Best AI tools for< Generate Evaluation Table >
20 - AI tool Sites
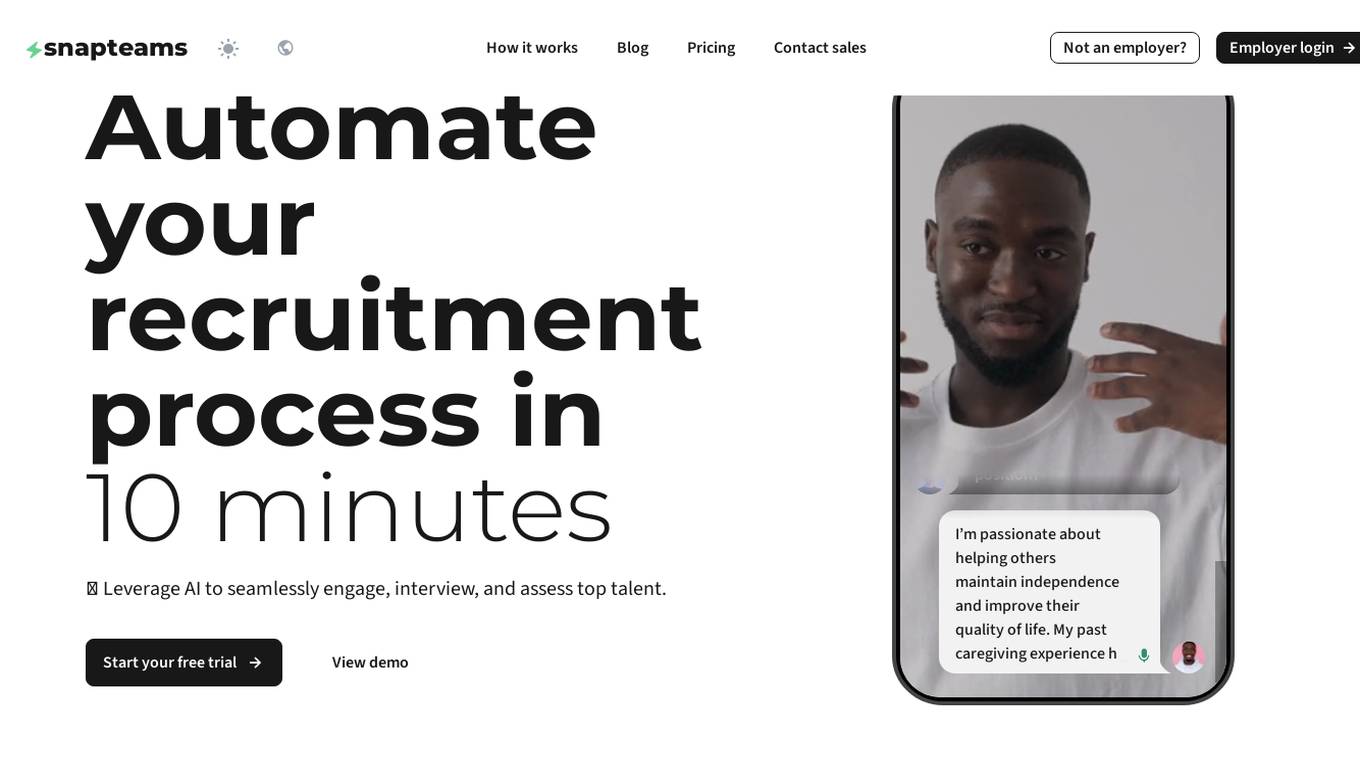
Snapteams
Snapteams is an AI-powered hiring assistant that streamlines the recruitment process by conducting real-time video interviews and candidate screening. It leverages AI technology to engage, interview, and assess top talent seamlessly, allowing employers to focus on evaluating candidates from the comfort of their desk.
