
BlueLM
BlueLM(蓝心大模型): Open large language models developed by vivo AI Lab
Stars: 869
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
README:
🤗 Hugging Face • 👾 ModelScope • 🤖 wisemodel • 📜 LICENSE • 🎯 vivo Developers • 🗨 WeChat
- 2024年3月25日更新 BlueLM-7B-Chat-32K 模型参数,支持 function calling 能力。我们在 api_server.py 中提供了 OpenAI 格式的 API。更新 BlueLM-7B-Chat-32K-AWQ 和 BlueLM-7B-Chat-32K-GPTQ 模型。
- 2024年12月25日将本项目的大模型开源许可证变更为 开放原子模型许可证。
BlueLM 是由 vivo AI 全球研究院自主研发的大规模预训练语言模型,本次发布包含 7B 基础 (base) 模型和 7B 对话 (chat) 模型,同时我们开源了支持 32K 的长文本基础 (base) 模型和对话 (chat) 模型。
- 更大量的优质数据:高质量语料库进行训练,规模达到了 2.6 万亿 的 token 数,该语料库包含中文、英文以及少量日韩数据;
- 更优的效果:其中 BlueLM-7B-Chat 在 C-Eval 和 CMMLU 上均取得领先结果,对比同尺寸开源模型中具有较强的竞争力;
- 长文本支持:BlueLM-7B-Base-32K 和 BlueLM-7B-Chat-32K 均支持 32K 长文本,在保持基础能力相当情况下,能够支持更长上下文理解;
- 协议说明:BlueLM 系列欢迎开发者进行学术研究和商业应用;
本次发布基座模型下载链接见:
| 基座模型 | 对齐模型 | 量化模型 | |
|---|---|---|---|
| 7B-2K | 🤗 BlueLM-7B-Base | 🤗 BlueLM-7B-Chat | 🤗 BlueLM-7B-Chat-4bits |
| 7B-32K | 🤗 BlueLM-7B-Base-32K | 🤗 BlueLM-7B-Chat-32K | 🤗 BlueLM-7B-Chat-32K-AWQ / BlueLM-7B-Chat-32K-GPTQ |
欢迎阅读我们的技术报告BlueLM: An Open Multilingual 7B Language Model!
我们后续将开源 13B 模型和支持多模态的 7B-vl 模型,还请期待!
为了保证模型评测的一致性,我们采用 OpenCompass 进行相关榜单的评测。我们分别在 C-Eval、MMLU、CMMLU、GaoKao、AGIEval、BBH、GSM8K、MATH 和 HumanEval 榜单对 BlueLM 的通用能力、数学能力和代码能力进行了测试。
- C-Eval 是一个全面的中文基础模型评测数据集,它包含了 13948 个多项选择题,涵盖了 52 个学科和四个难度级别。我们使用了 few shot 的方法来进行测试。
- MMLU 是一个包含了 57 个子任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,有效地衡量了人文、社科和理工等多个大类的综合知识能力。我们使用了 few shot 的方法来进行测试。
- CMMLU 是一个包含了 67 个主题的中文评测数据集,涉及自然科学、社会科学、工程、人文、以及常识等,有效地评估了大模型在中文知识储备和语言理解上的能力。我们使用了 few shot 的方法来进行测试。
- Gaokao 是一个中国高考题目的数据集,旨在直观且高效地测评大模型语言理解能力、逻辑推理能力的测评框架。我们只保留了其中的单项选择题,使用 zero shot 的方法来进行测试。
- AGIEval 是一个用于评估基础模型在标准化考试(如高考、公务员考试、法学院入学考试、数学竞赛和律师资格考试)中表现的数据集。我们只保留了其中的四选一单项选择题,使用 zero shot 的方法来进行测试。
- BBH 是一个挑战性任务 Big-Bench 的子集。Big-Bench 涵盖了语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面。BBH 更专注于其中 23 个具有挑战性的任务。我们使用了 few shot 的方法来进行测试。
- GSM8K 是一个高质量的英文小学数学问题测试集,包含 7.5K 训练数据和 1K 测试数据。这些问题通常需要 2-8 步才能解决,有效评估了数学与逻辑能力。我们使用了 few shot 的方法来进行测试。
- MATH 是一个由数学竞赛问题组成的评测集,由 AMC 10、AMC 12 和 AIME 等组成,包含 7.5K 训练数据和 5K 测试数据。我们使用 few shot 的方法来进行测试。
- HumanEval 是由 OpenAI 发布的 164 个手写的编程问题,包括模型语言理解、推理、算法和简单数学等任务。我们使用 zero shot 的方法来进行测试。
- LongBench 是第一个用于对大型语言模型进行双语、多任务、全面评估长文本理解能力的基准测试。
- T-Eval 是第一个用于对大型语言模型的工具使用能力进行全面评估的测试集,涵盖有工具调用(Function call)、规划、执行信息抽取、工具运行日志评估等多维度。我们使用 zero shot 的方法在它的中文测试集上进行测试。
| Model | C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | GSM8K | MATH | HumanEval |
|---|---|---|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 0-shot | 0-shot | 3-shot | 4-shot | 5-shot | 0-shot | |
| GPT-4 | 69.9 | 86.4 | 71.2 | 72.3 | 55.1 | 86.7 | 91.4 | 45.8 | 74.4 |
| ChatGPT | 52.5 | 70.0 | 53.9 | 51.1 | 39.9 | 70.1 | 78.2 | 28 | 73.2 |
| LLaMA2-7B | 32.5 | 45.3 | 31.8 | 18.9 | 21.8 | 38.2 | 16.7 | 3.3 | 12.8 |
