
steel-browser
🔥 Open Source Browser API for AI Agents & Apps. Steel Browser is a batteries-included browser instance that lets you automate the web without worrying about infrastructure.
Stars: 4056
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.
README:
![]()
The open-source browser API for AI agents & apps.
The best way to build live web agents and browser automation tools.






Steel.dev is an open-source browser API that makes it easy to build AI apps and agents that interact with the web. Instead of building automation infrastructure from scratch, you can focus on your AI application while Steel handles the complexity.
Under the hood, it manages sessions, pages, and browser processes, allowing you to perform complex browsing tasks programmatically without any of the headaches:
- Full Browser Control: Uses Puppeteer and CDP for complete control over Chrome instances -- allowing you to connect using Puppeteer, Playwright, or Selenium.
- Session Management: Maintains browser state, cookies, and local storage across requests
- Proxy Support: Built-in proxy chain management for IP rotation
- Extension Support: Load custom Chrome extensions for enhanced functionality
- Debugging Tools: Built-in request logging and a UI to view/debug sessions with
- Anti-Detection: Includes stealth plugins and fingerprint management
- Resource Management: Automatic cleanup and browser lifecycle management
- Browser Tools: Exposes APIs to quick convert pages to markdown, readability, screenshots, or PDFs.
For detailed API documentation and examples, check out our API reference or explore the Swagger UI directly at http://0.0.0.0:3000/documentation.
Steel is in public beta and evolving every day. Your suggestions, ideas, and reported bugs help us immensely. Do not hesitate to join in the conversation on Discord or raise a GitHub issue. We read everything, respond to most, and love you.
If you love open-source, AI, and dev tools, we're hiring across the stack!

The easiest way to get started with Steel is by creating a Steel Cloud account. Otherwise, you can deploy this Steel browser instance to a cloud provider or run it locally.
If you're looking to deploy to a cloud provider, we've got you covered.
| Deployment methods | Link |
|---|---|
| Pre-built Docker Image (API only) | |
| 1-click deploy to Railway | |
| 1-click deploy to Render |
The simplest way to run a Steel browser instance locally is to run the pre-built Docker images:
# Clone and build the Docker image
git clone https://github.com/steel-dev/steel-browser
cd steel-browser
docker compose upThis will start the Steel server on port 3000 (http://localhost:3000) and the UI on port 5173 (http://localhost:5173).
You can now create sessions, scrape pages, take screenshots, and more. Jump to the Usage section for some quick examples on how you can do that.
When developing locally, you will need to run the docker-compose.dev.yml file instead of the default docker-compose.yml file so that your local changes are reflected. Doing this will build the Docker images from the api and ui directories and run the server and UI on port 3000 and 5173 respectively.
docker compose -f docker-compose.dev.yml upYou will also need to run it with --build to ensure the Docker images are re-built every time you make changes:
docker compose -f docker-compose.dev.yml up --buildIn case you run on a custom host, you need to copy .env.example to .env while changing the host or modify the environment variables used by the docker-compose.dev.yml to use your host.
Alternatively, if you have Node.js and Chrome installed, you can run the server directly:
npm install
npm run devThis will also start the Steel server on port 3000 and the UI on port 5173.
Make sure you have the Chrome executable installed and in one of these paths:
-
Linux:
/usr/bin/google-chrome -
MacOS:
/Applications/Google Chrome.app/Contents/MacOS/Google Chrome -
Windows:
-
C:\Program Files\Google\Chrome\Application\chrome.exeOR C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
-
If you have a custom Chrome executable or a different path, you can set the CHROME_EXECUTABLE_PATH environment variable to the path of your Chrome executable:
export CHROME_EXECUTABLE_PATH=/path/to/your/chrome
npm run devFor more details on where this is checked look at api/src/utils/browser.ts.
If you're looking for quick examples on how to use Steel, check out the Cookbook.
Alternatively you can play with the REPL package too
cd replandnpm run start
There are two main ways to interact with the Steel browser API:
In these examples, we assume your custom Steel API endpoint is http://localhost:3000.
The full REST API documentation can be found on your Steel instance at /documentation (e.g., http://localhost:3000/documentation).
If you prefer to use the our Python and Node SDKs, you can install the steel-sdk package for Node or Python.
These SDKs are built on top of the REST API and provide a more convenient way to interact with the Steel browser API. They are fully typed, and are compatible with both Steel Cloud and self-hosted Steel instances (changeable using the baseUrl option on Node and base_url on Python).
For more details on installing and using the SDKs, please see the Node SDK Reference and the Python SDK Reference.
