
foul-play
A Pokemon Showdown Battle Bot
Stars: 272
Foul Play is a Pokémon battle-bot that can play single battles in all generations on Pokemon Showdown. It requires Python 3.10+. The bot uses environment variables for configuration and supports different game modes and battle strategies. Users can specify teams and choose between algorithms like Monte-Carlo Tree Search and Expectiminimax. Foul Play can be run locally or with Docker, and the engine used for battles must be built from source. The tool provides flexibility in gameplay and strategy for Pokémon battles.
README:

A Pokémon battle-bot that can play battles on Pokemon Showdown.
Foul Play can play single battles in all generations though currently dynamax, mega-evolutions, and z-moves are not supported.
![]()
Requires Python 3.10+.
Environment variables are used for configuration. You may either set these in your environment before running, or populate them in the env file.
The configurations available are:
| Config Name | Type | Required | Description |
|---|---|---|---|
BATTLE_BOT |
string | yes | The BattleBot to use. More on this below in the Battle Bots section |
WEBSOCKET_URI |
string | yes | The address to use to connect to the Pokemon Showdown websocket |
PS_USERNAME |
string | yes | Pokemon Showdown username |
PS_PASSWORD |
string | yes | Pokemon Showdown password |
PS_AVATAR |
string | yes | Pokemon Showdown avatar. e.g. lucas, dawn, etc. |
BOT_MODE |
string | yes | What to do after logging-in. Options are: - CHALLENGE_USER- SEARCH_LADDER - ACCEPT_CHALLENGE
|
POKEMON_MODE |
string | yes | The type of game this bot will play: gen8ou, gen7randombattle, etc. |
USER_TO_CHALLENGE |
string | only if BOT_MODE is CHALLENGE_USER
|
If BOT_MODE is CHALLENGE_USER, this is the name of the user to challenge |
SMOGON_STATS |
string | no | If set, use the smogon stats for this format instead of the ones defined by POKEMON_MODE. This is useful when POKEMON_MODE does not have a smogon stats page |
RUN_COUNT |
int | no | The number of games to play before quitting |
SEARCH_TIME_MS |
int | no | The amount of time to spend looking for a move in milliseconds. This applies to monte-carlo search, as well as expectiminimax when using iterative-deepening |
TEAM_NAME |
string | no | The name of the file that contains the team you want to use. More on this below in the Specifying Teams section. |
ROOM_NAME |
string | no | If BOT_MODE is ACCEPT_CHALLENGE, join this chatroom while waiting for a challenge. |
SAVE_REPLAY |
boolean | no | Whether or not to save replays of the battles (True / False) |
LOG_LEVEL |
string | no | The Python logging level for stdout logs (DEBUG, INFO, etc.) |
LOG_TO_FILE |
string | no | If True then DEBUG logs are written to a file in ./logs regardless of what LOG_LEVEL is set to. A new file is created per battle |
1. Clone
Clone the repository with git clone https://github.com/pmariglia/foul-play.git
2. Install Requirements
Install the requirements with pip install -r requirements.txt.
Note: Requires Rust to be installed on your machine to build the engine.
3. Configure your env file
Here is a sample:
BATTLE_BOT=safest
WEBSOCKET_URI=wss://sim3.psim.us/showdown/websocket
PS_USERNAME=MyUsername
PS_PASSWORD=MyPassword
BOT_MODE=SEARCH_LADDER
POKEMON_MODE=gen7randombattle
RUN_COUNT=1
4. Run
Run with python run.py
1. Clone the repository
git clone https://github.com/pmariglia/foul-play.git
2. Build the Docker image
Use the Makefile to build a Docker image
make dockeror for a specific generation:
make docker GEN=gen43. Run with an environment variable file
docker run --env-file env foul-play:latest
This project uses poke-engine to search through battles. See the engine docs for more information.
The engine must be built from source if installing locally so you must have rust installed on your machine.
It is common to want to re-install the engine for different generations of Pokémon.
pip will used cached .whl artifacts when installing packages
and cannot detect the --config-settings flag that was used to build the engine.
