Best AI tools for< Lateral Thinking Trainer >
Infographic
3 - AI tool Sites
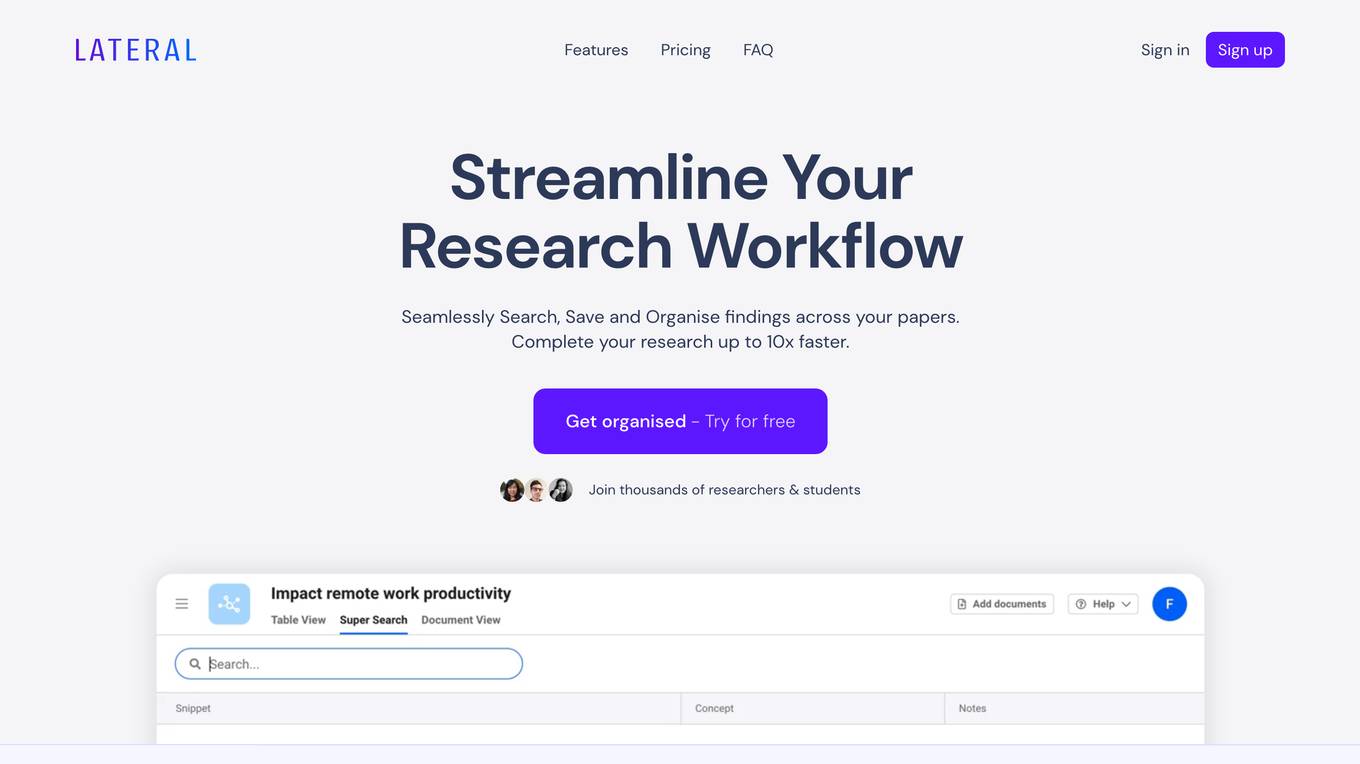
Lateral
Lateral is an AI-powered research tool that helps academics and students streamline their workflow by seamlessly searching, saving, and organizing findings across their papers. It uses AI to generate an auto-generated table, name concepts, and provide super search capabilities, making it easy to find relevant information quickly. Lateral also allows users to collaborate and share their work, making it a valuable tool for researchers working on collaborative projects.
Operant
Operant is a cloud-native runtime protection platform that offers instant visibility and control from infrastructure to APIs. It provides AI security shield for applications, API threat protection, Kubernetes security, automatic microsegmentation, and DevSecOps solutions. Operant helps defend APIs, protect Kubernetes, and shield AI applications by detecting and blocking various attacks in real-time. It simplifies security for cloud-native environments with zero instrumentation, application code changes, or integrations.
Pentest Copilot
Pentest Copilot by BugBase is an ultimate ethical hacking assistant that guides users through each step of the hacking journey, from analyzing web apps to root shells. It eliminates redundant research, automates payload and command generation, and provides intelligent contextual analysis to save time. The application excels at data extraction, privilege escalation, lateral movement, and leaving no trace behind. With features like secure VPN integration, total control over sessions, parallel command processing, and flexibility to choose between local or cloud execution, Pentest Copilot offers a seamless and efficient hacking experience without the need for Kali Linux installation.
0 - Open Source Tools
6 - OpenAI Gpts


AI Constitution
Literal interpretation of the U.S. Constitution, emphasizing clear language.