Best AI tools for< Computational Linguist >
Infographic
20 - AI tool Sites

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.

Bay Area AI
Bay Area AI is a technical AI meetup group based in San Francisco, CA, consisting of startup engineers, research scientists, computational linguists, mathematicians, and philosophers. The group focuses on understanding the meaning of text, reasoning, and human intent through technology to build new businesses and enhance the human experience in the modern connected world. They work on building systems with Machine Learning on top of Data Pipelines, exploring open-source solutions, and modeling human behavior in industry for practical results.

Wolfram|Alpha
Wolfram|Alpha is a computational knowledge engine that answers questions using data, algorithms, and artificial intelligence. It can perform calculations, generate graphs, and provide information on a wide range of topics, including mathematics, science, history, and culture. Wolfram|Alpha is used by students, researchers, and professionals around the world to solve problems, learn new things, and make informed decisions.
Wolfram
Wolfram is a comprehensive platform that unifies algorithms, data, notebooks, linguistics, and deployment to provide a powerful computation platform. It offers a range of products and services for various industries, including education, engineering, science, and technology. Wolfram is known for its revolutionary knowledge-based programming language, Wolfram Language, and its flagship product Wolfram|Alpha, a computational knowledge engine. The platform also includes Wolfram Cloud for cloud-based services, Wolfram Engine for software implementation, and Wolfram Data Framework for real-world data analysis.

Artificial Intelligence: Foundations of Computational Agents
Artificial Intelligence: Foundations of Computational Agents, 3rd edition by David L. Poole and Alan K. Mackworth, Cambridge University Press 2023, is a book about the science of artificial intelligence (AI). It presents artificial intelligence as the study of the design of intelligent computational agents. The book is structured as a textbook, but it is accessible to a wide audience of professionals and researchers. In the last decades we have witnessed the emergence of artificial intelligence as a serious science and engineering discipline. This book provides an accessible synthesis of the field aimed at undergraduate and graduate students. It provides a coherent vision of the foundations of the field as it is today. It aims to provide that synthesis as an integrated science, in terms of a multi-dimensional design space that has been partially explored. As with any science worth its salt, artificial intelligence has a coherent, formal theory and a rambunctious experimental wing. The book balances theory and experiment, showing how to link them intimately together. It develops the science of AI together with its engineering applications.