The /sessions endpoint lets you relaunch the browser with custom options or extensions (e.g. with a custom proxy) and also reset the browser state. Perfect for complex, stateful workflows that need fine-grained control.
Once you have a session, you can use the session ID or the root URL to interact with the browser. To do this, you will need to use Puppeteer or Playwright. You can find some examples of how to use Puppeteer and Playwright with Steel in the docs below:
Creating a Session using the Node SDK
import Steel from 'steel-sdk';
const client = new Steel({
baseUrl: "http://localhost:3000", // Custom API Base URL override
});
(async () => {
try {
// Create a new browser session with custom options
const session = await client.sessions.create({
sessionTimeout: 1800000, // 30 minutes
blockAds: true,
});
console.log("Created session with ID:", session.id);
} catch (error) {
console.error("Error creating session:", error);
}
})();Creating a Session using the Python SDK
import os
from steel import Steel
client = Steel(
base_url="http://localhost:3000", # Custom API Base URL override
)
try:
# Create a new browser session with custom options
session = client.sessions.create(
session_timeout=1800000, # 30 minutes
block_ads=True,
)
print("Created session with ID:", session.id)
except Exception as e:
print("Error creating session:", e)Creating a Session using Curl
# Launch a new browser session
curl -X POST http://localhost:3000/v1/sessions \
-H "Content-Type: application/json" \
-d '{
"options": {
"proxy": "user:pass@host:port",
// Custom launch options
}
}'Note: This integration does not support all the features of the CDP-based browser sessions API.
For teams with existing Selenium workflows, the Steel browser provides a drop-in replacement that adds enhanced features while maintaining compatibility. You can simply use the isSelenium option to create a Selenium session:
// Using the Node SDK
const session = await client.sessions.create({ isSelenium: true });# Using the Python SDK
session = client.sessions.create(is_selenium=True)Using Curl
# Launch a Selenium session
curl -X POST http://localhost:3000/v1/sessions \
-H "Content-Type: application/json" \
-d '{
"options": {
"isSelenium": true,
// Selenium-compatible options
}
}'The Selenium API is fully compatible with Selenium's WebDriver protocol, so you can use any existing Selenium clients to connect to the Steel browser. For more details on using Selenium with Steel, refer to the Selenium Docs.
The /scrape, /screenshot, and /pdf endpoints let you quickly extract clean, well-formatted data from any webpage using the running Steel server. Ideal for simple, read-only, on-demand jobs:
Scrape a Web Page
Extract the HTML content of a web page.
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/scrape \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"waitFor": 1000
}'Take a Screenshot
Take a screenshot of a web page.
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/screenshot \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"fullPage": true
}' --output screenshot.pngDownload a PDF
Download a PDF of a web page.
# Example using the Actions API
curl -X POST http://0.0.0.0:3000/v1/pdf \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"fullPage": true
}' --output output.pdfSteel browser is an open-source project, and we welcome contributions!
Made with ❤️ by the Steel team.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for steel-browser
Similar Open Source Tools
steel-browser
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
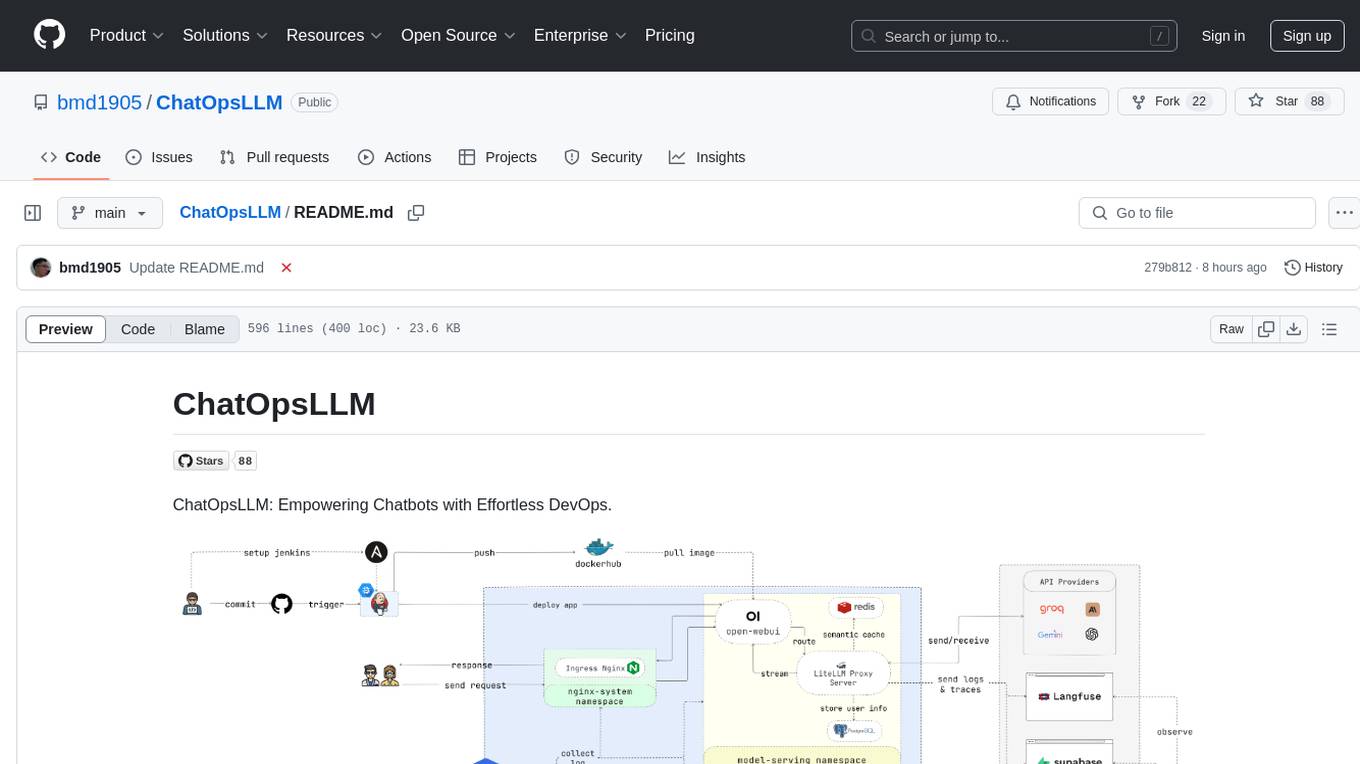
ChatOpsLLM