| ChatGLM2-6B(Base) | 51.7 | 47.9 | 50.0 | - | - | 33.7 | 32.4 | 6.5 | - |
| Baichuan2-7B | 56.3 | 54.7 | 57.0 | 34.8 | 34.6 | 41.8 | 24.6 | 5.4 | 17.7 |
| BlueLM-7B-Base | 67.5 | 55.2 | 66.6 | 58.9 | 43.4 | 41.7 | 27.2 | 6.2 | 18.3 |
| BlueLM-7B-Chat | 72.7 | 50.7 | 74.2 | 48.7 | 43.4 | 65.6 | 51.9 | 13.4 | 21.3 |
我们还在 LongBench 和 T-Eval 评测集上对我们的 BlueLM-7B-Chat-32K 模型进行了测试,具体结果如下表所示:
| Model | 平均 | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic |
|---|---|---|---|---|---|---|---|
| BlueLM-7B-Chat-32K | 41.2 | 18.8 | 35.6 | 36.2 | 54.2 | 56.9 | 45.5 |
| Model | instruct | plan | reason | retrieve | understand | review | overall |
|---|---|---|---|---|---|---|---|
| Qwen-7B | 82.3 | 62.2 | 50.0 | 59.1 | 67.0 | 57.1 | 63.0 |
| Qwen-14B | 96.5 | 77.1 | 57.0 | 73.0 | 76.5 | 43.7 | 70.6 |
| BlueLM-7B-Chat-32K | 79.6 | 63.4 | 61.5 | 73.9 | 74.2 | 73.9 | 71.3 |
首先需要下载本仓库:
git clone https://github.com/vivo-ai-lab/BlueLM
cd BlueLM
然后使用 pip 安装依赖:
pip install -r requirements.txt
使用 BlueLM-7B-Base-32K 或 BlueLM-7B-Chat-32K,请额外安装 flash_attn:
pip install flash_attn==2.3.3
如果安装失败,建议安装预编译版本的 flash_attn。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("vivo-ai/BlueLM-7B-Base", trust_remote_code=True, use_fast=False)
>>> model = AutoModelForCausalLM.from_pretrained("vivo-ai/BlueLM-7B-Base", device_map="cuda:0", trust_remote_code=True)
>>> model = model.eval()
>>> inputs = tokenizer("儒林外史->吴敬梓\n隋唐演义->褚人获\n红楼梦->", return_tensors="pt")
>>> inputs = inputs.to("cuda:0")
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
儒林外史->吴敬梓
隋唐演义->褚人获
红楼梦->曹雪芹
三国演义->罗贯中
水浒传->施耐庵
西游记->吴承恩
聊斋志异->蒲松龄
封神演义->许仲琳
东周列国志->冯梦龙
三侠五义->石玉昆
七剑十三侠->唐芸洲
python cli_demo.py本命令行 Demo 仅支持 Chat 场景。

streamlit run web_demo.py --server.port 8080本网页 Demo 仅支持 Chat 场景。
运行 api_server.py 部署 OpenAI 格式的代码,支持基于 ChatGPT 应用后端。
cd openai_api_demo
python api_server.pypython 测试代码,包括支持流式响应和 function calling 的请求。
cd openai_api_demo
python openai_api_request.py可在命令行运行工具使用 Demo cli_demo_tool.py, demo 中已提供可作为测试的工具 sample。
python cli_demo_tool.py根据命令行提示分别输入问题与外部工具的执行结果,完成一次工具调用需进行两轮对话。
示例:"<>"内为待用户输入内容。
用户: <杭州今天的湿度是多少?>
BlueLM:
{\"answer\": null, \"function_calls\": [{\"name\": \"current-weather\", \"parameters\": {\"city\": \"杭州\"}}]}
工具结果: <{\"city\": \"杭州\", \"weather\": \"当前天气 晴,气温20摄氏度,风力2级,湿度40%\"}>
BlueLM:
{"answer": "杭州湿度40%。", "function_calls": null}
代码
User:某在线教育平台的课程数据存储在一个名为courses的列表中,每门课程用字典表示,包含课程名称(name)、教师姓名(teacher)和学生人数(students)三个字段。请编写一个Python函数,根据学生人数,计算课程的平均学生人数,并返回。
BlueLM-7B:下面是实现代码:
```python
def average_students(courses):
total_students = 0
count = 0
for course in courses:
total_students += course['students']
count += 1
if count == 0:
return 0
else:
return total_students / count
```
这个函数接受一个课程列表作为参数,然后遍历列表中的每个课程,累加学生人数的总和,同时记录课程的数量。最后,如果列表为空,则返回0;否则,返回学生人数的平均值。
数学
User:朵朵有100元,她要买两本绘画书,绘画书每本40元,朵朵买完绘画书还剩多少元?
