
verifAI
VerifAI initiative to build open-source easy-to-deploy generative question-answering engine that can reference and verify answers for correctness (using posteriori model)
Stars: 54

VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.
README:





VerifAI is a Generative Search/Productivity engine with Verifiable answers. Please check our website https://verifai-project.com/, or deployed app at https://app.verifai-project.com/
No more searches, just verifiably accurate answers.
- Project Description
- Main Features
- Support This Project
- Installation and Start-up
- Developed Models and Datasets
- Using our APP
- Collaborators and Contributions
- Papers and Citations
- Funding
VerifAI is a document-based question-answering systems that aims to address problem of hallucinations in generative large language models and generative search engines. Initially, we started with biomedical domain, however, now we have expanded VerifAI to support indexing any documents in txt,md, docx, pptx, or pdf formats.
VerifAI is an AI system designed to answer users' questions by retrieving the most relevant documents, generate answer with references to the relevant documents and verify that the generated answer does not contain any hallucinations. In the core of the engine is generative search engine, powered by open technologies. However, generative models may hallucinate, and therefore VerifAI is developed a second model that would check the sources of generative model and flag any misinformation or misinterpretations of source documents. Therefore, make the answer created by generative search engine completly verifiable.
The best part is, that we are making it open source, so anyone can use it!
Check the article about VerifAI project published on TowardsDataScience
How does it work:


- Easy installation by running a single script
- Easy indexing of local files in PDF,EPUB, PPTX, DOCX, MD and TXT formats
- Combination of lexical and semantic search to find the most relevant documents
- Usage of any HuggingFace listed model for document embeddings
- Usage of any LLM that follows OpenAI API standard (deployed using vLLM, Nvidia NIM, Ollama, or via commercial APIs, such as OpenAI, Azure)
- Supports large amounts of indexed documents (tested with over 200GB of data and 30 million documents)
- Shows the closest sentence in the document to the generated claim
- User registration and log-in
- Pleasent user interface developed in React.js
- Verification that generated text does not contain hallucinations by a specially fine-tuned model
- Possible single-sign-on with AzureAD (future plans to add other services, e.g. Google, GitHub, etc.)
If you find this project helpful or interesting, please consider giving it a star on GitHub! Your support helps make this project more visible to others who might benefit from it.

By starring this repository, you'll also stay updated on new features and improvements. Thank you for your support! 🙏
- Clone the repository or download latest release
- Create virtual python environment by running:
python -m venv verifai
source verifai/bin/activate- In case you get errors with installing psycopg2, you may need to install postgres by running
sudo apt install postgresql-server-dev-all - On a clean instance you may need to run:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt update
- Run requirements.txt by running
pip install -r backend/requirements.txt - Configure system, by replacing and modifying
.env.local.examplein backend folder and rename it into just.env: The configuration should look in the following manner:
SECRET_KEY=6183db7b3c4f67439ad61d1b798224a035fe35c4113bf870
ALGORITHM=HS256
DBNAME=verifai_database
USER_DB=myuser
PASSWORD_DB=mypassword
HOST_DB=localhost
OPENSEARCH_IP=localhost
OPENSEARCH_USER=admin
OPENSEARCH_PASSWORD=admin
OPENSEARCH_PORT=9200
OPENSEARCH_USE_SSL=False
QDRANT_IP=localhost
QDRANT_PORT=6333
QDRANT_API=8da7725d78141e19a9bf3d878f4cb333fedb56eed9727904b46ce4b32e1ce085
QDRANT_USE_SSL=False
OPENAI_PATH=<path-to-openai/azure/vllm/nvidia_nim/ollama-interface>
OPENAI_KEY=<key-in-interface>
DEPLOYMENT_MODEL=GPT4o
MAX_CONTEXT_LENGTH=128000
SIMILARITY_METRIC=DOT
VECTOR_SIZE=768
EMBEDDING_MODEL="sentence-transformers/msmarco-bert-base-dot-v5"
INDEX_NAME_LEXICAL = 'myindex-lexical'
INDEX_NAME_SEMANTIC = "myindex-semantic"
USE_VERIFICATION=True
Please note that value of SIMILARITY_METRIC can be either DOT (dot product) or COSINE (cosine similarity). If not stated, it will resolve to Cosine similarity.
