AI tools for SoundWise.ai
Related Tools:
SoundWise.ai
SoundWise.ai is an AI tool that offers free unlimited audio & video transcription services. Users can easily convert audio and video files into accurate text directly in their browser. The tool supports various file formats such as WAV, MP3, FLAC, AAC, M4A, MP4, MOV, and MKV. SoundWise.ai is designed to provide a seamless transcription experience for individuals and businesses looking to transcribe their recordings efficiently.
Soundbite
Soundbite is a communication tool that combines video and audio messaging with sophisticated targeting and reports to streamline organizational communication. It offers a platform for creating engaging content, fostering meaningful dialogue, and collecting real-time engagement data to enhance communication strategies. Soundbite is designed to cut through information overload, increase productivity, and build human connections in the workplace.
Lid
Lid is an AI-powered voice journaling app that helps users form healthy habits, gather insights, and journal securely and privately. It uses advanced AI to analyze voice entries and provides a written summary, identifying key themes from the user's day. Lid also creates personalized soundbites, offering a mirror to the user's emotions and experiences. The app is designed to enhance mindfulness, provide a quick and easy way to journal on the go, and help in tracking mood and habits.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more
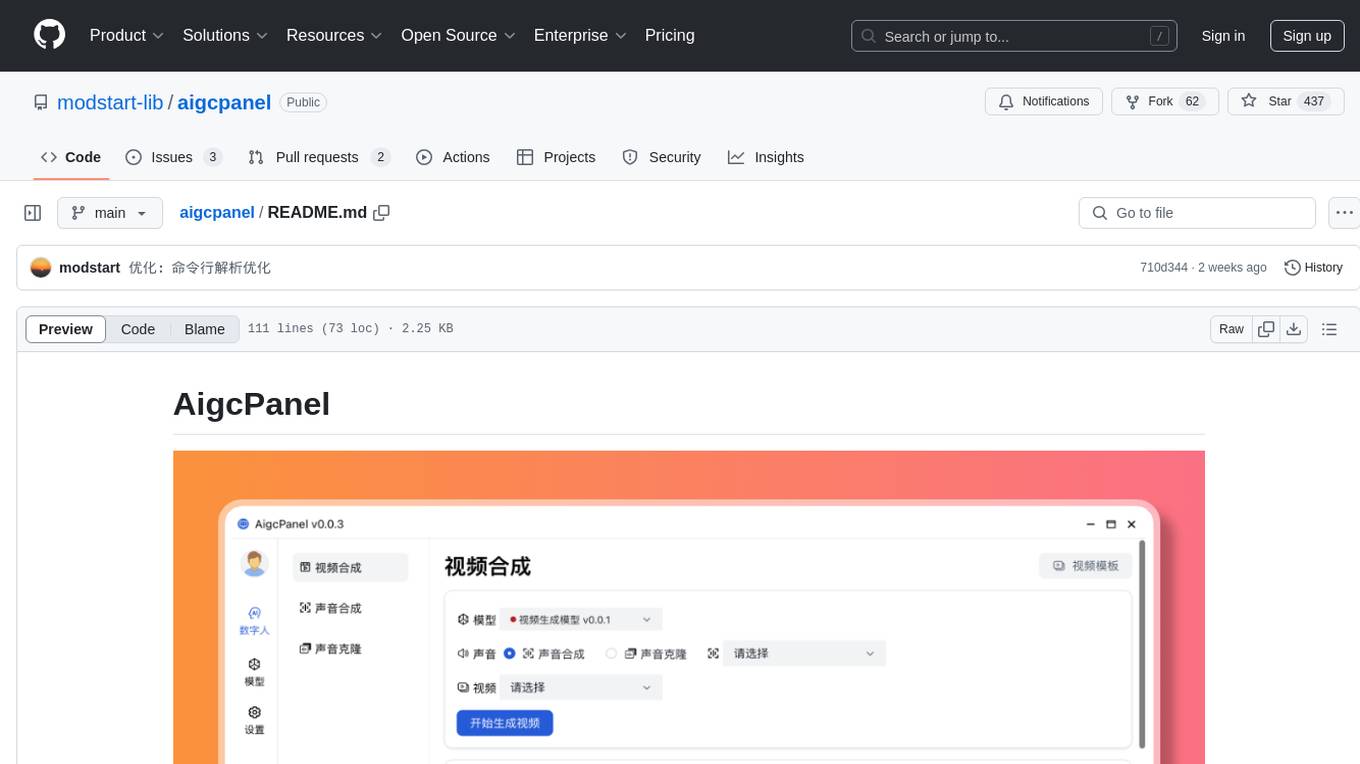
aigcpanel
AigcPanel is a simple and easy-to-use all-in-one AI digital human system that even beginners can use. It supports video synthesis, voice synthesis, voice cloning, simplifies local model management, and allows one-click import and use of AI models. It prohibits the use of this product for illegal activities and users must comply with the laws and regulations of the People's Republic of China.
EmotiVoice
EmotiVoice is a powerful and modern open-source text-to-speech engine that supports emotional synthesis, enabling users to create speech with a wide range of emotions such as happy, excited, sad, and angry. It offers over 2000 different voices in both English and Chinese. Users can access EmotiVoice through an easy-to-use web interface or a scripting interface for batch generation of results. The tool is continuously evolving with new features and updates, prioritizing community input and user feedback.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.
Fay
Fay is an open-source digital human framework that offers different versions for various purposes. The '带货完整版' is suitable for online and offline salespersons. The '助理完整版' serves as a human-machine interactive digital assistant that can also control devices upon command. The 'agent版' is designed to be an autonomous agent capable of making decisions and contacting its owner. The framework provides updates and improvements across its different versions, including features like emotion analysis integration, model optimizations, and compatibility enhancements. Users can access detailed documentation for each version through the provided links.
pianotrans
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.