Best AI tools for< Synthesize Voices In Any Language >
20 - AI tool Sites
Revocalize AI
Revocalize AI is a studio-level AI voice generation and music tool that allows users to create studio-quality AI voices in one-click or choose from officially licensed AI voice models. The tool captures unique harmonics of a voice and transforms it into another, offering features like hyper-realistic AI voices with human-level emotion, voice synthesizing without constraints, real-time auto-pitch, and professional voice modulation. Users can create unlimited natural-sounding voice content without the need for a recording studio, explore an extensive catalog of voices, and give their voice exceptional expressiveness. Revocalize AI also offers language versatility, auto-generate vocal variations, and trusted by award-winning creators and professionals.
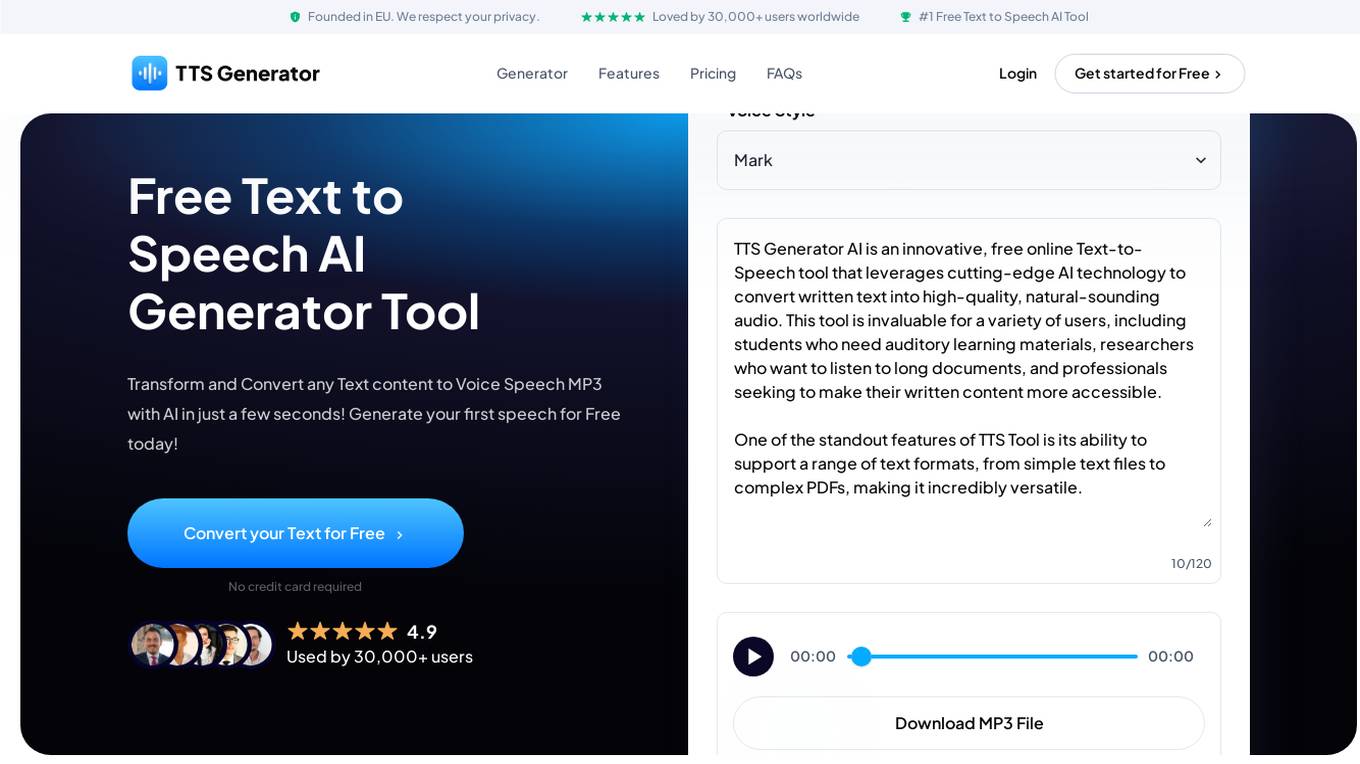
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
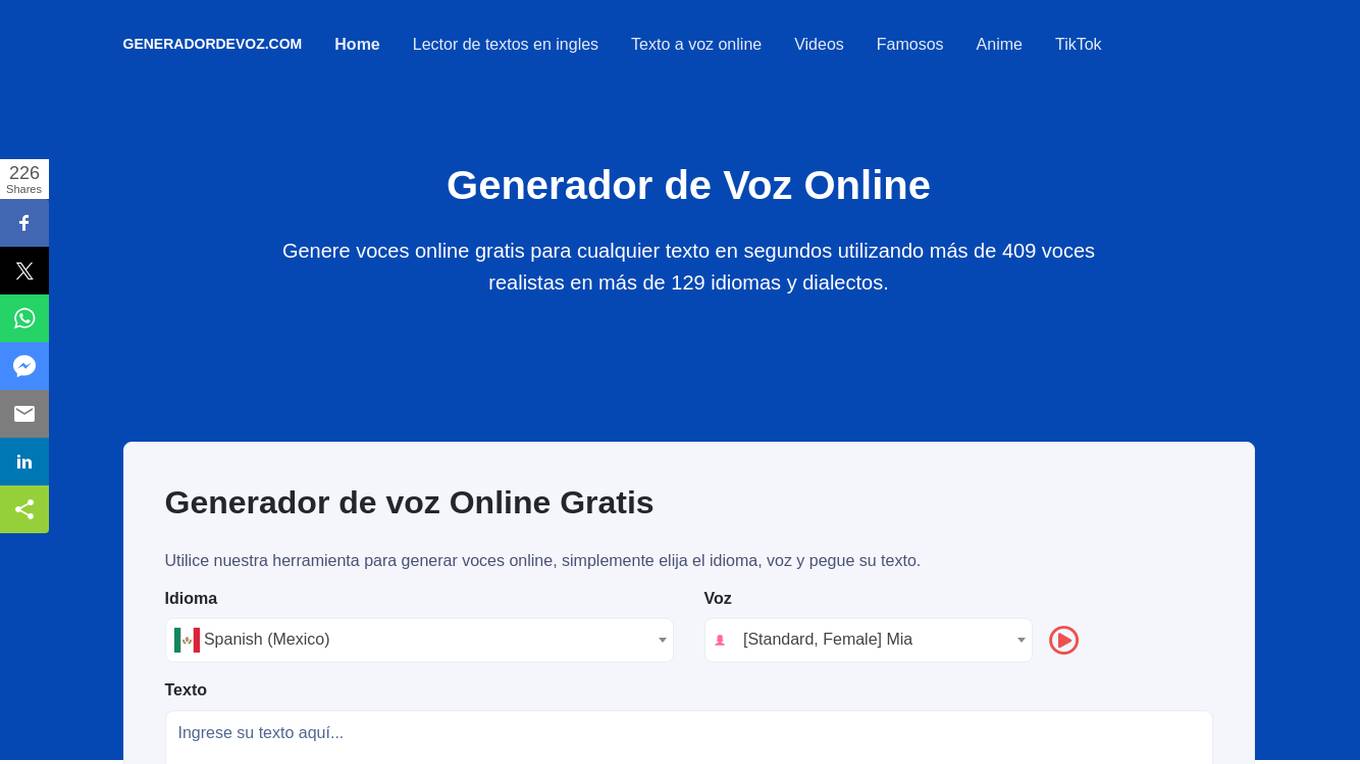
Generador de Voz
Generadordevoz.com is an online tool that allows users to generate voices for any text in seconds using over 409 realistic voices in more than 129 languages and dialects. Users can choose the language, voice, and paste their text to generate voices online. The tool offers advanced features such as extended character limit for audio generation, access to generated