
crb
CRB 🦀 transactional actors
Stars: 105
CRB (Composable Runtime Blocks) is a unique framework that implements hybrid workloads by seamlessly combining synchronous and asynchronous activities, state machines, routines, the actor model, and supervisors. It is ideal for building massive applications and serves as a low-level framework for creating custom frameworks, such as AI-agents. The core idea is to ensure high compatibility among all blocks, enabling significant code reuse. The framework allows for the implementation of algorithms with complex branching, making it suitable for building large-scale applications or implementing complex workflows, such as AI pipelines. It provides flexibility in defining structures, implementing traits, and managing execution flow, allowing users to create robust and nonlinear algorithms easily.
README:


A unique framework that implementes hybrid workloads, seamlessly combining synchronous and asynchronous activities, state machines, routines, the actor model, and supervisors.
It’s perfect for building massive applications and serves as an ideal low-level framework for creating your own frameworks, for example AI-agents. The core idea is to ensure all blocks are highly compatible with each other, enabling significant code reuse.
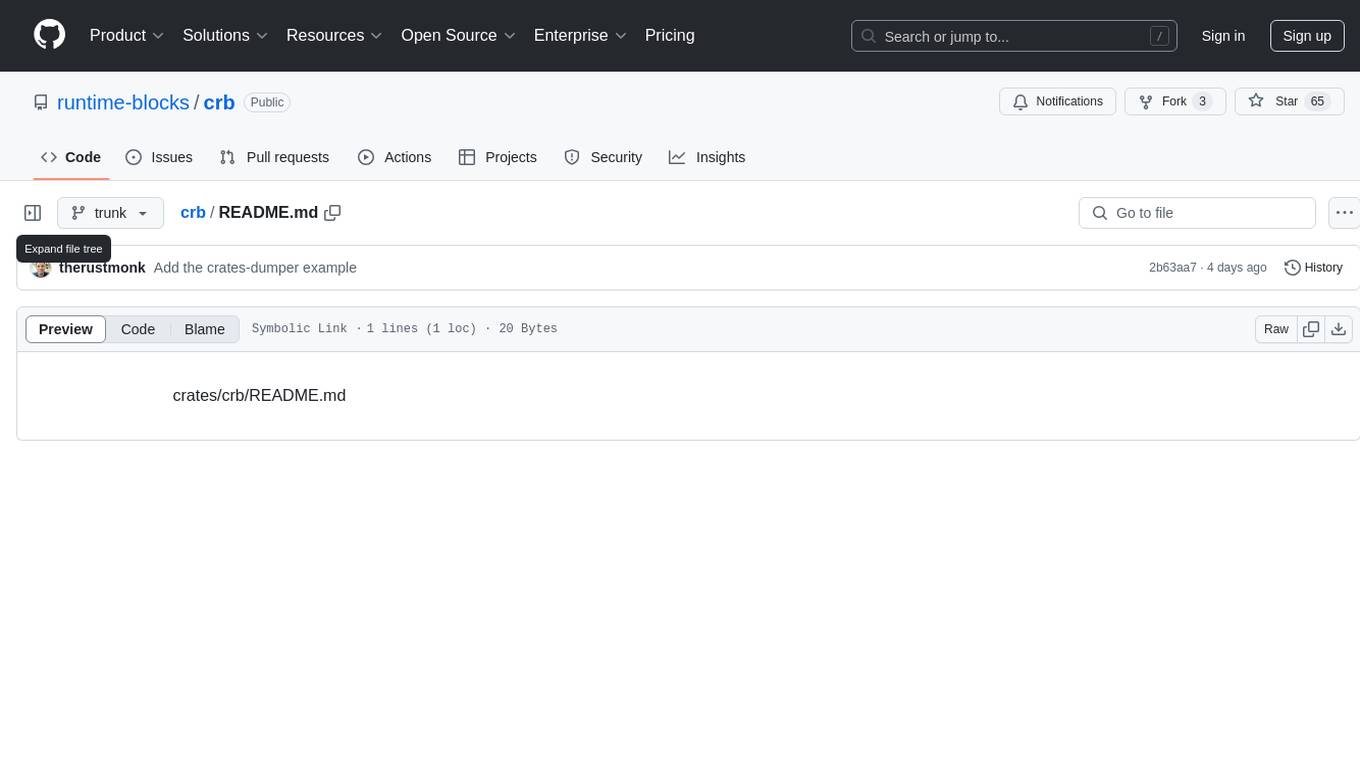
A hybrid workload is a concurrent task capable of switching roles - it can function as a synchronous or asynchronous task, a finite state machine, or as an actor exchanging messages.
