Best AI tools for< Image Processing Engineer >
Infographic
20 - AI tool Sites

NumPy
NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and high-level mathematical functions to perform operations on these arrays. It is the fundamental package for scientific computing with Python and is used in a wide range of applications, including data science, machine learning, and image processing. NumPy is open source and distributed under a liberal BSD license, and is developed and maintained publicly on GitHub by a vibrant, responsive, and diverse community.
Ximilar Visual AI for Business
Ximilar Visual AI for Business is an AI tool that offers a comprehensive platform for image recognition and visual search solutions. It provides features such as image classification, regression, object detection, AI model combination, image annotation, and more. Users can easily build custom machine learning models without coding, access ready-to-use visual AI demos, and benefit from features like image upscaling, background removal, and color extraction. The platform caters to various industries including fashion, home decor, stock photos, collectibles, med & biotech, manufacturing, and real estate.
api4ai
api4ai is a cloud-native AI application that offers image processing APIs powered by artificial intelligence. It provides affordable and personalized solutions for businesses, empowering them with computer vision and machine learning capabilities. The application allows users to monitor visitor statistics, expand product identification apps, integrate background removal algorithms, estimate marketing campaign effectiveness, automate production processes, manage clothing stocktaking, enhance car dealership ads, ensure workplace safety, and extract information for enterprises, startups, and developers. With a wide range of ready-to-use APIs and customization options, api4ai simplifies the implementation of AI solutions across various industries.
Sightwise GmbH
Sightwise GmbH offers an end-to-end machine vision solution powered by synthetic data. Their modular software platform is designed for manufacturing companies to enhance visual quality assurance. By leveraging synthetic data, they create tailored datasets and applications for various inspection tasks, overcoming the limitations of traditional AI. The platform enables easy data management, dataset generation, application deployment, and continuous improvements, ultimately helping manufacturers achieve top-tier product quality.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.

Segment Anything by Meta AI
Segment Anything by Meta AI is an advanced AI model that specializes in image segmentation, allowing users to easily 'cut out' any object in an image with a single click. The model, named SAM, offers zero-shot generalization to unfamiliar objects and images without the need for additional training. SAM's promptable design enables a wide range of segmentation tasks through input prompts, making it a versatile tool for various applications.
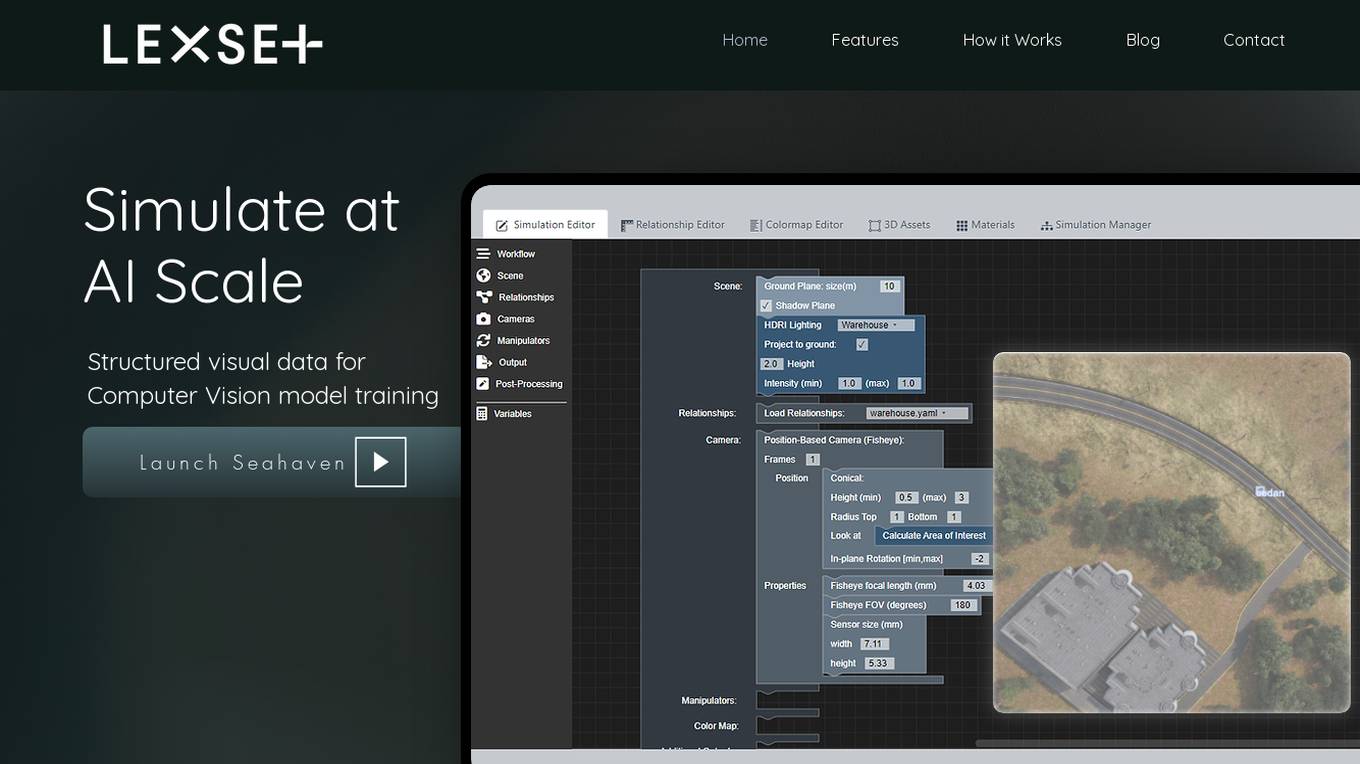
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.
Undressing AI
Undressing AI is a website that provides information about artificial intelligence (AI) and its potential impact on society. The site includes articles, videos, and other resources on topics such as the history of AI, the different types of AI, and the ethical implications of AI.