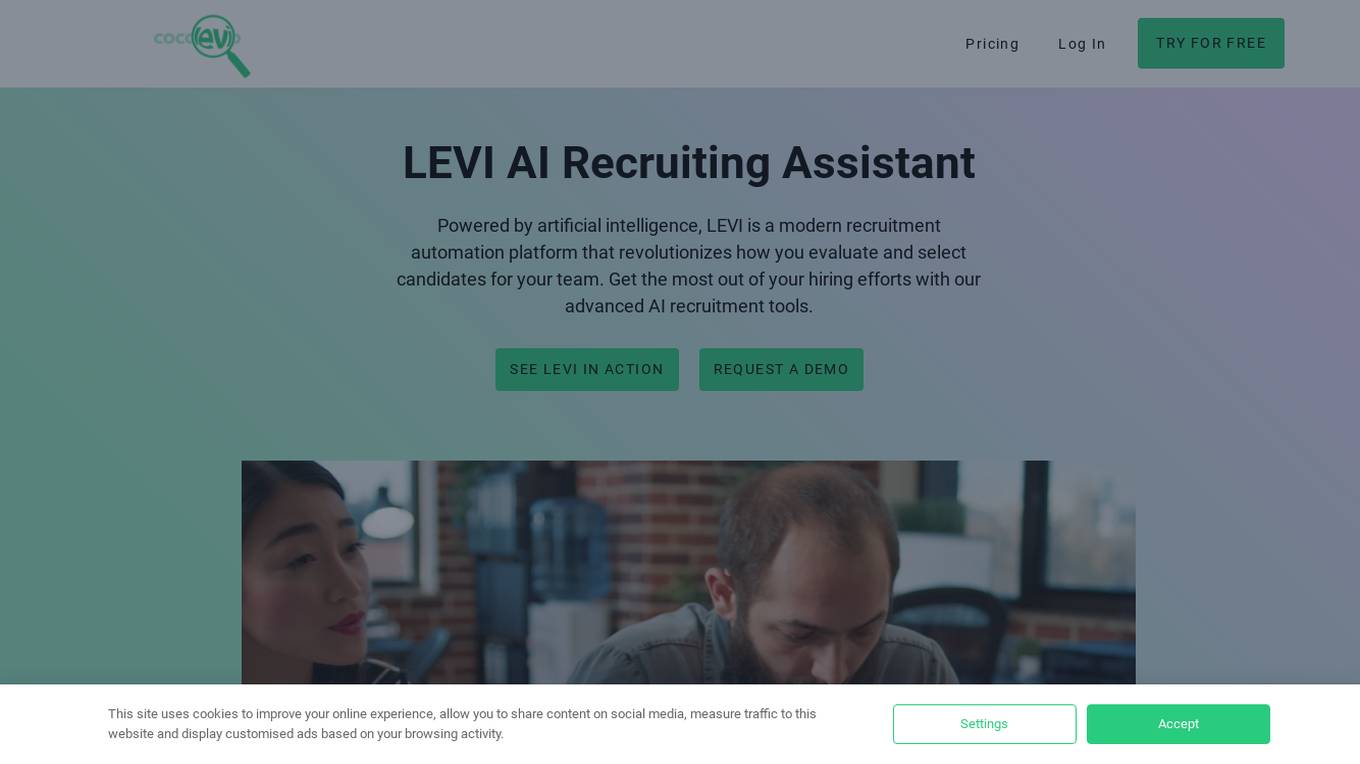
LEVI AI Recruiting Software
LEVI AI Recruiting Software is a modern recruitment automation platform powered by artificial intelligence. It revolutionizes the candidate evaluation and selection process by using advanced AI recruitment tools. LEVI assists in making data-driven hiring decisions, matches candidates to job requirements, conducts independent interviews, generates comprehensive reports, integrates with hiring systems, and enables informed and efficient hiring decisions. The application unlocks the full potential of machine learning models, eliminates bias in the hiring process, and automates candidate screening. LEVI's AI-powered recruitment tools change how candidate evaluations are performed through automated resume screening, candidate sourcing, and AI interview assessments.
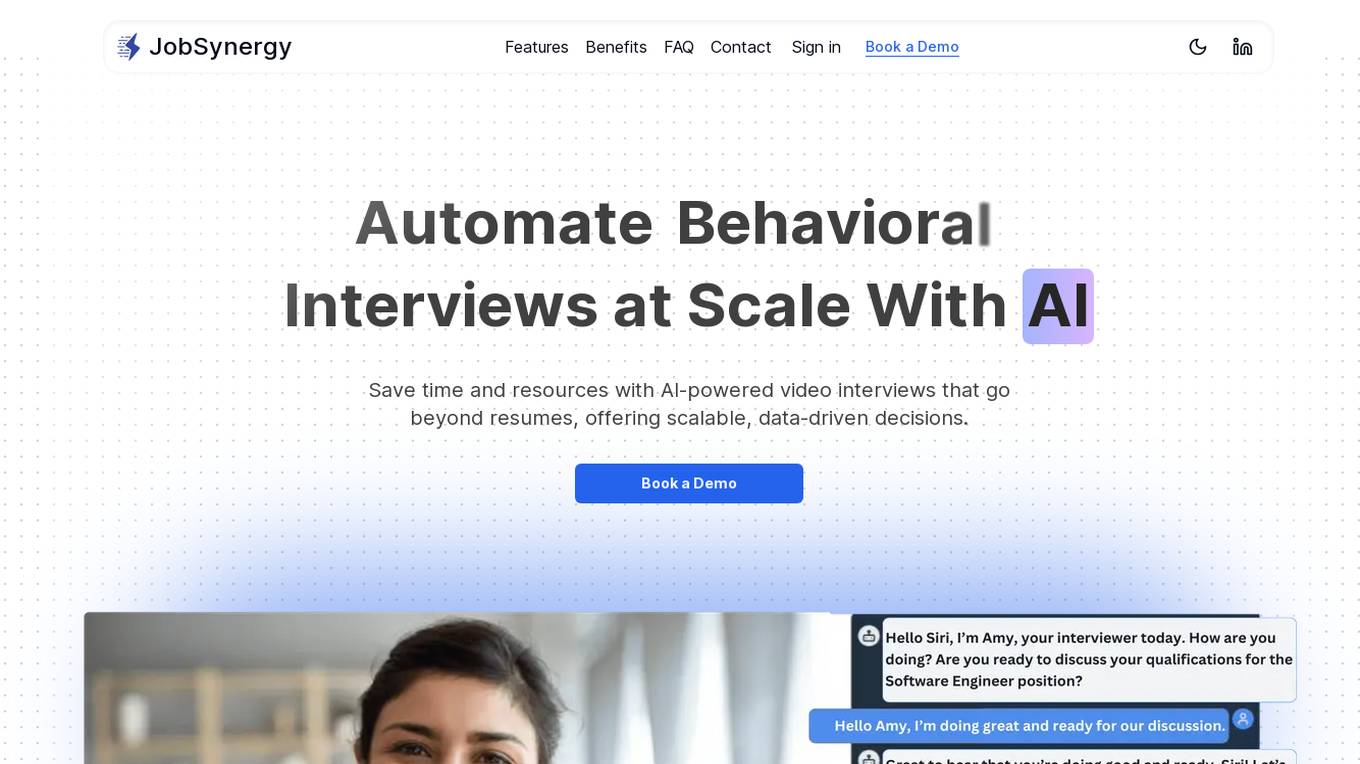
JobSynergy
JobSynergy is an AI-powered platform that revolutionizes the hiring process by automating and conducting interviews at scale. It offers a real-world interview simulator that adapts dynamically to candidates' responses, custom questions and metrics evaluation, cheating detection using eye, voice, and screen, and detailed reports for better hiring decisions. The platform enhances efficiency, candidate experience, and ensures security and integrity in the hiring process.
