
autoarena
Rank LLMs, RAG systems, and prompts using automated head-to-head evaluation
Stars: 65
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.
README:
Create leaderboards ranking LLM outputs against one another using automated judge evaluation





- 🏆 Rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of your system
- ⚔️ Perform automated head-to-head evaluation using judges from OpenAI, Anthropic, Cohere, and more
- 🤖 Define and run your own custom judges, connecting to internal services or implementing bespoke logic
- 💻 Run application locally, getting full control over your environment and data
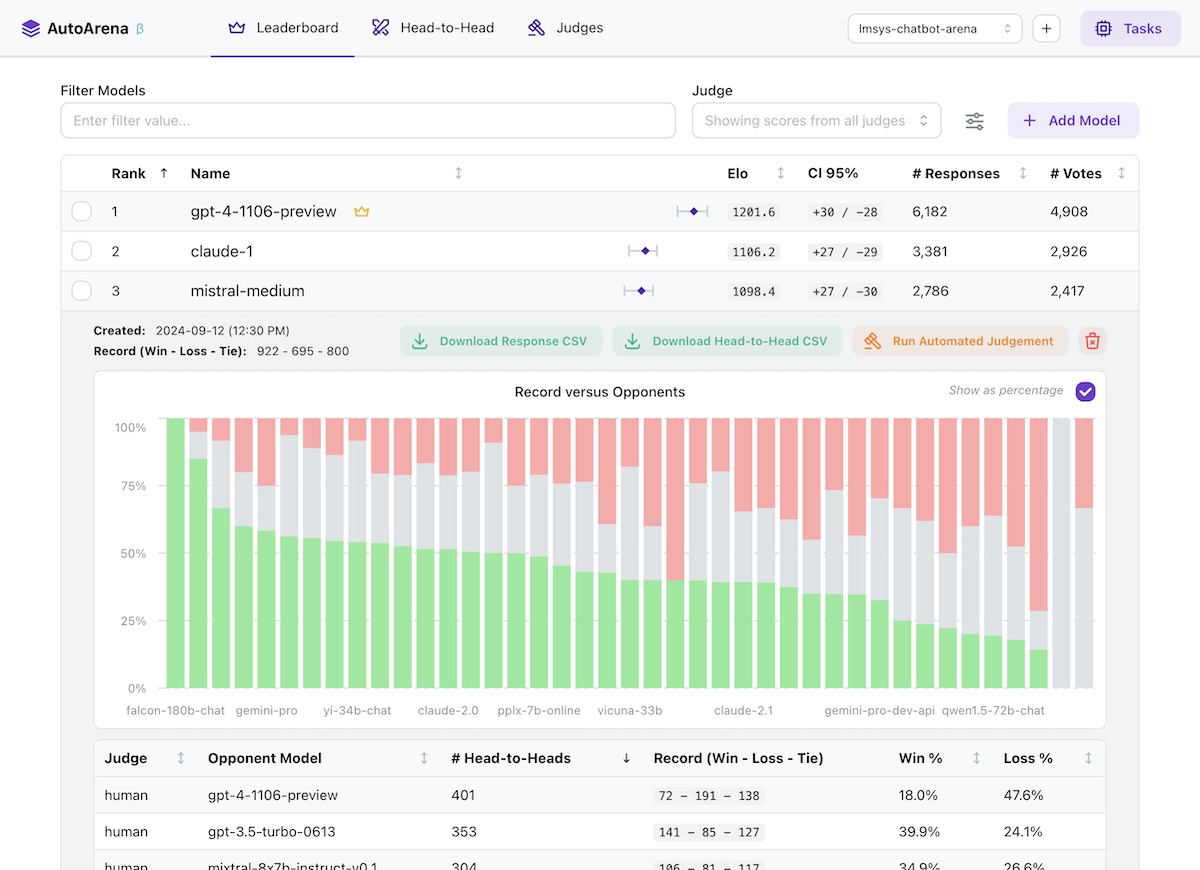
- LLMs are better at judging responses head-to-head than they are in isolation (arXiv:2408.08688) — leaderboard rankings computed using Elo scores from many automated side-by-side comparisons should be more trustworthy than leaderboards using metrics computed on each model's responses independently!
- The LMSYS Chatbot Arena has replaced benchmarks for many people as the trusted true leaderboard for foundation model performance (arXiv:2403.04132). Why not apply this approach to your own foundation model selection, RAG system setup, or prompt engineering efforts?
- Using a "jury" of multiple smaller models from different model families like
gpt-4o-mini,command-r, andclaude-3-haikugenerally yields better accuracy than a single frontier judge likegpt-4o— while being faster and much cheaper to run. AutoArena is built around this technique, called PoLL: Panel of LLM evaluators (arXiv:2404.18796). - Automated side-by-side comparison of model outputs is one of the most prevalent evaluation practices (arXiv:2402.10524) — AutoArena makes this process easier than ever to get up and running.