audio history, audio control settings, realistic breathing pauses, SSML support for audio customization, and priority support. Users can participate by creating articles or videos showcasing the tool's usage to gain access to the Advanced Panel with premium features. The tool can be used for various purposes such as advertisements, corporate training, IVR greetings, product promotions, podcasts, YouTube monetization, audiobooks, social media videos, news delivery, university lectures, accessibility for people with disabilities, and more.
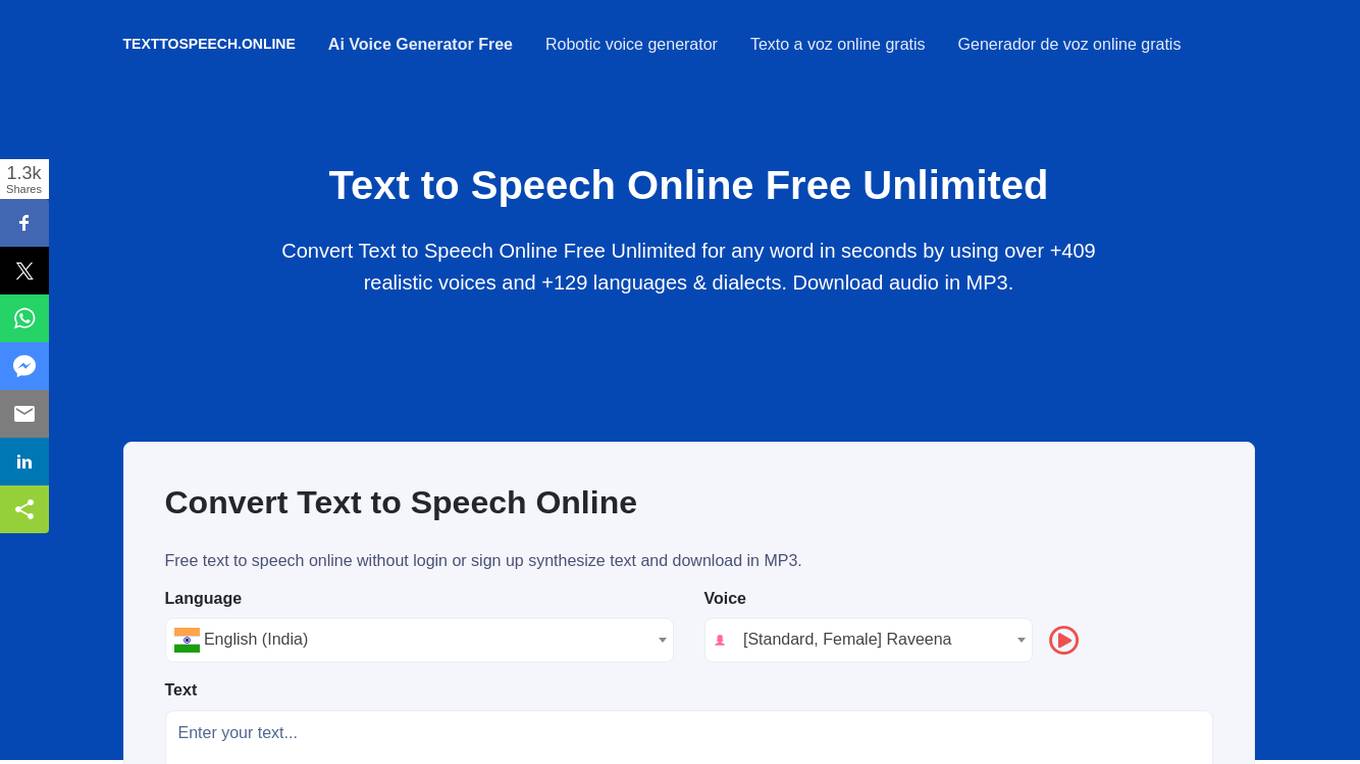
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
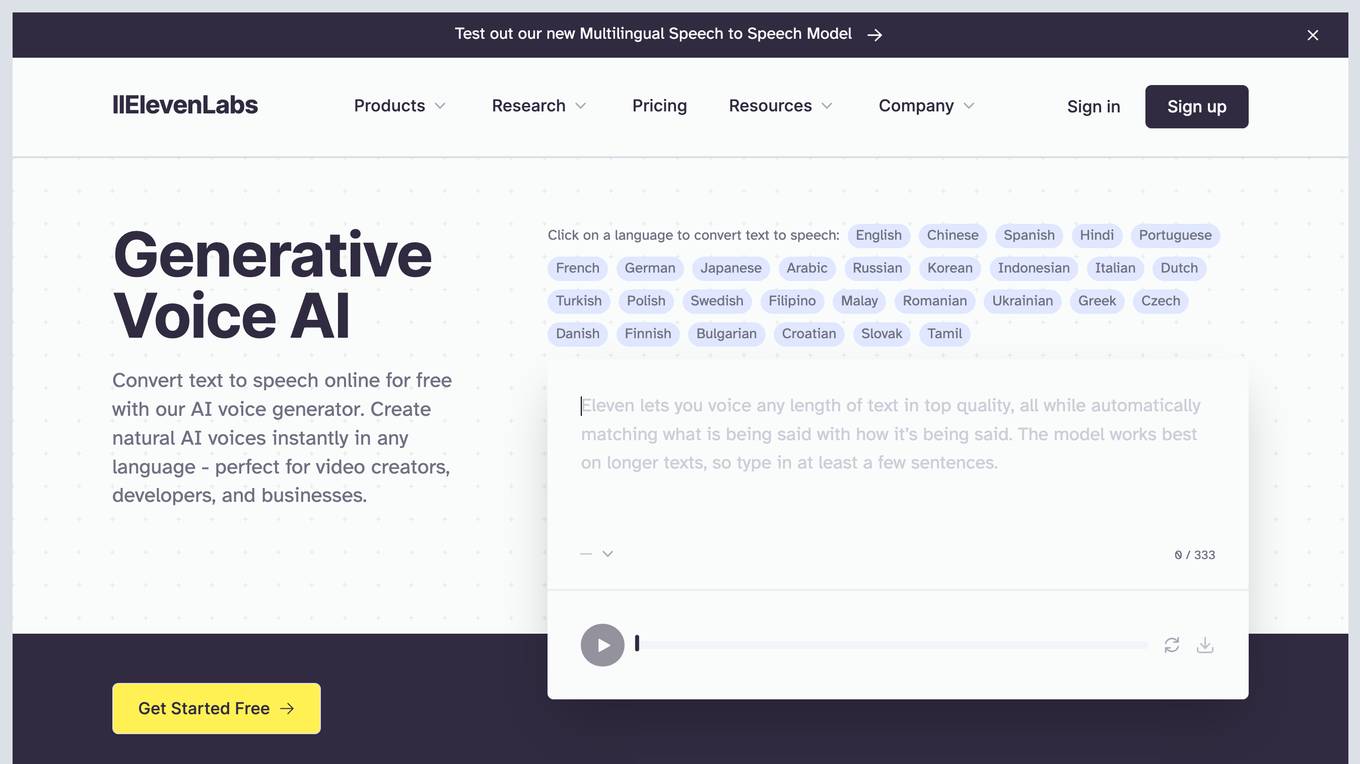
