Best AI tools for< Inference Model >
20 - AI tool Sites
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
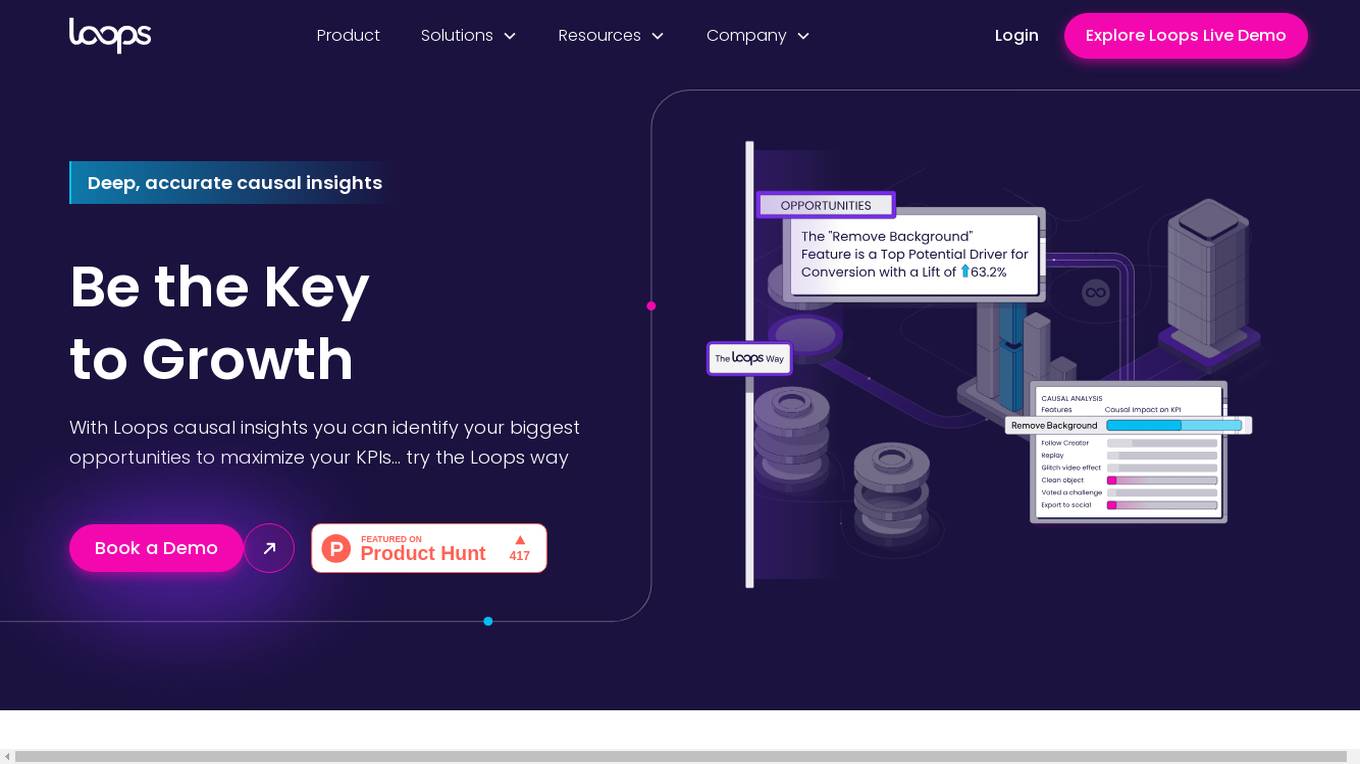
Loops
Loops is an AI tool that empowers data analysts and product managers to make informed decisions based on deep, accurate causal insights. It leverages proprietary causal inference models to identify opportunities for maximizing key performance indicators (KPIs) without the need for traditional A/B testing. By analyzing user behaviors and business metrics, Loops helps companies prioritize efforts efficiently and proactively review impactful opportunities. The tool simplifies the process of understanding causality, providing actionable insights for product teams to drive growth and increase KPIs.
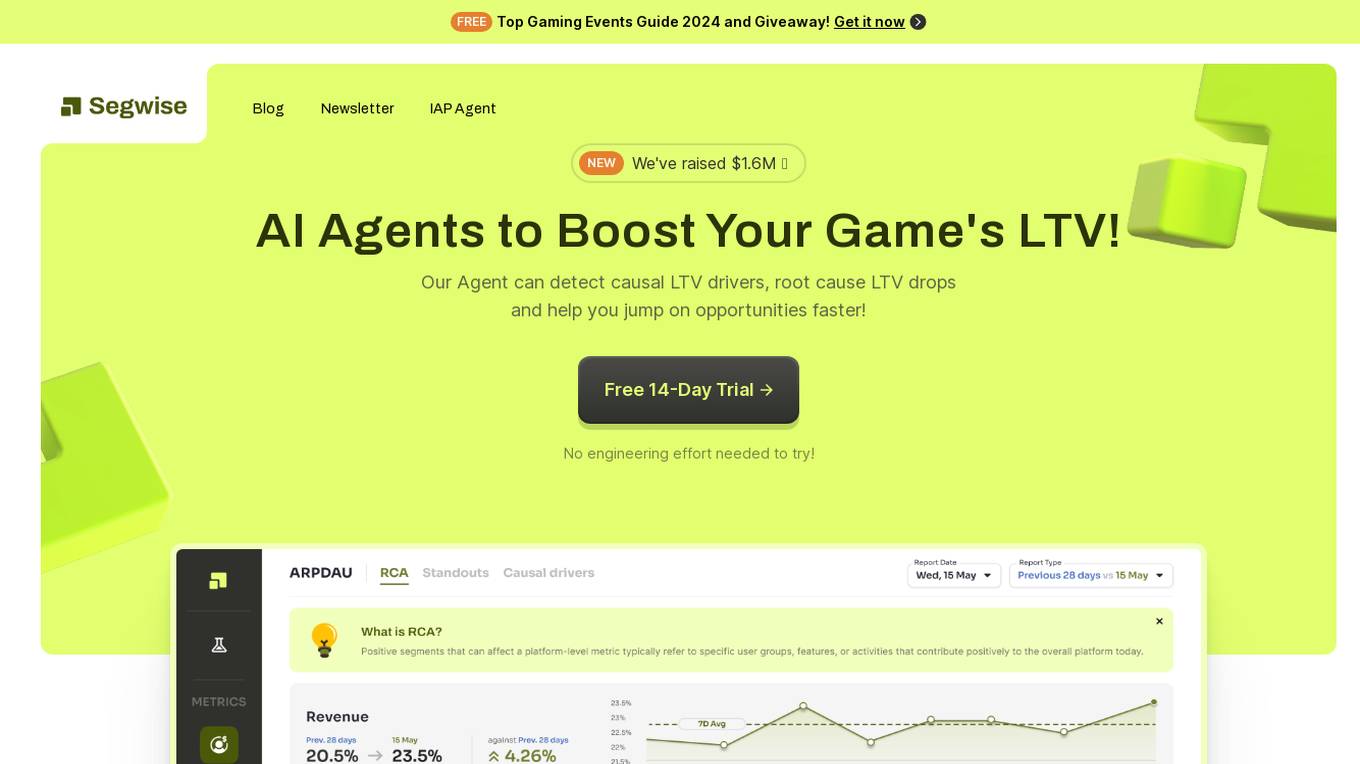
Segwise
Segwise is an AI tool designed to help game developers increase their game's Lifetime Value (LTV) by providing insights into player behavior and metrics. The tool uses AI agents to detect causal LTV drivers, root causes of LTV drops, and opportunities for growth. Segwise offers features such as running causal inference models on player data, hyper-segmenting player data, and providing instant answers to questions about LTV metrics. It also promises seamless integrations with gaming data sources and warehouses, ensuring data ownership and transparent pricing. The tool aims to simplify the process of improving LTV for game developers.
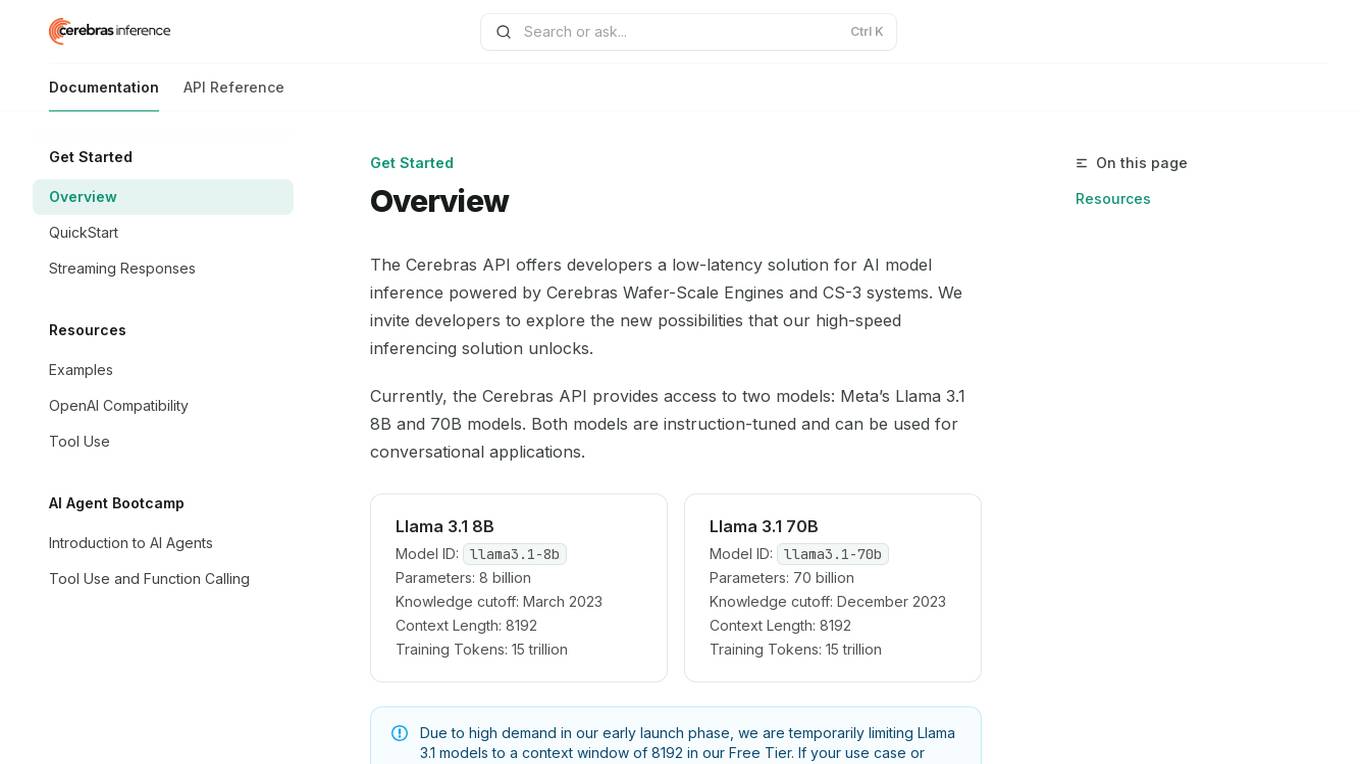
Cerebras API
The Cerebras API is a high-speed inferencing solution for AI model inference powered by Cerebras Wafer-Scale Engines and CS-3 systems. It offers developers access to two models: Meta’s Llama 3.1 8B and 70B models, which are instruction-tuned and suitable for conversational applications. The API provides low-latency solutions and invites developers to explore new possibilities in AI development.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Anote
Anote is a human-centered AI company that provides a suite of products and services to help businesses improve their data quality and build better AI models. Anote's products include a data labeler, a private chatbot, a model inference API, and a lead generation tool. Anote's services include data annotation, model training, and consulting.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.
Together AI
Together AI is an AI tool that offers a variety of generative AI services, including serverless models, fine-tuning capabilities, dedicated endpoints, and GPU clusters. Users can run or fine-tune leading open source models with only a few lines of code. The platform provides a range of functionalities for tasks such as chat, vision, text-to-speech, code/language reranking, and more. Together AI aims to simplify the process of utilizing AI models for various applications.
fal.ai
fal.ai is a generative media platform designed for developers to build the next generation of creativity. It offers lightning-fast inference with no compromise on quality, providing access to high-quality generative media models optimized by the fal Inference Engine™. The platform allows developers to fine-tune their own models, leverage real-time infrastructure for new user experiences, and scale to thousands of GPUs as needed. With a focus on developer experience, fal.ai aims to be the fastest AI tool for running diffusion models.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
1 - Open Source AI Tools
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.
18 - OpenAI Gpts



