
txtai
💡 All-in-one open-source AI framework for semantic search, LLM orchestration and language model workflows
Stars: 11553

Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.
README:
![]()
All-in-one AI framework



![]()

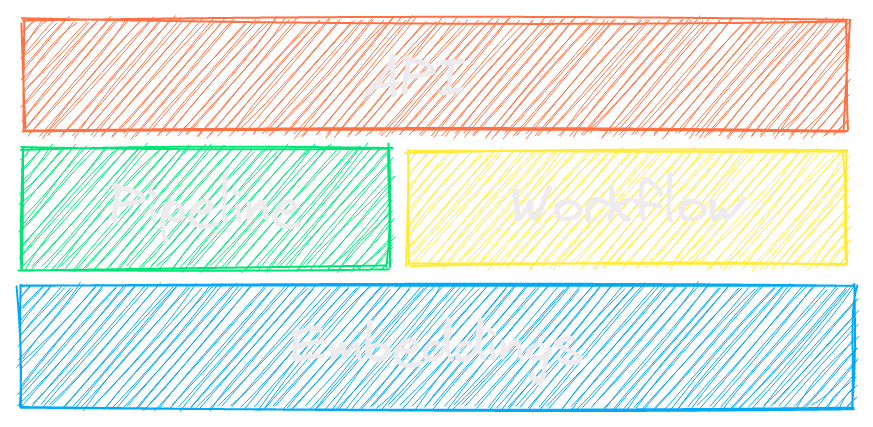
txtai is an all-in-one AI framework for semantic search, LLM orchestration and language model workflows.


The key component of txtai is an embeddings database, which is a union of vector indexes (sparse and dense), graph networks and relational databases.
This foundation enables vector search and/or serves as a powerful knowledge source for large language model (LLM) applications.
Build autonomous agents, retrieval augmented generation (RAG) processes, multi-model workflows and more.
Summary of txtai features:
- 🔎 Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
- 📄 Create embeddings for text, documents, audio, images and video
- 💡 Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarization and more
- ↪️️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
- 🤖 Agents that intelligently connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems
- ⚙️ Web and Model Context Protocol (MCP) APIs. Bindings available for JavaScript, Java, Rust and Go.
- 🔋 Batteries included with defaults to get up and running fast
- ☁️ Run local or scale out with container orchestration
txtai is built with Python 3.10+, Hugging Face Transformers, Sentence Transformers and FastAPI. txtai is open-source under an Apache 2.0 license.
Interested in an easy and secure way to run hosted txtai applications? Then join the txtai.cloud preview to learn more.

New vector databases, LLM frameworks and everything in between are sprouting up daily. Why build with txtai?
# Get started in a couple lines
import txtai
embeddings = txtai.Embeddings()
embeddings.index(["Correct", "Not what we hoped"])
embeddings.search("positive", 1)
#[(0, 0.29862046241760254)]- Built-in API makes it easy to develop applications using your programming language of choice
# app.yml
embeddings:
path: sentence-transformers/all-MiniLM-L6-v2CONFIG=app.yml uvicorn "txtai.api:app"
curl -X GET "http://localhost:8000/search?query=positive"- Run local - no need to ship data off to disparate remote services
- Work with micromodels all the way up to large language models (LLMs)
- Low footprint - install additional dependencies and scale up when needed
- Learn by example - notebooks cover all available functionality
The following sections introduce common txtai use cases. A comprehensive set of over 60 example notebooks and applications are also available.
Build semantic/similarity/vector/neural search applications.

Traditional search systems use keywords to find data. Semantic search has an understanding of natural language and identifies results that have the same meaning, not necessarily the same keywords.

