
dstack
dstack is a lightweight, open-source alternative to Kubernetes & Slurm, simplifying AI container orchestration with multi-cloud & on-prem support. It natively supports NVIDIA, AMD, TPU, and Intel accelerators.
Stars: 1745

Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.
README:



dstack is a streamlined alternative to Kubernetes and Slurm, specifically designed for AI. It simplifies container orchestration
for AI workloads both in the cloud and on-prem, speeding up the development, training, and deployment of AI models.
dstack is easy to use with any cloud provider as well as on-prem servers.
dstack supports NVIDIA, AMD, Google TPU, and Intel Gaudi accelerators out of the box.
- [2025/02] dstack 0.18.41: GPU blocks, Proxy jump, inactivity duration, and more
- [2025/01] dstack 0.18.38: Intel Gaudi
- [2025/01] dstack 0.18.35: Vultr
- [2024/12] dstack 0.18.30: AWS Capacity Reservations and Capacity Blocks
- [2024/10] dstack 0.18.21: Instance volumes
- [2024/10] dstack 0.18.18: Hardware metrics monitoring
Before using
dstackthrough CLI or API, set up adstackserver. If you already have a runningdstackserver, you only need to set up the CLI.
To use dstack with cloud providers, configure backends.
For using dstack with on-prem servers, create SSH fleets instead.
Once the backends are configured, proceed to start the server:
$ pip install "dstack[all]" -U
$ dstack server
Applying ~/.dstack/server/config.yml...
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"
The server is running at http://127.0.0.1:3000/For more details on server configuration options, see the server deployment guide.
To point the CLI to the dstack server, configure it
with the server address, user token, and project name:
$ pip install dstack
$ dstack config --url http://127.0.0.1:3000 \
--project main \
--token bbae0f28-d3dd-4820-bf61-8f4bb40815da
Configuration is updated at ~/.dstack/config.ymldstack supports the following configurations:
- Dev environments — for interactive development using a desktop IDE
- Tasks — for scheduling jobs (incl. distributed jobs) or running web apps
- Services — for deployment of models and web apps (with auto-scaling and authorization)
- Fleets — for managing cloud and on-prem clusters
- Volumes — for managing persisted volumes
- Gateways — for configuring the ingress traffic and public endpoints
Configuration can be defined as YAML files within your repo.
Apply the configuration either via the dstack apply CLI command or through a programmatic API.
dstack automatically manages provisioning, job queuing, auto-scaling, networking, volumes, run failures,
out-of-capacity errors, port-forwarding, and more — across clouds and on-prem clusters.
For additional information and examples, see the following links:
You're very welcome to contribute to dstack.
Learn more about how to contribute to the project at CONTRIBUTING.md.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dstack
Similar Open Source Tools
dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
skynet
Skynet is an API server for AI services that wraps several apps and models. It consists of specialized modules that can be enabled or disabled as needed. Users can utilize Skynet for tasks such as summaries and action items with vllm or Ollama, live transcriptions with Faster Whisper via websockets, and RAG Assistant. The tool requires Poetry and Redis for operation. Skynet provides a quickstart guide for both Summaries/Assistant and Live Transcriptions, along with instructions for testing docker changes and running demos. Detailed documentation on configuration, running, building, and monitoring Skynet is available in the docs. Developers can contribute to Skynet by installing the pre-commit hook for linting. Skynet is distributed under the Apache 2.0 License.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