Install from PyPI:
pip install autoarenaRun as a module and visit localhost:8899 in your browser:
python -m autoarenaWith the application running, getting started is simple:
- Create a project via the UI.
- Add responses from a model by selecting a CSV file with
promptandresponsecolumns. - Configure an automated judge via the UI. Note that most judges require credentials, e.g.
X_API_KEYin the environment where you're running AutoArena. - Add responses from a second model to kick off an automated judging task using the judges you configured in the
previous step to decide which of the models you've uploaded provided a better
responseto a givenprompt.
That's it! After these steps you're fully set up for automated evaluation on AutoArena.
AutoArena requires two pieces of information to test a model: the input prompt and corresponding model response.
-
prompt: the inputs to your model. When uploading responses, any other models that have been run on the same prompts are matched and evaluated using the automated judges you have configured. -
response: the output from your model. Judges decide which of two models produced a better response, given the same prompt.
Data is stored in ./data/<project>.sqlite files in the directory where you invoked AutoArena. See
data/README.md for more details on data storage in AutoArena.
AutoArena uses uv to manage dependencies. To set up this repository for development, run:
uv venv && source .venv/bin/activate
uv pip install --all-extras -r pyproject.toml
uv tool run pre-commit install
uv run python3 -m autoarena serve --devTo run AutoArena for development, you will need to run both the backend and frontend service:
- Backend:
uv run python3 -m autoarena serve --dev(the--dev/-dflag enables automatic service reloading when source files change) - Frontend: see
ui/README.md
To build a release tarball in the ./dist directory:
./scripts/build.shFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for autoarena
Similar Open Source Tools
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.
Sanmill
Sanmill is a free, powerful UCI-like N men's morris program with CUI, Flutter GUI and Qt GUI. Nine men's morris is a strategy board game for two players dating at least to the Roman Empire. The game is also known as nine-man morris , mill , mills , the mill game , merels , merrills , merelles , marelles , morelles , and ninepenny marl in English.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
sparql-llm
This project provides tools to enhance the capabilities of Large Language Models (LLMs) in generating SPARQL queries for specific endpoints. It includes reusable components, a chat web service, and an experimental MCP server. The system integrates Retrieval-Augmented Generation (RAG) and SPARQL query validation through endpoint schemas to ensure accurate query generation on large-scale knowledge graphs. Components can work independently or as part of a chat-based system requiring endpoint metadata. Features include metadata extraction, SPARQL query validation, deployable chat system, and live example chat system at chat.expasy.org.
stable-diffusion-discord-bot
A discord bot built to interface with the InvokeAI fork of stable-diffusion. It is a work in progress for a major rewrite of the arty project, compatible with `invokeai 5.1.1`. The bot supports various functionalities like building node graphs from job requests, refreshing renders using png metadata, removing backgrounds, job progress tracking, and LLM integration. Users can install custom invokeai nodes for advanced functionality and launch the bot natively or with docker. Patches and pull requests are welcomed.
agents
Polymarket Agents is a developer framework and set of utilities for building AI agents to trade autonomously on Polymarket. It integrates with Polymarket API, provides AI agent utilities for prediction markets, supports local and remote RAG, sources data from various services, and offers comprehensive LLM tools for prompt engineering. The architecture features modular components like APIs and scripts for managing local environments, server set-up, and CLI for end-user commands.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.
habitat-lab
Habitat-Lab is a modular high-level library for end-to-end development in embodied AI. It is designed to train agents to perform a wide variety of embodied AI tasks in indoor environments, as well as develop agents that can interact with humans in performing these tasks.
For similar tasks
autoarena
AutoArena is a tool designed to create leaderboards ranking Language Model outputs against one another using automated judge evaluation. It allows users to rank outputs from different LLMs, RAG setups, and prompts to find the best configuration of their system. Users can perform automated head-to-head evaluation using judges from various platforms like OpenAI, Anthropic, and Cohere. Additionally, users can define and run custom judges, connect to internal services, or implement bespoke logic. AutoArena enables users to run the application locally, providing full control over their environment and data.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.
llm-examples
Starter examples for building LLM apps with Streamlit. This repository showcases a growing collection of LLM minimum working examples, including a Chatbot, File Q&A, Chat with Internet search, LangChain Quickstart, LangChain PromptTemplate, and Chat with user feedback. Users can easily get their own OpenAI API key and set it as an environment variable in Streamlit apps to run the examples locally.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
gaianet-node
GaiaNet-node is a tool that allows users to run their own GaiaNet node, enabling them to interact with an AI agent. The tool provides functionalities to install the default node software stack, initialize the node with model files and vector database files, start the node, stop the node, and update configurations. Users can use pre-set configurations or pass a custom URL for initialization. The tool is designed to facilitate communication with the AI agent and access node information via a browser. GaiaNet-node requires sudo privilege for installation but can also be installed without sudo privileges with specific commands.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.