
any-parser
Accurate, private and configurable document retrieval LLM
Stars: 129
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.
README:


AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format.
To get started, generate your API key from the Sandbox Account Page. Each account comes with 100 free pages.
⚠️ Note: The free API is limited to 10 pages/call.
For more information or to inquire about larger usage plans, feel free to contact us at [email protected].
To set up your API key (CAMBIO_API_KEY), follow these steps:
- Create a
.envfile in the root directory of your project. - Add the following line to the
.envfile:
CAMBIO_API_KEY=0cam************************
First, create and activate a new Conda environment, then install AnyParser:
conda create -n any-parse python=3.10 -y
conda activate any-parse
pip3 install any-parserUse your API key to create an instance of AnyParser. Make sure you’ve set up your .env file to store your API key securely:
import os
from dotenv import load_dotenv
from any_parser import AnyParser
# Load environment variables
load_dotenv(override=True)
# Get the API key from the environment
example_apikey = os.getenv("CAMBIO_API_KEY")
# Create an AnyParser instance
ap = AnyParser(api_key=example_apikey)To extract data synchronously and receive immediate results:
# Extract content from the file and get the markdown output along with processing time
markdown, total_time = ap.parse(file_path="./data/test.pdf")For asynchronous extraction, send the file for processing and fetch results later:
# Send the file to begin asynchronous extraction
file_id = ap.async_parse(file_path="./data/test.pdf")
# Fetch the extracted content using the file ID
markdown = ap.async_fetch(file_id=file_id)For batch extraction, send the file to begin processing and fetch results later:
# Send the file to begin batch extraction
response = ap.batches.create(file_path="./data/test.pdf")
request_id = response.requestId
# Fetch the extracted content using the request ID
markdown = ap.batches.retrieve(request_id)Batch API for folder input:
# Send the folder to begin batch extraction
WORKING_FOLDER = "./sample_data"
# This will generate a jsonl with filename and requestID
response = ap.batches.create(WORKING_FOLDER)Each response in the JSONL file contains:
- The filename
- A unique request ID
- Additional processing metadata You can later use these request IDs to retrieve the extracted content for each file:
# Fetch the extracted content using the request ID from the jsonl file
markdown = ap.batches.retrieve(request_id)For more details about code implementation of batch API, refer to examples/parse_batch_upload.py and examples/parse_batch_fetch.py
⚠️ Note: Batch extraction is currently in beta testing. Processing time may take up to 12 hours to complete.
⚠️ Important: API keys generated from cambioml.com do not automatically have batch processing permissions. Please contact [email protected] to request batch processing access for your API key.
Check out these examples to see how you can utilize AnyParser to extract text, numbers, and symbols in fewer than 10 lines of code!
Are you an AI engineer looking to accurately extract both the text and layout (e.g., table of contents or Markdown headers hierarchy) from a PDF? Check out this 3-minute notebook demo.
Are you a financial analyst needing to accurately extract numbers from a table within an image? Explore this 3-minute notebook example.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for any-parser
Similar Open Source Tools
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
Local-File-Organizer
The Local File Organizer is an AI-powered tool designed to help users organize their digital files efficiently and securely on their local device. By leveraging advanced AI models for text and visual content analysis, the tool automatically scans and categorizes files, generates relevant descriptions and filenames, and organizes them into a new directory structure. All AI processing occurs locally using the Nexa SDK, ensuring privacy and security. With support for multiple file types and customizable prompts, this tool aims to simplify file management and bring order to users' digital lives.

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.