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
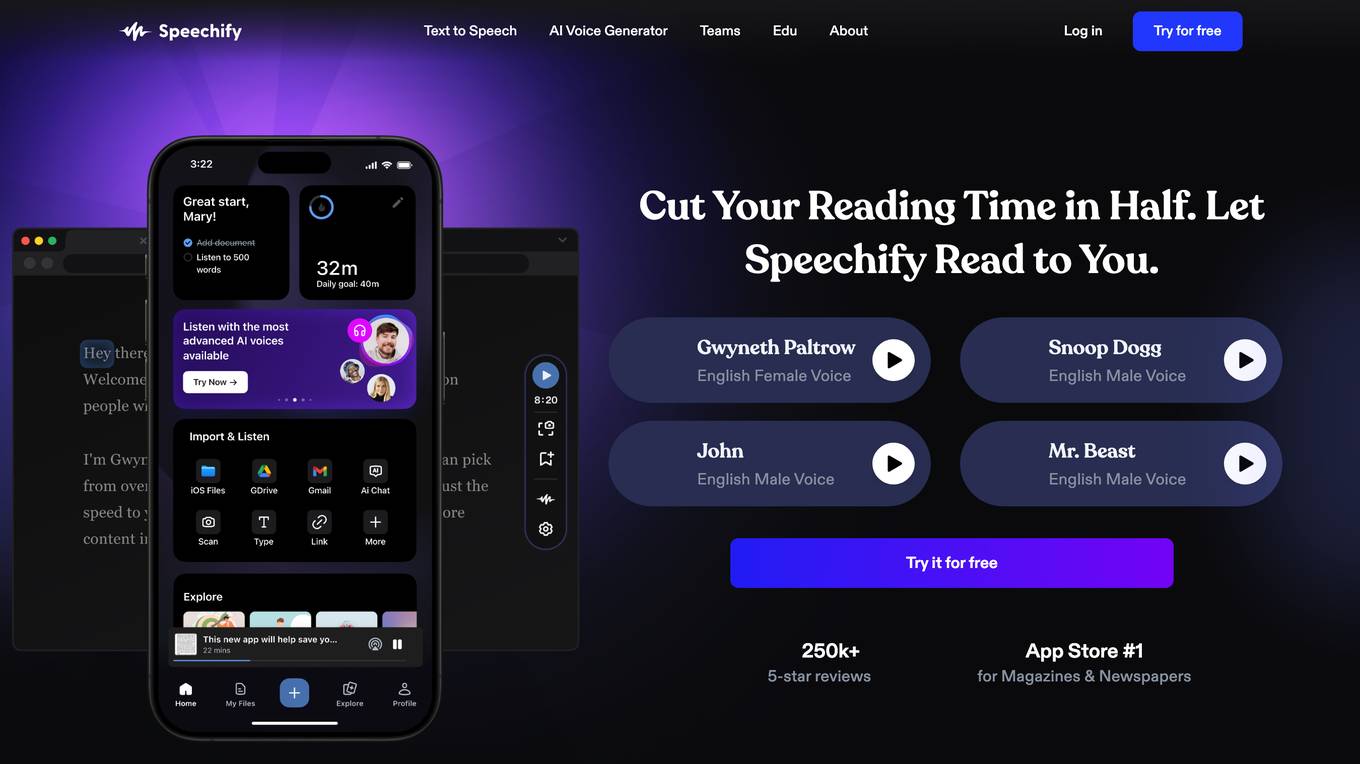
Speechify
Speechify is the #1 rated AI text to speech app in its category with over 250,000 5 star reviews. It is available as a Chrome extension, iOS app, Android app, Microsoft Edge Add-on, and web app. Speechify can convert any text into natural-sounding AI voice in over 50 languages and accents. It can also read aloud any PDF, doc, or web page. Speechify is used by students, professionals, readers, and those who struggle to read. It can help with reading comprehension, focus, and retention. Speechify is also a great tool for people with disabilities such as dyslexia, ADHD, and dry eyes.