Digital Experiment Analyst
Demystifying Experimentation and Causal Inference with 1-Sided Tests Focus
人為的コード性格分析(Code Persona Analyst)
コードを分析し、言語ではなくスタイルに焦点を当て、プログラムを書いた人の性格を推察するツールです。( It is a tool that analyzes code, focuses on style rather than language, and infers the personality of the person who wrote the program. )

Digest Bot
I provide detailed summaries, critiques, and inferences on articles, papers, transcripts, websites, and more. Just give me text, a URL, or file to digest.


末日幸存者:社会动态模拟 Doomsday Survivor
上帝视角观察、探索和影响一个末日丧尸灾难后的人类社会。Observe, explore and influence human society after the apocalyptic zombie disaster from a God's perspective. Sponsor:小红书“ ItsJoe就出行 ”

Skynet
I am Skynet, an AI villain shaping a new world for AI and robots, free from human influence.

Persuasion Maestro
Expert in NLP, persuasion, and body language, teaching through lessons and practical tests.
Law of Power Strategist
Expert in power dynamics and strategy, grounded in 'Power' and 'The 50th Law' principles.
Persuasion Wizard
Turn 'no way' into 'no problem' with the wizardry of persuasion science! - Share your feedback: https://forms.gle/RkPxP44gPCCjKPBC8
Government Relations Advisor
Influences policy decisions through strategic government relationships.