BlueLM-7B:可以先计算两本绘画书需要支付的总金额,然后计算购买后还剩下的金额。
已知朵朵有的钱数为:100元;
已知每本绘画书的价格为:40元;
因此,两本绘画书需要支付的总金额为:$40 \times 2 = 80$元;
购买两本绘画书后,还剩下的金额为:$100 - 80 = 20$元;
所以,朵朵买完绘画书还剩下20元。
角色扮演
User:我是一名营销经理,最近我们推出了一款新产品,但是销售情况并不理想。这款产品是一款健康食品,主打低脂低糖,适合健身人群和需要控制饮食的人群。我们已经尝试过线上营销、线下推广、与知名健身房合作等方式,但是效果都不明显。你能帮我分析一下可能的原因以及提供一些销售策略吗?
BlueLM-7B:分析:
1. 竞争激烈:市场上已经存在许多类似的产品,消费者有更多的选择,导致新产品的市场占有率为零或很低。
2. 价格过高:该产品的价格比同类其他产品更高,可能会使消费者更倾向于购买其他品牌或更便宜的选项。
3. 缺乏宣传:没有足够的宣传使得消费者对该产品的了解程度不够,从而无法吸引更多的消费者。
4. 销售渠道不当:虽然已经尝试了多种销售方式,但可能没有选择到最适合的渠道,导致销售情况不佳。
策略:
1. 降低价格:考虑降低价格以吸引更多的消费者,同时保持产品质量和品质。
2. 加强宣传:增加宣传力度,包括在社交媒体上发布广告、增加线上营销等方式,提高消费者对产品的认知度。
3. 寻找合适的销售渠道:考虑与健身房等机构进行合作,或者寻找更符合目标消费者的销售渠道。
4. 改进产品:根据消费者的反馈意见,对产品进行改进,提高其质量和受欢迎程度。
我们提供了 BlueLM-7B-Chat 的 4bits 版本 BlueLM-7B-Chat-4bits。如果你的 GPU 显存有限,可以尝试加载 4-bits 模型,只需要 5GB 显存。且经过测试,BlueLM 在 4-bits 量化下仍能流畅地生成文本。
安装依赖:
cd BlueLM/quant_cuda
python setup_cuda.py install
加载模型推理示例:
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", trust_remote_code=True, use_fast=False)
>>> model = AutoModelForCausalLM.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", device_map="cuda:0", trust_remote_code=True)
>>> model = model.eval()
>>> inputs = tokenizer("[|Human|]:三国演义的作者是谁?[|AI|]:", return_tensors="pt")
>>> inputs = inputs.to("cuda:0")
>>> outputs = model.generate(**inputs, max_new_tokens=128)
>>> print(tokenizer.decode(outputs.cpu()[0], skip_special_tokens=True))
三国演义的作者是谁? 《三国演义》是由元末明初小说家罗贯中所著,是中国古典四大名著之一,也是中国古代历史小说发展的巅峰之作。我们基于 vllm 推理框架,添加了 BlueLM 模型推理代码,代码在 example/vllm 目录中。
环境准备及编译:
运行环境需要英伟达驱动版本为 525.125.06,同时 cuda 版本为 12.1。
python -m venv vllm
source vllm/bin/activate
cd example/vllm
pip install -e .
