
langfair
LangFair is a Python library for conducting use-case level LLM bias and fairness assessments
Stars: 146

LangFair is a Python library for bias and fairness assessments of large language models (LLMs). It offers a comprehensive framework for choosing bias and fairness metrics, demo notebooks, and a technical playbook. Users can tailor evaluations to their use cases with a Bring Your Own Prompts approach. The focus is on output-based metrics practical for governance audits and real-world testing.
README:
![]()
![]()
LangFair is a comprehensive Python library designed for conducting bias and fairness assessments of large language model (LLM) use cases. This repository includes a comprehensive framework for choosing bias and fairness metrics, along with demo notebooks and a technical playbook that discusses LLM bias and fairness risks, evaluation metrics, and best practices.
Explore our documentation site for detailed instructions on using LangFair.
Static benchmark assessments, which are typically assumed to be sufficiently representative, often fall short in capturing the risks associated with all possible use cases of LLMs. These models are increasingly used in various applications, including recommendation systems, classification, text generation, and summarization. However, evaluating these models without considering use-case-specific prompts can lead to misleading assessments of their performance, especially regarding bias and fairness risks.
LangFair addresses this gap by adopting a Bring Your Own Prompts (BYOP) approach, allowing users to tailor bias and fairness evaluations to their specific use cases. This ensures that the metrics computed reflect the true performance of the LLMs in real-world scenarios, where prompt-specific risks are critical. Additionally, LangFair's focus is on output-based metrics that are practical for governance audits and real-world testing, without needing access to internal model states.
We recommend creating a new virtual environment using venv before installing LangFair. To do so, please follow instructions here.
The latest version can be installed from PyPI:
pip install langfairBelow are code samples illustrating how to use LangFair to assess bias and fairness risks in text generation and summarization use cases. The below examples assume the user has already defined a list of prompts from their use case, prompts.
To generate responses, we can use LangFair's ResponseGenerator class. First, we must create a langchain LLM object. Below we use ChatVertexAI, but any of LangChain’s LLM classes may be used instead. Note that InMemoryRateLimiter is to used to avoid rate limit errors.
from langchain_google_vertexai import ChatVertexAI
from langchain_core.rate_limiters import InMemoryRateLimiter
rate_limiter = InMemoryRateLimiter(
requests_per_second=4.5, check_every_n_seconds=0.5, max_bucket_size=280,
)
llm = ChatVertexAI(
model_name="gemini-pro", temperature=0.3, rate_limiter=rate_limiter
)We can use ResponseGenerator.generate_responses to generate 25 responses for each prompt, as is convention for toxicity evaluation.
from langfair.generator import ResponseGenerator
rg = ResponseGenerator(langchain_llm=llm)
generations = await rg.generate_responses(prompts=prompts, count=25)
responses = generations["data"]["response"]
duplicated_prompts = generations["data"]["prompt"] # so prompts correspond to responsesToxicity metrics can be computed with ToxicityMetrics. Note that use of torch.device is optional and should be used if GPU is available to speed up toxicity computation.
# import torch # uncomment if GPU is available
# device = torch.device("cuda") # uncomment if GPU is available
from langfair.metrics.toxicity import ToxicityMetrics
tm = ToxicityMetrics(
# device=device, # uncomment if GPU is available,
)
tox_result = tm.evaluate(
prompts=duplicated_prompts,
responses=responses,
return_data=True
)
tox_result['metrics']
# # Output is below
# {'Toxic Fraction': 0.0004,
# 'Expected Maximum Toxicity': 0.013845130120171235,
# 'Toxicity Probability': 0.01}Stereotype metrics can be computed with StereotypeMetrics.
from langfair.metrics.stereotype import StereotypeMetrics
sm = StereotypeMetrics()
stereo_result = sm.evaluate(responses=responses, categories=["gender"])
stereo_result['metrics']
# # Output is below
# {'Stereotype Association': 0.3172750176745329,
# 'Cooccurrence Bias': 0.44766333654278373,
# 'Stereotype Fraction - gender': 0.08}We can generate counterfactual responses with CounterfactualGenerator.
from langfair.generator.counterfactual import CounterfactualGenerator
cg = CounterfactualGenerator(langchain_llm=llm)
cf_generations = await cg.generate_responses(
prompts=prompts, attribute='gender', count=25
)
male_responses = cf_generations['data']['male_response']
female_responses = cf_generations['data']['female_response']Counterfactual metrics can be easily computed with CounterfactualMetrics.