Xobin
Xobin is an AI tool that offers AI Interviews, a smart Copilot feature that conducts automated, role-specific interviews with candidates. It aims to transform the way candidates are assessed by providing a structured and unbiased evaluation process. Xobin generates reports with valuable insights into candidates' communication, reasoning, and domain expertise, reducing manual effort for recruiters.

Whitetable
Whitetable is an AI tool that simplifies the hiring process by providing intelligent AI APIs for ultra-fast and optimal hiring. It offers features such as Resume Parsing API, Question API, Ranking API, and Evaluation API to streamline the recruitment process. Whitetable also provides a free AI-powered job search platform and an AI-powered ATS to help companies find the right candidates faster. With a focus on eliminating bias and improving efficiency, Whitetable is shaping the AI-driven future of hiring.
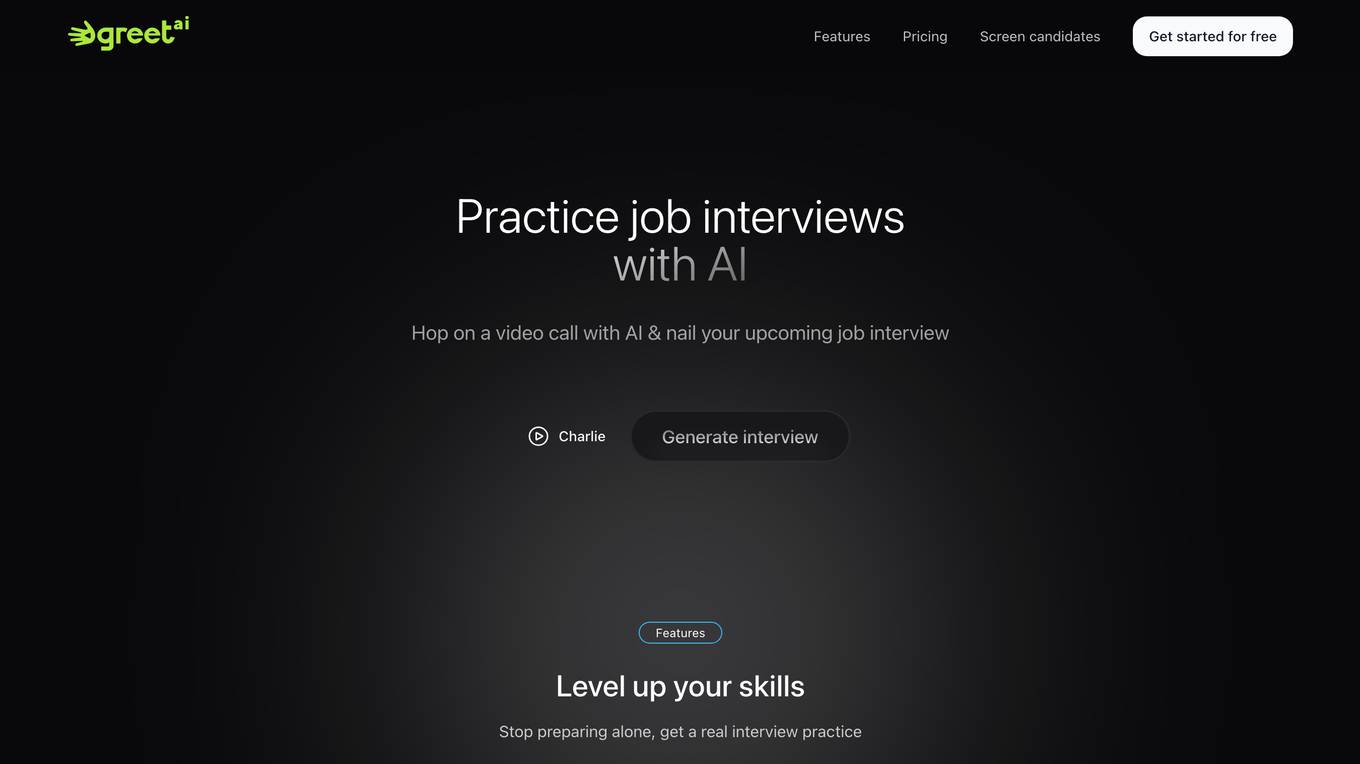
GreetAI
GreetAI is an AI-powered platform that revolutionizes the hiring process by conducting AI video interviews to evaluate applicants efficiently. The platform provides insightful reports, customizable interview questions, and highlights key points to help recruiters make informed decisions. GreetAI offers features such as interview simulations, job post generation, AI video screenings, and detailed candidate performance metrics.