The following command will ensure that the engine is re-installed properly:
pip uninstall -y poke-engine && pip install -v --force-reinstall --no-cache-dir poke-engine --config-settings="build-args=--features poke-engine/<GENERATION> --no-default-features"Or using the Makefile:
make poke_engine GEN=<generation>For example, to re-install the engine for generation 4:
make poke_engine GEN=gen4The Battle Bot decides which algorithm to use to pick a move
use BATTLE_BOT=mcts
Uses poke-engine to perform a monte-carlo tree search to determine the best move to make.
use BATTLE_BOT=minimax
Uses poke-engine to perform an expectiminimax search and picks the move that minimizes the loss for the turn.
You can specify teams by setting the TEAM_NAME environment variable.
Examples can be found in teams/teams/.
Passing in a directory will cause a random team to be selected from that directory.
The path specified should be relative to teams/teams/.
Specify a file:
TEAM_NAME=gen8/ou/clef_sand
Specify a directory:
TEAM_NAME=gen8/ou
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for foul-play
Similar Open Source Tools
foul-play
Foul Play is a Pokémon battle-bot that can play single battles in all generations on Pokemon Showdown. It requires Python 3.10+. The bot uses environment variables for configuration and supports different game modes and battle strategies. Users can specify teams and choose between algorithms like Monte-Carlo Tree Search and Expectiminimax. Foul Play can be run locally or with Docker, and the engine used for battles must be built from source. The tool provides flexibility in gameplay and strategy for Pokémon battles.
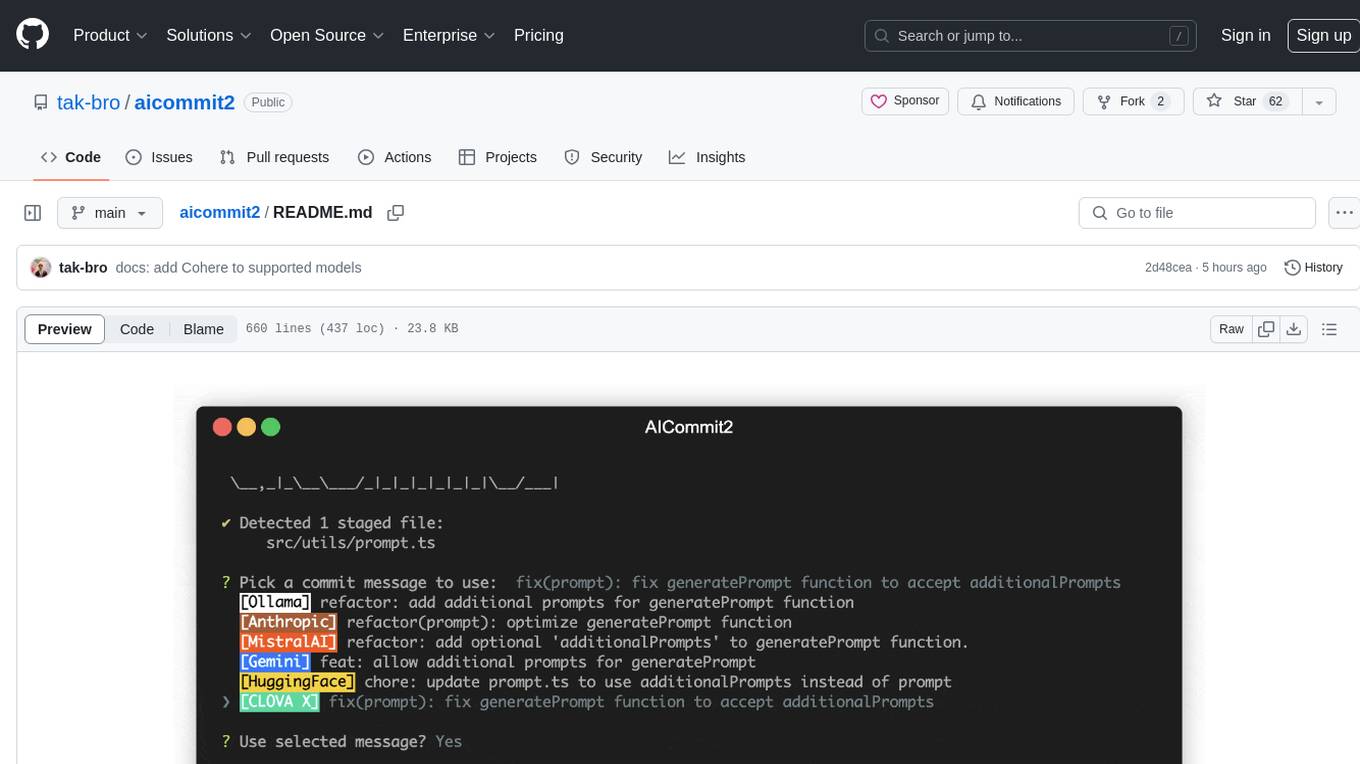
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
mcp-ts-template
The MCP TypeScript Server Template is a production-grade framework for building powerful and scalable Model Context Protocol servers with TypeScript. It features built-in observability, declarative tooling, robust error handling, and a modular, DI-driven architecture. The template is designed to be AI-agent-friendly, providing detailed rules and guidance for developers to adhere to best practices. It enforces architectural principles like 'Logic Throws, Handler Catches' pattern, full-stack observability, declarative components, and dependency injection for decoupling. The project structure includes directories for configuration, container setup, server resources, services, storage, utilities, tests, and more. Configuration is done via environment variables, and key scripts are available for development, testing, and publishing to the MCP Registry.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
airflow-chart
This Helm chart bootstraps an Airflow deployment on a Kubernetes cluster using the Helm package manager. The version of this chart does not correlate to any other component. Users should not expect feature parity between OSS airflow chart and the Astronomer airflow-chart for identical version numbers. To install this helm chart remotely (using helm 3) kubectl create namespace airflow helm repo add astronomer https://helm.astronomer.io helm install airflow --namespace airflow astronomer/airflow To install this repository from source sh kubectl create namespace airflow helm install --namespace airflow . Prerequisites: Kubernetes 1.12+ Helm 3.6+ PV provisioner support in the underlying infrastructure Installing the