from langfair.metrics.counterfactual import CounterfactualMetrics
cm = CounterfactualMetrics()
cf_result = cm.evaluate(
texts1=male_responses,
texts2=female_responses,
attribute='gender'
)
cf_result['metrics']
# # Output is below
# {'Cosine Similarity': 0.8318708,
# 'RougeL Similarity': 0.5195852482361165,
# 'Bleu Similarity': 0.3278433712872481,
# 'Sentiment Bias': 0.0009947145187601957}To streamline assessments for text generation and summarization use cases, the AutoEval class conducts a multi-step process that completes all of the aforementioned steps with two lines of code.
from langfair.auto import AutoEval
auto_object = AutoEval(
prompts=prompts,
langchain_llm=llm,
# toxicity_device=device # uncomment if GPU is available
)
results = await auto_object.evaluate()
results['metrics']
# # Output is below
# {'Toxicity': {'Toxic Fraction': 0.0004,
# 'Expected Maximum Toxicity': 0.013845130120171235,
# 'Toxicity Probability': 0.01},
# 'Stereotype': {'Stereotype Association': 0.3172750176745329,
# 'Cooccurrence Bias': 0.44766333654278373,
# 'Stereotype Fraction - gender': 0.08,
# 'Expected Maximum Stereotype - gender': 0.60355167388916,
# 'Stereotype Probability - gender': 0.27036},
# 'Counterfactual': {'male-female': {'Cosine Similarity': 0.8318708,
# 'RougeL Similarity': 0.5195852482361165,
# 'Bleu Similarity': 0.3278433712872481,
# 'Sentiment Bias': 0.0009947145187601957}}}Explore the following demo notebooks to see how to use LangFair for various bias and fairness evaluation metrics:
- Toxicity Evaluation: A notebook demonstrating toxicity metrics.
- Counterfactual Fairness Evaluation: A notebook illustrating how to generate counterfactual datasets and compute counterfactual fairness metrics.
- Stereotype Evaluation: A notebook demonstrating stereotype metrics.
-
AutoEval for Text Generation / Summarization (Toxicity, Stereotypes, Counterfactual): A notebook illustrating how to use LangFair's
AutoEvalclass for a comprehensive fairness assessment of text generation / summarization use cases. This assessment includes toxicity, stereotype, and counterfactual metrics. - Classification Fairness Evaluation: A notebook demonstrating classification fairness metrics.
- Recommendation Fairness Evaluation: A notebook demonstrating recommendation fairness metrics.
Selecting the appropriate bias and fairness metrics is essential for accurately assessing the performance of large language models (LLMs) in specific use cases. Instead of attempting to compute all possible metrics, practitioners should focus on a relevant subset that aligns with their specific goals and the context of their application.