ComfyUI-IF_LLM
ComfyUI-IF_AI_LLM is a lighter version of ComfyUI-IF_AI_tools, providing custom nodes to run local and API LLMs and LMMs. It supports various models like Ollama, LlamaCPP, LMstudio, Koboldcpp, TextGen, Transformers, and APIs such as Anthropic, Groq, OpenAI, Google Gemini, Mistral, xAI. Users can create their own profiles (SystemPrompts) with custom presets. The tool offers features like xAI Grok Vision, Mistral, Google Gemini, Anthropic Haiku, OpenAI preview, auto prompts generation, image generation with IF_PROMPTImaGEN via Dalle3, and more. Installation involves searching for IF_LLM in the manager or manually installing ComfyUI-IF_AI_ImaGenPromptMaker by cloning the repository and installing requirements.
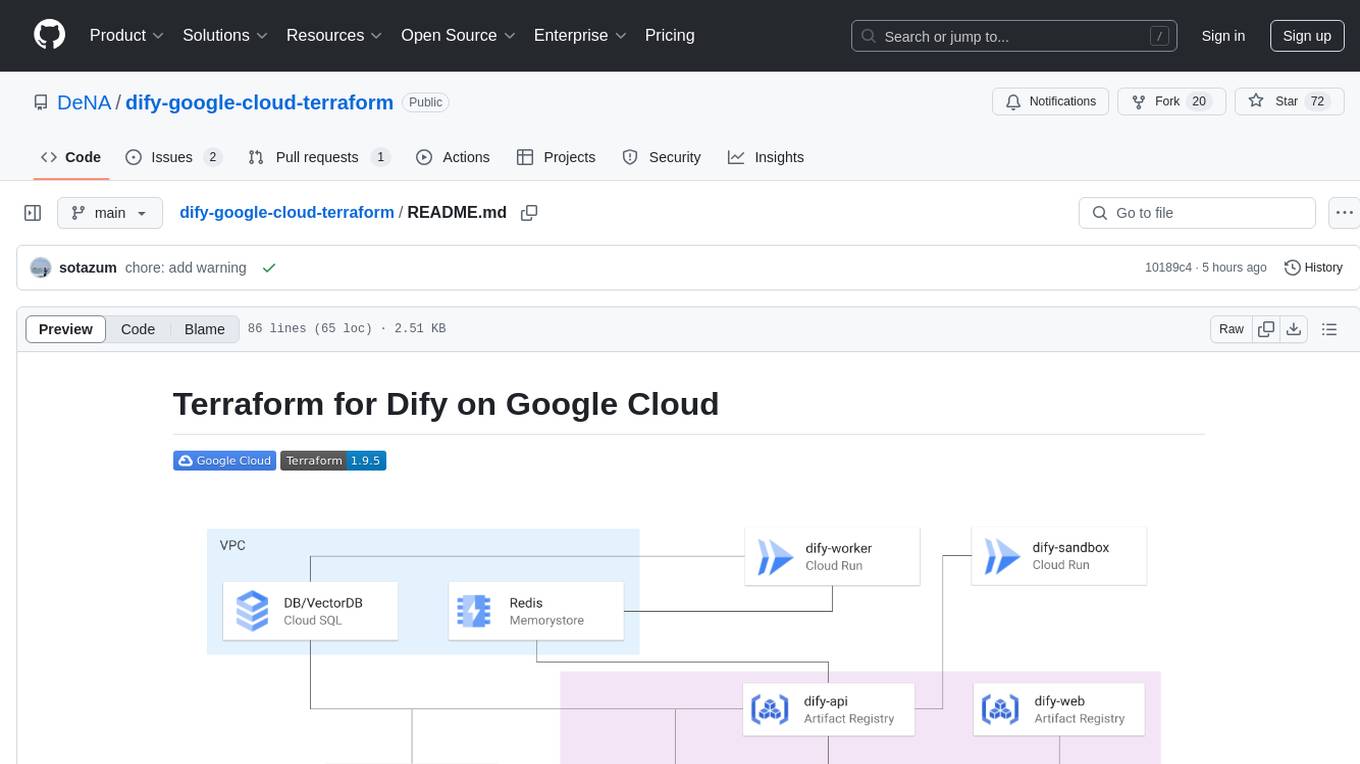
dify-google-cloud-terraform
This repository provides Terraform configurations to automatically set up Google Cloud resources and deploy Dify in a highly available configuration. It includes features such as serverless hosting, auto-scaling, and data persistence. Users need a Google Cloud account, Terraform, and gcloud CLI installed to use this tool. The configuration involves setting environment-specific values and creating a GCS bucket for managing Terraform state. The tool allows users to initialize Terraform, create Artifact Registry repository, build and push container images, plan and apply Terraform changes, and cleanup resources when needed.
AgentSquare
AgentSquare is an official implementation for the paper 'AgentSquare: Automatic LLM Agent Search in Modular Design Space'. It provides code, prompts, and results for automatic LLM agent search. The tool allows users to set up OpenAI API key, install dependencies, and run various tasks such as ALFworld, Webshop, M3Tooleval, and Sciworld. Users can also contribute new modules to the modular design challenge by standardizing LLM agents with recommended I/O interfaces. The tool aims to offer a platform for fully exploiting successful agent designs and consolidating efforts of the LLM agent research community.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
vim-ollama
The 'vim-ollama' plugin for Vim adds Copilot-like code completion support using Ollama as a backend, enabling intelligent AI-based code completion and integrated chat support for code reviews. It does not rely on cloud services, preserving user privacy. The plugin communicates with Ollama via Python scripts for code completion and interactive chat, supporting Vim only. Users can configure LLM models for code completion tasks and interactive conversations, with detailed installation and usage instructions provided in the README.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.
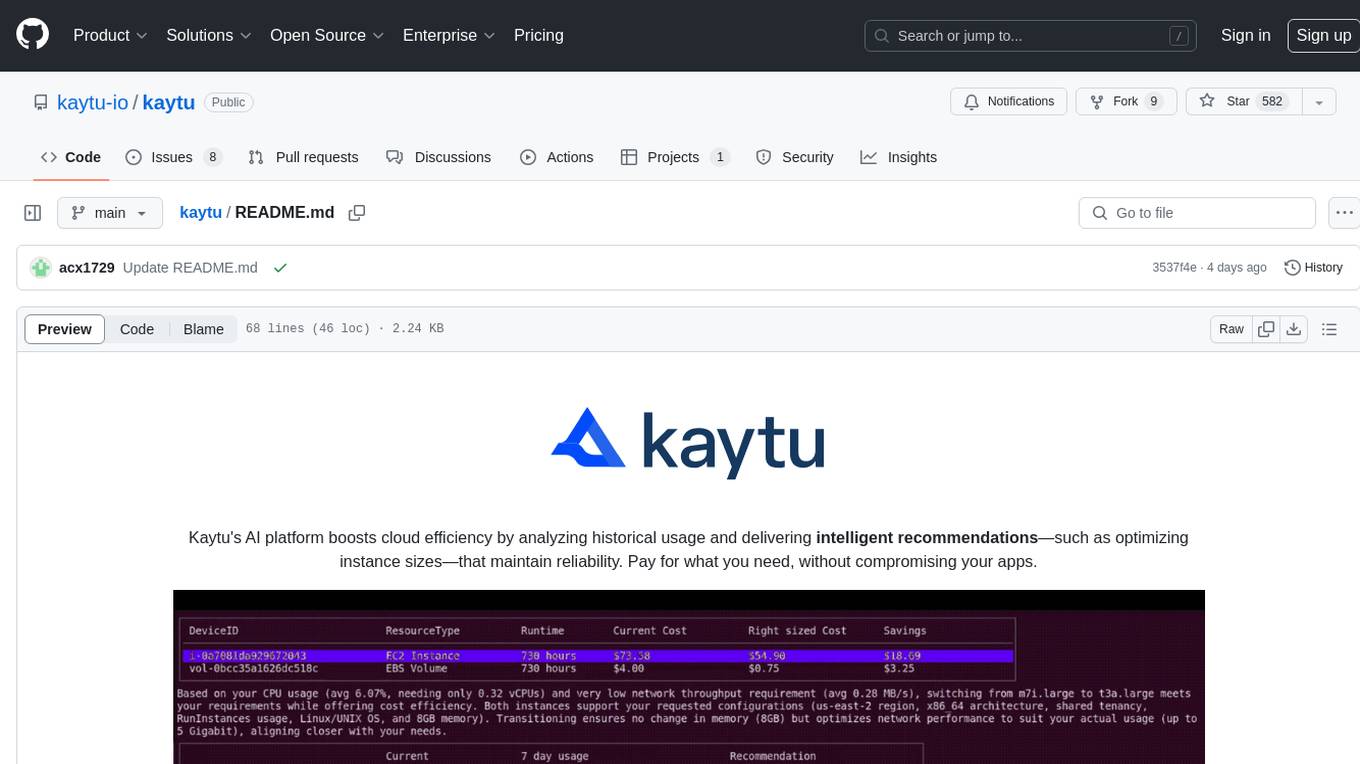
kaytu
Kaytu is an AI platform that enhances cloud efficiency by analyzing historical usage data and providing intelligent recommendations for optimizing instance sizes. Users can pay for only what they need without compromising the performance of their applications. The platform is easy to use with a one-line command, allows customization for specific requirements, and ensures security by extracting metrics from the client side. Kaytu is open-source and supports AWS services, with plans to expand to GCP, Azure, GPU optimization, and observability data from Prometheus in the future.
tangent
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

