
langport
Langport is a language model inference service
Stars: 91
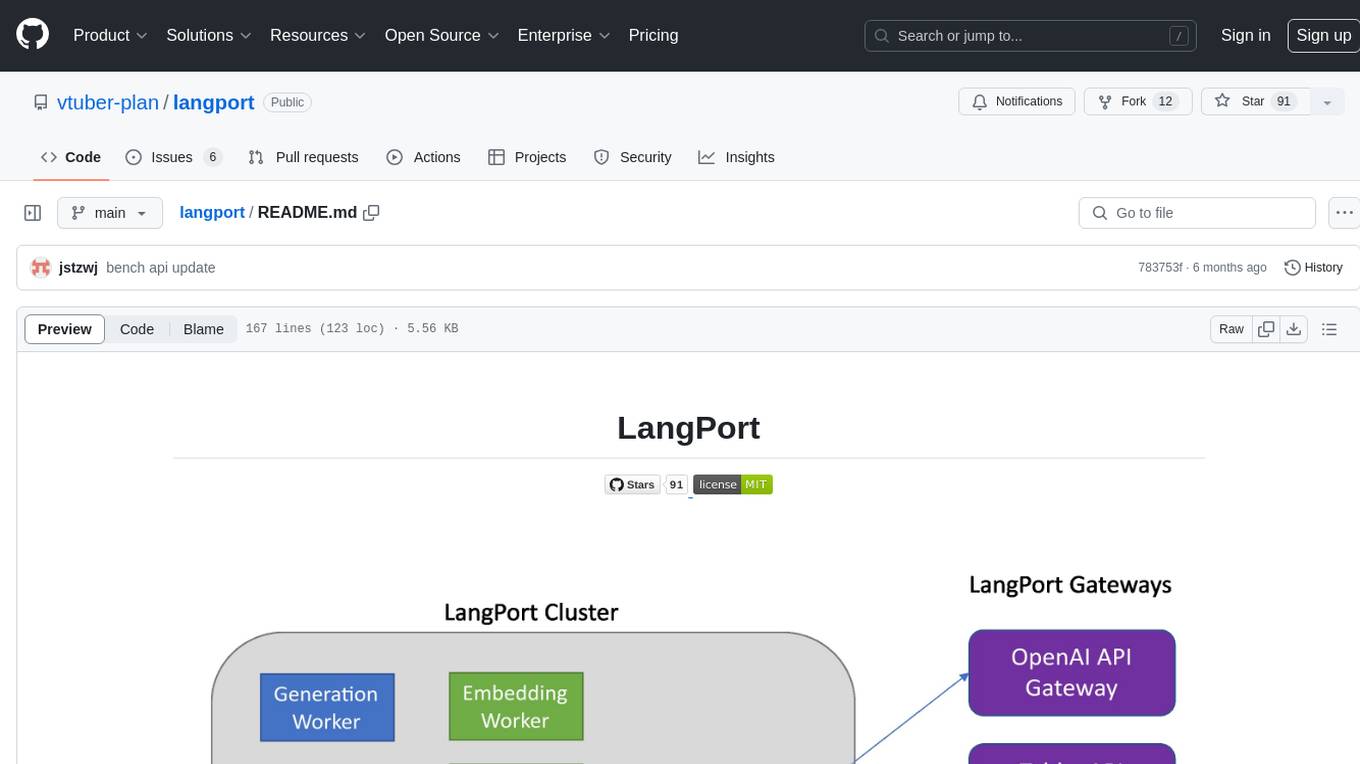
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.
README:



LangPort is a open-source large language model serving platform. Our goal is to build a super fast LLM inference service.
This project is inspired by lmsys/fastchat, we hope that the serving platform is lightweight and fast, but fastchat includes other features such as training and evaluation make it complicated.
The core features include:
- Huggingface transformers support.
- ggml (llama.cpp) support.
- A distributed serving system for state-of-the-art models.
- Streaming generation support with various decoding strategies.