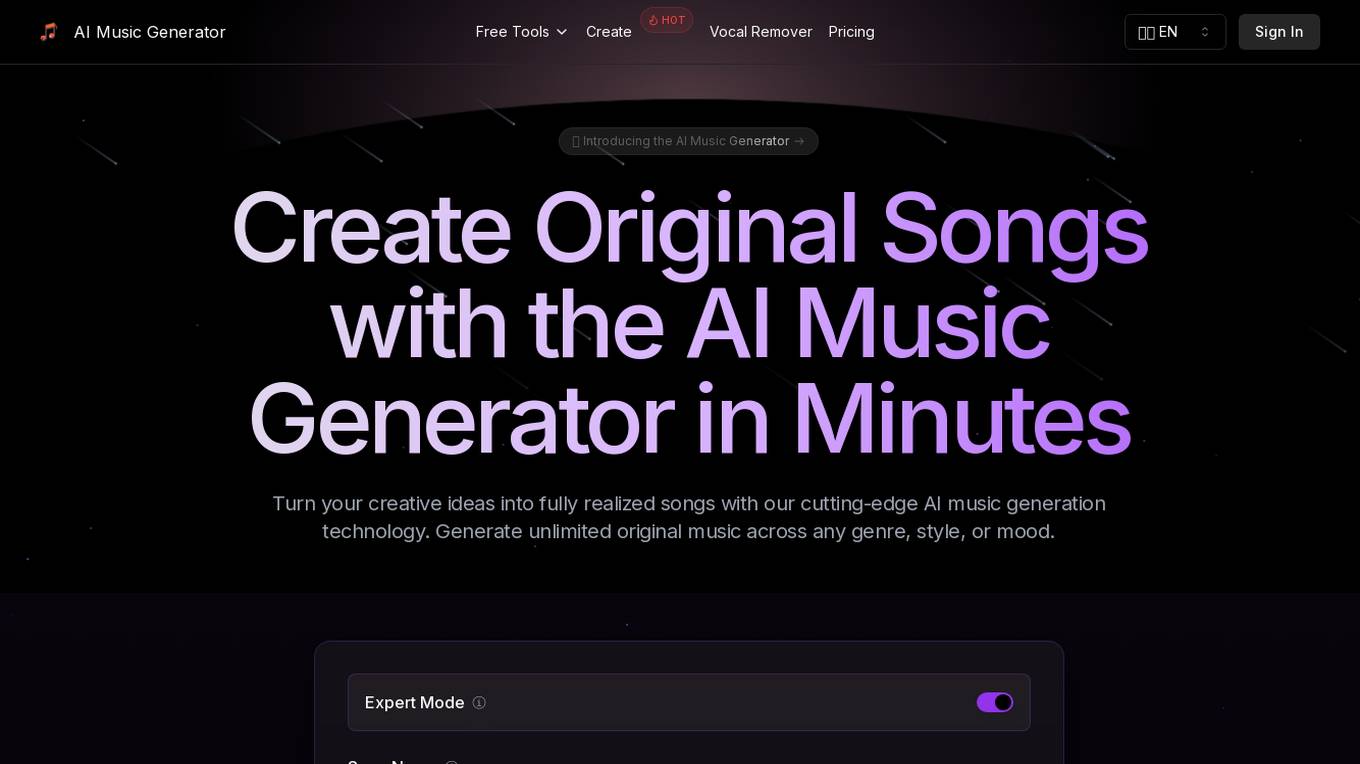
AI Music Generator
The AI Music Generator is an advanced platform powered by AI technology that allows users to create original music in any genre, style, or mood. It offers a range of features such as Text To Song, Lyrics To Song, AI Song Cover Generator, Voice Remover, Music Extension, Lyrics Generator, and more. The platform leverages deep learning models, transformer architecture, and neural networks to produce professional-quality music with voice synthesis and audio processing capabilities. Users can customize music styles, genres, and arrangements, and the tool is suitable for musicians, content creators, game developers, filmmakers, podcasters, businesses, and creative professionals.
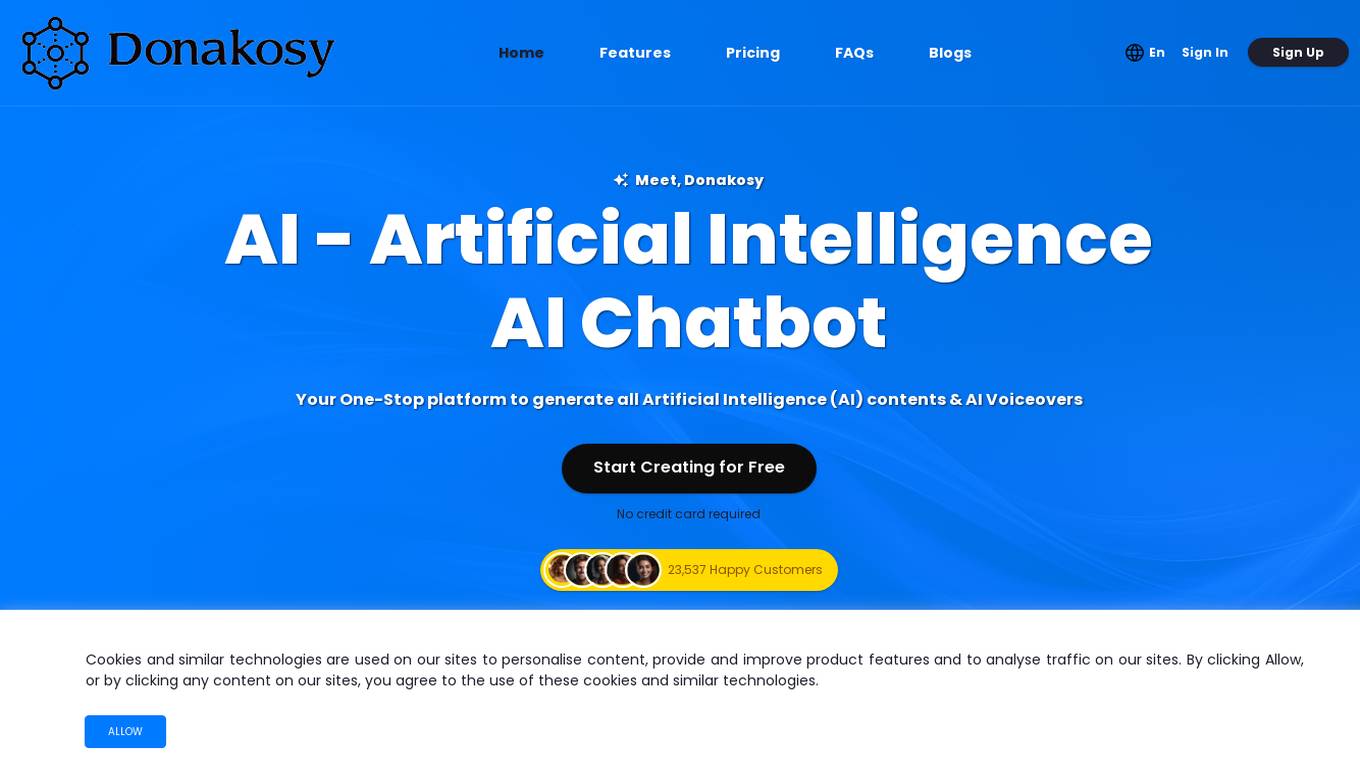
Donakosy
Donakosy is an AI-powered content and voiceover generation platform that helps professionals and content creators save time and effort while creating high-quality written content and lifelike voiceovers. With its advanced AI algorithms and machine learning capabilities, Donakosy