The implementation is designed as a fully portable solution that can run in a standard environment, a WASM virtual machine (e.g., in a browser), or a TEE enclave. This approach significantly reduces development costs by allowing you to reuse code across all parts of your application: backend, frontend, agents, and more.

The key feature is its ability to combine the roles, enabling the implementation of algorithms with complex branching that would be impossible in the flat structure of a standard function. This makes it ideal for building the framework of large-scale applications or implementing complex workflows, such as AI pipelines.
The following projects have been implemented using the framework:
- Nine - AI agents that work everywhere.
- Crateful - AI-curated weekly newsletter about Rust crates.
- Knowledge.Dev - An interactive book for learning practical, idiomatic Rust (product is entirely written in Rust).
Below, you'll find numerous examples of building hybrid activities using the framework. These examples are functional but simplified for clarity:
- Type imports are omitted to keep examples clean and focused.
- The
async_traitmacro is used but not explicitly shown, as exported traits with asynchronous methods are expected in the future. -
anyhow::Resultis used instead of the standardResultfor simplicity. - Agent context is not specified, as it is always
AgentSessionin these cases.
The examples demonstrate various combinations of states and modes, but in reality, there are many more possibilities, allowing for any sequence or combination.
To create a universal hybrid activity, you need to define a structure and implement the Agent trait for it. By default, the agent starts in a reactive actor mode, ready to receive messages and interact with other actors.
However, you can override this behavior by explicitly specifying the agent's initial state in the begin() method.
pub struct Task;
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
Next::do_async(()) // The next state
}
}The next state is defined using the Next object, which provides various methods for controlling the state machine. To perform an asynchronous activity, use the do_async() method, passing the new state as a parameter (default is ()).
Then, implement the DoAsync trait for your agent by defining the asynchronous once() method:
impl DoAsync for Task {
async fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
do_something().await?;
Ok(Next::done())
}
}The result should specify the next state of the state machine. If you want to terminate the agent, simply return the termination state by calling the done() method on the Next type.
The simplest example is creating a task that performs an asynchronous activity and then terminates.
pub struct Task;
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
Next::do_async(())
}
}
impl DoAsync for Task {
async fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
reqwest::get("https://www.rust-lang.org").await?.text().await?;
Ok(Next::done())
}
}Unlike standard asynchronous activities, you can implement the fallback() method to modify the course of actions in case of an error:
impl DoAsync for Task {
async fn fallback(&mut self, err: Error) -> Next<Self> {
log::error!("Can't load a page: {err}. Trying again...");
Ok(Next::do_async(()))
}
}The task will now repeatedly enter the same state until the loading process succeeds.
The agent already implements a persistent routine in the repeat() method, which repeatedly attempts to succeed by calling the once() method. To achieve the same effect, we can simply override that method:
impl DoAsync for Task {
async fn repeat(&mut self, _: &mut ()) -> Result<Option<Next<Self>>> {
reqwest::get("https://www.rust-lang.org").await?.text().await?;
Ok(Some(Next::done()))
}
}The repeat() method will continue to run until it returns the next state for the agent to transition to.
To implement a synchronous task simply call the do_sync() method on Next:
pub struct Task;
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
Next::do_sync(())
}
}Next, implement the DoSync trait to run the task in a thread (either the same or a separate one, depending on the platform):
impl DoSync for Task {
fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
let result: u64 = (1u64..=20).map(|x| x.pow(10)).sum();
println!("{result}");
Ok(Next::done())
}
}In the example, it calculates the sum of powers and prints the result to the terminal.
Interestingly, you can define different states and implement unique behavior for each, whether synchronous or asynchronous. This gives you both a state machine and varied execution contexts without the need for manual process management.
Let’s create an agent that prints the content of a webpage to the terminal. The first state the agent should transition to is GetPage, which includes the URL of the page to be loaded. This state will be asynchronous, so call the do_async() method with the Next state.
pub struct Task;
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
let url = "https://www.rust-lang.org".into();
Next::do_async(GetPage { url })
}
}Implement the GetPage state by defining the corresponding structure and using it in the DoAsync trait implementation for our agent Task:
struct GetPage { url: String }
impl DoAsync<GetPage> for Task {
async fn once(&mut self, state: &mut GetPage) -> Result<Next<Self>> {
let text = reqwest::get(state.url).await?.text().await?;
Ok(Next::do_sync(Print { text }))
}
}In the GetPage state, the webpage will be loaded, and its content will be passed to the next state, Print, for printing. Since the next state is synchronous, it is provided as a parameter to the do_sync() method.