Deep Learning
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free. The deep learning textbook can now be ordered on Amazon. For up to date announcements, join our mailing list.
Innovatiana
Innovatiana is a data labeling outsourcing company that provides high-quality training data for AI models. They specialize in computer vision, data moderation, document processing, natural language processing, and data collection. Innovatiana is committed to ethical and sustainable practices, and they pay their data labelers fair wages and provide them with good working conditions. They also use a variety of quality control measures to ensure that their data is accurate and reliable.
Robovision
Robovision is a central platform to manage vision intelligence inside smart machines. Successfully introduce AI in dynamic environments without the need for AI experts.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.
OpenCV
OpenCV is the world's largest computer vision library. It's open source, contains over 2500 algorithms and is operated by the non-profit Open Source Vision Foundation.
OpenCV
OpenCV is a library of programming functions mainly aimed at real-time computer vision. Originally developed by Intel, it was later supported by Willow Garage and is now maintained by Itseez. OpenCV is cross-platform and free for use under the open-source BSD license.
Fyne AI
Fyne AI is an AI application that applies AI research in computer vision, generative AI, and machine learning to develop innovative products. The focus of the application is on automating analysis, generating insights from image and video datasets, enhancing creativity and productivity, and building prediction models. Users can subscribe to the Fyne AI newsletter to stay updated on product news and updates.
5 - Open Source Tools
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
automatic
Automatic is an Image Diffusion implementation with advanced features. It supports multiple diffusion models, built-in control for text, image, batch, and video processing, and is compatible with various platforms and backends. The tool offers optimized processing with the latest torch developments, built-in support for torch.compile, and multiple compile backends. It also features platform-specific autodetection, queue management, enterprise-level logging, and a built-in installer with automatic updates and dependency management. Automatic is mobile compatible and provides a main interface using StandardUI and ModernUI.
sdnext
SD.Next is an Image Diffusion implementation with advanced features. It offers multiple UI options, diffusion models, and built-in controls for text, image, batch, and video processing. The tool is multiplatform, supporting Windows, Linux, MacOS, nVidia, AMD, IntelArc/IPEX, DirectML, OpenVINO, ONNX+Olive, and ZLUDA. It provides optimized processing with the latest torch developments, including model compile, quantize, and compress functionalities. SD.Next also features Interrogate/Captioning with various models, queue management, automatic updates, and mobile compatibility.
20 - OpenAI Gpts

Signal Processing Advisor
Provides expert guidance on signal processing in engineering projects.

Reverse Engineer Icons - ThePromptfather
Specialist in reverse engineering icons to your specifications. Upload an image of the icons you want - ThePromptfather

Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
How's it made?
I find videos on how items are made from your photos and describe the process.

KingLand ∞ L'Élite Numérique IA
Plateforme innovante en IA pour passionnés de technologie, offrant conseils et articles via 100 IA collaboratives.
AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles


🏢 🏙 City of GP-Topia 🏙 🏭 👨🔧🧰
🕴a Pocket City of Ai Buildings for Every Purpose you might have.
The AI Pragmatist
Grumpily explores AI's potential and limits, concluding "AI Ain't gonna fix it."
Charlie Dumas : Directrice IA & Innovation
Directrice de l'innovation chez KingLand, experte en IA, gestion de projets et R&D.

GPT Finder
This tool is designed to locate the ideal GPT model tailored to your specific requirements. Simply articulate your needs, and it will diligently work to identify the perfect GPT solution for you.