analyzes vast amounts of data to understand patterns, styles, and context, enabling it to generate content that is not only accurate and relevant but also exhibits a human-like touch. The platform offers a wide range of features, including the ability to generate written content up to 100K characters, synthesize voices in multiple languages, and provide lifelike audio content. Donakosy is designed to be user-friendly and accessible to individuals with no prior AI knowledge or experience, making it a valuable tool for professionals and content creators alike.
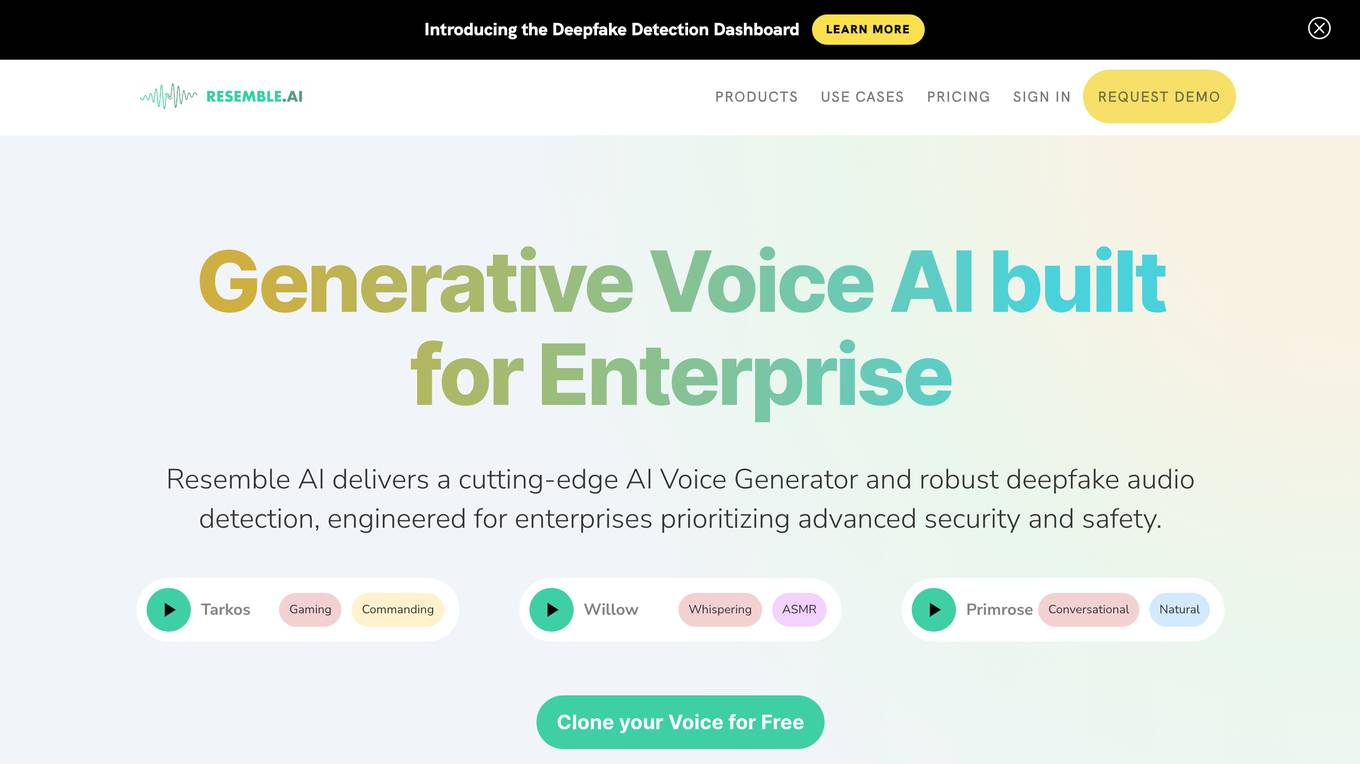
AI Voice Generator
The AI Voice Generator is an advanced tool that offers features such as voice cloning, text-to-speech, speech-to-speech conversion, multilingual support, audio editing, and deepfake detection. It provides state-of-the-art detection models and tools for creating AI voices that are indistinguishable from humans. The application is widely used in various industries for tasks like personalization, entertainment, education, and content creation.