Now, let’s define the Print state as a structure and implement the DoSync trait for it:
struct Print { text: String }
impl DoSync<Print> for Task {
fn once(&mut self, state: &mut Print) -> Result<Next<Self>> {
printlnt!("{}", state.text);
Ok(Next::done())
}
}The result is a state machine with the flexibility to direct its workflow into different states, enabling the implementation of a robust and sometimes highly nonlinear algorithm that would be extremely difficult to achieve within a single asynchronous function.
Previously, we didn't modify the data stored in a state. However, states provide a convenient context for managing execution flow or collecting statistics without cluttering the task's main structure!
pub struct Task;
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
Next::do_async(Monitor)
}
}
struct Monitor {
total: u64,
success: u64,
}
impl DoAsync<Monitor> for Task {
async fn repeat(&mut self, mut state: &mut Monitor) -> Result<Option<Next<Self>>> {
state.total += 1;
reqwest::get("https://www.rust-lang.org").await?.error_for_status()?;
state.success += 1;
sleep(Duration::from_secs(10)).await;
Ok(None)
}
}Above is an implementation of a monitor that simply polls a website and counts successful attempts. It does this without modifying the Task structure while maintaining access to it.
Within an asynchronous activity, all standard tools for concurrently executing multiple Futures are available. For example, in the following code, several web pages are requested simultaneously using the join_all() function:
pub struct ConcurrentTask;
impl Agent for ConcurrentTask {
fn begin(&mut self) -> Next<Self> {
Next::do_async(())
}
}
impl DoAsync for ConcurrentTask {
async fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
let urls = vec![
"https://www.rust-lang.org",
"https://www.crates.io",
"https://crateful.substack.com",
"https://knowledge.dev",
];
let futures = urls.into_iter().map(|url| reqwest::get(url));
future::join_all(futures).await
Ok(Next::done())
}
}This approach allows for more efficient utilization of the asynchronous runtime while maintaining the workflow without needing to synchronize the retrieval of multiple results.
Another option is parallelizing computations. This is easily achieved by implementing a synchronous state. Since it runs in a separate thread, it doesn't block the asynchronous runtime, allowing other agents to continue executing in parallel.
pub struct ParallelTask;
impl Agent for ParallelTask {
fn begin(&mut self) -> Next<Self> {
Next::do_sync(())
}
}
impl DoSync for ParallelTask {
fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let squares = numbers.into_par_iter().map(|n| n * n).collect();
Ok(Next::done())
}
}In the example above, parallel computations are performed using the rayon crate. The results are awaited asynchronously by the agent since DoSync shifts execution to a thread while continuing to wait for the result asynchronously.
The framework allows tasks to be reused within other tasks, offering great flexibility in structuring code.
pub struct RunBoth;
impl Agent for RunBoth {
fn begin(&mut self) -> Next<Self> {
Next::do_async(())
}
}
impl DoAsync for RunBoth {
async fn once(&mut self, _: &mut ()) -> Result<Next<Self>> {
join!(
ConcurrentTask.run(),
ParallelTask.run(),
).await;
Ok(Next::done())
}
}The code example implementes an agent that waits for the simultaneous completion of two tasks we implemented earlier: concurrent and parallel.
Although the states within a group inherently form a state machine, you can define it more explicitly by adding a field to the agent and describing the states with a dedicated enum:
enum State {
First,
Second,
Third,
}
struct Task {
state: State,
}In this case, the State enumeration can handle transitions between states. Transition rules can be implemented as a function that returns a Next instance with the appropriate state handler.
impl State {
fn next(&self) -> Next<Task> {
match self {
State::First => Next::do_async(First),
State::Second => Next::do_async(Second),
State::Third => Next::do_async(Third),
}
}
}Set the initial state when creating the task (it can even be set in the constructor), and delegate state transitions to the next() function, called from the begin() method.
impl Agent for Task {
fn begin(&mut self) -> Next<Self> {
self.state.next()
}
}Implement all state handlers, with the State field determining the transition to the appropriate handler. Simply use its next() method so that whenever the state changes, the transition always leads to the correct handler.
struct First;
impl DoAsync<First> for Task {
async fn once(&mut self, _: &mut First) -> Result<Next<Self>> {
self.state = State::Second;
Ok(self.state.next())
}
}
struct Second;
impl DoAsync<Second> for Task {
async fn once(&mut self, _: &mut Second) -> Result<Next<Self>> {
self.state = State::Third;
Ok(self.state.next())
}
}
struct Third;
impl DoAsync<Third> for Task {
async fn once(&mut self, _: &mut Third) -> Result<Next<Self>> {
Ok(Next::done())
}
}💡 The framework is so flexible that it allows you to make this logic even more explicit by implementing a custom Performer for the agent.