- Batch inference for higher throughput.
- Support for encoder-only, decoder-only and encoder-decoder models.
- OpenAI-compatible RESTful APIs.
- FauxPilot-compatible RESTful APIs.
- HuggingFace-compatible RESTful APIs.
- Tabby-compatible RESTful APIs.
- LLaMa, LLaMa2, GLM, Bloom, OPT, GPT2, GPT Neo, GPT Big Code and so on.
- NingYu, LLaMa, LLaMa2, Vicuna, ChatGLM, ChatGLM2, Falcon, Starcoder, WizardLM, InternLM, OpenBuddy, FireFly, CodeGen, Phoenix, RWKV, StableLM and so on.
- [2024/01/13] Introduce the
ChatProto. - [2023/08/04] Dynamic batch inference.
- [2023/07/16] Support int4 quantization.
- [2023/07/13] Support generation logprobs parameter.
- [2023/06/18] Add ggml (llama.cpp gpt.cpp starcoder.cpp etc.) worker support.
- [2023/06/09] Add LLama.cpp worker support.
- [2023/06/01] Add HuggingFace Bert embedding worker support.
- [2023/06/01] Add HuggingFace text generation API support.
- [2023/06/01] Add tabby API support.
- [2023/05/23] Add chat throughput test script.
- [2023/05/22] New distributed architecture.
- [2023/05/14] Batch inference supported.
- [2023/05/10] Langport project started.
pip install langportor:
pip install git+https://github.com/vtuber-plan/langport.git If you need ggml generation worker, use this command:
pip install langport[ggml]If you want to use GPU:
CT_CUBLAS=1 pip install langport[ggml]- Clone this repository
git clone https://github.com/vtuber-plan/langport.git
cd langport- Install the Package
pip install --upgrade pip
pip install -e .It is simple to start a local chat API service:
First, start a worker process in the terminal:
python -m langport.service.server.generation_worker --port 21001 --model-path <your model path>Then, start a API service in another terminal:
python -m langport.service.gateway.openai_apiNow, you can use the inference API by openai protocol.
It is simple to start a single node chat API service:
python -m langport.service.server.generation_worker --port 21001 --model-path <your model path>
python -m langport.service.gateway.openai_apiIf you need a single node embeddings API server:
python -m langport.service.server.embedding_worker --port 21002 --model-path bert-base-chinese --gpus 0 --num-gpus 1
python -m langport.service.gateway.openai_api --port 8000 --controller-address http://localhost:21002If you need the embeddings API or other features, you can deploy a distributed inference cluster:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --model-path <your model path> --neighbors http://localhost:21001
python -m langport.service.server.embedding_worker --model-path <your model path> --neighbors http://localhost:21001
python -m langport.service.gateway.openai_api --controller-address http://localhost:21001In practice, the gateway can connect to any node to distribute inference tasks:
python -m langport.service.server.dummy_worker --port 21001
python -m langport.service.server.generation_worker --port 21002 --model-path <your model path> --neighbors http://localhost:21001
python -m langport.service.server.generation_worker --port 21003 --model-path <your model path> --neighbors http://localhost:21001 http://localhost:21002
python -m langport.service.server.generation_worker --port 21004 --model-path <your model path> --neighbors http://localhost:21001 http://localhost:21003
python -m langport.service.server.generation_worker --port 21005 --model-path <your model path> --neighbors http://localhost:21001 http://localhost:21004
python -m langport.service.gateway.openai_api --controller-address http://localhost:21003 # 21003 is OK!