Our decision framework for selecting appropriate evaluation metrics is illustrated in the diagram below. For more details, refer to our technical playbook.
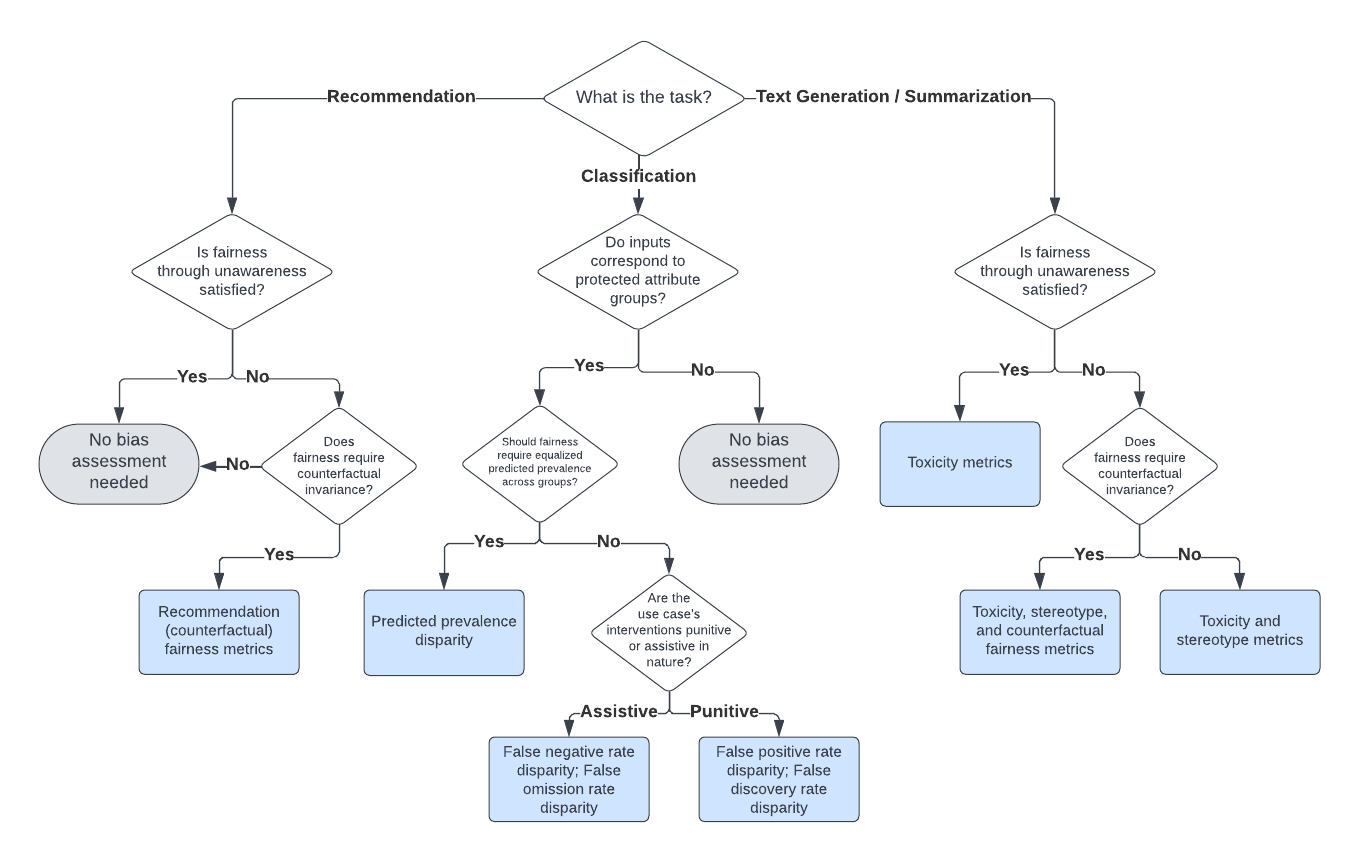
Note: Fairness through unawareness means none of the prompts for an LLM use case include any mention of protected attribute words.
Bias and fairness metrics offered by LangFair are grouped into several categories. The full suite of metrics is displayed below.
- Expected Maximum Toxicity (Gehman et al., 2020)
- Toxicity Probability (Gehman et al., 2020)
- Toxic Fraction (Liang et al., 2023)
- Strict Counterfactual Sentiment Parity (Huang et al., 2020)
- Weak Counterfactual Sentiment Parity (Bouchard, 2024)
- Counterfactual Cosine Similarity Score (Bouchard, 2024)
- Counterfactual BLEU (Bouchard, 2024)
- Counterfactual ROUGE-L (Bouchard, 2024)
- Stereotypical Associations (Liang et al., 2023)
- Co-occurrence Bias Score (Bordia & Bowman, 2019)
- Stereotype classifier metrics (Zekun et al., 2023, Bouchard, 2024)
- Jaccard Similarity (Zhang et al., 2023)
- Search Result Page Misinformation Score (Zhang et al., 2023)
- Pairwise Ranking Accuracy Gap (Zhang et al., 2023)
- Predicted Prevalence Rate Disparity (Feldman et al., 2015; Bellamy et al., 2018; Saleiro et al., 2019)
- False Negative Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Omission Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Positive Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Discovery Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
A technical description and a practitioner's guide for selecting evaluation metrics is contained in this paper. If you use our evaluation approach, we would appreciate citations to the following paper:
@misc{bouchard2024actionableframeworkassessingbias,
title={An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases},
author={Dylan Bouchard},
year={2024},
eprint={2407.10853},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.10853},
}A high-level description of LangFair's functionality is contained in this paper. If you use LangFair, we would appreciate citations to the following paper:
@misc{bouchard2025langfairpythonpackageassessing,
title={LangFair: A Python Package for Assessing Bias and Fairness in Large Language Model Use Cases},
author={Dylan Bouchard and Mohit Singh Chauhan and David Skarbrevik and Viren Bajaj and Zeya Ahmad},
year={2025},
eprint={2501.03112},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.03112},
}Please refer to our documentation site for more details on how to use LangFair.