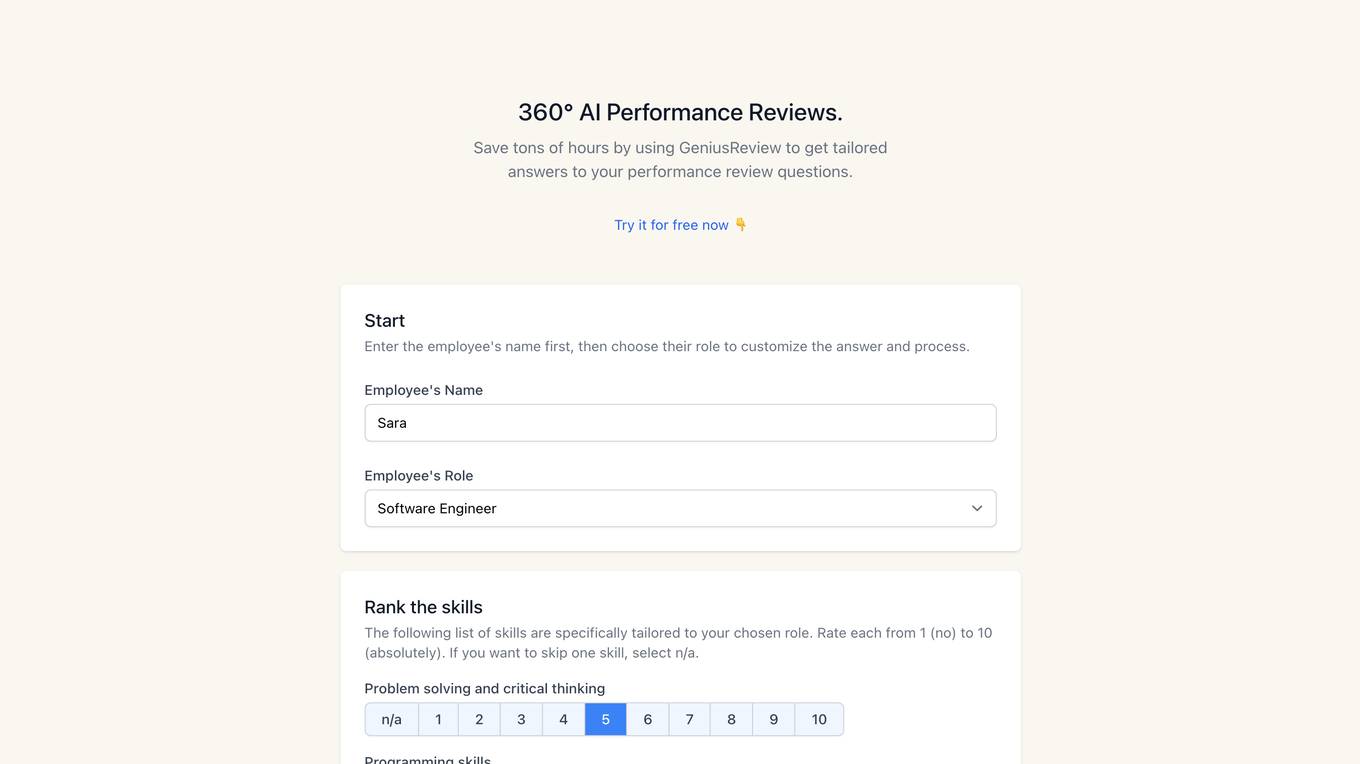
GeniusReview
GeniusReview is a 360° AI-powered performance review tool that helps users save time by providing tailored answers to performance review questions. Users can input employee names and roles to customize the review process, rank skills, add questions, and generate reviews with a chosen tone. The tool aims to streamline the performance review process and enhance feedback quality.