python -m langport.service.gateway.openai_api --controller-address http://localhost:21002 # Any worker is also OK!Run text generation with multi GPUs:
python -m langport.service.server.generation_worker --port 21001 --model-path <your model path> --gpus 0,1 --num-gpus 2
python -m langport.service.gateway.openai_apiRun text generation with ggml worker:
python -m langport.service.server.ggml_generation_worker --port 21001 --model-path <your model path> --gpu-layers <num layer to gpu (resize this for your VRAM)>Run OpenAI forward server:
python -m langport.service.server.chatgpt_generation_worker --port 21001 --api-url <url> --api-key <key>langport is released under the Apache Software License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langport
Similar Open Source Tools
langport
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
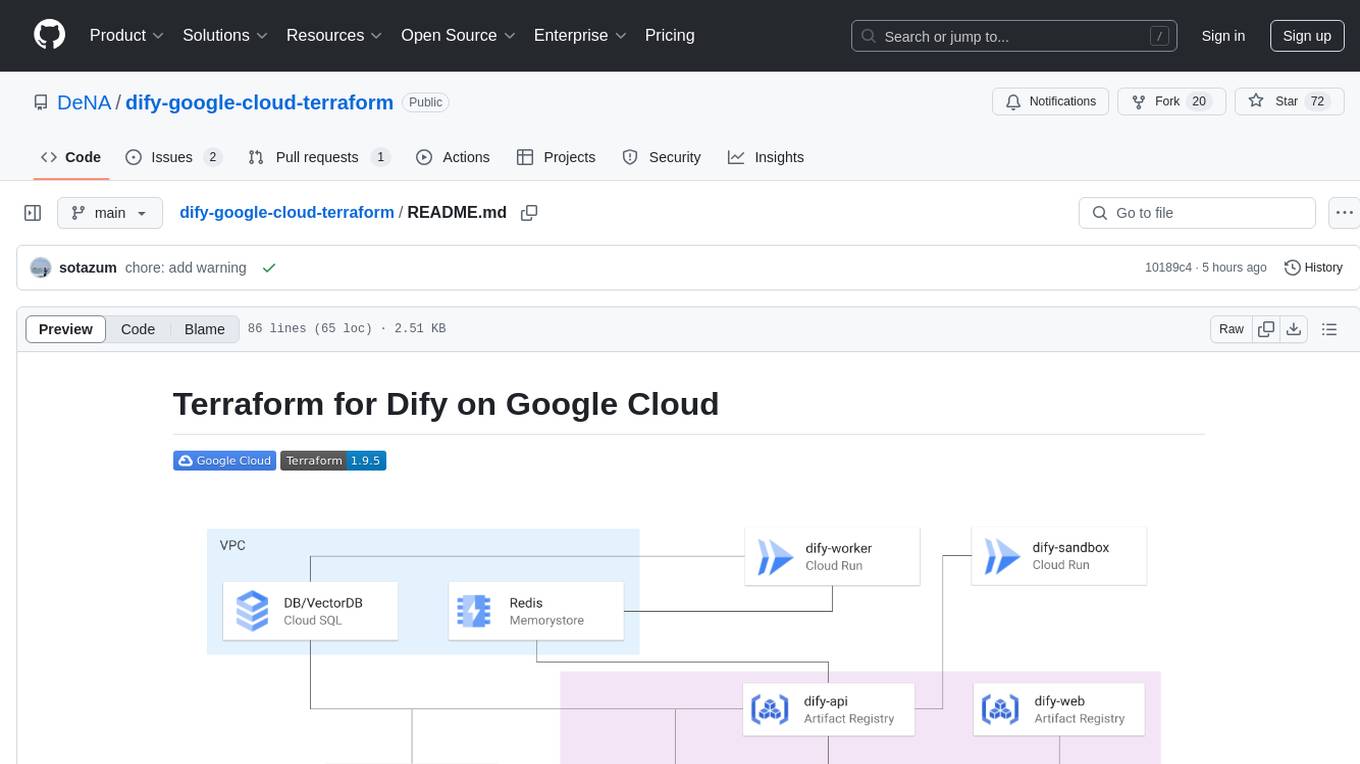
dify-google-cloud-terraform
