
graphrag-visualizer
A web-based tool for visualizing and exploring artifacts from Microsoft's GraphRAG.
Stars: 301

GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.
README:
👉 GraphRAG Visualizer
👉 GraphRAG Visualizer Demo

GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts. By uploading parquet files generated from the GraphRAG indexing pipeline, users can easily view and analyze data without needing additional software or scripts.
If you are using GraphRAG 0.3.x or below, please use the legacy version of GraphRAG Visualizer available at:
👉 GraphRAG Visualizer Legacy
- Graph Visualization: View the graph in 2D or 3D in the "Graph Visualization" tab.
- Data Tables: Display data from the parquet files in the "Data Tables" tab.
- Search Functionality: Fully supports search, allowing users to focus on specific nodes or relationships.
- Local Processing: All artifacts are processed locally on your machine, ensuring data security and privacy.
Once the graphrag-api server is up and running, you can perform searches directly through the GraphRAG Visualizer. Simply go to the GraphRAG Visualizer and use the search interface to query the API server. This allows you to easily search and explore data that is hosted on your local server.

The logic for creating relationships for text units, documents, communities, and covariates is derived from the GraphRAG import Neo4j Cypher notebook.
| Node | Type |
|---|---|
| Document | RAW_DOCUMENT |
| Text Unit | CHUNK |
| Community | COMMUNITY |
| Finding | FINDING |
| Covariate | COVARIATE |
| Entity | Varies |
| Source Node | Relationship | Target Node |
|---|---|---|
| Entity | RELATED |
Entity |
| Text Unit | PART_OF |
Document |
| Text Unit | HAS_ENTITY |
Entity |
| Text Unit | HAS_COVARIATE |
Covariate |
| Community | HAS_FINDING |
Finding |
| Entity | IN_COMMUNITY |
Community |
-
Clone the repository to your local machine:
git clone https://github.com/noworneverev/graphrag-visualizer.git cd graphrag-visualizer -
Install the necessary dependencies:
npm install
-
Run the development server:
npm start
-
Open the app in your browser:
http://localhost:3000
To load .parquet files automatically when the application starts, place your Parquet files in the public/artifacts directory. These files will be loaded into the application for visualization and data table display. The files can be organized as follows:
-
GraphRAG v2.x.x
public/artifacts/entities.parquetpublic/artifacts/relationships.parquetpublic/artifacts/documents.parquetpublic/artifacts/text_units.parquetpublic/artifacts/communities.parquetpublic/artifacts/community_reports.parquetpublic/artifacts/covariates.parquet
-
GraphRAG v1.x.x
public/artifacts/create_final_entities.parquetpublic/artifacts/create_final_relationships.parquetpublic/artifacts/create_final_documents.parquetpublic/artifacts/create_final_text_units.parquetpublic/artifacts/create_final_communities.parquetpublic/artifacts/create_final_community_reports.parquetpublic/artifacts/create_final_covariates.parquet
If the files are placed in the public/artifacts folder, the app will automatically load and display them on startup.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for graphrag-visualizer
Similar Open Source Tools
graphrag-visualizer
GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.