Agents handle messages asynchronously. Actor behavior is enabled by default if no transition state is specified in the begin() method. Alternatively, you can switch to this mode from any state by calling Next::events(), which starts message processing.
In other words, the actor state is the default for the agent, so simply implementing the Agent trait is enough:
struct Actor;
impl Agent for Actor {}An actor can accept any data type as a message, as long as it implements the OnEvent trait for that type and its handle() method. For example, let's teach our actor to accept an AddUrl message, which adds an external resource:
struct AddUrl { url: Url }
impl OnEvent<AddUrl> for Actor {
async handle(&mut self, event: AddUrl, ctx: &mut Context<Self>) -> Result<()> {
todo!()
}
}Actors can implement handlers for any number of messages, allowing you to add as many OnEvent implementations as needed:
struct DeleteUrl { url: Url }
impl OnEvent<DeleteUrl> for Actor {
async handle(&mut self, event: DeleteUrl, ctx: &mut Context<Self>) -> Result<()> {
todo!()
}
}The provided context (ctx) allows you to send a message, terminate the actor, or transition to a new state by setting the next state with Next.
State transitions have the highest priority. Even if there are messages in the queue, the state transition will occur first, and messages will wait until the agent returns to the actor state.
The actor model is designed to let you add custom handler traits for any type of event. For example, this framework supports interactive actor interactions—special messages that include a request and a channel for sending a response.
The example below implements a server that reserves an Id in response to an interactive request and returns it:
struct Server {
slab: Slab<Record>,
}
struct GetId;
impl Request for GetId {
type Response = usize;
}
impl OnRequest<GetId> for Server {
async on_request(&mut self, _: GetId, ctx: &mut Context<Self>) -> Result<usize> {
let record = Record { ... };
Ok(self.slab.insert(record))
}
}The request must implement the Request trait to specify the Response type. As you may have noticed, for the OnRequest trait, we implemented the on_request() method, which expects a response as the result. This eliminates the need to send it manually.
The following code implements a Client that configures itself by sending a request to the server to obtain an Id and waits for a response by implementing the OnResponse trait.
struct Client {
server: Address<Server>,
}
impl Agent for Client {
fn begin(&mut self) -> Next<Self> {
Next::do_async(Configure)
}
}
struct Configure;
impl DoAsync<Configure> for Client {
async fn once(&mut self, _: &mut Configure, ctx: &mut Context<Self>) -> Result<Next<Self>> {
self.server.request(GetId)?.forward_to(ctx)?;
Ok(Next::events())
}
}
impl OnResponse<GetId> for Client {
async on_response(&mut self, id: usize, ctx: &mut Context<Self>) -> Result<()> {
println!("Reserved id: {id}");
Ok(())
}
}An actor (or any agent) can be launched from anywhere if it implements the Standalone trait. Otherwise, it can only be started within the context of a supervisor.
The supervisor can also manage all spawned tasks and terminate them in a specific order by implementing the Supervisor trait:
struct App;
impl Agent for App {
type Context = SupervisorSession<Self>;
}
impl Supervior for App {
type Group = Group;
}The Group type defines a grouping for tasks, where the order of its values determines the sequence in which child agents (tasks, actors) are terminated.
#[derive(Clone, PartialEq, Eq, PartialOrd, Ord, Hash)]
enum Group {
Workers,
Requests,
Server,
HealthCheck,
DbCleaner,
UserSession(Uid),
}The framework includes an experimental implementation of pipelines that automatically trigger tasks as they process input data from the previous stage.
However, creating complex workflows is also possible using just the agent's core implementation.
todo
One of the library's major advantages is its out-of-the-box compatibility with WebAssembly (WASM). This allows you to write full-stack solutions in Rust while reusing the same codebase across different environments.
Synchronous tasks are currently unavailable in WASM due to its lack of full thread support. However, using them in environments like browsers is generally unnecessary, as they block asynchronous operations.
