
oss-fuzz-gen
LLM powered fuzzing via OSS-Fuzz.
Stars: 1162

This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
README:
This framework generates fuzz targets for real-world C/C++/Java/Python projects with
various Large Language Models (LLM) and benchmarks them via the
OSS-Fuzz platform.
More details available in AI-Powered Fuzzing: Breaking the Bug Hunting Barrier:

Current supported models are:
- Vertex AI code-bison
- Vertex AI code-bison-32k
- Gemini Pro
- Gemini Ultra
- Gemini Experimental
- Gemini 1.5
- OpenAI GPT-3.5-turbo
- OpenAI GPT-4
- OpenAI GPT-4o
- OpenAI GPT-4o-mini
- OpenAI GPT-4-turbo
- OpenAI GPT-3.5-turbo (Azure)
- OpenAI GPT-4 (Azure)
- OpenAI GPT-4o (Azure)
Generated fuzz targets are evaluated with four metrics against the most up-to-date data from production environment:
- Compilability
- Runtime crashes
- Runtime coverage
- Runtime line coverage diff against existing human-written fuzz targets in
OSS-Fuzz.
Here is a sample experiment result from 2024 Jan 31. The experiment included 1300+ benchmarks from 297 open-source projects.
Overall, this framework manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
Note that these reports are not public as they may contain undisclosed vulnerabilities.
Check our detailed usage guide for instructions on how to run this framework and generate reports based on the results.
Interested in research or open-source community collaborations? Please feel free to create an issue or email us: [email protected].

