features photorealistic visuals, physical realism, fluid and soft body support, large-scale high-quality scenes and objects, dynamic kinematic and semantic object states, mobile manipulator robots with modular controllers, and an OpenAI Gym interface. The platform provides a comprehensive environment for researchers to conduct experiments and simulations in the field of Embodied AI.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.
AI-PhD-S24
AI-PhD-S24 is a mono-repo for the PhD course 'AI for Business Research' at CUHK Business School in Spring 2024. The course aims to provide a basic understanding of machine learning and artificial intelligence concepts/methods used in business research, showcase how ML/AI is utilized in business research, and introduce state-of-the-art AI/ML technologies. The course includes scribed lecture notes, class recordings, and covers topics like AI/ML fundamentals, DL, NLP, CV, unsupervised learning, and diffusion models.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.
SkyRL
SkyRL is a full-stack RL library that provides components such as 'skyagent' for training long-horizon, real-world agents, 'skyrl-train' for modular RL training, and 'skyrl-gym' for a variety of tool-use tasks. It offers a library of math, coding, search, and SQL environments implemented in the Gymnasium API, optimized for multi-turn tool use LLMs on long-horizon, real-environment tasks.
ToolUniverse
ToolUniverse is a collection of 211 biomedical tools designed for Agentic AI, providing access to biomedical knowledge for solving therapeutic reasoning tasks. The tools cover various aspects of drugs and diseases, linked to trusted sources like US FDA-approved drugs since 1939, Open Targets, and Monarch Initiative.
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
meridian
Meridian is a tool that provides personalized daily intelligence briefings by scraping news from hundreds of sources, analyzing stories with AI, and delivering concise briefs. It offers key global events, context, implications analysis, and open-source transparency. Built for the curious who seek in-depth news beyond headlines without spending too much time. The tool uses multi-stage LLM processing for article and cluster analysis, smart clustering techniques to group related articles, and a web interface powered by Nuxt 3. The workflow involves scraping RSS feeds, processing articles with Gemini for relevance, clustering articles, and generating a final brief. The project leverages AI models like Gemini, multilingual embeddings, UMAP, and HDBSCAN for analysis. The tech stack includes Turborepo, Cloudflare services, TypeScript, PostgreSQL, and Nuxt 3 with Vue 3 and Tailwind for the frontend.
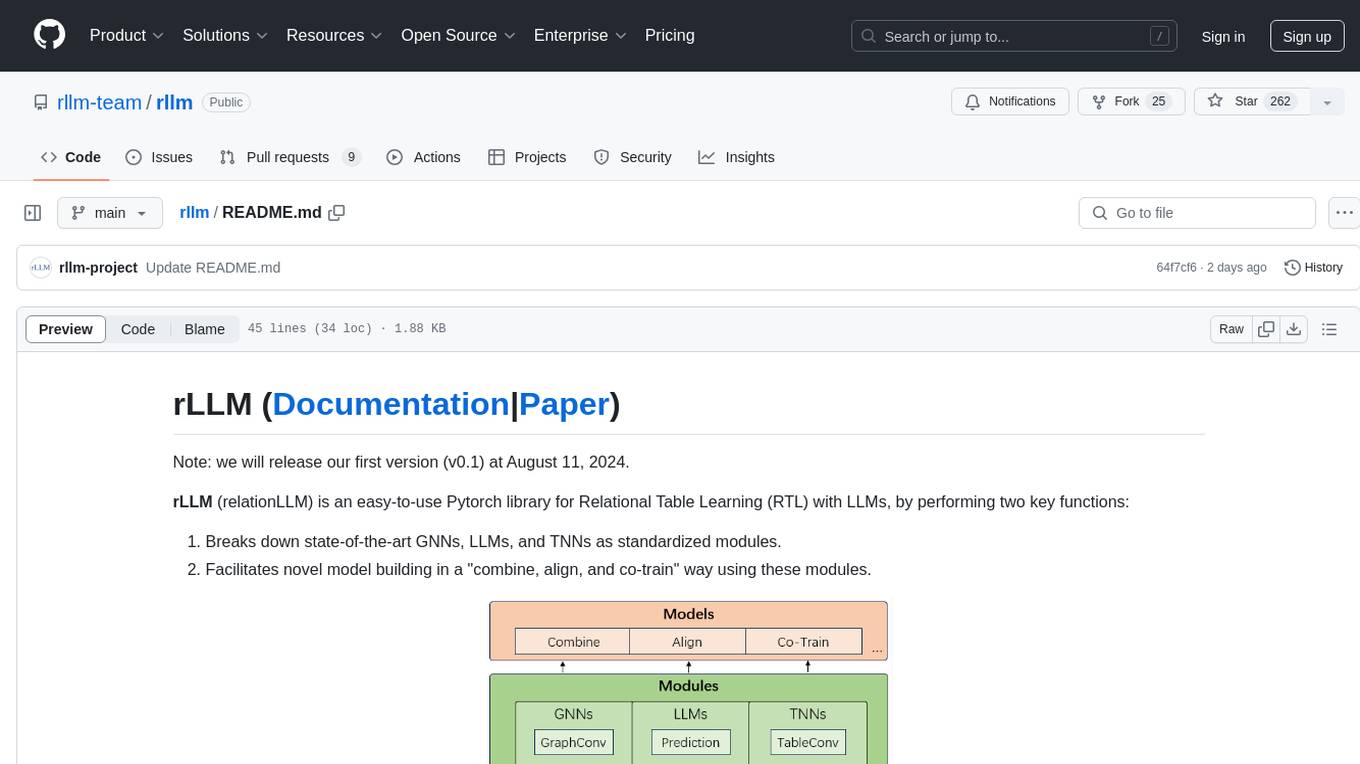
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
agentfactory