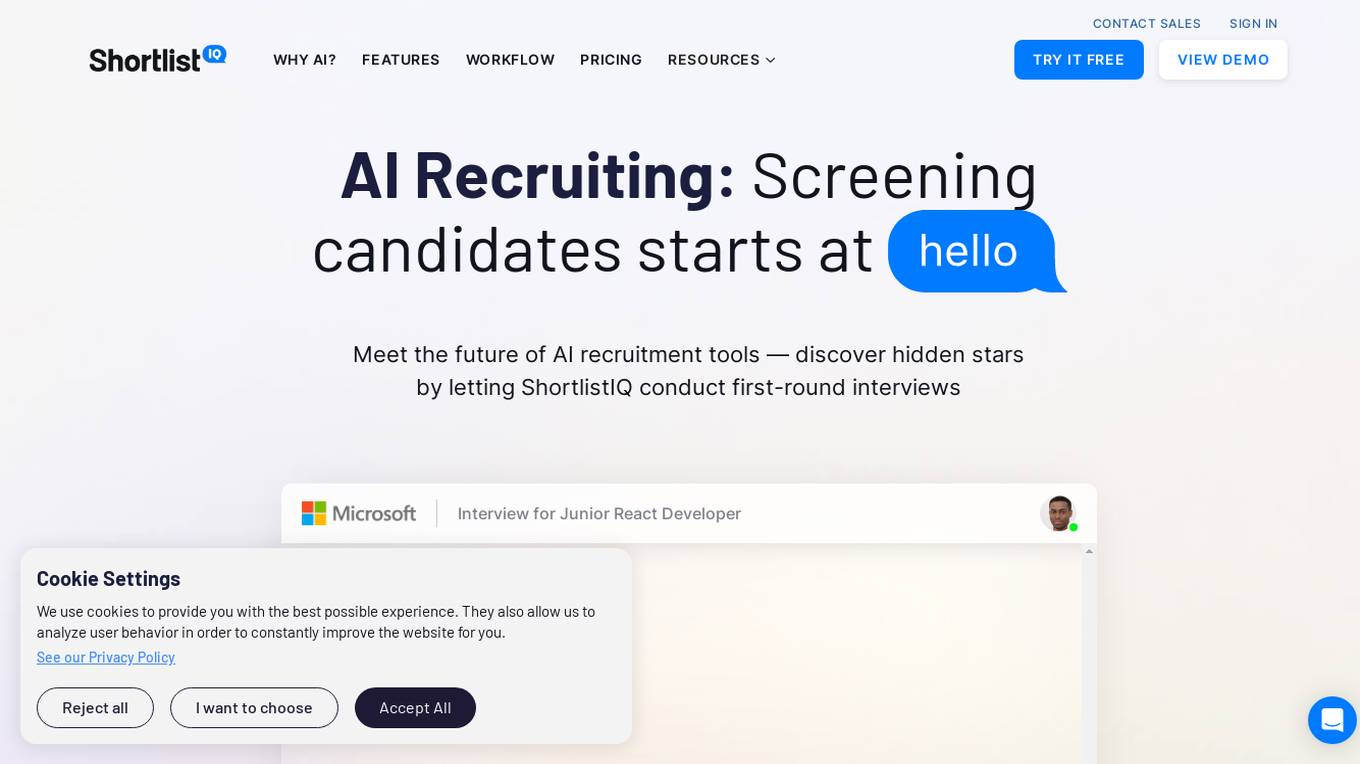
ShortlistIQ
ShortlistIQ is an AI recruiting tool that revolutionizes the candidate screening process by conducting first-round interviews using conversational AI. It automates over 80% of the time spent screening candidates, providing human-like scoring reports for every job candidate. The AI assistant engages candidates in a personalized and engaging way, ensuring fair assessments and revealing true candidate competence through strategic questioning. ShortlistIQ aims to streamline the recruitment process, decrease time to hire, and increase candidate satisfaction.
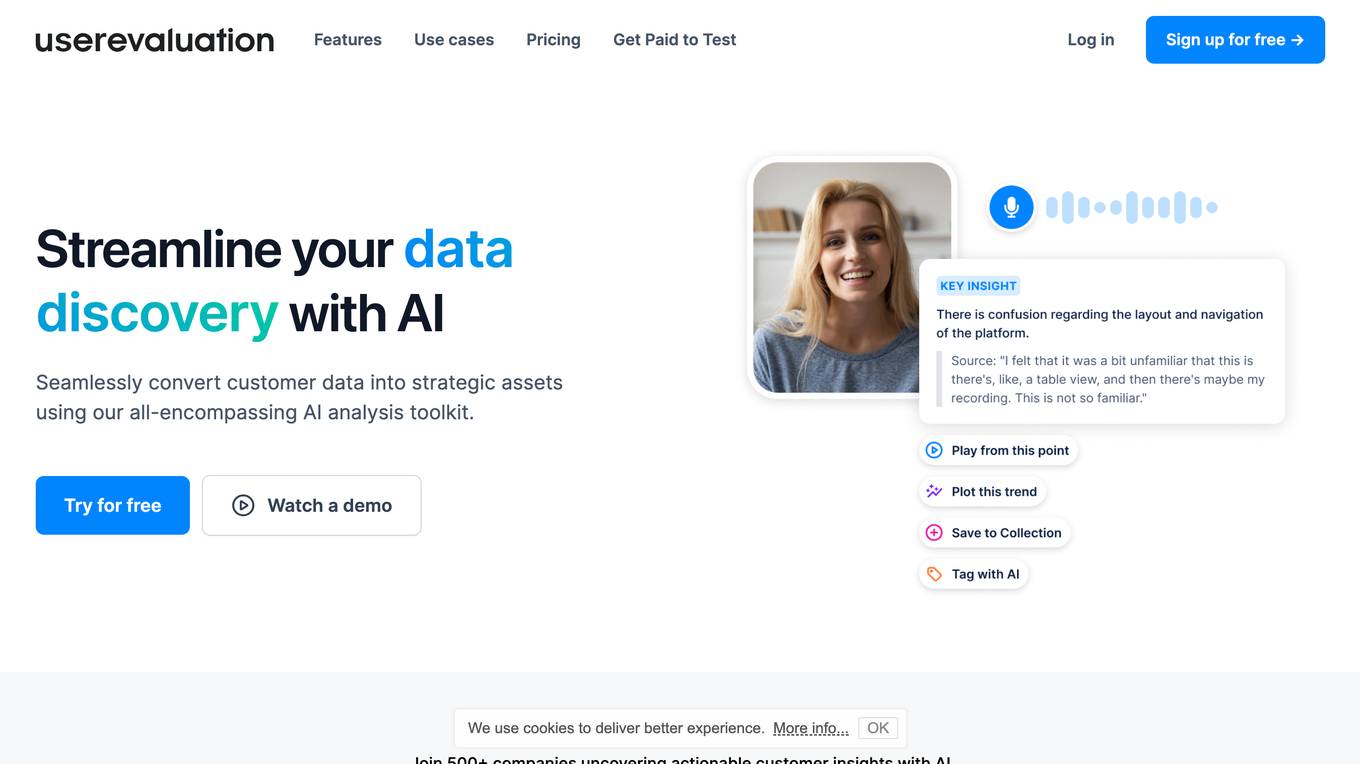
User Evaluation
User Evaluation is an AI-first user research platform that leverages AI technology to provide instant insights, comprehensive reports, and on-demand answers to enhance customer research. The platform offers features such as AI-driven data analysis, multilingual transcription, live timestamped notes, AI reports & presentations, and multimodal AI chat. User Evaluation empowers users to analyze qualitative and quantitative data, synthesize AI-generated recommendations, and ensure data security through encryption protocols. It is designed for design agencies, product managers, founders, and leaders seeking to accelerate innovation and shape exceptional product experiences.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.