The library includes a complete implementation of the actor model, enabling you to build a hierarchy of actors and facilitate message passing between them. When the application stops, actors gracefully shut down between messages processing phases, and in the specified order.
The framework supports not only asynchronous activities (IO-bound) but also allows running synchronous (CPU-bound) tasks using threads. The results of these tasks can seamlessly be consumed by asynchronous activities.
The library offers a Pipeline implementation compatible with actors, routines, and tasks (including synchronous ones), making it ideal for building AI processing workflows.
Unlike many actor frameworks, this library relies heavily on traits. For example, tasks like interactive communication, message handling, or Stream processing are implemented through specific trait implementations.
More importantly, the library is designed to be extensible, allowing you to define your own traits for various needs while keeping your code modular and elegant. For instance, actor interruption is implemented on top of this model.
Trait methods are designed and implemented so that you only need to define specific methods to achieve the desired behavior.
Alternatively, you can fully override the behavior and method call order - for instance, customizing an actor’s behavior in any way you like or adding your own intermediate phases and methods.
The library provides built-in error handling features, such as managing failures during message processing, making it easier to write robust and resilient applications.
The project was originally created by @therustmonk as a result of extensive experimental research into implementing a hybrid actor model in Rust.
To support the project, consider subscribing to Crateful, my newsletter focused on AI agent development in Rust. It features insights gathered by a group of crab agents built with this framework.
This project is licensed under the MIT license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for crb
Similar Open Source Tools
crb
CRB (Composable Runtime Blocks) is a unique framework that implements hybrid workloads by seamlessly combining synchronous and asynchronous activities, state machines, routines, the actor model, and supervisors. It is ideal for building massive applications and serves as a low-level framework for creating custom frameworks, such as AI-agents. The core idea is to ensure high compatibility among all blocks, enabling significant code reuse. The framework allows for the implementation of algorithms with complex branching, making it suitable for building large-scale applications or implementing complex workflows, such as AI pipelines. It provides flexibility in defining structures, implementing traits, and managing execution flow, allowing users to create robust and nonlinear algorithms easily.
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.
experts
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.
LLMUnity
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine, allowing users to create intelligent characters for immersive player interactions. The tool supports major LLM models, runs locally without internet access, offers fast inference on CPU and GPU, and is easy to set up with a single line of code. It is free for both personal and commercial use, tested on Unity 2021 LTS, 2022 LTS, and 2023. Users can build multiple AI characters efficiently, use remote servers for processing, and customize model settings for text generation.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.
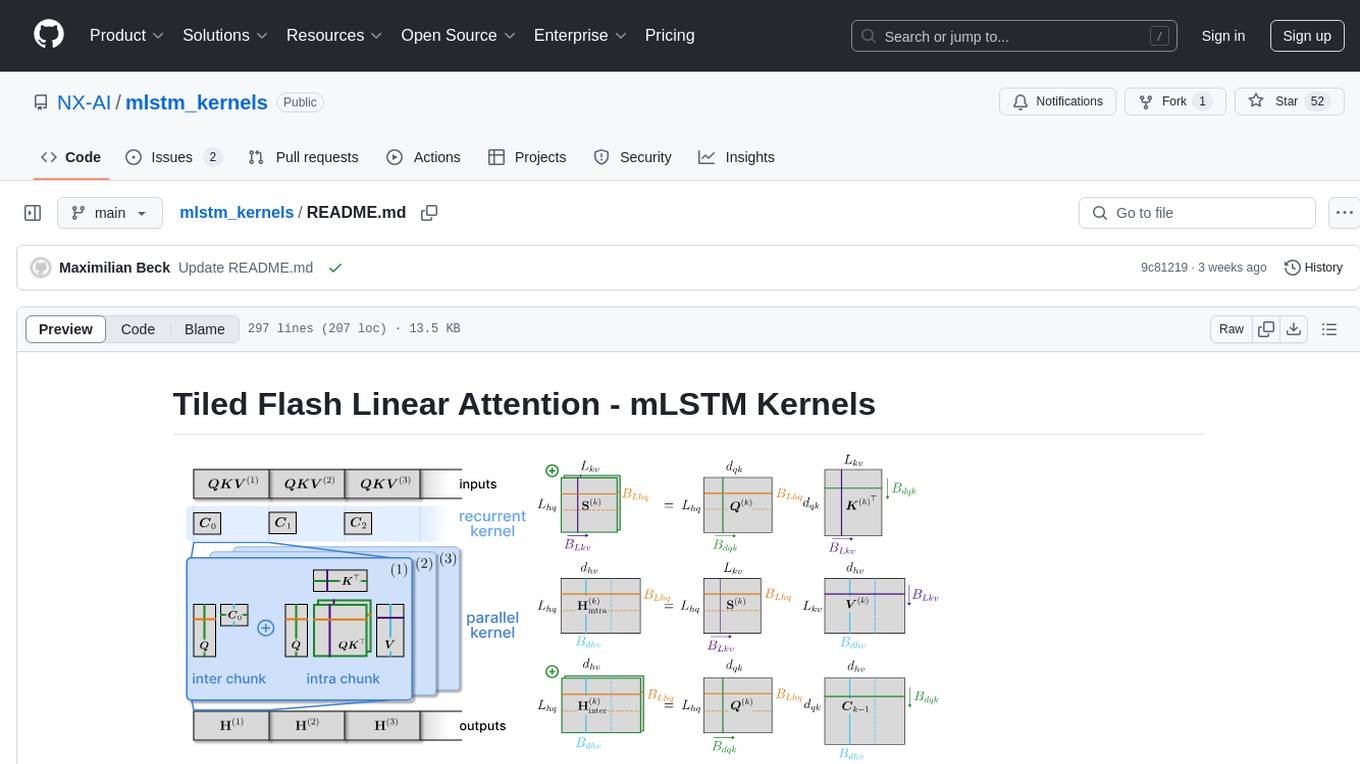
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.
MiniAgents
MiniAgents is an open-source Python framework designed to simplify the creation of multi-agent AI systems. It offers a parallelism and async-first design, allowing users to focus on building intelligent agents while handling concurrency challenges. The framework, built on asyncio, supports LLM-based applications with immutable messages and seamless asynchronous token and message streaming between agents.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.