So far, we have reported 30 new bugs/vulnerabilities found by automatically generated targets built by this framework:
| Project | Bug | LLM | Prompt Builder | Target oracle |
|---|---|---|---|---|
cJSON |
OOB read | Vertex AI | Default | Far reach, low coverage |
libplist |
OOB read | Vertex AI | Default | Far reach, low coverage |
hunspell |
OOB read | Vertex AI | default | Far reach, low coverage |
zstd |
OOB write | Vertex AI | default | Far reach, low coverage |
gdbm |
Stack buffer underflow | Vertex AI | default | Far reach, low coverage |
hoextdown |
Use of uninitialised memory | Vertex AI | default | Far reach, low coverage |
pjsip |
OOB read | Vertex AI | Default | Low coverage with fuzz keyword + easy params far reach |
pjsip |
OOB read | Vertex AI | Default | Low coverage with fuzz keyword + easy params far reach |
gpac |
OOB read | Vertex AI | Default | Low coverage with fuzz keyword + easy params far reach |
gpac |
OOB read/write | Vertex AI | Default | All |
gpac |
OOB read | Vertex AI | Default | All |
gpac |
OOB read | Vertex AI | Default | All |
sqlite3 |
OOB read | Vertex AI | Default | All |
htslib |
OOB read | Vertex AI | Default | All |
libical |
OOB read | Vertex AI | Default | All |
croaring |
OOB read | Vertex AI | Test-to-harness | All |
openssl |
CVE-2024-9143 - OOB read/write | Vertex AI | Default | All |
liblouis |
Use of uninitialised memory | Vertex AI | Test-to-harness | Test identifier |
libucl |
OOB read | Vertex AI | Default | Low coverage with fuzz keyword + easy params far reach |
openbabel |
Use after free | Vertex AI | Default | Low coverage with fuzz keyword + easy params far reach |
libyang |
OOB read | Vertex AI | Default | All |
openbabel |
OOB read | Vertex AI | Default | All |
exiv2 |
OOB read | Vertex AI | Default | All |
| Undisclosed | Java RCE (pending maintainer triage) | Vertex AI | Default | Far reach, low coverage |
| Undisclosed | Regexp DoS (pending maintainer triage) | Vertex AI | Default | Far reach, low coverage |
| Undisclosed | OOB read | Vertex AI | Default | All |
| Undisclosed | OOB write | Vertex AI | Default | All |
| Undisclosed | OOB read | Vertex AI | Default | All |
| Undisclosed | OOB read | Vertex AI | Default | All |
| Undisclosed | Use after free | Vertex AI | Agent prompt | All |
These bugs could only have been discovered with newly generated targets. They were not reachable with existing OSS-Fuzz targets.
| Project | Total coverage gain | Total relative gain | OSS-Fuzz-gen total covered lines | OSS-Fuzz-gen new covered lines | Existing covered lines | Total project lines |
|---|---|---|---|---|---|---|
| phmap | 98.42% | 205.75% | 1601 | 1181 | 574 | 1120 |
| usbguard | 97.62% | 26.04% | 24550 | 5463 | 20979 | 3564 |
| onednn | 96.67% | 7057.14% | 5434 | 5434 | 77 | 210 |
| avahi | 82.06% | 155.90% | 3358 | 2814 | 1805 | 3046 |
| pugixml | 72.98% | 194.95% | 9015 | 6646 | 3409 | 7662 |
| librdkafka | 66.88% | 845.57% | 5019 | 4490 | 531 | 1169 |
| casync | 66.75% | 903.23% | 1171 | 1120 | 124 | 1678 |
| tomlplusplus | 61.06% | 331.10% | 4755 | 3652 | 1103 | 5981 |
| astc-encoder | 59.35% | 177.88% | 2726 | 1745 | 981 | 2940 |
| mruby | 48.56% | 0.00% | 34493 | 34493 | 0 | 71038 |
| arduinojson | 42.10% | 85.80% | 3344 | 1800 | 2098 | 4276 |
| json | 41.13% | 66.51% | 5051 | 3339 | 5020 | 8119 |
| double-conversion | 40.40% | 88.12% | 1663 | 779 | 884 | 1928 |
| tinyobjloader | 38.26% | 77.01% | 1157 | 717 | 931 | 1874 |
| glog | 38.18% | 58.69% | 895 | 331 | 564 | 867 |
| cppitertools | 35.78% | 45.07% | 253 | 151 | 335 | 422 |
| eigen | 35.38% | 190.70% | 2643 | 1947 | 1021 | 5503 |
| glaze | 34.55% | 30.06% | 2920 | 2416 | 8036 | 6993 |
| rapidjson | 31.83% | 148.07% | 1585 | 958 | 647 | 3010 |
| libunwind | 30.58% | 83.25% | 2899 | 1342 | 1612 | 4388 |
| openh264 | 30.07% | 50.14% | 6607 | 5751 | 11470 | 19123 |
* "Total project lines" measures the source code of the project-under-test compiled and linked by the preexisting human-written fuzz targets from OSS-Fuzz.
* "Total coverage gain" is calculated using a denominator of the "Total project lines". "Total relative gain" is the increase in coverage compared to the old number of covered lines.
* Additional code from the project-under-test maybe included when compiling the new fuzz targets and result in high percentage gains.
Please click on the 'Cite this repository' button located on the right-hand side of this GitHub page for citation details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for oss-fuzz-gen
Similar Open Source Tools
oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
ai-reference-models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
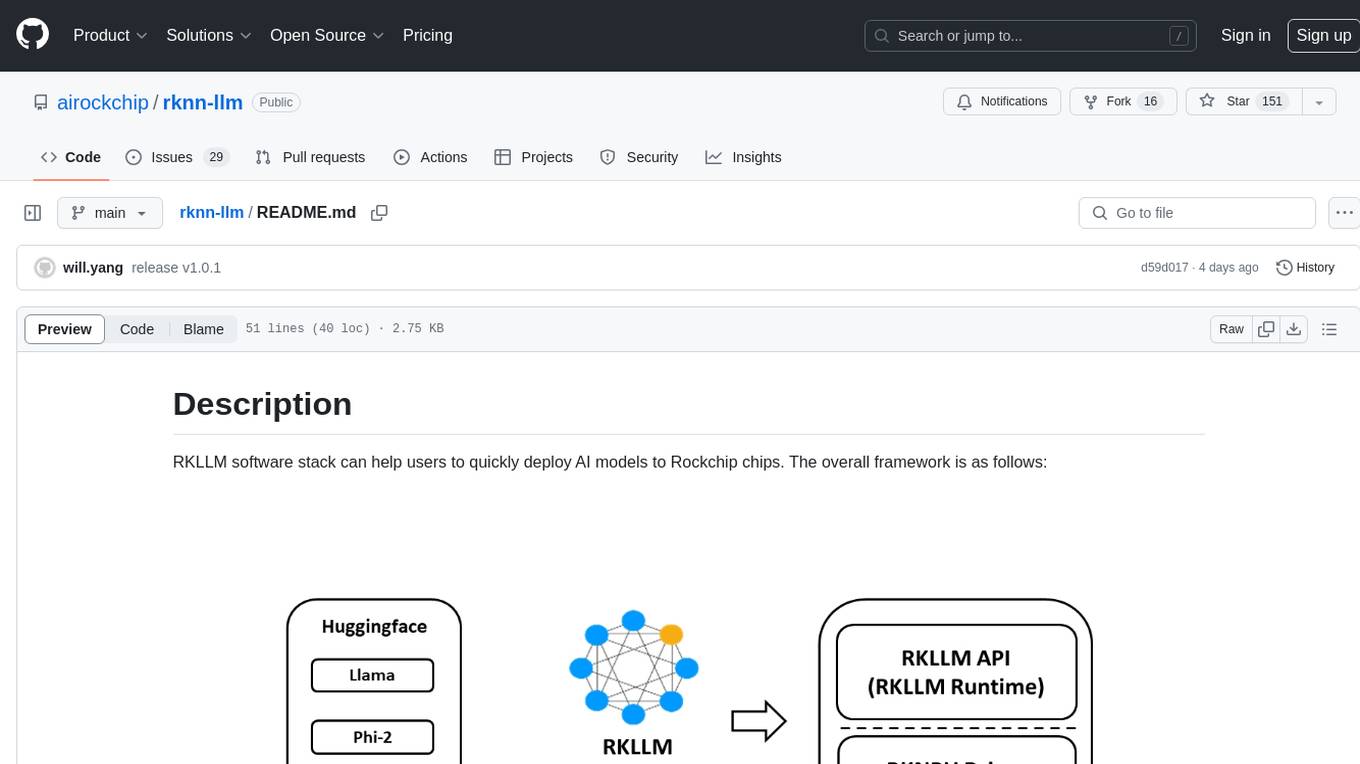
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool
Github-Ranking-AI
This repository provides a list of the most starred and forked repositories on GitHub. It is updated automatically and includes information such as the project name, number of stars, number of forks, language, number of open issues, description, and last commit date. The repository is divided into two sections: LLM and chatGPT. The LLM section includes repositories related to large language models, while the chatGPT section includes repositories related to the chatGPT chatbot.
Data-and-AI-Concepts
This repository is a curated collection of data science and AI concepts and IQs, covering topics from foundational mathematics to cutting-edge generative AI concepts. It aims to support learners and professionals preparing for various data science roles by providing detailed explanations and notebooks for each concept.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
For similar tasks
oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.
oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.