This repository provides Terraform configurations to automatically set up Google Cloud resources and deploy Dify in a highly available configuration. It includes features such as serverless hosting, auto-scaling, and data persistence. Users need a Google Cloud account, Terraform, and gcloud CLI installed to use this tool. The configuration involves setting environment-specific values and creating a GCS bucket for managing Terraform state. The tool allows users to initialize Terraform, create Artifact Registry repository, build and push container images, plan and apply Terraform changes, and cleanup resources when needed.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
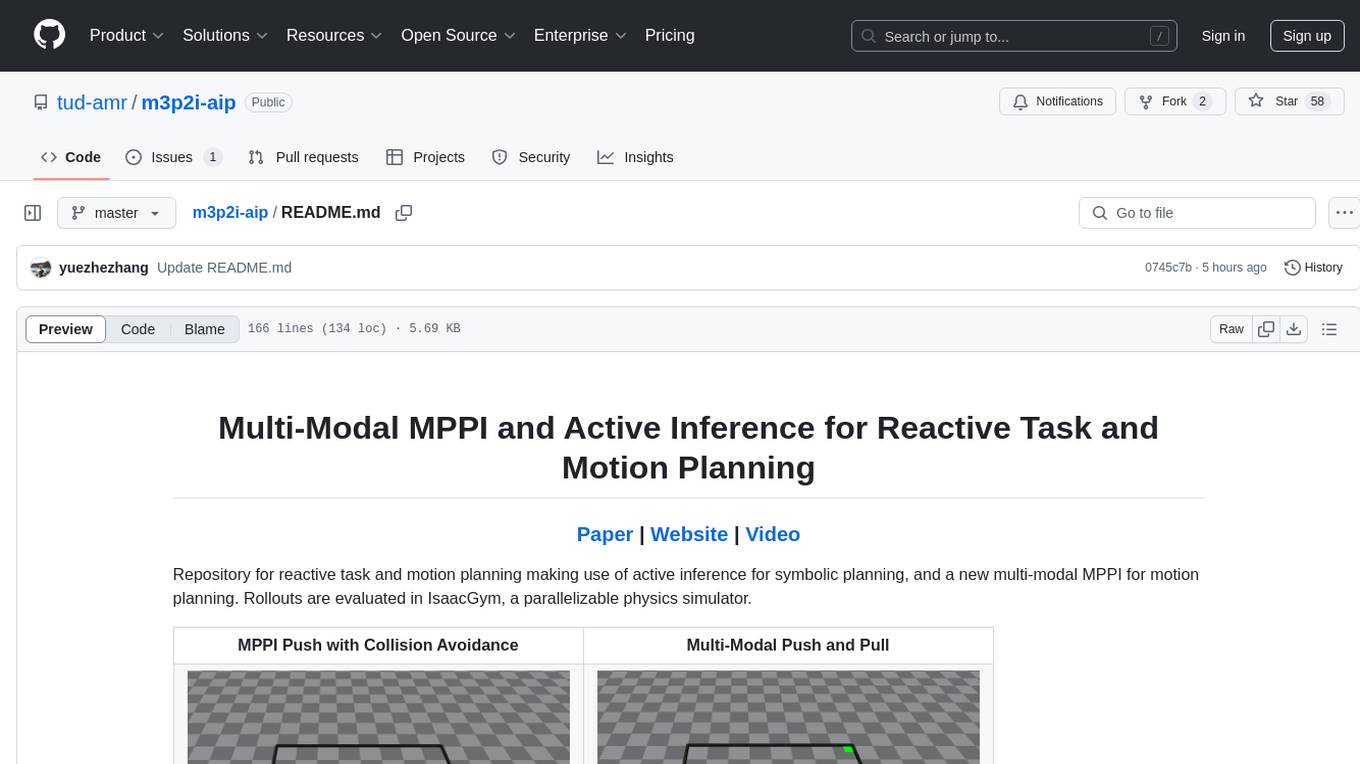
m3p2i-aip
Repository for reactive task and motion planning using active inference for symbolic planning and multi-modal MPPI for motion planning. Rollouts are evaluated in IsaacGym, a parallelizable physics simulator. The tool provides functionalities for push, pull, pick, and multi-modal push-pull tasks with collision avoidance.