Voicer
Voicer is a Text to Speech WordPress Plugin that utilizes machine learning and artificial intelligence to synthesize text into high-quality human voices across 45+ languages and variants. It offers more than 275 human-like voices, works with all WordPress themes, and is perfect for RTL direction. The plugin applies advanced deep learning neural network algorithms to create lifelike interactions with users, transforming customer service and device interaction.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Betafi
Betafi is a cloud-based user research and product feedback platform that helps businesses capture, organize, and share customer feedback from various sources, including user interviews, usability testing, and product demos. It offers features such as timestamped note-taking, automatic transcription and translation, video clipping, and integrations with popular collaboration tools like Miro, Figma, and Notion. Betafi enables teams to gather qualitative and quantitative feedback from users, synthesize insights, and make data-driven decisions to improve their products and services.
Synthesizer V
Dreamtonics is a Tokyo-based startup company specializing in computer music and speech technologies. They build music software to suit customers' creativity needs and offer technology licensing and the creation of artificial voices as a service for corporate clients. Their flagship product is Synthesizer V, a singing synthesizer that combines a powerful audio processing engine with an intuitive user interface. With Synthesizer V, users can create their own songs by sketching out the melody and filling in the lyrics.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
Voicepanel
Voicepanel is an AI-powered platform that helps businesses gather detailed feedback from their customers at unprecedented speed and scale. It uses AI to recruit target audiences, conduct interviews over voice or video, and synthesize actionable insights instantly. Voicepanel's platform is easy to use and can be set up in minutes. It offers a variety of features, including AI interviewing, AI recruiting, and AI synthesis. Voicepanel is a valuable tool for businesses that want to gain a deeper understanding of their customers and make better decisions.
Synthesia
Synthesia is an AI video assistant platform that offers innovative features to create engaging videos. Users can turn .PPTX files into videos, animate texts based on scripts, clone voices in multiple languages, use expressive avatars that follow text sentiment, and collaborate live on video creation. The platform is designed to streamline video production processes and enhance user creativity.
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.

ttsMP3.com
ttsMP3.com is a free Text-To-Speech and Text-to-MP3 tool that allows users to easily convert US English text into professional speech for various purposes such as e-learning, presentations, YouTube videos, and website accessibility. The tool offers a wide range of voices in different languages and accents, including regular and AI voices. Users can download the generated speech as MP3 files, and customize speech with features like breaks, emphasis, speed adjustments, pitch variations, whispers, and conversations. Supported voice languages include Arabic, English, Portuguese, Spanish, Chinese, Danish, Dutch, French, German, Icelandic, Indian, Italian, Japanese, Korean, Mexican, Norwegian, Polish, Romanian, Russian, Swedish, Turkish, and Welsh.