ChatOpsLLM is a project designed to empower chatbots with effortless DevOps capabilities. It provides an intuitive interface and streamlined workflows for managing and scaling language models. The project incorporates robust MLOps practices, including CI/CD pipelines with Jenkins and Ansible, monitoring with Prometheus and Grafana, and centralized logging with the ELK stack. Developers can find detailed documentation and instructions on the project's website.
ChatGPT
The ChatGPT API Free Reverse Proxy provides free self-hosted API access to ChatGPT (`gpt-3.5-turbo`) with OpenAI's familiar structure, eliminating the need for code changes. It offers streaming response, API endpoint compatibility, and complimentary access without an API key. Installation options include Docker, PC/Server, and Termux on Android devices. The API can be accessed through a self-hosted local server or a pre-hosted API with an API key obtained from the Discord server. Usage examples are provided for Python and Node.js, and the project is licensed under AGPL-3.0.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
director
Director is a context infrastructure tool for AI agents that simplifies managing MCP servers, prompts, and configurations by packaging them into portable workspaces accessible through a single endpoint. It allows users to define context workspaces once and share them across different AI clients, enabling seamless collaboration, instant context switching, and secure isolation of untrusted servers without cloud dependencies or API keys. Director offers features like workspaces, universal portability, local-first architecture, sandboxing, smart filtering, unified OAuth, observability, multiple interfaces, and compatibility with all MCP clients and servers.
playword
PlayWord is a tool designed to supercharge web test automation experience with AI. It provides core features such as enabling browser operations and validations using natural language inputs, as well as monitoring interface to record and dry-run test steps. PlayWord supports multiple AI services including Anthropic, Google, and OpenAI, allowing users to select the appropriate provider based on their requirements. The tool also offers features like assertion handling, frame handling, custom variables, test recordings, and an Observer module to track user interactions on web pages. With PlayWord, users can interact with web pages using natural language commands, reducing the need to worry about element locators and providing AI-powered adaptation to UI changes.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
model-compose
model-compose is an open-source, declarative workflow orchestrator inspired by docker-compose. It lets you define and run AI model pipelines using simple YAML files. Effortlessly connect external AI services or run local AI models within powerful, composable workflows. Features include declarative design, multi-workflow support, modular components, flexible I/O routing, streaming mode support, and more. It supports running workflows locally or serving them remotely, Docker deployment, environment variable support, and provides a CLI interface for managing AI workflows.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
For similar tasks
steel-browser
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.
desktop
E2B Desktop Sandbox is a secure virtual desktop environment powered by E2B, allowing users to create isolated sandboxes with customizable dependencies. It provides features such as streaming the desktop screen, mouse and keyboard control, taking screenshots, opening files, and running bash commands. The environment is based on Linux and Xfce, offering a fast and lightweight experience that can be fully customized to create unique desktop environments.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.