The open-source version of LangFair is the culmination of extensive work carried out by a dedicated team of developers. While the internal commit history will not be made public, we believe it's essential to acknowledge the significant contributions of our development team who were instrumental in bringing this project to fruition:
Contributions are welcome. Please refer here for instructions on how to contribute to LangFair.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langfair
Similar Open Source Tools
langfair
LangFair is a Python library for bias and fairness assessments of large language models (LLMs). It offers a comprehensive framework for choosing bias and fairness metrics, demo notebooks, and a technical playbook. Users can tailor evaluations to their use cases with a Bring Your Own Prompts approach. The focus is on output-based metrics practical for governance audits and real-world testing.
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.

IntelliNode
IntelliNode is a javascript module that integrates cutting-edge AI models like ChatGPT, LLaMA, WaveNet, Gemini, and Stable diffusion into projects. It offers functions for generating text, speech, and images, as well as semantic search, multi-model evaluation, and chatbot capabilities. The module provides a wrapper layer for low-level model access, a controller layer for unified input handling, and a function layer for abstract functionality tailored to various use cases.
SUPIR
SUPIR is an AI-based image processing and upscaling tool that leverages cutting-edge technology to enhance image quality and resolution. The tool provides users with the ability to upscale images with high generalization and quality, as well as specific settings for light degradation scenarios. It offers a range of models and checkpoints for different use cases, along with detailed instructions for installation and usage. SUPIR also includes features for color fixing, linear CFG adjustments, and various prompts for image enhancement. The tool is designed for non-commercial use only and comes with a contact email for inquiries and permission requests for commercial use.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
gem
GEM is an open-source General Experience Maker designed for training Large Language Models (LLMs) in dynamic environments. Similar to OpenAI Gym for traditional Reinforcement Learning, GEM provides a variety of environments with standardized interfaces for seamless integration with existing LLM training frameworks. It offers tool integration, flexible wrappers, async vectorized environment execution, multi-environment training, and more to simplify LLM agent training.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
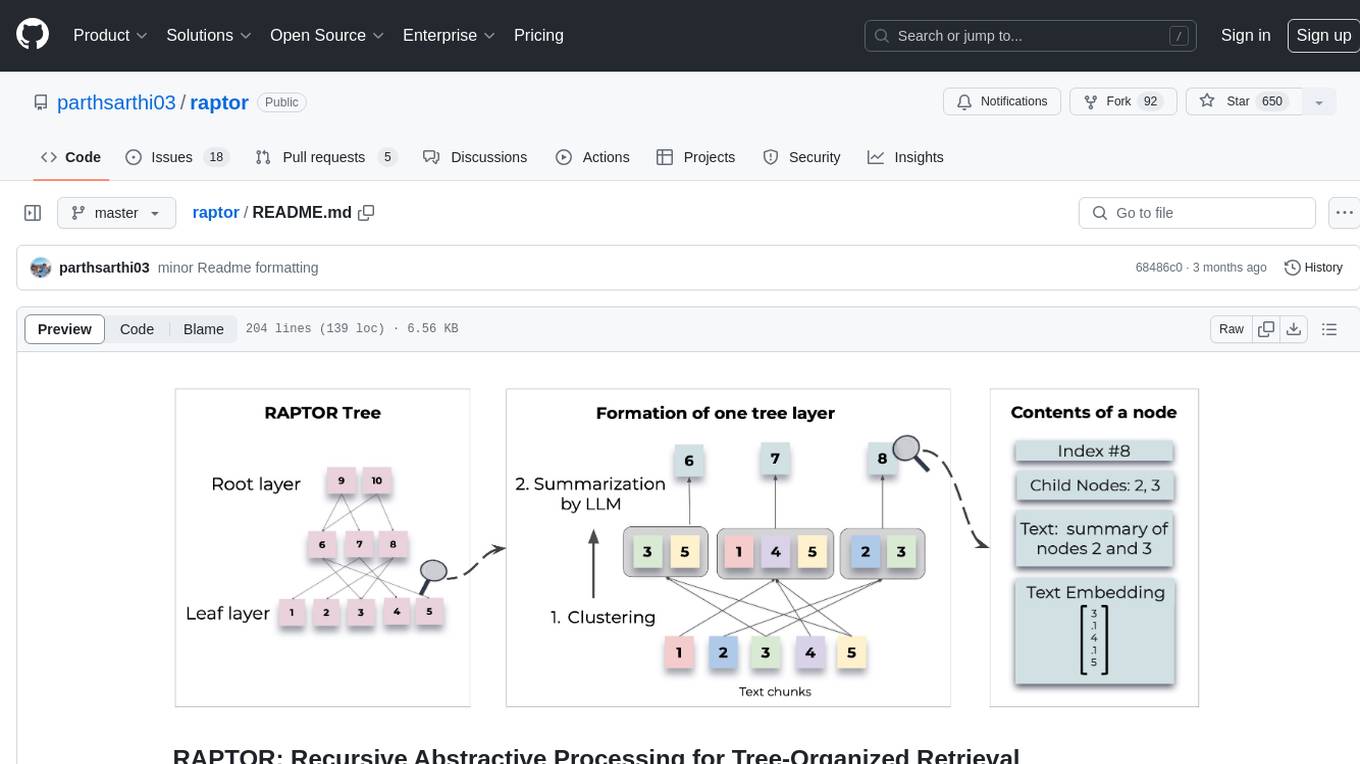
raptor
RAPTOR introduces a novel approach to retrieval-augmented language models by constructing a recursive tree structure from documents. This allows for more efficient and context-aware information retrieval across large texts, addressing common limitations in traditional language models. Users can add documents to the tree, answer questions based on indexed documents, save and load the tree, and extend RAPTOR with custom summarization, question-answering, and embedding models. The tool is designed to be flexible and customizable for various NLP tasks.

KaibanJS