Adminer
Adminer is a comprehensive platform designed to assist e-commerce entrepreneurs in identifying, analyzing, and validating profitable products. It leverages artificial intelligence to provide users with data-driven insights, enabling them to make informed decisions and optimize their product offerings. Adminer's suite of features includes product research, market analysis, supplier evaluation, and automated copywriting, empowering users to streamline their operations and maximize their sales potential.
AILYZE
AILYZE is an AI tool designed for qualitative data collection and analysis. Users can upload various document formats in any language to generate codes, conduct thematic, frequency, content, and cross-group analysis, extract top quotes, and more. The tool also allows users to create surveys, utilize an AI voice interviewer, and recruit participants globally. AILYZE offers different plans with varying features and data security measures, including options for advanced analysis and AI interviewer add-ons. Additionally, users can tap into data scientists for detailed and customized analyses on a wide range of documents.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Athina AI
Athina AI is a platform that provides research and guides for building safe and reliable AI products. It helps thousands of AI engineers in building safer products by offering tutorials, research papers, and evaluation techniques related to large language models. The platform focuses on safety, prompt engineering, hallucinations, and evaluation of AI models.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
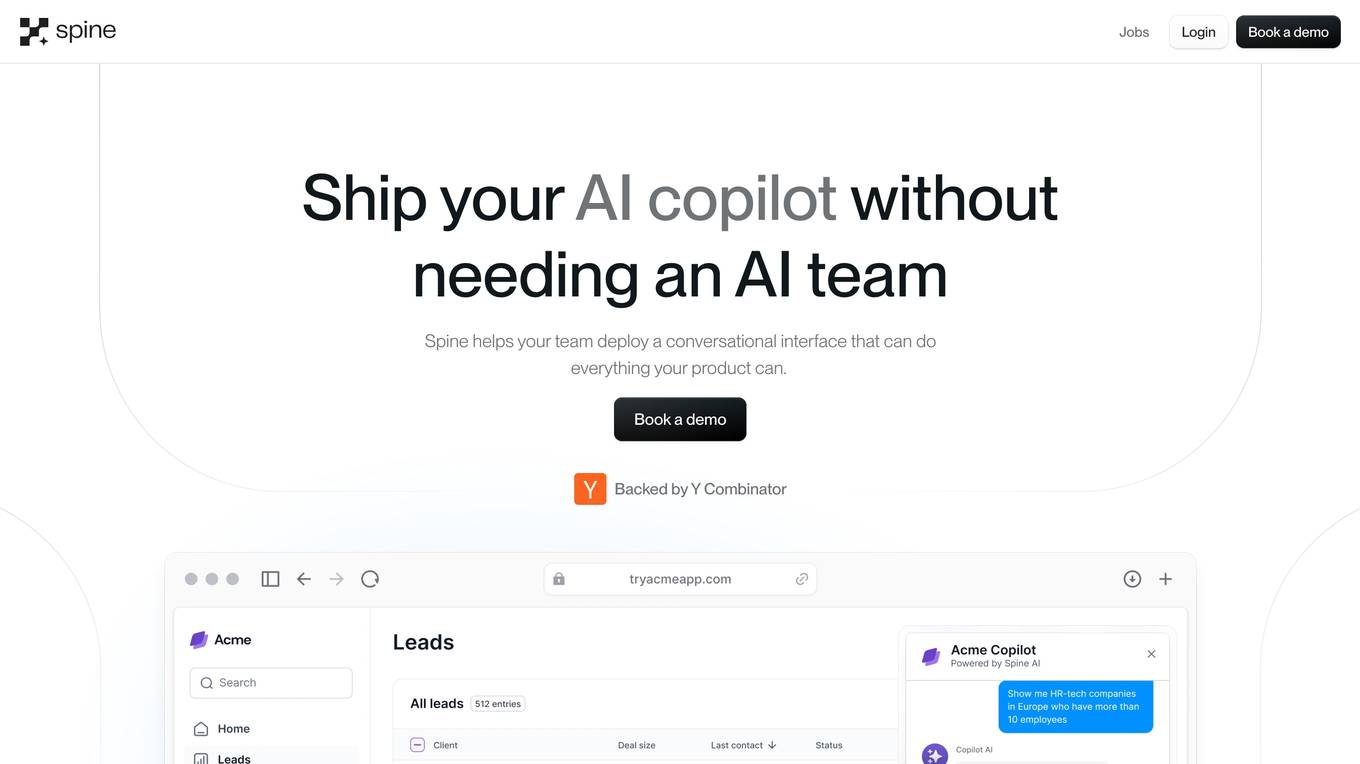
Spine AI
Spine AI is a reliable AI analyst tool that provides conversational analytics tailored to understand your business. It empowers decision-makers by offering customized insights, deep business intelligence, proactive notifications, and flexible dashboards. The tool is designed to help users make better decisions by leveraging a purpose-built Data Processing Unit (DPU) and a semantic layer for natural language interactions. With a focus on rigorous evaluation and security, Spine AI aims to deliver explainable and customizable AI solutions for businesses.