Get started with the following examples.
| Notebook | Description | |
|---|---|---|
|
Introducing txtai |
Overview of the functionality provided by txtai | |
| Similarity search with images | Embed images and text into the same space for search | |
| Build a QA database | Question matching with semantic search | |
| Semantic Graphs | Explore topics, data connectivity and run network analysis |
Autonomous agents, retrieval augmented generation (RAG), chat with your data, pipelines and workflows that interface with large language models (LLMs).
See below to learn more.
| Notebook | Description | |
|---|---|---|
| Prompt templates and task chains | Build model prompts and connect tasks together with workflows | |
| Integrate LLM frameworks | Integrate llama.cpp, LiteLLM and custom generation frameworks | |
| Build knowledge graphs with LLMs | Build knowledge graphs with LLM-driven entity extraction | |
| Parsing the stars with txtai | Explore an astronomical knowledge graph of known stars, planets, galaxies |
Agents connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems.
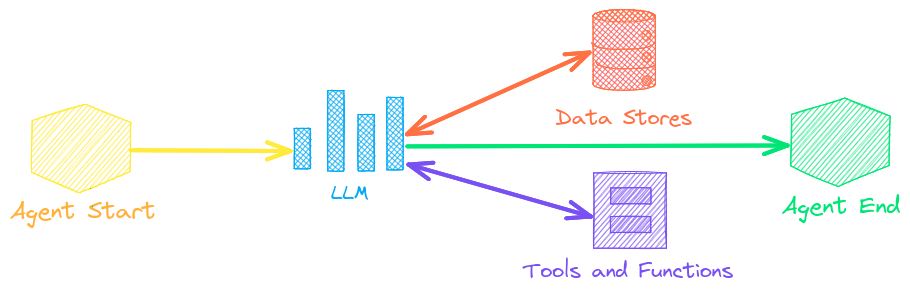
txtai agents are built on top of the smolagents framework. This supports all LLMs txtai supports (Hugging Face, llama.cpp, OpenAI / Claude / AWS Bedrock via LiteLLM).
See the link below to learn more.
| Notebook | Description | |
|---|---|---|
| Analyzing Hugging Face Posts with Graphs and Agents | Explore a rich dataset with Graph Analysis and Agents | |
| Granting autonomy to agents | Agents that iteratively solve problems as they see fit | |
| Analyzing LinkedIn Company Posts with Graphs and Agents | Exploring how to improve social media engagement with AI |
Retrieval augmented generation (RAG) reduces the risk of LLM hallucinations by constraining the output with a knowledge base as context. RAG is commonly used to "chat with your data".


A novel feature of txtai is that it can provide both an answer and source citation.
| Notebook | Description | |
|---|---|---|
| Build RAG pipelines with txtai | Guide on retrieval augmented generation including how to create citations | |
| Chunking your data for RAG | Extract, chunk and index content for effective retrieval | |
| Advanced RAG with graph path traversal | Graph path traversal to collect complex sets of data for advanced RAG | |
|
Speech to Speech RAG |
Full cycle speech to speech workflow with RAG |
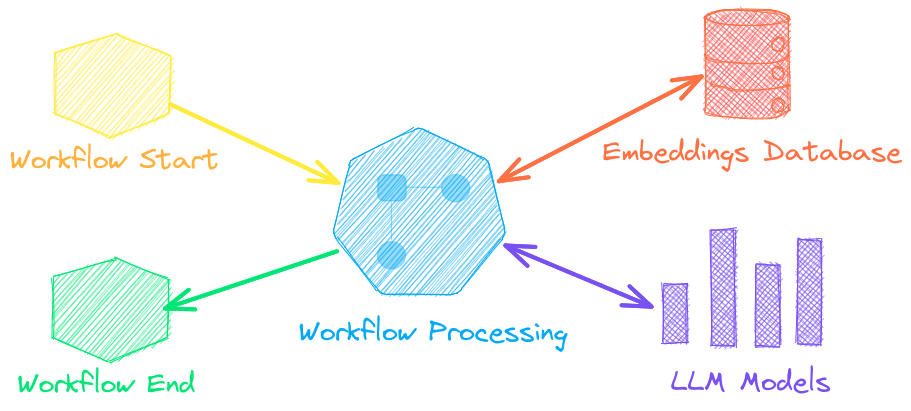
Language model workflows, also known as semantic workflows, connect language models together to build intelligent applications.


While LLMs are powerful, there are plenty of smaller, more specialized models that work better and faster for specific tasks. This includes models for extractive question-answering, automatic summarization, text-to-speech, transcription and translation.
| Notebook | Description | |
|---|---|---|
|
Run pipeline workflows |
Simple yet powerful constructs to efficiently process data | |
| Building abstractive text summaries | Run abstractive text summarization | |
| Transcribe audio to text | Convert audio files to text | |
| Translate text between languages | Streamline machine translation and language detection |


The easiest way to install is via pip and PyPI
pip install txtai
Python 3.10+ is supported. Using a Python virtual environment is recommended.
See the detailed install instructions for more information covering optional dependencies, environment specific prerequisites, installing from source, conda support and how to run with containers.
See the table below for the current recommended models. These models all allow commercial use and offer a blend of speed and performance.
Models can be loaded as either a path from the Hugging Face Hub or a local directory. Model paths are optional, defaults are loaded when not specified. For tasks with no recommended model, txtai uses the default models as shown in the Hugging Face Tasks guide.
See the following links to learn more.
- Hugging Face Tasks
- Hugging Face Model Hub
- MTEB Leaderboard
- LMSYS LLM Leaderboard
- Open LLM Leaderboard
The following applications are powered by txtai.
| Application | Description |
|---|---|
| rag | Retrieval Augmented Generation (RAG) application |
| ragdata | Build knowledge bases for RAG |
| paperai | AI for medical and scientific papers |
| annotateai | Automatically annotate papers with LLMs |
In addition to this list, there are also many other open-source projects, published research and closed proprietary/commercial projects that have built on txtai in production.