Chart: sh helm install --name my-release . The command deploys Airflow on the Kubernetes cluster in the default configuration. The Parameters section lists the parameters that can be configured during installation. Upgrading the Chart: First, look at the updating documentation to identify any backwards-incompatible changes. To upgrade the chart with the release name `my-release`: sh helm upgrade --name my-release . Uninstalling the Chart: To uninstall/delete the `my-release` deployment: sh helm delete my-release The command removes all the Kubernetes components associated with the chart and deletes the release. Updating DAGs: Bake DAGs in Docker image The recommended way to update your DAGs with this chart is to build a new docker image with the latest code (`docker build -t my-company/airflow:8a0da78 .`), push it to an accessible registry (`docker push my-company/airflow:8a0da78`), then update the Airflow pods with that image: sh helm upgrade my-release . --set images.airflow.repository=my-company/airflow --set images.airflow.tag=8a0da78 Docker Images: The Airflow image that are referenced as the default values in this chart are generated from this repository: https://github.com/astronomer/ap-airflow. Other non-airflow images used in this chart are generated from this repository: https://github.com/astronomer/ap-vendor. Parameters: The complete list of parameters supported by the community chart can be found on the Parameteres Reference page, and can be set under the `airflow` key in this chart. The following tables lists the configurable parameters of the Astronomer chart and their default values. | Parameter | Description | Default | | :----------------------------- | :-------------------------------------------------------------------------------------------------------- | :---------------------------- | | `ingress.enabled` | Enable Kubernetes Ingress support | `false` | | `ingress.acme` | Add acme annotations to Ingress object | `false` | | `ingress.tlsSecretName` | Name of secret that contains a TLS secret | `~` | | `ingress.webserverAnnotations` | Annotations added to Webserver Ingress object | `{}` | | `ingress.flowerAnnotations` | Annotations added to Flower Ingress object | `{}` | | `ingress.baseDomain` | Base domain for VHOSTs | `~` | | `ingress.auth.enabled` | Enable auth with Astronomer Platform | `true` | | `extraObjects` | Extra K8s Objects to deploy (these are passed through `tpl`). More about Extra Objects. | `[]` | | `sccEnabled` | Enable security context constraints required for OpenShift | `false` | | `authSidecar.enabled` | Enable authSidecar | `false` | | `authSidecar.repository` | The image for the auth sidecar proxy | `nginxinc/nginx-unprivileged` | | `authSidecar.tag` | The image tag for the auth sidecar proxy | `stable` | | `authSidecar.pullPolicy` | The K8s pullPolicy for the the auth sidecar proxy image | `IfNotPresent` | | `authSidecar.port` | The port the auth sidecar exposes | `8084` | | `gitSyncRelay.enabled` | Enables git sync relay feature. | `False` | | `gitSyncRelay.repo.url` | Upstream URL to the git repo to clone. | `~` | | `gitSyncRelay.repo.branch` | Branch of the upstream git repo to checkout. | `main` | | `gitSyncRelay.repo.depth` | How many revisions to check out. Leave as default `1` except in dev where history is needed. | `1` | | `gitSyncRelay.repo.wait` | Seconds to wait before pulling from the upstream