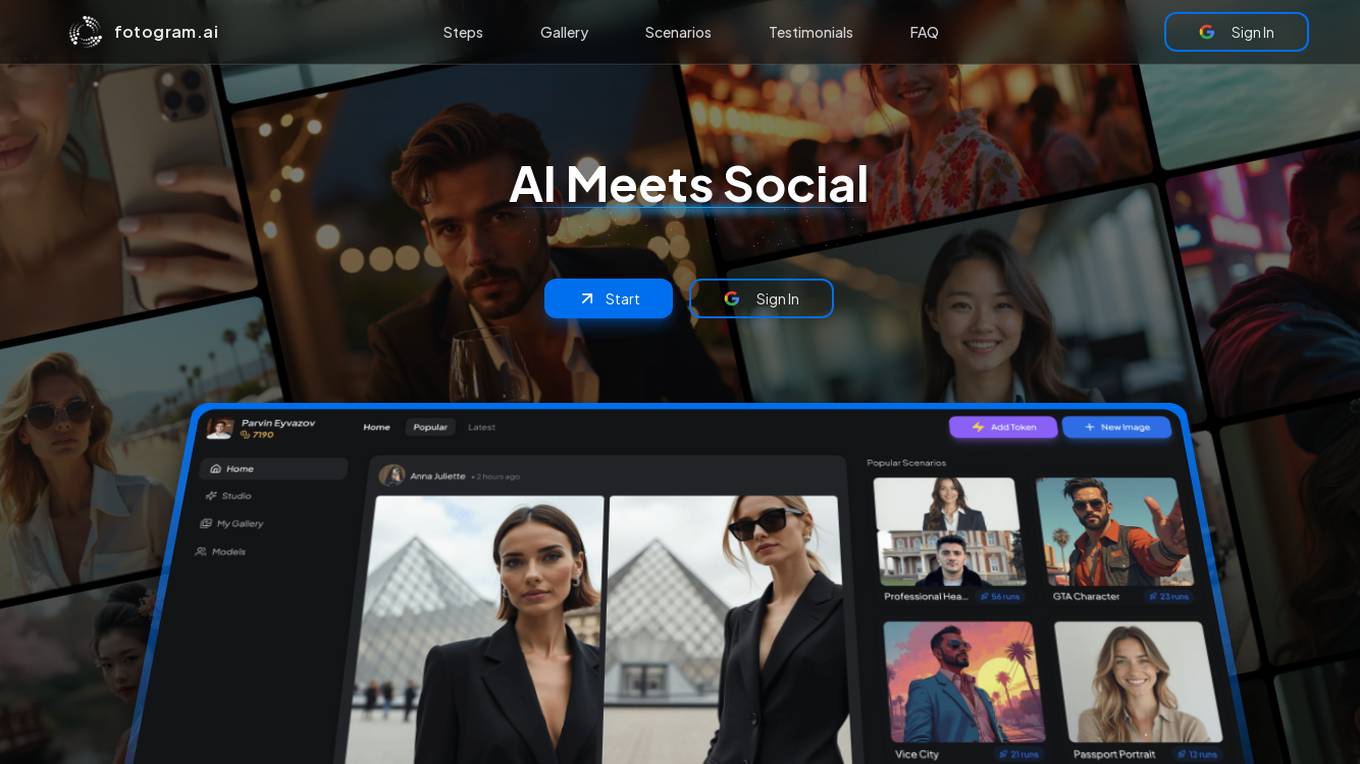
Fotogram.ai
Fotogram.ai is an AI-powered image editing tool that offers a wide range of features to enhance and transform your photos. With Fotogram.ai, users can easily apply filters, adjust colors, remove backgrounds, add effects, and retouch images with just a few clicks. The tool uses advanced AI algorithms to provide professional-level editing capabilities to users of all skill levels. Whether you are a photographer looking to streamline your workflow or a social media enthusiast wanting to create stunning visuals, Fotogram.ai has you covered.
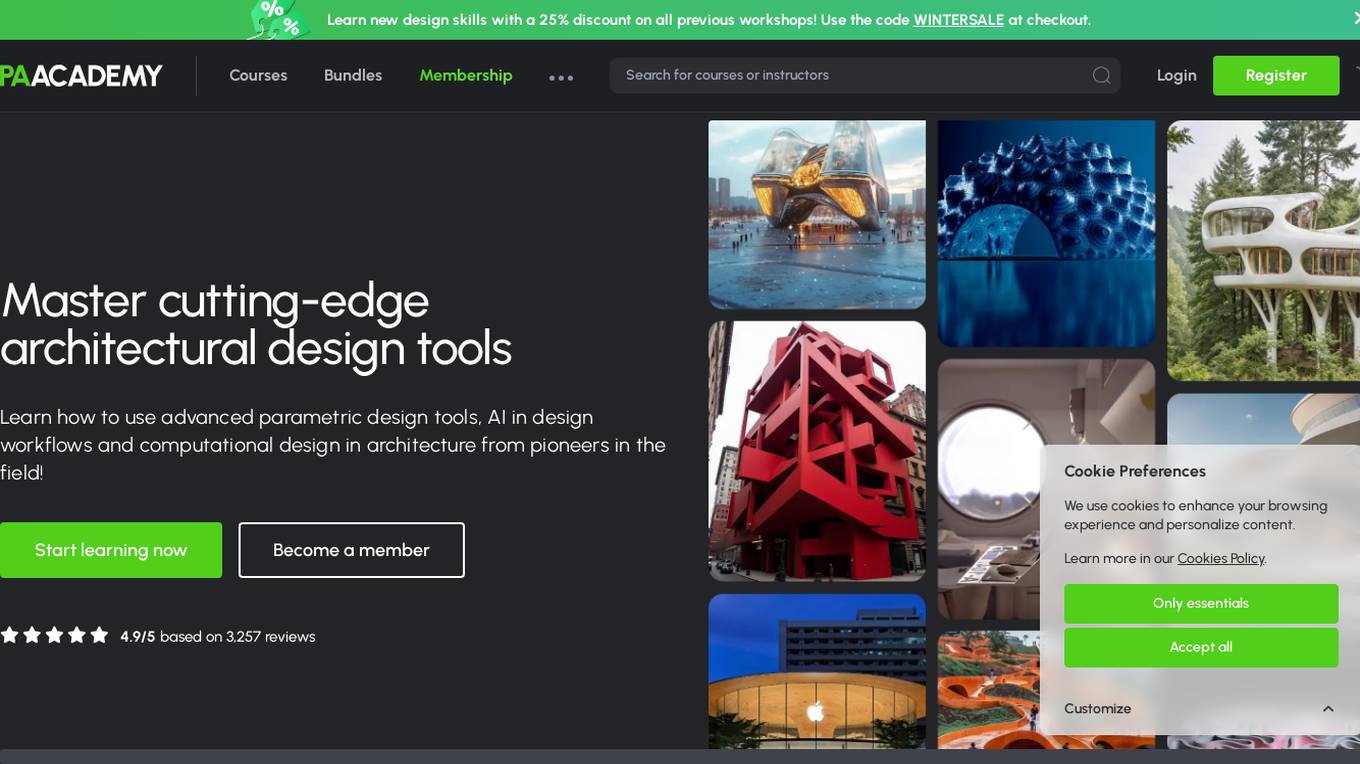
PAACADEMY
PAACADEMY is an educational platform focused on architecture and design, offering workshops and courses on advanced design tools, computational design, and AI integration in architecture. The platform provides insights, tutorials, and live events to inspire and educate aspiring designers. PAACADEMY features renowned instructors and covers topics such as parametric design, 3D printing, and AI-driven architectural practices.
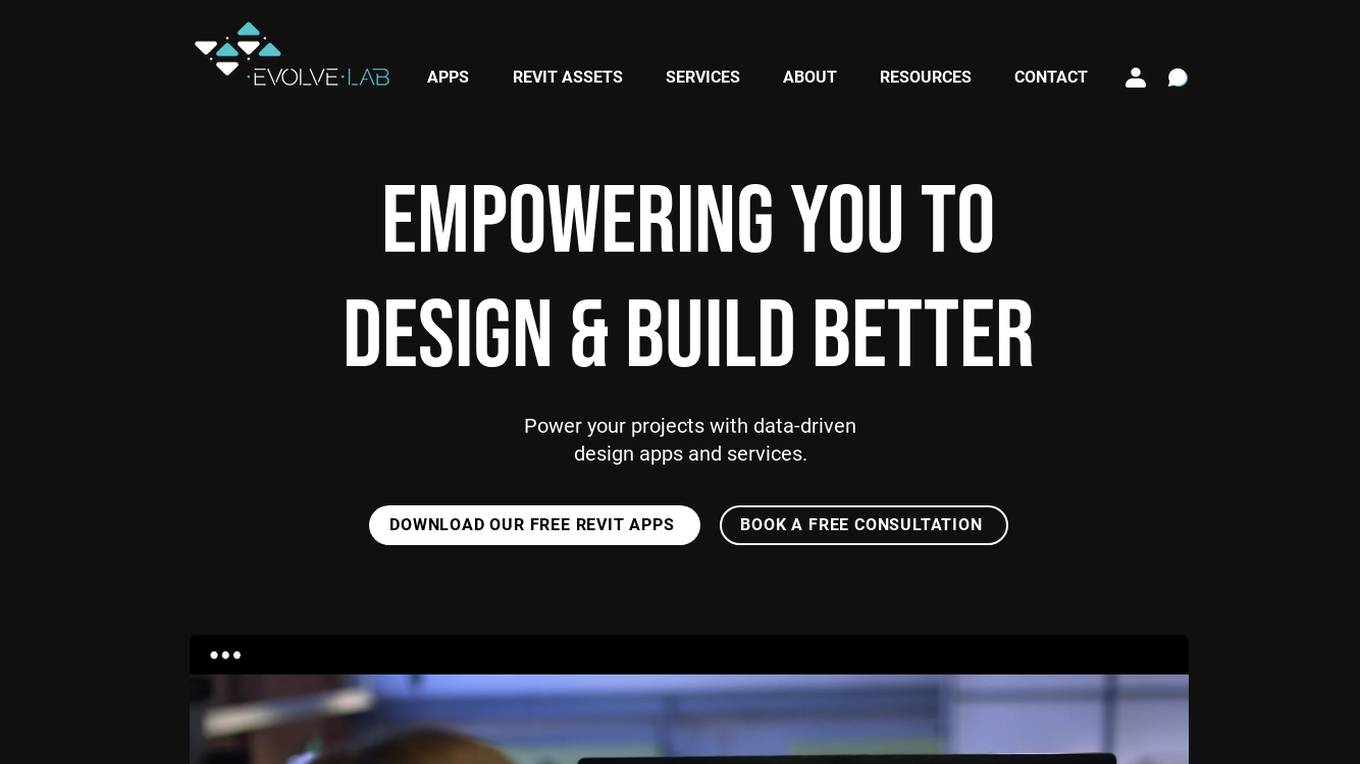
EvolveLab
EvolveLab is a digital solutions provider specializing in BIM management and app development for the AEC (Architecture, Engineering, and Construction) industry. They offer a range of powerful apps and services designed to empower architects, engineers, and contractors to streamline their workflows and bring their ideas to life more efficiently. With a focus on data-driven design and AI technology, EvolveLab's innovative tools help users enhance productivity and turn concepts into reality.