- Run install_datastores.py file. To run this file, it is necessary to install Docker (and run the daemon). This file is designed to install necessary components, such as OpenSearch, Qdrant and PostgreSQL, as well as to create database in PostgreSQL.
python install_datastore.py- Index your files, by running index_files.py and pointing it to the directory with files you would like to index. It will recuresevly index all files in the directory.
python index_files.py <path-to-directory-with-files>As an example, we have created a folder with some example files in the folder test_data. You can index them by running:
python index_files.py test_data- Run the backend of VerifAI by running
main.pyin the backend folder.
python main.py- Install React by following this guide, or by running following commands:
sudo apt update
sudo apt install nodejs npm
sudo npm install -g create-react-app
- Install React requirements for the front-end in
client-gui/verifai-uifolder and run front end:
cd ..
cd client-gui/verifai-ui
npm installCreate .env file in the client-gui/verifai-ui folder with the following content (or based on .env.example file):
REACT_APP_BACKEND = http://127.0.0.1:5001/ # or your API url
REACT_APP_AZURE_CLIENT_ID=<your_azure_client_id>
REACT_APP_AZURE_TENANT_ID=<your_azure_tenant_id>
REACT_APP_AZURE_REDIRECT_URL=http://localhost:3000
If you do not configure REACT_APP_AZURE_CLIENT_ID and REACT_APP_AZURE_TENANT_ID, the app will not have the option to log in with AzureAD. Your AzureAD application needs to be registered as Single-Page Application in Azure. Change REACT_APP_AZURE_REDIRECT_URL to the redirect URL matching one in Azure.
Start the app by running:
npm start- Go to
http://localhost:3000to see the VerifAI in action.
You can check a tutorial on deploying VerifAI published on Towards Data Science
This is biomedical version of VerifAI. It is designed to answer questions from the biomedical domain.
One requirement to run locally is to have installed Postgres SQL. You can install it for example on mac by running brew install postgresql.
- Clone the repository
- Run requirements.txt by running
pip install -r backend/requirements.txt - Download Medline. You can do it by executing
download_medline_data.shfor core files for the current year anddownload_medline_data_update.shfor Medline current update files. - Install Qdrant following the guide here
- Run the script:
python medline2json.pyto transform MEDLINE XML files into JSON - Run
python json2selected.pyto selects the fields that should be inported into the index - Run
python abstarct_parser.pyto concatinate abstract titles and abstracts and splits texts to 512 parts that can be indexed using a transformer model - Run
python embeddings_creation.pyto create embeddings. - Run
python scripts/indexing_qdrant.pyto create qdrant index. Make sure to point to the right folder created in the previous step and to the qdrant instance. - Install OpenSearch following the guide here
- Create OpenSearch index by running
python scripts/indexing_lexical_pmid.py. Make sure to configure access to the OpenSearch and point the path variable to the folder created by json2selected script. - Set up system variables that are needed for the project. You can do it by creating
.envfile with the following content:
OPENSEARCH_IP=open_search_ip
OPENSEARCH_USER=open_search_user
OPENSEARCH_PASSWORD=open_search_pass
OPENSEARCH_PORT=9200
QDRANT_IP=qdrant_ip
QDRANT_PORT=qdrant_port
QDRANT_API=qdrant_api_key
QDRANT_USE_SSL=False
OPENSEARCH_USE_SSL=False
MAX_CONTEXT_LENGTH=32000
EMBEDDING_MODEL="sentence-transformers/msmarco-bert-base-dot-v5"
INDEX_NAME_LEXICAL = 'medline-faiss-hnsw-lexical-pmid'
INDEX_NAME_SEMANTIC = "medline-faiss-hnsw"
USE_VERIFICATION=True
- Run backend by running
python backend/main.py - Install React by following this guide
- Run
npm run-script build - Run frontend by running
npm startin client-gui/verifai-ui
- Fine tuned QLoRA addapted for Mistral 7B-instruct v01
- Fine tuned QLoRA addapted for Mistral 7B-instruct v02
- PQAref dataset
- Verification model based on DeBERTa, fine-tuned on SciFact dataset
You can use our app here. You need to create a free account by clicking on Join now.