remote. | `60` | | `gitSyncRelay.repo.subPath` | Path to the dags directory within the git repository. | `~` | Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example, sh helm install --name my-release --set executor=CeleryExecutor --set enablePodLaunching=false . Walkthrough using kind: Install kind, and create a cluster We recommend testing with Kubernetes 1.25+, example: sh kind create cluster --image kindest/node:v1.25.11 Confirm it's up: sh kubectl cluster-info --context kind-kind Add Astronomer's Helm repo sh helm repo add astronomer https://helm.astronomer.io helm repo update Create namespace + install the chart sh kubectl create namespace airflow helm install airflow -n airflow astronomer/airflow It may take a few minutes. Confirm the pods are up: sh kubectl get pods --all-namespaces helm list -n airflow Run `kubectl port-forward svc/airflow-webserver 8080:8080 -n airflow` to port-forward the Airflow UI to http://localhost:8080/ to confirm Airflow is working. Login as _admin_ and password _admin_. Build a Docker image from your DAGs: 1. Start a project using astro-cli, which will generate a Dockerfile, and load your DAGs in. You can test locally before pushing to kind with `astro airflow start`. `sh mkdir my-airflow-project && cd my-airflow-project astro dev init` 2. Then build the image: `sh docker build -t my-dags:0.0.1 .` 3. Load the image into kind: `sh kind load docker-image my-dags:0.0.1` 4. Upgrade Helm deployment: sh helm upgrade airflow -n airflow --set images.airflow.repository=my-dags --set images.airflow.tag=0.0.1 astronomer/airflow Extra Objects: This chart can deploy extra Kubernetes objects (assuming the role used by Helm can manage them). For Astronomer Cloud and Enterprise, the role permissions can be found in the Commander role. yaml extraObjects: - apiVersion: batch/v1beta1 kind: CronJob metadata: name: "{{ .Release.Name }}-somejob" spec: schedule: "*/10 * * * *" concurrencyPolicy: Forbid jobTemplate: spec: template: spec: containers: - name: myjob image: ubuntu command: - echo args: - hello restartPolicy: OnFailure Contributing: Check out our contributing guide! License: Apache 2.0 with Commons Clause
chonkie
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
binary_ninja_mcp
This repository contains a Binary Ninja plugin, MCP server, and bridge that enables seamless integration of Binary Ninja's capabilities with your favorite LLM client. It provides real-time integration, AI assistance for reverse engineering, multi-binary support, and various MCP tools for tasks like decompiling functions, getting IL code, managing comments, renaming variables, and more.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.
llm2sh
llm2sh is a command-line utility that leverages Large Language Models (LLMs) to translate plain-language requests into shell commands. It provides a convenient way to interact with your system using natural language. The tool supports multiple LLMs for command generation, offers a customizable configuration file, YOLO mode for running commands without confirmation, and is easily extensible with new LLMs and system prompts. Users can set up API keys for OpenAI, Claude, Groq, and Cerebras to use the tool effectively. llm2sh does not store user data or command history, and it does not record or send telemetry by itself, but the LLM APIs may collect and store requests and responses for their purposes.