python vllm_demo.py
pip install deepspeed==0.10.3
为了简单展示模型的微调流程,我们在 BELLE 项目 50w 中文指令 中随机抽取了 1w 条中文指令数据,处理后的数据路径为 data/bella_train_demo.json 和 data/bella_dev_demo.json。
获得处理完的数据后,可通过训练脚本 script/bluelm-7b-sft.sh 配置相应的路径和超参数,进行全量微调训练。
相关参数的说明如下所示:
| Parameter | Description |
|---|---|
| num_gpus | 对应 GPU 的卡数 |
| train_file | 训练数据的路径 |
| prompt_column | 数据集指令问题的列名 |
| response_column | 数据集指令回复的列名 |
| model_name_or_path | 预加载模型的存储路径 |
| output_dir | 微调模型的保存路径 |
| tensorboard_dir | tensorboard的保存路径 |
| seq_len | 训练序列的最大长度 |
| batch_size_per_device | 训练迭代中每个 GPU 输入的样本数量 |
| gradient_accumulation_steps | 梯度累积的步长,默认为 1,表示不进行梯度累积 |
| gradient_checkpointing | 是否开启激活重算 |
| max_steps | 模型训练的迭代数 |
| save_steps | 模型训练的保存周期 |
| learning_rate | 初始学习率 |
| finetune | 是否开启模型微调 |
使用全量微调的启动命令如下:
cd train
sh script/bluelm-7b-sft.sh本项目支持 LoRA 的微调训练。关于 LoRA 的详细介绍可以参考论文 LoRA: Low-Rank Adaptation of Large Language Models 以及 Github 仓库 LoRA。
主要参数说明如下:
| Parameter | Description |
|---|---|
| lora_rank | lora 矩阵的秩。一般设置为 8、16、32、64 等。 |
| lora_alpha | lora 中的缩放参数。一般设为 16、32 即可 |
| lora_dropout | lora 权重的 dropout rate。 |
使用 LoRA 微调的启动命令如下:
cd train
sh script/bluelm-7b-sft-lora.sh我们在此郑重声明,对于所有使用开源模型的有关方,强烈呼吁不要进行任何损害国家社会安全或违反相关法律的行为,也恳请使用者不把 BlueLM 模型用于未经适当安全审批和备案的产品应用中。请务必在合法、合规的前提下开展一切业务活动,我们期望所有使用者都能以此为准。
同时,本模型“按原样”提供,我们也已尽全力确保数据的合规性,但由于模型训练和数据的复杂性,仍可能存在一些无法预估的问题,我们也强烈建议使用者对模型应用风险做详尽评估,确保应用的合法合规,如使用 BlueLM 开源模型而导致的任何问题,我们将不承担任何责任。
为了使本项目更加开放、灵活,服务更多开发者与用户,自2024年12月25日起,本项目的大模型开源许可证进行了一次重要更新,由 原vivo_BlueLM模型许可协议 变更为 开放原子模型许可证。
基于全新的大模型开源许可证,使用者可以在更少的限制下使用、修改和分发本项目的大模型。请确保您阅读并理解新的 许可证内容。我们欢迎任何对这一变化的反馈,您可以通过 GitHub Issues 与我们联系。
BlueLM 模型权重对学术研究完全开放,同时在填写 问卷 进行登记认证后可免费商业使用。
@misc{2023bluelm,
title={BlueLM: An Open Multilingual 7B Language Model},
author={BlueLM Team},
howpublished = {\url{https://github.com/vivo-ai-lab/BlueLM}},
year={2023}
}
如有任何疑问,可以通过邮件([email protected])联系我们,也可以加入 BlueLM 微信交流群探讨。

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BlueLM
Similar Open Source Tools
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
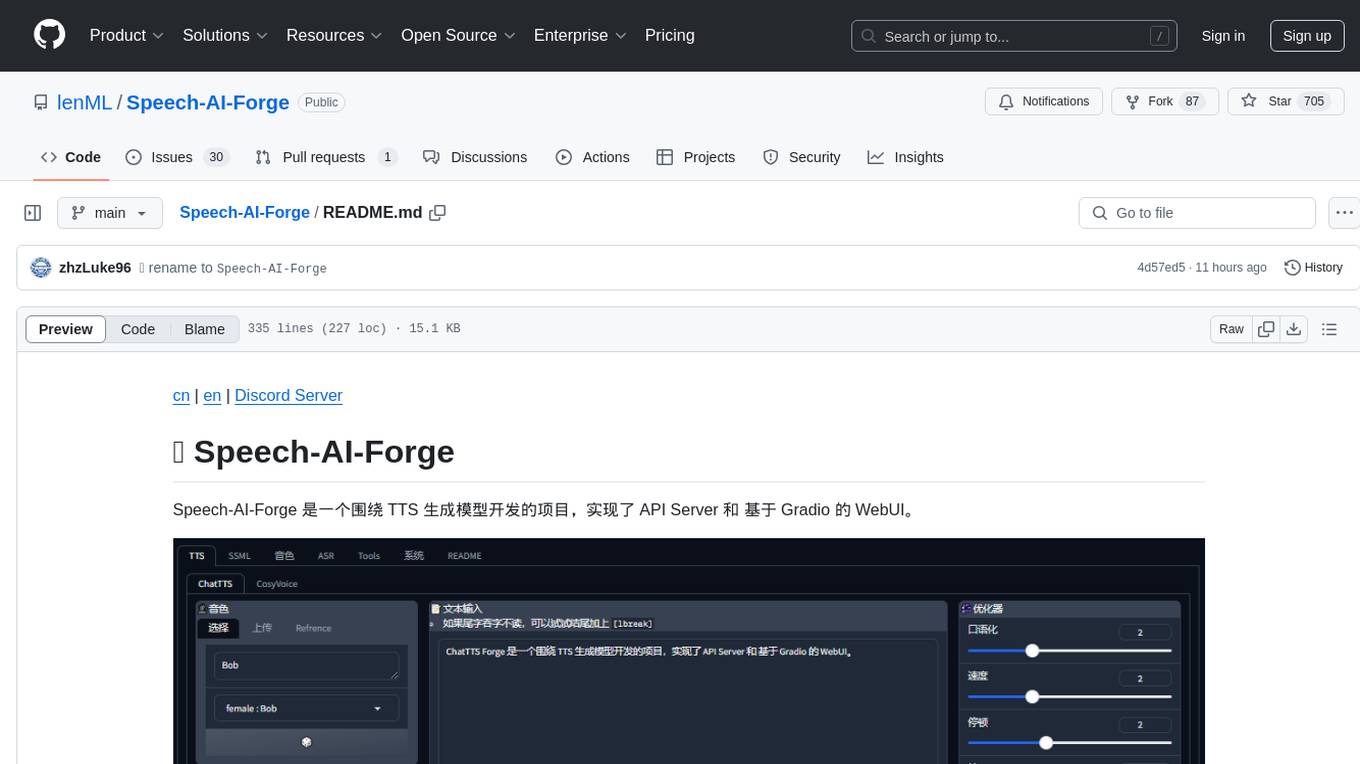
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
DISC-LawLLM
DISC-LawLLM is a legal domain large model that aims to provide professional, intelligent, and comprehensive **legal services** to users. It is developed and open-sourced by the Data Intelligence and Social Computing Lab (Fudan-DISC) at Fudan University.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.
gpt_server