Currently, two institutions are the main drivers of this project, namely Bayer A.G and Institute for Artificial Intelligence Research and Development of Serbia. Current contrbiutors are by institutions
- Bayer A.G.
- Nikola Milosevic
- Lorenzo Cassano
- Institute for Artificial Intelligence Research and Development of Serbia:
- Adela Ljajic
- Milos Kosprdic
- Bojana Basaragin
- Darija Medvecki
- Angela Pupovac
- Nataša Radmilović
- Petar Stevanović
We welcome contribution to this project by anyone interested in participating. This is an open source project under AGPL license. In order to prevent any legal issues, before sending the first pull request, we ask potential contributors to sign Individual Contributor Agreement and send to us via email ([email protected]).
- Adela Ljajić, Miloš Košprdić, Bojana Bašaragin, Darija Medvecki, Lorenzo Cassano, Nikola Milošević, “Scientific QA System with Verifiable Answers”, The 6th International Open Search Symposium 2024
- Košprdić, M., Ljajić, A., Bašaragin, B., Medvecki, D., & Milošević, N. "Verif. ai: Towards an Open-Source Scientific Generative Question-Answering System with Referenced and Verifiable Answers." The Sixteenth International Conference on Evolving Internet INTERNET 2024 (2024).
- Bojana Bašaragin, Adela Ljajić, Darija Medvecki, Lorenzo Cassano, Miloš Košprdić, Nikola Milošević "How do you know that? Teaching Generative Language Models to Reference Answers to Biomedical Questions", Accepted at BioNLP 2024, Colocated with ACL 2024
- Adela Ljajić, Lorenzo Cassano, Miloš Košprdić, Bašaragin Bojana, Darija Medvecki, Nikola Milošević, "Enhancing Biomedical Information Retrieval with Semantic Search: A Comparative Analysis Using PubMed Data", Belgrade Bioinformatics Conference BelBi2024, 2024
- Košprdić, M.; Ljajić, A.; Medvecki, D.; Bašaragin, B. and Milošević, N. (2024). Scientific Claim Verification with Fine-Tuned NLI Models. In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management - KMIS; ISBN 978-989-758-716-0; ISSN 2184-3228, SciTePress, pages 15-25. DOI: 10.5220/0012900000003838
This project was in September 2023 funded by NGI Search project of the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or European Commission. Neither the European Union nor the granting authority can be held responsible for them. Funded within the framework of the NGI Search project under grant agreement No 101069364
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for verifAI
Similar Open Source Tools
verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

physical-AI-interpretability
Physical AI Interpretability is a toolkit for transformer-based Physical AI and robotics models, providing tools for attention mapping, feature extraction, and out-of-distribution detection. It includes methods for post-hoc attention analysis, applying Dictionary Learning into robotics, and training sparse autoencoders. The toolkit aims to enhance interpretability and understanding of AI models in physical environments.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
bionemo-framework
NVIDIA BioNeMo Framework is a collection of programming tools, libraries, and models for computational drug discovery. It accelerates building and adapting biomolecular AI models by providing domain-specific, optimized models and tooling for GPU-based computational resources. The framework offers comprehensive documentation and support for both community and enterprise users.
vscode-pddl
The vscode-pddl extension provides comprehensive support for Planning Domain Description Language (PDDL) in Visual Studio Code. It enables users to model planning domains, validate them, industrialize planning solutions, and run planners. The extension offers features like syntax highlighting, auto-completion, plan visualization, plan validation, plan happenings evaluation, search debugging, and integration with Planning.Domains. Users can create PDDL files, run planners, visualize plans, and debug search algorithms efficiently within VS Code.
agents
Polymarket Agents is a developer framework and set of utilities for building AI agents to trade autonomously on Polymarket. It integrates with Polymarket API, provides AI agent utilities for prediction markets, supports local and remote RAG, sources data from various services, and offers comprehensive LLM tools for prompt engineering. The architecture features modular components like APIs and scripts for managing local environments, server set-up, and CLI for end-user commands.

llm-memorization
The 'llm-memorization' project is a tool designed to index, archive, and search conversations with a local LLM using a SQLite database enriched with automatically extracted keywords. It aims to provide personalized context at the start of a conversation by adding memory information to the initial prompt. The tool automates queries from local LLM conversational management libraries, offers a hybrid search function, enhances prompts based on posed questions, and provides an all-in-one graphical user interface for data visualization. It supports both French and English conversations and prompts for bilingual use.