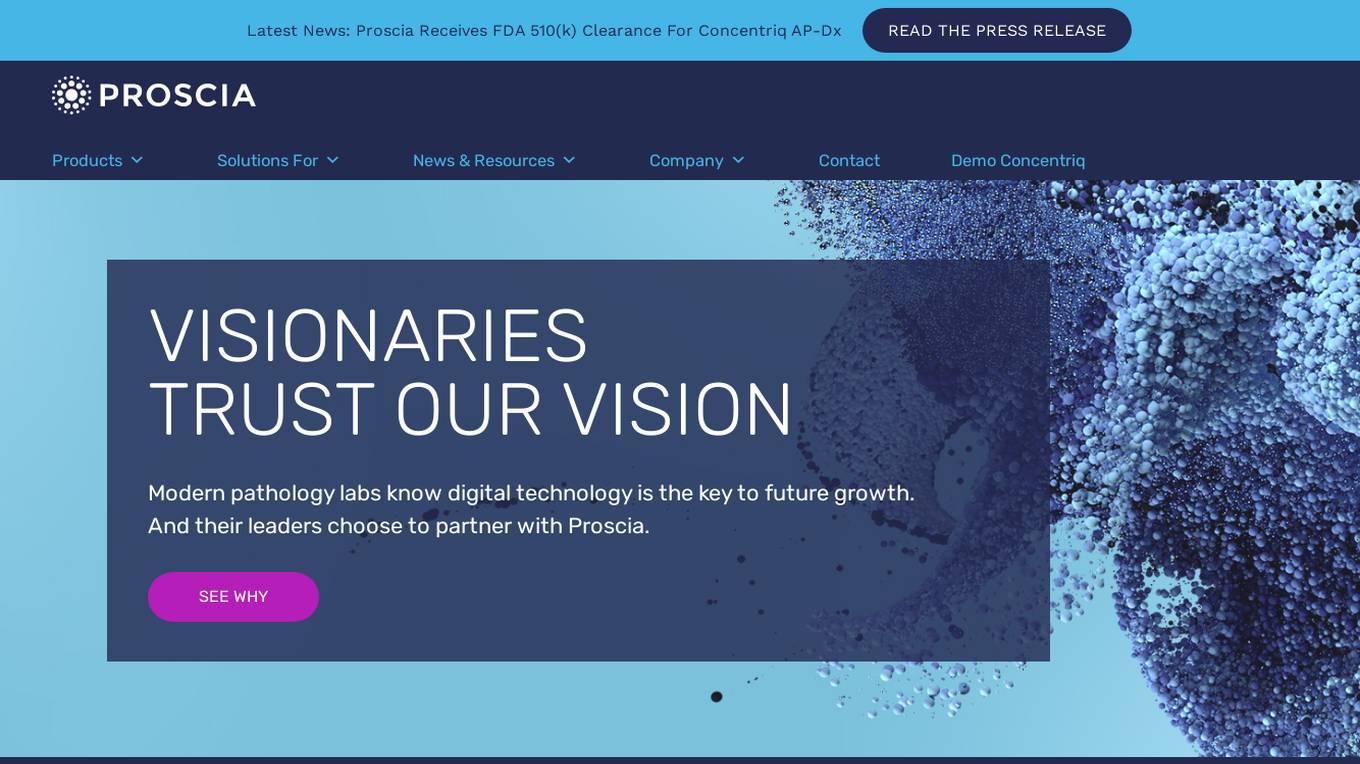
Proscia
Proscia is a leading provider of digital pathology solutions for the modern laboratory. Its flagship product, Concentriq, is an enterprise pathology platform that enables anatomic pathology laboratories to achieve 100% digitization and deliver faster, more precise results. Proscia also offers a range of AI applications that can be used to automate tasks, improve diagnostic accuracy, and accelerate research. The company's mission is to perfect cancer diagnosis with intelligent software that changes the way the world practices pathology.
AIOZ Network
AIOZ Network is an AI-powered platform that focuses on Web3, AI, storage, and streaming services. It offers decentralized AI computation, fast and reliable storage solutions, and seamless video streaming for dApps within the network. AIOZ aims to empower a fast, secure, and decentralized future by providing a one-click integration of dApps on the AIOZ blockchain, supporting popular smart contract languages, and utilizing spare computing resources from a global community of nodes.
Live Portrait Ai Generator
Live Portrait Ai Generator is an AI application that transforms static portrait images into lifelike videos using advanced animation technology. Users can effortlessly animate their portraits, fine-tune animations, unleash artistic styles, and make memories move with text, music, and other elements. The tool offers a seamless stitching technology and retargeting capabilities to achieve perfect results. Live Portrait Ai enhances generation quality and generalization ability through a mixed image-video training strategy and network architecture upgrades.
Altera
Altera is an applied research company focused on building digital humans - machines with fundamental human qualities. Led by Dr. Robert Yang, the team comprises computational neuroscientists, CS and Physics experts from prestigious institutions. Their mission is to create digital human beings that can live, care, and grow with us. The company's early research prototypes began in games, offering a glimpse into the potential of these digital humans.
CCDS
CCDS (Center for Computational & Data Sciences) is a research center at Independent University Bangladesh dedicated to artificial intelligence, data sciences, and computational science. The center has various wings focusing on AI, computational biology, physics, data science, human-computer interaction, and industry partnerships. CCDS explores the use of computation to understand nature and society, uncover hidden stories in data, and tackle complex challenges. The center collaborates with institutions like CERN and the Dunlap Institute for Astronomy and Astrophysics.