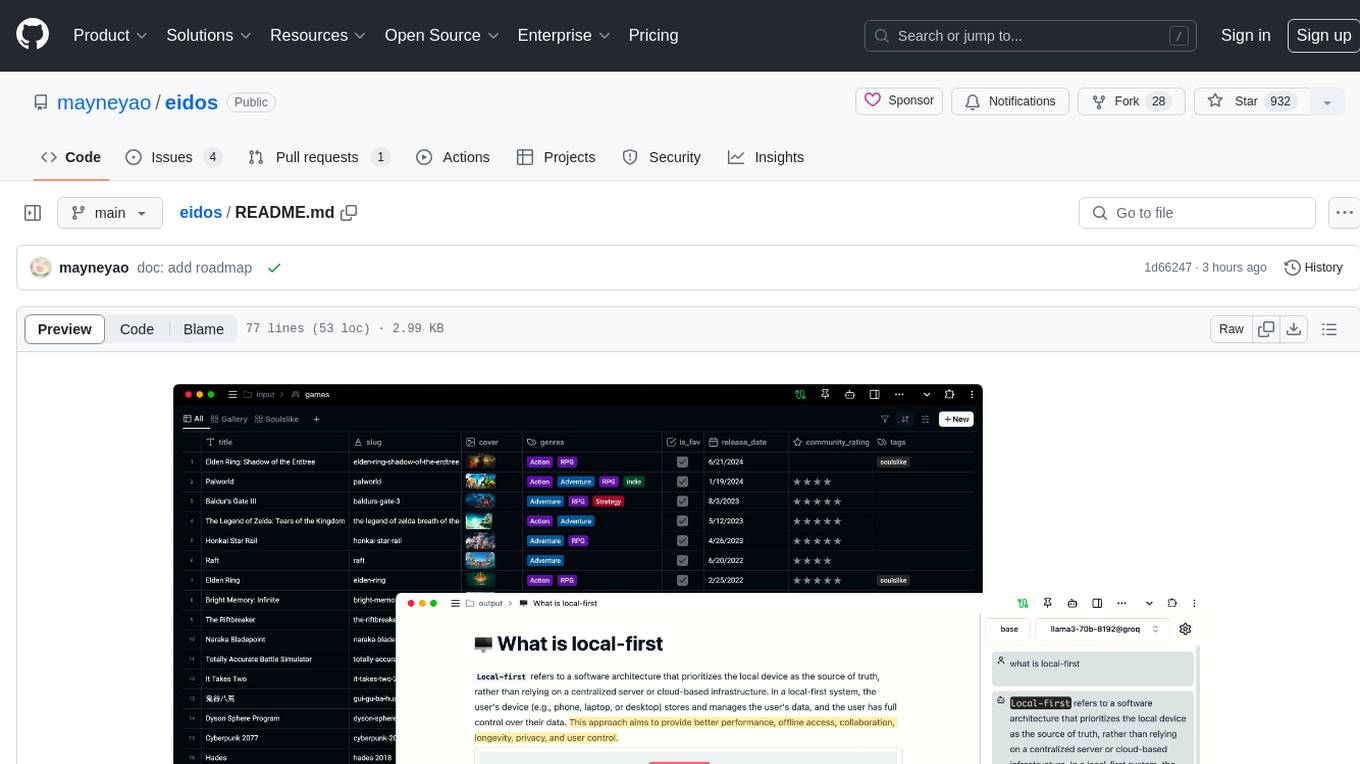
eidos
Eidos is an extensible framework for managing personal data in one place. It runs inside the browser as a PWA with offline support. It integrates AI features for translation, summarization, and data interaction. Users can customize Eidos with Prompt extension, JavaScript for Formula functions, TypeScript/JavaScript for data processing logic, and build apps using any framework. Eidos is developer-friendly with API & SDK, and uses SQLite standardization for data tables.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.
tangent
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.
gpt-engineer
GPT-Engineer is a tool that allows you to specify a software in natural language, sit back and watch as an AI writes and executes the code, and ask the AI to implement improvements.