nodejs-todo-api-boilerplate
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
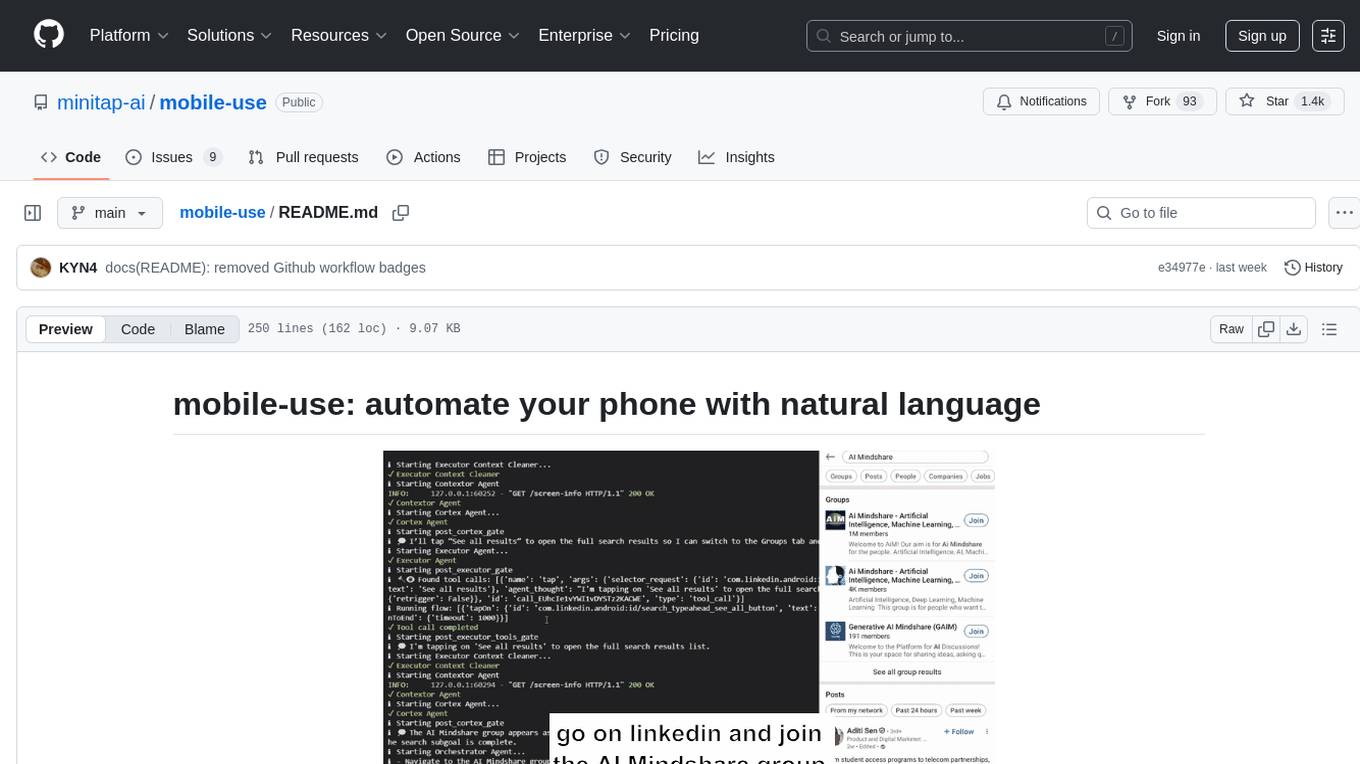
mobile-use
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.
Foxel
Foxel is a highly extensible private cloud storage solution for individuals and teams, featuring AI-powered semantic search. It offers unified file management, pluggable storage backends, semantic search capabilities, built-in file preview, permissions and sharing options, and a task processing center. Users can easily manage files, search content within unstructured data, preview various file types, share files, and process tasks asynchronously. Foxel is designed to centralize file management and enhance search capabilities for users.
aisdk-prompt-optimizer
AISDK Prompt Optimizer is an open-source tool designed to transform AI interactions by optimizing prompts. It utilizes the GEPA reflective optimizer to evolve textual components of AI systems, providing features such as reflective prompt mutation, rich textual feedback, and Pareto-based selection. Users can teach their AI desired behaviors, collect ideal samples, run optimization to generate optimized prompts, and deploy the results in their applications. The tool leverages advanced optimization algorithms to guide AI through interactive conversations and refine prompt candidates for improved performance.
For similar tasks
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.
terraform-genai-doc-summarization
This solution showcases how to summarize a large corpus of documents using Generative AI. It provides an end-to-end demonstration of document summarization going all the way from raw documents, detecting text in the documents and summarizing the documents on-demand using Vertex AI LLM APIs, Cloud Vision Optical Character Recognition (OCR) and BigQuery.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.