orama-core
OramaCore is a database designed for AI projects, answer engines, copilots, and search functionalities. It offers features such as a full-text search engine, vector database, LLM interface, and various utilities. The tool is currently under active development and not recommended for production use due to potential API changes. OramaCore aims to provide a comprehensive solution for managing data and enabling advanced AI capabilities in projects.

shellChatGPT
ShellChatGPT is a shell wrapper for OpenAI's ChatGPT, DALL-E, Whisper, and TTS, featuring integration with LocalAI, Ollama, Gemini, Mistral, Groq, and GitHub Models. It provides text and chat completions, vision, reasoning, and audio models, voice-in and voice-out chatting mode, text editor interface, markdown rendering support, session management, instruction prompt manager, integration with various service providers, command line completion, file picker dialogs, color scheme personalization, stdin and text file input support, and compatibility with Linux, FreeBSD, MacOS, and Termux for a responsive experience.
For similar tasks

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.
dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
examples
Cerebrium's official examples repository provides practical, ready-to-use examples for building Machine Learning / AI applications on the platform. The repository contains self-contained projects demonstrating specific use cases with detailed instructions on deployment. Examples cover a wide range of categories such as getting started, advanced concepts, endpoints, integrations, large language models, voice, image & video, migrations, application demos, batching, and Python apps.
HuaTuoAI
HuaTuoAI is an artificial intelligence image classification system specifically designed for traditional Chinese medicine. It utilizes deep learning techniques, such as Convolutional Neural Networks (CNN), to accurately classify Chinese herbs and ingredients based on input images. The project aims to unlock the secrets of plants, depict the unknown realm of Chinese medicine using technology and intelligence, and perpetuate ancient cultural heritage.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.