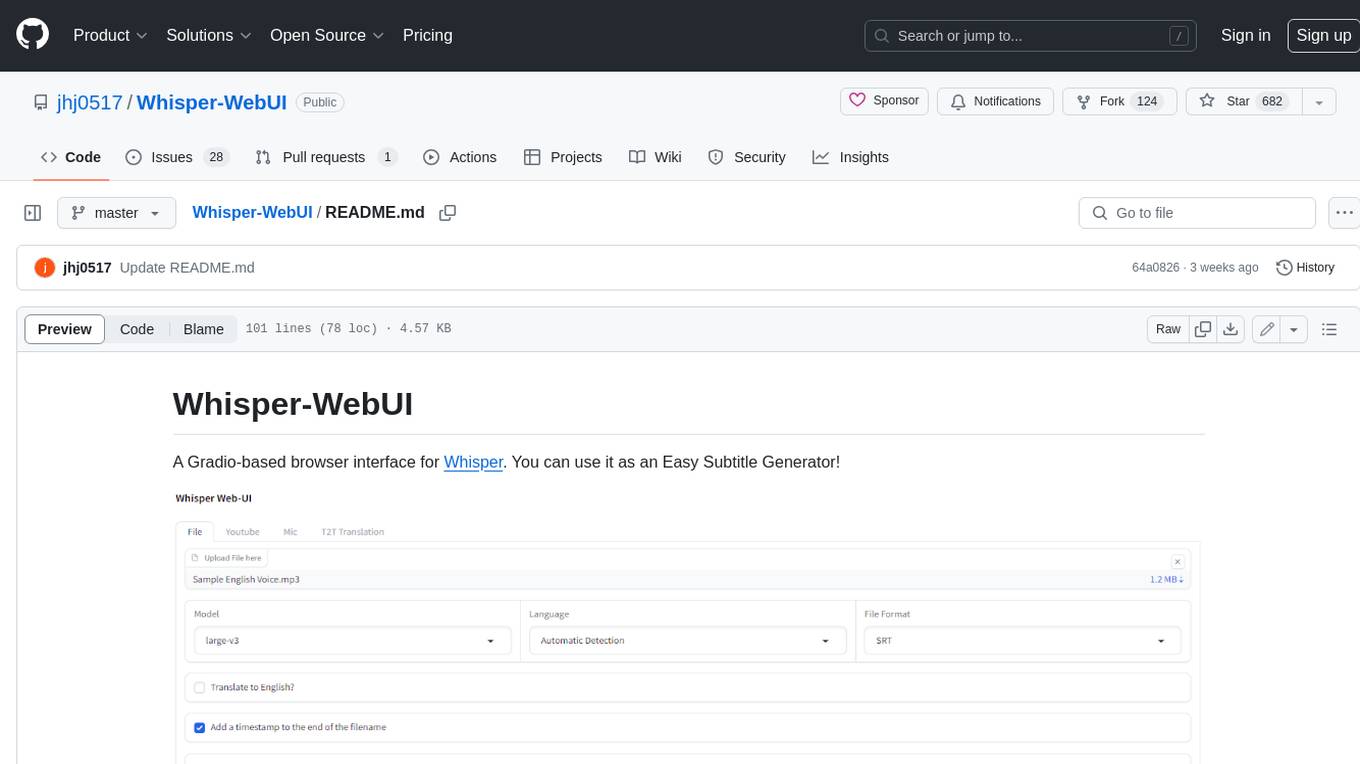
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
gemini-next-chat
Gemini Next Chat is an open-source, extensible high-performance Gemini chatbot framework that supports one-click free deployment of private Gemini web applications. It provides a simple interface with image recognition and voice conversation, supports multi-modal models, talk mode, visual recognition, assistant market, support plugins, conversation list, full Markdown support, privacy and security, PWA support, well-designed UI, fast loading speed, static deployment, and multi-language support.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
For similar tasks
langport
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.