wa_llm
WhatsApp Group Summary Bot is an AI-powered tool that joins WhatsApp groups, tracks conversations, and generates intelligent summaries. It features automated group chat responses, LLM-based conversation summaries, knowledge base integration, persistent message history with PostgreSQL, support for multiple message types, group management, and a REST API with Swagger docs. Prerequisites include Docker, Python 3.12+, PostgreSQL with pgvector extension, Voyage AI API key, and a WhatsApp account for the bot. The tool can be quickly set up by cloning the repository, configuring environment variables, starting services, and connecting devices. It offers API usage for loading new knowledge base topics and generating & dispatching summaries to managed groups. The project architecture includes FastAPI backend, WhatsApp Web API client, PostgreSQL database with vector storage, and AI-powered message processing.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
chonkie
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
ovos-installer
The ovos-installer is a simple and multilingual tool designed to install Open Voice OS and HiveMind using Bash, Whiptail, and Ansible. It supports various Linux distributions and provides an automated installation process. Users can easily start and stop services, update their Open Voice OS instance, and uninstall the tool if needed. The installer also allows for non-interactive installation through scenario files. It offers a user-friendly way to set up Open Voice OS on different systems.
agentic
Agentic is a standard AI functions/tools library optimized for TypeScript and LLM-based apps, compatible with major AI SDKs. It offers a set of thoroughly tested AI functions that can be used with favorite AI SDKs without writing glue code. The library includes various clients for services like Bing web search, calculator, Clearbit data resolution, Dexa podcast questions, and more. It also provides compound tools like SearchAndCrawl and supports multiple AI SDKs such as OpenAI, Vercel AI SDK, LangChain, LlamaIndex, Firebase Genkit, and Dexa Dexter. The goal is to create minimal clients with strongly-typed TypeScript DX, composable AIFunctions via AIFunctionSet, and compatibility with major TS AI SDKs.

TPI-LLM
TPI-LLM (Tensor Parallelism Inference for Large Language Models) is a system designed to bring LLM functions to low-resource edge devices, addressing privacy concerns by enabling LLM inference on edge devices with limited resources. It leverages multiple edge devices for inference through tensor parallelism and a sliding window memory scheduler to minimize memory usage. TPI-LLM demonstrates significant improvements in TTFT and token latency compared to other models, and plans to support infinitely large models with low token latency in the future.
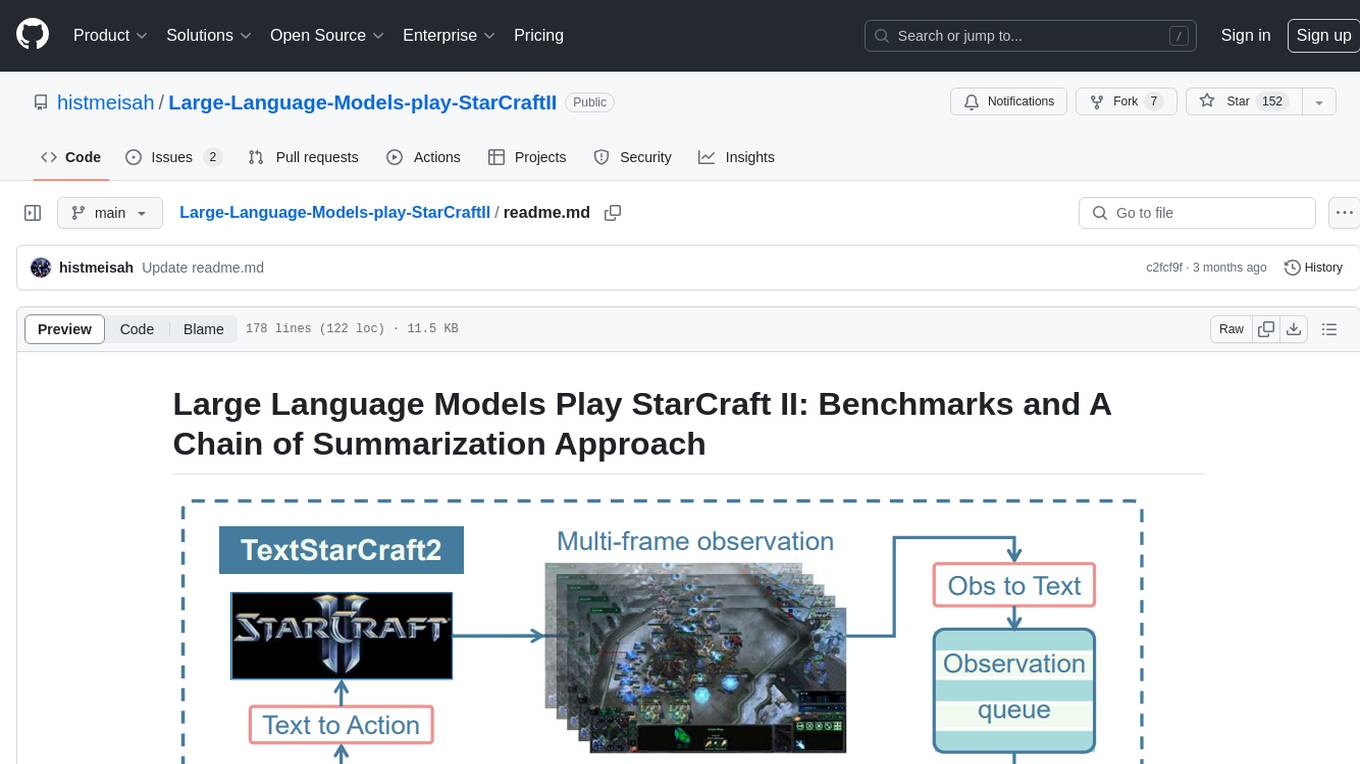
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.
rpaframework
RPA Framework is an open-source collection of libraries and tools for Robotic Process Automation (RPA), designed to be used with Robot Framework and Python. It offers well-documented core libraries for Software Robot Developers, optimized for Robocorp Control Room and Developer Tools, and accepts external contributions. The project includes various libraries for tasks like archiving, browser automation, date/time manipulations, cloud services integration, encryption operations, database interactions, desktop automation, document processing, email operations, Excel manipulation, file system operations, FTP interactions, web API interactions, image manipulation, AI services, and more. The development of the repository is Python-based and requires Python version 3.8+, with tooling based on poetry and invoke for compiling, building, and running the package. The project is licensed under the Apache License 2.0.
cortex.cpp
Cortex.cpp is an open-source platform designed as the brain for robots, offering functionalities such as vision, speech, language, tabular data processing, and action. It provides an AI platform for running AI models with multi-engine support, hardware optimization with automatic GPU detection, and an OpenAI-compatible API. Users can download models from the Hugging Face model hub, run models, manage resources, and access advanced features like multiple quantizations and engine management. The tool is under active development, promising rapid improvements for users.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
llm-structured-output-benchmarks
Benchmark various LLM Structured Output frameworks like Instructor, Mirascope, Langchain, LlamaIndex, Fructose, Marvin, Outlines, LMFormatEnforcer, etc on tasks like multi-label classification, named entity recognition, synthetic data generation. The tool provides benchmark results, methodology, instructions to run the benchmark, add new data, and add a new framework. It also includes a roadmap for framework-related tasks, contribution guidelines, citation information, and feedback request.
For similar tasks
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
graphrag-visualizer
GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.