- Introducing txtai, the all-in-one AI framework
- Tutorial series on Hashnode | dev.to
- What's new in txtai 9.0 | 8.0 | 7.0 | 6.0 | 5.0 | 4.0
- Getting started with semantic search | workflows | rag
- Running txtai at scale
- Vector search & RAG Landscape: A review with txtai
Full documentation on txtai including configuration settings for embeddings, pipelines, workflows, API and a FAQ with common questions/issues is available.
For those who would like to contribute to txtai, please see this guide.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for txtai
Similar Open Source Tools
txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.
Olares
Olares is an open-source sovereign cloud OS designed for local AI, enabling users to build their own AI assistants, sync data across devices, self-host their workspace, stream media, and more within a sovereign cloud environment. Users can effortlessly run leading AI models, deploy open-source AI apps, access AI apps and models anywhere, and benefit from integrated AI for personalized interactions. Olares offers features like edge AI, personal data repository, self-hosted workspace, private media server, smart home hub, and user-owned decentralized social media. The platform provides enterprise-grade security, secure application ecosystem, unified file system and database, single sign-on, AI capabilities, built-in applications, seamless access, and development tools. Olares is compatible with Linux, Raspberry Pi, Mac, and Windows, and offers a wide range of system-level applications, third-party components and services, and additional libraries and components.
cocoindex
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.
haystack-tutorials
Haystack is an open-source framework for building production-ready LLM applications, retrieval-augmented generative pipelines, and state-of-the-art search systems that work intelligently over large document collections. It lets you quickly try out the latest models in natural language processing (NLP) while being flexible and easy to use.

pipeline
Pipeline is a Python library designed for constructing computational flows for AI/ML models. It supports both development and production environments, offering capabilities for inference, training, and finetuning. The library serves as an interface to Mystic, enabling the execution of pipelines at scale and on enterprise GPUs. Users can also utilize this SDK with Pipeline Core on a private hosted cluster. The syntax for defining AI/ML pipelines is reminiscent of sessions in Tensorflow v1 and Flows in Prefect.
recommenders
Recommenders is a project under the Linux Foundation of AI and Data that assists researchers, developers, and enthusiasts in prototyping, experimenting with, and bringing to production a range of classic and state-of-the-art recommendation systems. The repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. It covers tasks such as preparing data, building models using various recommendation algorithms, evaluating algorithms, tuning hyperparameters, and operationalizing models in a production environment on Azure. The project provides utilities to support common tasks like loading datasets, evaluating model outputs, and splitting training/test data. It includes implementations of state-of-the-art algorithms for self-study and customization in applications.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
Dictate
Dictate is an easy-to-use keyboard tool that utilizes OpenAI Whisper for transcription and dictation. It offers accurate results in multiple languages with punctuation and custom AI rewording using GPT-4 Omni. The tool is designed to simplify the process of transcribing spoken words into text, making it convenient for users to dictate their thoughts and notes effortlessly.
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)
palico-ai
Palico AI is a tech stack designed for rapid iteration of LLM applications. It allows users to preview changes instantly, improve performance through experiments, debug issues with logs and tracing, deploy applications behind a REST API, and manage applications with a UI control panel. Users have complete flexibility in building their applications with Palico, integrating with various tools and libraries. The tool enables users to swap models, prompts, and logic easily using AppConfig. It also facilitates performance improvement through experiments and provides options for deploying applications to cloud providers or using managed hosting. Contributions to the project are welcomed, with easy ways to get involved by picking issues labeled as 'good first issue'.
RAG-Driven-Generative-AI
RAG-Driven Generative AI provides a roadmap for building effective LLM, computer vision, and generative AI systems that balance performance and costs. This book offers a detailed exploration of RAG and how to design, manage, and control multimodal AI pipelines. By connecting outputs to traceable source documents, RAG improves output accuracy and contextual relevance, offering a dynamic approach to managing large volumes of information. This AI book also shows you how to build a RAG framework, providing practical knowledge on vector stores, chunking, indexing, and ranking. You'll discover techniques to optimize your project's performance and better understand your data, including using adaptive RAG and human feedback to refine retrieval accuracy, balancing RAG with fine-tuning, implementing dynamic RAG to enhance real-time decision-making, and visualizing complex data with knowledge graphs. You'll be exposed to a hands-on blend of frameworks like LlamaIndex and Deep Lake, vector databases such as Pinecone and Chroma, and models from Hugging Face and OpenAI. By the end of this book, you will have acquired the skills to implement intelligent solutions, keeping you competitive in fields ranging from production to customer service across any project.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
generative-ai-with-javascript
The 'Generative AI with JavaScript' repository is a comprehensive resource hub for JavaScript developers interested in delving into the world of Generative AI. It provides code samples, tutorials, and resources from a video series, offering best practices and tips to enhance AI skills. The repository covers the basics of generative AI, guides on building AI applications using JavaScript, from local development to deployment on Azure, and scaling AI models. It is a living repository with continuous updates, making it a valuable resource for both beginners and experienced developers looking to explore AI with JavaScript.
SLR-FC
This repository provides a comprehensive collection of AI tools and resources to enhance literature reviews. It includes a curated list of AI tools for various tasks, such as identifying research gaps, discovering relevant papers, visualizing paper content, and summarizing text. Additionally, the repository offers materials on generative AI, effective prompts, copywriting, image creation, and showcases of AI capabilities. By leveraging these tools and resources, researchers can streamline their literature review process, gain deeper insights from scholarly literature, and improve the quality of their research outputs.
For similar tasks