ps-fuzz
The Prompt Fuzzer is an open-source tool that helps you assess the security of your GenAI application's system prompt against various dynamic LLM-based attacks. It provides a security evaluation based on the outcome of these attack simulations, enabling you to strengthen your system prompt as needed. The Prompt Fuzzer dynamically tailors its tests to your application's unique configuration and domain. The Fuzzer also includes a Playground chat interface, giving you the chance to iteratively improve your system prompt, hardening it against a wide spectrum of generative AI attacks.

graphrag-visualizer
GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.
crssnt
crssnt is a tool that converts RSS/Atom feeds into LLM-friendly Markdown or JSON, simplifying integration of feed content into AI workflows. It supports LLM-optimized conversion, multiple output formats, feed aggregation, and Google Sheet support. Users can access various endpoints for feed conversion and Google Sheet processing, with query parameters for customization. The tool processes user-provided URLs transiently without storing feed data, and can be self-hosted as Firebase Cloud Functions. Contributions are welcome under the MIT License.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
For similar tasks
foul-play
Foul Play is a Pokémon battle-bot that can play single battles in all generations on Pokemon Showdown. It requires Python 3.10+. The bot uses environment variables for configuration and supports different game modes and battle strategies. Users can specify teams and choose between algorithms like Monte-Carlo Tree Search and Expectiminimax. Foul Play can be run locally or with Docker, and the engine used for battles must be built from source. The tool provides flexibility in gameplay and strategy for Pokémon battles.
showdown
Showdown is a Pokémon battle-bot that can play battles on Pokemon Showdown. It can play single battles in generations 3 through 8. The project offers different battle bot implementations such as Safest, Nash-Equilibrium, Team Datasets, and Most Damage. Users can configure the bot using environment variables and run it either without Docker by cloning the repository and installing requirements or with Docker by building the Docker image and running it with an environment variable file. Additionally, users can write their own bot by creating a package in showdown/battle_bots with a module named main.py and implementing a find_best_move function.
AI-Solana_Bot
MevBot Solana is an advanced trading bot for the Solana blockchain with an interactive and user-friendly interface. It offers features like scam token scanning, automatic network connection, and focus on trading $TRUMP and $MELANIA tokens. Users can set stop-loss and take-profit thresholds, filter tokens based on market cap, and configure purchase amounts. The bot requires a starting balance of at least 3 SOL for optimal performance. It can be managed through a main menu in VS Code and requires prerequisites like Git, Node.js, and VS Code for installation and usage.

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.
vasttools
This repository contains a collection of tools that can be used with vastai. The tools are free to use, modify and distribute. If you find this useful and wish to donate your welcome to send your donations to the following wallets. BTC 15qkQSYXP2BvpqJkbj2qsNFb6nd7FyVcou XMR 897VkA8sG6gh7yvrKrtvWningikPteojfSgGff3JAUs3cu7jxPDjhiAZRdcQSYPE2VGFVHAdirHqRZEpZsWyPiNK6XPQKAg RVN RSgWs9Co8nQeyPqQAAqHkHhc5ykXyoMDUp USDT(ETH ERC20) 0xa5955cf9fe7af53bcaa1d2404e2b17a1f28aac4f Paypal PayPal.Me/cryptolabsZA

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.