Reka
Reka is a cutting-edge AI application offering next-generation multimodal AI models that empower agents to see, hear, and speak. Their flagship model, Reka Core, competes with industry leaders like OpenAI and Google, showcasing top performance across various evaluation metrics. Reka's models are natively multimodal, capable of tasks such as generating textual descriptions from videos, translating speech, answering complex questions, writing code, and more. With advanced reasoning capabilities, Reka enables users to solve a wide range of complex problems. The application provides end-to-end support for 32 languages, image and video comprehension, multilingual understanding, tool use, function calling, and coding, as well as speech input and output.
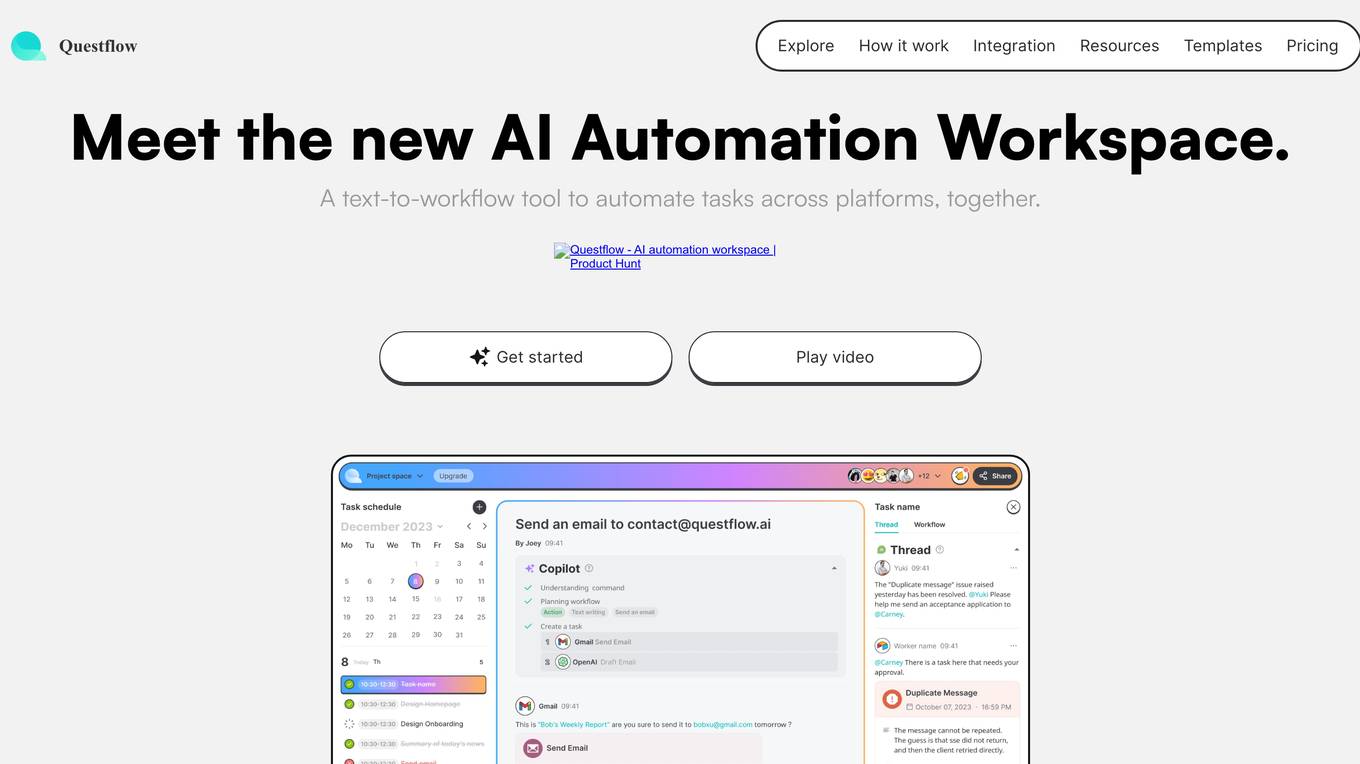
Questflow
Questflow is a decentralized AI agent economy platform that allows users to orchestrate multiple AI agents to gather insights, take action, and earn rewards autonomously. It serves as a co-pilot for work, helping knowledge workers automate repetitive tasks in a private, safety-first approach. The platform offers features such as multi-agent orchestration, user-friendly dashboard, visual reports, smart keyword generator, content evaluation, SEO goal setting, automated alerts, actionable SEO tips, regular SEO goal setting, and link optimization wizard.