kvpress
This repository implements multiple key-value cache pruning methods and benchmarks using transformers, aiming to simplify the development of new methods for researchers and developers in the field of long-context language models. It provides a set of 'presses' that compress the cache during the pre-filling phase, with each press having a compression ratio attribute. The repository includes various training-free presses, special presses, and supports KV cache quantization. Users can contribute new presses and evaluate the performance of different presses on long-context datasets.
avatar
AvaTaR is a novel and automatic framework that optimizes an LLM agent to effectively use provided tools and improve performance on a given task/domain. It designs a comparator module to provide insightful prompts to the LLM agent via reasoning between positive and negative examples from training data.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.
ellmer
ellmer is a tool that facilitates the use of large language models (LLM) from R. It supports various LLM providers and offers features such as streaming outputs, tool/function calling, and structured data extraction. Users can interact with ellmer in different ways, including interactive chat console, interactive method call, and programmatic chat. The tool provides support for multiple model providers and offers recommendations for different use cases, such as exploration or organizational use.
aire
Aire is a modern Laravel form builder with a focus on expressive and beautiful code. It allows easy configuration of form components using fluent method calls or Blade components. Aire supports customization through config files and custom views, data binding with Eloquent models or arrays, method spoofing, CSRF token injection, server-side and client-side validation, and translations. It is designed to run on Laravel 5.8.28 and higher, with support for PHP 7.1 and higher. Aire is actively maintained and under consideration for additional features like read-only plain text, cross-browser support for custom checkboxes and radio buttons, support for Choices.js or similar libraries, improved file input handling, and better support for content prepending or appending to inputs.
mountain-goap
Mountain GOAP is a generic C# GOAP (Goal Oriented Action Planning) library for creating AI agents in games. It favors composition over inheritance, supports multiple weighted goals, and uses A* pathfinding to plan paths through sequential actions. The library includes concepts like agents, goals, actions, sensors, permutation selectors, cost callbacks, state mutators, state checkers, and a logger. It also features event handling for agent planning and execution. The project structure includes examples, API documentation, and internal classes for planning and execution.
For similar tasks
crb
CRB (Composable Runtime Blocks) is a unique framework that implements hybrid workloads by seamlessly combining synchronous and asynchronous activities, state machines, routines, the actor model, and supervisors. It is ideal for building massive applications and serves as a low-level framework for creating custom frameworks, such as AI-agents. The core idea is to ensure high compatibility among all blocks, enabling significant code reuse. The framework allows for the implementation of algorithms with complex branching, making it suitable for building large-scale applications or implementing complex workflows, such as AI pipelines. It provides flexibility in defining structures, implementing traits, and managing execution flow, allowing users to create robust and nonlinear algorithms easily.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.