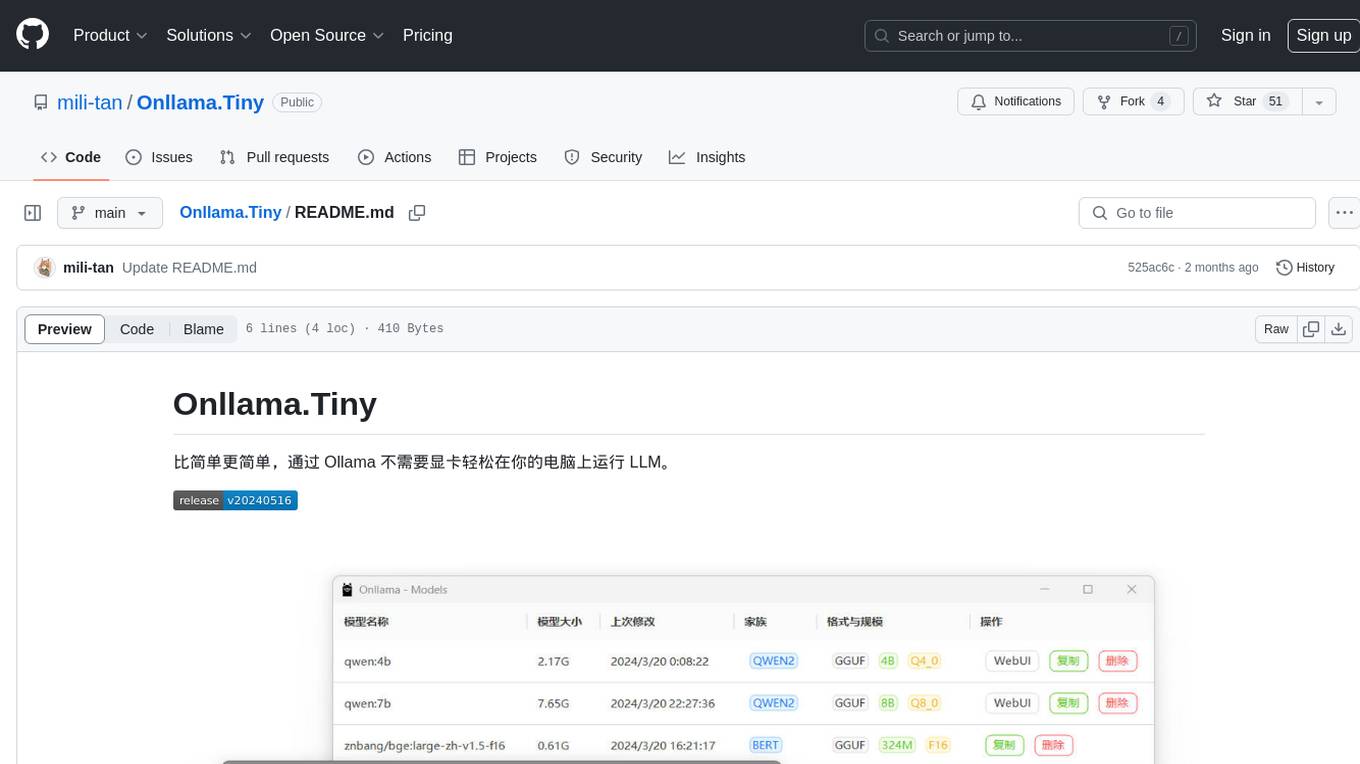
Onllama.Tiny
Onllama.Tiny is a lightweight tool that allows you to easily run LLM on your computer without the need for a dedicated graphics card. It simplifies the process of running LLM, making it more accessible for users. The tool provides a user-friendly interface and streamlines the setup and configuration required to run LLM on your machine. With Onllama.Tiny, users can quickly set up and start using LLM for various applications and projects.
OnAIR
The On-board Artificial Intelligence Research (OnAIR) Platform is a framework that enables AI algorithms written in Python to interact with NASA's cFS. It is intended to explore research concepts in autonomous operations in a simulated environment. The platform provides tools for generating environments, handling telemetry data through Redis, running unit tests, and contributing to the repository. Users can set up a conda environment, configure telemetry and Redis examples, run simulations, and conduct unit tests to ensure the functionality of their AI algorithms. The platform also includes guidelines for licensing, copyright, and contributions to the repository.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.