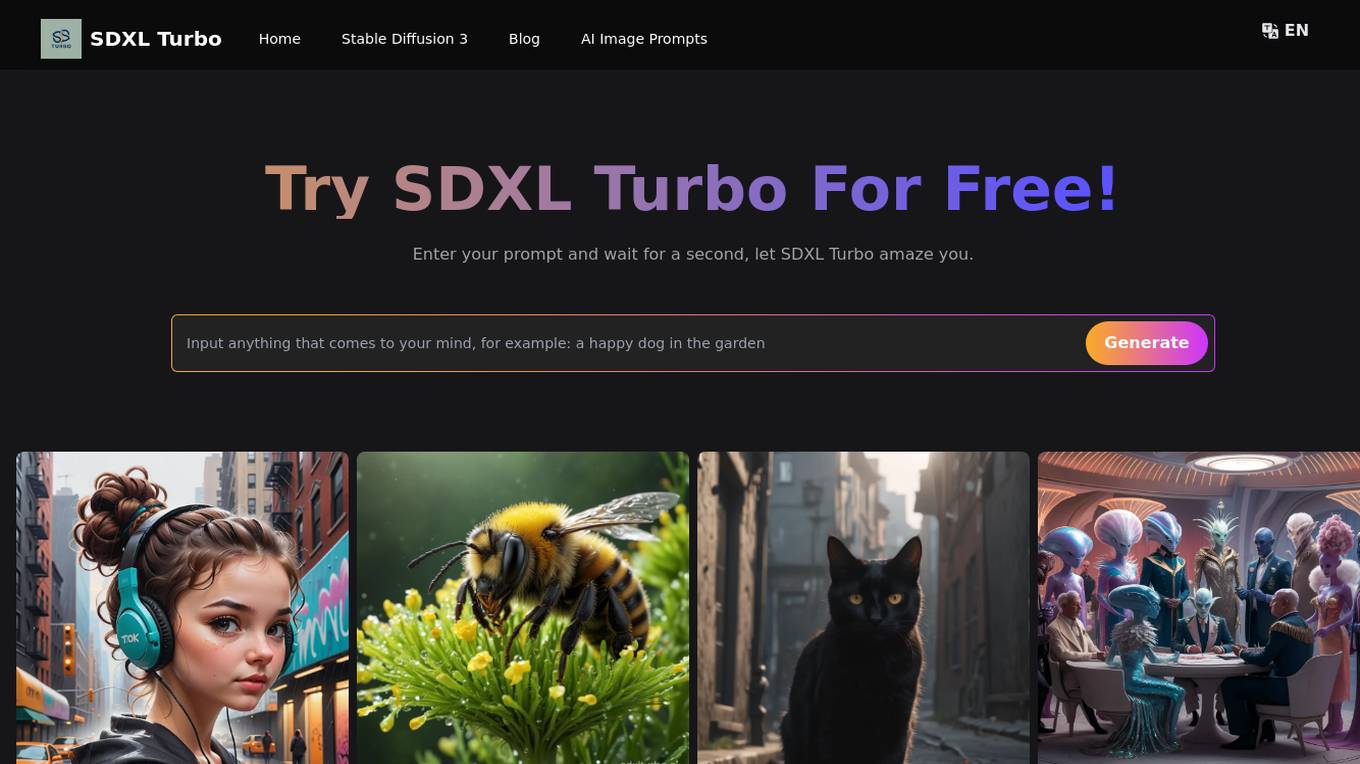
SDXL Turbo
SDXL Turbo is a cutting-edge text-to-image generation model that leverages Adversarial Diffusion Distillation (ADD) technology for high-quality, real-time image synthesis. Developed by Stability AI, SDXL Turbo is a distilled version of the SDXL 1.0 model, specifically trained for real-time synthesis. It excels in generating photorealistic images from text prompts in a single network evaluation, making it ideal for applications demanding speed and efficiency, such as video games, virtual reality, and instant content creation. SDXL Turbo is accessible to both professionals and hobbyists alike, with simple setup requirements and an intuitive interface. It presents unparalleled opportunities for research and development in advanced AI and image synthesis.
0 - Open Source AI Tools
20 - OpenAI Gpts

Project Post-Project Evaluation Advisor
Optimizes project outcomes through comprehensive post-project evaluations.

Content Evaluator
Analyzes and rates your writing using insights derived from studying LinkedIn influencers' top performing posts from the last 4 years.

API Evaluator Pro
Examines and evaluates public API documentation and offers detailed guidance for improvements, including AI usability



Financial Sentiment Analyst
A sentiment analysis tool for evaluating management-related texts.

GPT Searcher
Specializes in web searches for chat.openai.com using specific query format.


Angular Architect AI: Generate Angular Components
Generates Angular components based on requirements, with a focus on code-first responses.
🖌️ Line to Image: Generate The Evolved Prompt!
Transforms lines into detailed prompts for visual storytelling.