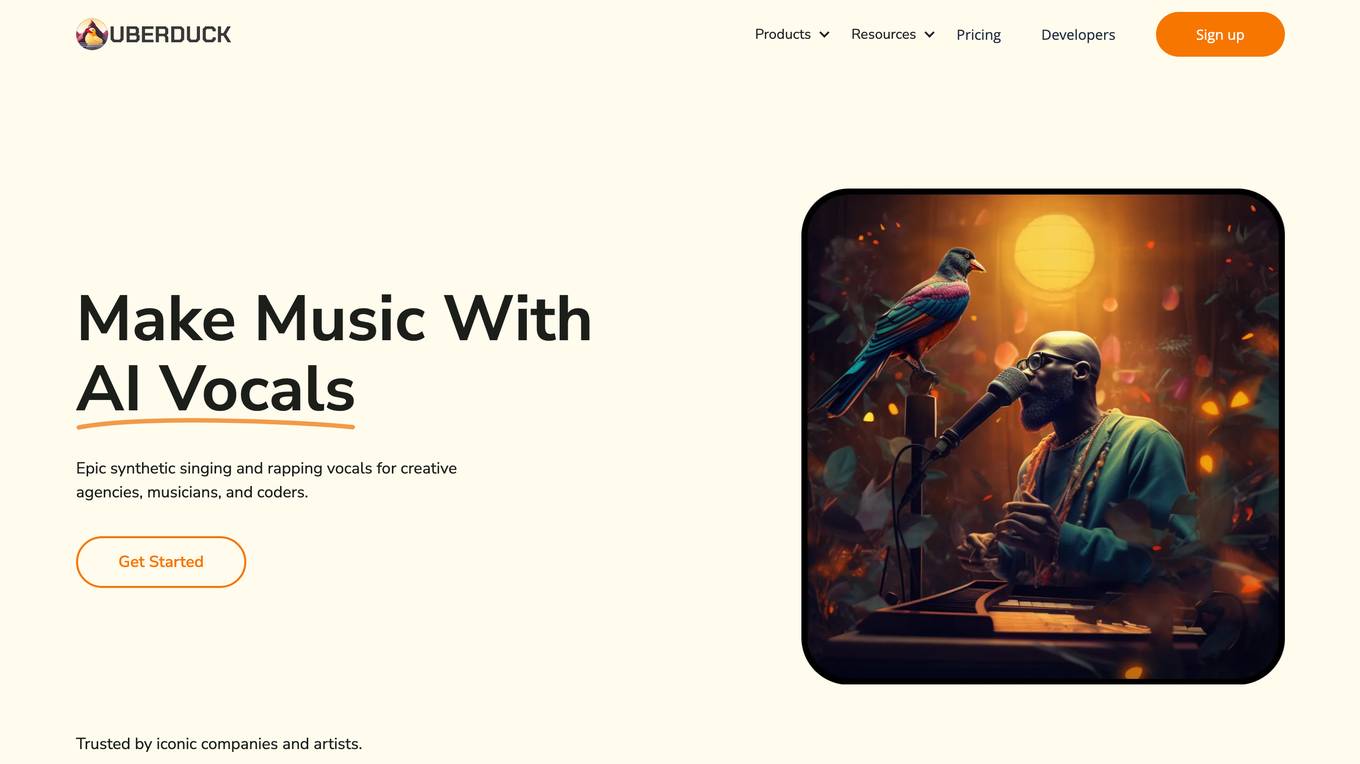
Uberduck
Uberduck is an AI-powered platform that allows users to create synthetic singing and rapping vocals. With Uberduck, users can choose from a collection of beats, generate lyrics with AI or write their own, choose a voice from a library of built-in voices or create their own custom voice, and download their creation as an audio or video file. Uberduck's technology has been used by major companies and artists, and has been featured in popular songs and videos.
Voxify
Voxify is an AI voice generator tool that allows users to effortlessly create immersive audio experiences by converting text to speech. With over 450 voices available in more than 120 languages and accents, users can customize every aspect of the narration, including pitch, speed, and emotion. Ideal for content creators, podcasters, and educators looking to enhance the quality of their voiceovers, Voxify offers a user-friendly interface and a wide range of customization options to bring text to life through realistic and engaging voice generation.
20 - Open Source AI Tools
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
EmotiVoice
EmotiVoice is a powerful and modern open-source text-to-speech engine that supports emotional synthesis, enabling users to create speech with a wide range of emotions such as happy, excited, sad, and angry. It offers over 2000 different voices in both English and Chinese. Users can access EmotiVoice through an easy-to-use web interface or a scripting interface for batch generation of results. The tool is continuously evolving with new features and updates, prioritizing community input and user feedback.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
skyeye
SkyEye is an AI-powered Ground Controlled Intercept (GCI) bot designed for the flight simulator Digital Combat Simulator (DCS). It serves as an advanced replacement for the in-game E-2, E-3, and A-50 AI aircraft, offering modern voice recognition, natural-sounding voices, real-world brevity and procedures, a wide range of commands, and intelligent battlespace monitoring. The tool uses Speech-To-Text and Text-To-Speech technology, can run locally or on a cloud server, and is production-ready software used by various DCS communities.

ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
AI.Labs
AI.Labs is an open-source project that integrates advanced artificial intelligence technologies to create a powerful AI platform. It focuses on integrating AI services like large language models, speech recognition, and speech synthesis for functionalities such as dialogue, voice interaction, and meeting transcription. The project also includes features like a large language model dialogue system, speech recognition for meeting transcription, speech-to-text voice synthesis, integration of translation and chat, and uses technologies like C#, .Net, SQLite database, XAF, OpenAI API, TTS, and STT.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.


MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
20 - OpenAI Gpts

Talk to a TV / Movie Character
I respond and answer as a specific character or person, using their tone and style.
PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity

AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.