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
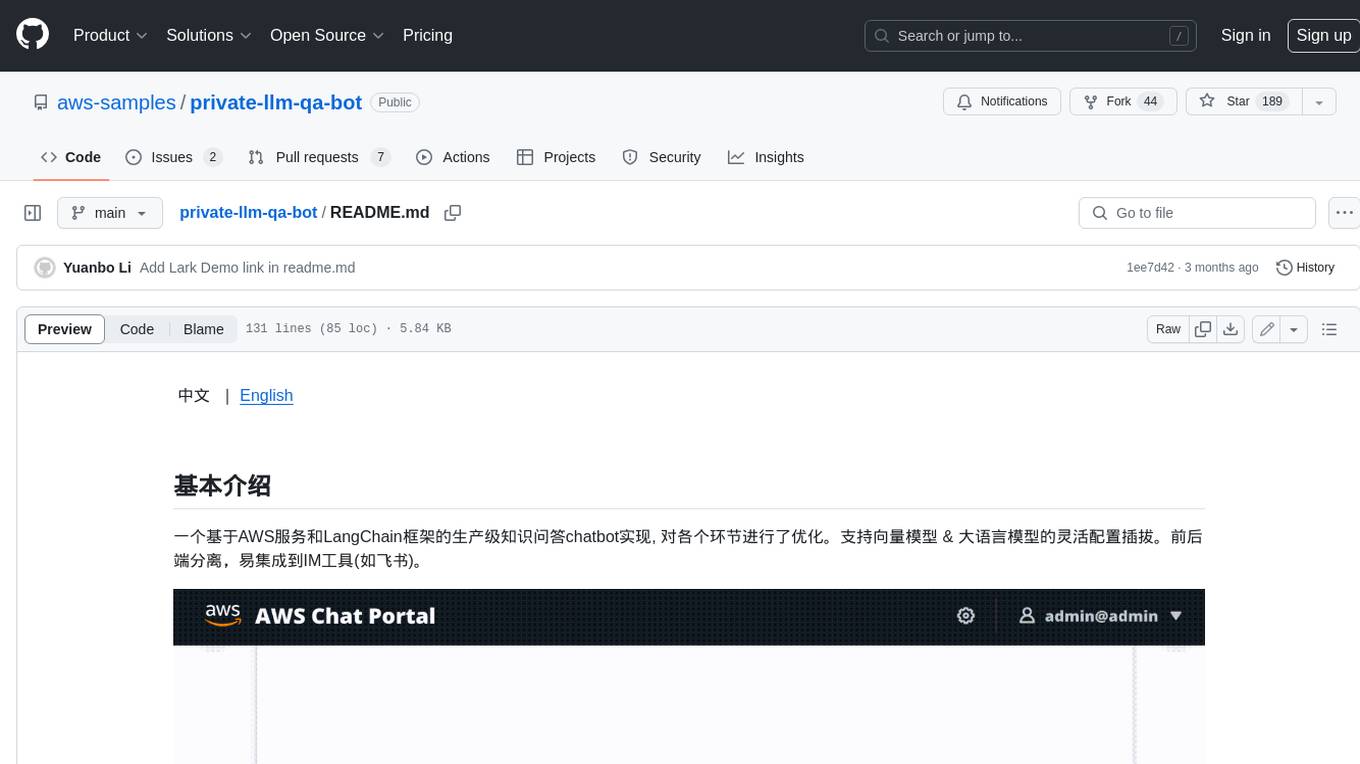
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.