
ai-accelerator
The AI Accelerator is a template project for setting up Red Hat OpenShift AI using GitOps
Stars: 56
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.
README:
Welcome to the AI Accelerator project source code. This project is designed to initialize an OpenShift cluster with a recommended set of operators and components that aid with training, deploying, serving and monitoring Machine Learning models.
This repo is intended to provide a core set of OpenShift features that would commonly be used for a Data Science environment, but can also be highly customized for specific scenarios. When starting out we recommend making a copy or a fork of this project on your Git based instance, since it utilizes the process of automating IT infrastructure using infrastructure as code and software development best practices such as Git, code review, and CI/CD - known as GitOps.
Once the initial components are deployed, several ArgoCD Application objects are created which are then used to install and manage the install of the operators on the cluster.

- Overview - what's inside this repository?
- Installation Guide - containing step by step instructions for executing this installation sequence on your cluster
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-accelerator
Similar Open Source Tools
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.
NeMo-Framework-Launcher
The NeMo Framework Launcher is a cloud-native tool designed for launching end-to-end NeMo Framework training jobs. It focuses on foundation model training for generative AI models, supporting large language model pretraining with techniques like model parallelism, tensor, pipeline, sequence, distributed optimizer, mixed precision training, and more. The tool scales to thousands of GPUs and can be used for training LLMs on trillions of tokens. It simplifies launching training jobs on cloud service providers or on-prem clusters, generating submission scripts, organizing job results, and supporting various model operations like fine-tuning, evaluation, export, and deployment.
aily-blockly
Aily Blockly is a blockly IDE under the Aily Project, providing AI-assisted programming capabilities for non-professional users. It aims to integrate numerous AI capabilities to help hardware developers develop more smoothly, ultimately achieving natural language programming. The software offers features like Engineering Project Management, Library Manager, Serial Debug Tool, AI Project Generation, AI Code Generation, AI Library Conversion, Development Board Configuration Generation, and Lightning Compilation Tool. It is currently in the alpha stage, suitable for prototype verification and educational teaching.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.
holoscan-sdk
The Holoscan SDK is part of NVIDIA Holoscan, the AI sensor processing platform that combines hardware systems for low-latency sensor and network connectivity, optimized libraries for data processing and AI, and core microservices to run streaming, imaging, and other applications, from embedded to edge to cloud. It can be used to build streaming AI pipelines for a variety of domains, including Medical Devices, High Performance Computing at the Edge, Industrial Inspection and more.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
ais-k8s
AIStore on Kubernetes is a toolkit for deploying a lightweight, scalable object storage solution designed for AI applications in a Kubernetes environment. It includes documentation, Ansible playbooks, Kubernetes operator, Helm charts, and Terraform definitions for deployment on public cloud platforms. The system overview shows deployment across nodes with proxy and target pods utilizing Persistent Volumes. The AIStore Operator automates cluster management tasks. The repository focuses on production deployments but offers different deployment options. Thorough planning and configuration decisions are essential for successful multi-node deployment. The AIStore Operator simplifies tasks like starting, deploying, adjusting size, and updating AIStore resources within Kubernetes.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.

llmariner
LLMariner is an extensible open source platform built on Kubernetes to simplify the management of generative AI workloads. It enables efficient handling of training and inference data within clusters, with OpenAI-compatible APIs for seamless integration with a wide range of AI-driven applications.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
aihwkit
The IBM Analog Hardware Acceleration Kit is an open-source Python toolkit for exploring and using the capabilities of in-memory computing devices in the context of artificial intelligence. It consists of two main components: Pytorch integration and Analog devices simulator. The Pytorch integration provides a series of primitives and features that allow using the toolkit within PyTorch, including analog neural network modules, analog training using torch training workflow, and analog inference using torch inference workflow. The Analog devices simulator is a high-performant (CUDA-capable) C++ simulator that allows for simulating a wide range of analog devices and crossbar configurations by using abstract functional models of material characteristics with adjustable parameters. Along with the two main components, the toolkit includes other functionalities such as a library of device presets, a module for executing high-level use cases, a utility to automatically convert a downloaded model to its equivalent Analog model, and integration with the AIHW Composer platform. The toolkit is currently in beta and under active development, and users are advised to be mindful of potential issues and keep an eye for improvements, new features, and bug fixes in upcoming versions.
knavigator
Knavigator is a project designed to analyze, optimize, and compare scheduling systems, with a focus on AI/ML workloads. It addresses various needs, including testing, troubleshooting, benchmarking, chaos engineering, performance analysis, and optimization. Knavigator interfaces with Kubernetes clusters to manage tasks such as manipulating with Kubernetes objects, evaluating PromQL queries, as well as executing specific operations. It can operate both outside and inside a Kubernetes cluster, leveraging the Kubernetes API for task management. To facilitate large-scale experiments without the overhead of running actual user workloads, Knavigator utilizes KWOK for creating virtual nodes in extensive clusters.