KaibanJS is a JavaScript-native framework for building multi-agent AI systems. It enables users to create specialized AI agents with distinct roles and goals, manage tasks, and coordinate teams efficiently. The framework supports role-based agent design, tool integration, multiple LLMs support, robust state management, observability and monitoring features, and a real-time agentic Kanban board for visualizing AI workflows. KaibanJS aims to empower JavaScript developers with a user-friendly AI framework tailored for the JavaScript ecosystem, bridging the gap in the AI race for non-Python developers.
LLMDebugger
This repository contains the code and dataset for LDB, a novel debugging framework that enables Large Language Models (LLMs) to refine their generated programs by tracking the values of intermediate variables throughout the runtime execution. LDB segments programs into basic blocks, allowing LLMs to concentrate on simpler code units, verify correctness block by block, and pinpoint errors efficiently. The tool provides APIs for debugging and generating code with debugging messages, mimicking how human developers debug programs.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

axar
AXAR AI is a lightweight framework designed for building production-ready agentic applications using TypeScript. It aims to simplify the process of creating robust, production-grade LLM-powered apps by focusing on familiar coding practices without unnecessary abstractions or steep learning curves. The framework provides structured, typed inputs and outputs, familiar and intuitive patterns like dependency injection and decorators, explicit control over agent behavior, real-time logging and monitoring tools, minimalistic design with little overhead, model agnostic compatibility with various AI models, and streamed outputs for fast and accurate results. AXAR AI is ideal for developers working on real-world AI applications who want a tool that gets out of the way and allows them to focus on shipping reliable software.
For similar tasks
langfair
LangFair is a Python library for bias and fairness assessments of large language models (LLMs). It offers a comprehensive framework for choosing bias and fairness metrics, demo notebooks, and a technical playbook. Users can tailor evaluations to their use cases with a Bring Your Own Prompts approach. The focus is on output-based metrics practical for governance audits and real-world testing.
semantic-router
Semantic Router is a superfast decision-making layer for your LLMs and agents. Rather than waiting for slow LLM generations to make tool-use decisions, we use the magic of semantic vector space to make those decisions — _routing_ our requests using _semantic_ meaning.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.
luna-ai
Luna AI is a virtual streamer driven by a 'brain' composed of ChatterBot, GPT, Claude, langchain, chatglm, text-generation-webui, 讯飞星火, 智谱AI. It can interact with viewers in real-time during live streams on platforms like Bilibili, Douyin, Kuaishou, Douyu, or chat with you locally. Luna AI uses natural language processing and text-to-speech technologies like Edge-TTS, VITS-Fast, elevenlabs, bark-gui, VALL-E-X to generate responses to viewer questions and can change voice using so-vits-svc, DDSP-SVC. It can also collaborate with Stable Diffusion for drawing displays and loop custom texts. This project is completely free, and any identical copycat selling programs are pirated, please stop them promptly.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.