The AI Agent Factory is a spec-driven blueprint for building and monetizing digital FTEs. It empowers developers, entrepreneurs, and organizations to learn, build, and monetize intelligent AI agents, creating reliable digital FTEs that can be trusted, deployed, and scaled. The tool focuses on co-learning between humans and machines, emphasizing collaboration, clear specifications, and evolving together. It covers AI-assisted, AI-driven, and AI-native development approaches, guiding users through the AI development spectrum and organizational AI maturity levels. The core philosophy revolves around treating AI as a collaborative partner, using specification-first methodology, bilingual development, learning by doing, and ensuring transparency and reproducibility. The tool is suitable for beginners, professional developers, entrepreneurs, product leaders, educators, and tech leaders.
LLM101n
LLM101n is a course focused on building a Storyteller AI Large Language Model (LLM) from scratch in Python, C, and CUDA. The course covers various topics such as language modeling, machine learning, attention mechanisms, tokenization, optimization, device usage, precision training, distributed optimization, datasets, inference, finetuning, deployment, and multimodal applications. Participants will gain a deep understanding of AI, LLMs, and deep learning through hands-on projects and practical examples.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.
For similar tasks
AIRS
AIRS is a collection of open-source software tools, datasets, and benchmarks focused on Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. The goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources to advance the field of AI for Science. The current resources include tools for Quantum Mechanics, Density Functional Theory, Small Molecules, Protein Science, Materials Science, Molecular Interactions, and Partial Differential Equations.
AI2BMD
AI2BMD is a program for efficiently simulating protein molecular dynamics with ab initio accuracy. The repository contains datasets, simulation programs, and public materials related to AI2BMD. It provides a Docker image for easy deployment and a standalone launcher program. Users can run simulations by downloading the launcher script and specifying simulation parameters. The repository also includes ready-to-use protein structures for testing. AI2BMD is designed for x86-64 GNU/Linux systems with recommended hardware specifications. The related research includes model architectures like ViSNet, Geoformer, and fine-grained force metrics for MLFF. Citation information and contact details for the AI2BMD Team are provided.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
sciml.ai
SciML.ai is an open source software organization dedicated to unifying packages for scientific machine learning. It focuses on developing modular scientific simulation support software, including differential equation solvers, inverse problems methodologies, and automated model discovery. The organization aims to provide a diverse set of tools with a common interface, creating a modular, easily-extendable, and highly performant ecosystem for scientific simulations. The website serves as a platform to showcase SciML organization's packages and share news within the ecosystem. Pull requests are encouraged for contributions.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.