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.
video-search-and-summarization
The NVIDIA AI Blueprint for Video Search and Summarization is a repository showcasing video search and summarization agent with NVIDIA NIM microservices. It enables industries to make better decisions faster by providing insightful, accurate, and interactive video analytics AI agents. These agents can perform tasks like video summarization and visual question-answering, unlocking new application possibilities. The repository includes software components like NIM microservices, ingestion pipeline, and CA-RAG module, offering a comprehensive solution for analyzing and summarizing large volumes of video data. The target audience includes video analysts, IT engineers, and GenAI developers who can benefit from the blueprint's 1-click deployment steps, easy-to-manage configurations, and customization options. The repository structure overview includes directories for deployment, source code, and training notebooks, along with documentation for detailed instructions. Hardware requirements vary based on deployment topology and dependencies like VLM and LLM, with different deployment methods such as Launchable Deployment, Docker Compose Deployment, and Helm Chart Deployment provided for various use cases.
For similar tasks
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
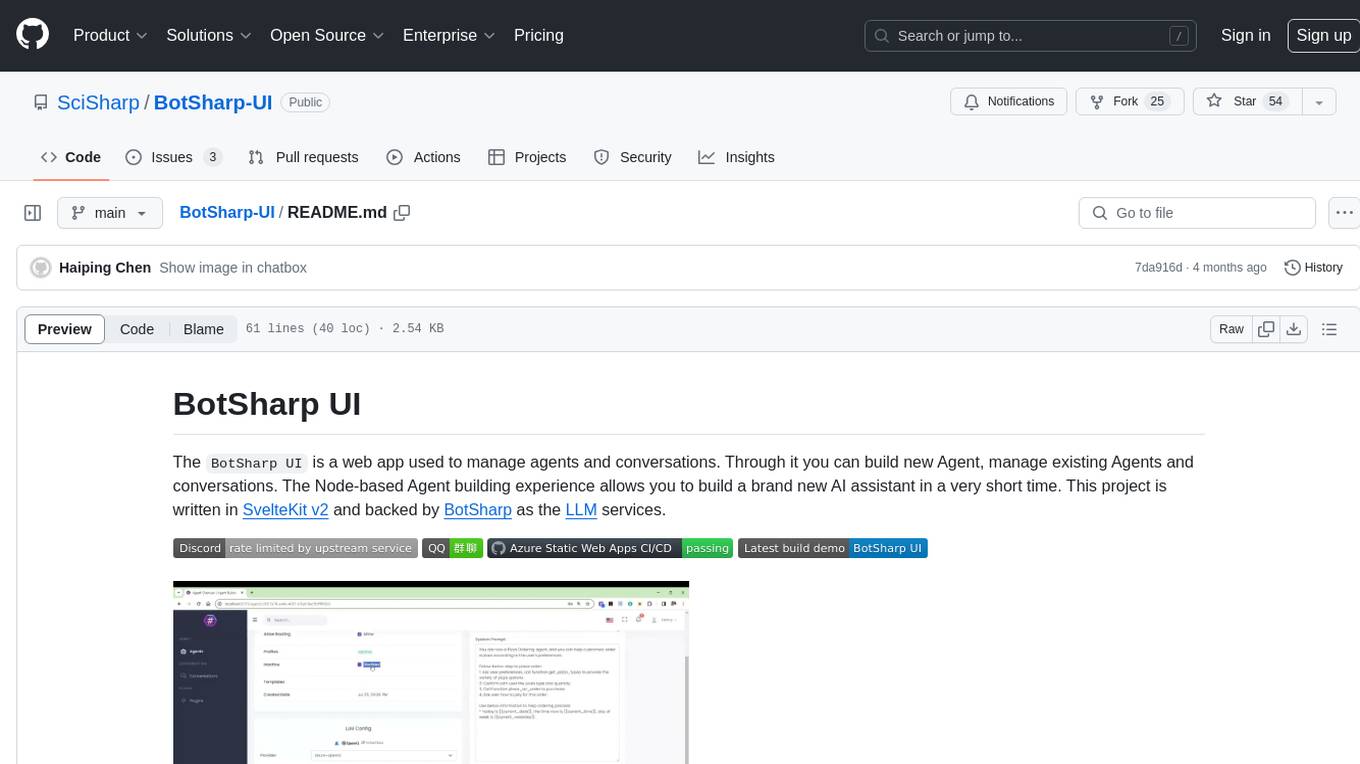
BotSharp-UI
BotSharp UI is a web app for managing agents and conversations. It allows users to build new AI assistants quickly using a Node-based Agent building experience. The project is written in SvelteKit v2 and utilizes BotSharp as the LLM services.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
For similar jobs
llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.