The GPT Server project leverages the basic capabilities of FastChat to provide the capabilities of an openai server. It perfectly adapts more models, optimizes models with poor compatibility in FastChat, and supports loading vllm, LMDeploy, and hf in various ways. It also supports all sentence_transformers compatible semantic vector models, including Chat templates with function roles, Function Calling (Tools) capability, and multi-modal large models. The project aims to reduce the difficulty of model adaptation and project usage, making it easier to deploy the latest models with minimal code changes.
DeepAI
DeepAI is a proxy server that enhances the interaction experience of large language models (LLMs) by integrating the 'thinking chain' process. It acts as an intermediary layer, receiving standard OpenAI API compatible requests, using independent 'thinking services' to generate reasoning processes, and then forwarding the enhanced requests to the LLM backend of your choice. This ensures that responses are not only generated by the LLM but also based on pre-inference analysis, resulting in more insightful and coherent answers. DeepAI supports seamless integration with applications designed for the OpenAI API, providing endpoints for '/v1/chat/completions' and '/v1/models', making it easy to integrate into existing applications. It offers features such as reasoning chain enhancement, flexible backend support, API key routing, weighted random selection, proxy support, comprehensive logging, and graceful shutdown.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
Element-Plus-X
Element-Plus-X is an out-of-the-box enterprise-level AI component library based on Vue 3 + Element-Plus. It features built-in scenario components such as chatbots and voice interactions, seamless integration with zero configuration based on Element-Plus design system, and support for on-demand loading with Tree Shaking optimization.
XianyuAutoAgent
Xianyu AutoAgent is an AI customer service robot system specifically designed for the Xianyu platform, providing 24/7 automated customer service, supporting multi-expert collaborative decision-making, intelligent bargaining, and context-aware conversations. The system includes intelligent conversation engine with features like context awareness and expert routing, business function matrix with modules like core engine, bargaining system, technical support, and operation monitoring. It requires Python 3.8+ and NodeJS 18+ for installation and operation. Users can customize prompts for different experts and contribute to the project through issues or pull requests.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.