XtalPi
XtalPi is a world-leading technology company driven by artificial intelligence (AI) and robotics to innovate in the fields of life sciences and new materials. Founded in 2015 at the Massachusetts Institute of Technology (MIT), the company is committed to realizing digital and intelligent innovation in the fields of life sciences and new materials. Based on cutting-edge technologies and capabilities such as quantum physics, artificial intelligence, cloud computing, and large-scale experimental robot clusters, the company provides innovative technologies, services, and products for global industries such as biomedicine, chemicals, new energy, and new materials.
Iambic Therapeutics
Iambic Therapeutics is a cutting-edge AI-driven drug discovery platform that tackles the most challenging design problems in drug discovery, addressing unmet patient need. Its physics-based AI algorithms drive a high-throughput experimental platform, converting new molecular designs to new biological insights each week. Iambic's platform optimizes target product profiles, exploring multiple profiles in parallel to ensure that molecules are designed to solve the right problems in disease biology. It also optimizes drug candidates, deeply exploring chemical space to reveal novel mechanisms of action and deliver diverse high-quality leads.

Owkin
Owkin is a full-stack AI biotech company that integrates the best of human and artificial intelligence to deliver better drugs and diagnostics at scale. By understanding complex biology through AI, Owkin identifies new treatments, de-risks and accelerates clinical trials, and builds diagnostic tools to reduce time to impact for patients.
Cradle
Cradle is a protein engineering platform that uses machine learning to design improved protein sequences. It allows users to import assay data, generate new sequences, test them in the lab, and import the results to improve the model. Cradle can be used to optimize multiple properties of a protein simultaneously, and it has been used by leading biotech teams to accelerate new and ongoing projects.
Variational AI
Variational AI is a company that uses generative AI to discover novel drug-like small molecules with optimized properties for defined targets. Their platform, Enki™, is the first commercially accessible foundation model for small molecules. It is designed to make generating novel molecule structures easy, with no data required. Users simply define their target product profile (TPP) and Enki does the rest. Enki is an ensemble of generative algorithms trained on decades worth of experimental data with proven results. The company was founded in September 2019 and is based in Vancouver, BC, Canada.
Cerebras
Cerebras is an AI tool that offers products and services related to AI supercomputers, cloud system processors, and applications for various industries. It provides high-performance computing solutions, including large language models, and caters to sectors such as health, energy, government, scientific computing, and financial services. Cerebras specializes in AI model services, offering state-of-the-art models and training services for tasks like multi-lingual chatbots and DNA sequence prediction. The platform also features the Cerebras Model Zoo, an open-source repository of AI models for developers and researchers.
Genesis Therapeutics
Genesis Therapeutics is an AI platform that leverages cutting-edge technology to revolutionize drug discovery and development processes. The platform integrates advanced algorithms and machine learning models to accelerate the identification of novel drug candidates and optimize their properties. By combining computational simulations with experimental data, Genesis Therapeutics offers a comprehensive solution to streamline the drug development pipeline and bring innovative therapies to market faster. The platform is designed to empower researchers and pharmaceutical companies with powerful tools for predicting drug-target interactions, optimizing molecular structures, and prioritizing lead compounds for further investigation.
10 - Open Source Tools

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
multimodal_cognitive_ai
The multimodal cognitive AI repository focuses on research work related to multimodal cognitive artificial intelligence. It explores the integration of multiple modes of data such as text, images, and audio to enhance AI systems' cognitive capabilities. The repository likely contains code, datasets, and research papers related to multimodal AI applications, including natural language processing, computer vision, and audio processing. Researchers and developers interested in advancing AI systems' understanding of multimodal data can find valuable resources and insights in this repository.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.
16 - OpenAI Gpts


StephenBot
A digital homage to honor Stephen Wolfram's impact on computational science and technology and to celebrate his dedication to public education, powered by Stephen Wolfram's wealth of public presentations, writings, and live streams.
Formula Generator
Expert in generating and explaining mathematical, chemical, and computational formulas.
ChatPNP
Blends academic insights & accessible explanations on P vs NP, drawing from Lance Fortnow's works.