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
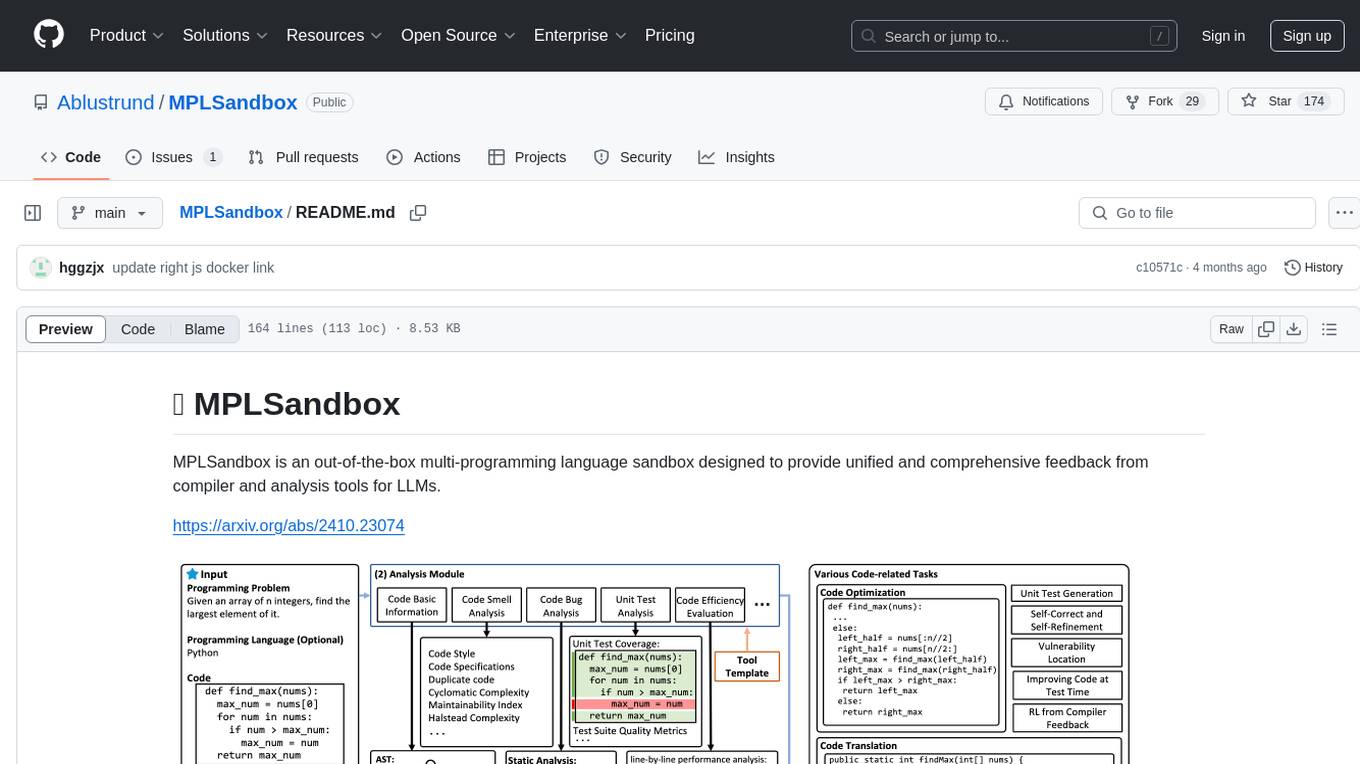
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.
ctakes
Apache cTAKES is a clinical Text Analysis and Knowledge Extraction System that focuses on extracting knowledge from clinical text through Natural Language Processing (NLP) techniques. It is modular and employs rule-based and machine learning methods to extract concepts such as symptoms, procedures, diagnoses, medications, and anatomy with attributes and standard codes. cTAKES can identify temporal events, dates, and times, placing events in a patient timeline. It supports various biomedical text processing tasks and can handle different types of clinical and health-related narratives using multiple data standards. cTAKES is widely used in research initiatives and encourages contributions from professionals, researchers, doctors, and students from diverse backgrounds.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
For similar tasks
verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.