client
DagsHub is a platform for machine learning and data science teams to build, manage, and collaborate on their projects. With DagsHub you can: 1. Version code, data, and models in one place. Use the free provided DagsHub storage or connect it to your cloud storage 2. Track Experiments using Git, DVC or MLflow, to provide a fully reproducible environment 3. Visualize pipelines, data, and notebooks in and interactive, diff-able, and dynamic way 4. Label your data directly on the platform using Label Studio 5. Share your work with your team members 6. Stream and upload your data in an intuitive and easy way, while preserving versioning and structure. DagsHub is built firmly around open, standard formats for your project. In particular: * Git * DVC * MLflow * Label Studio * Standard data formats like YAML, JSON, CSV Therefore, you can work with DagsHub regardless of your chosen programming language or frameworks.
SQLAgent
DataAgent is a multi-agent system for data analysis, capable of understanding data development and data analysis requirements, understanding data, and generating SQL and Python code for tasks such as data query, data visualization, and machine learning.
google-research
This repository contains code released by Google Research. All datasets in this repository are released under the CC BY 4.0 International license, which can be found here: https://creativecommons.org/licenses/by/4.0/legalcode. All source files in this repository are released under the Apache 2.0 license, the text of which can be found in the LICENSE file.
airda
airda(Air Data Agent) is a multi-agent system for data analysis, which can understand data development and data analysis requirements, understand data, and generate SQL and Python code for data query, data visualization, machine learning and other tasks.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.