Best AI tools for< Evaluate Response >
20 - AI tool Sites

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

RFxAI
RFxAI is a cutting-edge AI tool designed to empower intelligence for Request for Proposals (RFPs). It is a platform that offers efficient cost-saving and speed through automation to help users generate, analyze, score, evaluate, and optimize their RFPs. RFxAI aims to transform RFP dynamics by boosting success rates by over 80%. With a focus on elevating RFx responses, RFxAI is positioned as the winning business proposal platform for B2B SaaS RFPs.
Xobin
Xobin is an AI tool that offers AI Interviews, a feature that revolutionizes the candidate assessment process. It utilizes a smart Copilot to conduct automated, role-specific interviews, providing real-time analysis of candidate responses. This innovation streamlines the recruitment process by reducing manual effort for recruiters and ensuring a structured and unbiased evaluation process. Xobin generates detailed reports that include questions asked, responses given, and insights into candidates' communication, reasoning, and domain expertise.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.

Whitetable
Whitetable is an AI tool that simplifies the hiring process by providing intelligent AI APIs for ultra-fast and optimal hiring. It offers features such as Resume Parsing API, Question API, Ranking API, and Evaluation API to streamline the recruitment process. Whitetable also provides a free AI-powered job search platform and an AI-powered ATS to help companies find the right candidates faster. With a focus on eliminating bias and improving efficiency, Whitetable is shaping the AI-driven future of hiring.
Gen AI Interviewer
Gen AI Interviewer is an AI-powered tool designed to conduct interviews. It utilizes artificial intelligence to simulate real interview scenarios and evaluate candidates' responses. By leveraging advanced algorithms, it provides valuable insights to recruiters and hiring managers, helping them make informed decisions in the hiring process. With Gen AI Interviewer, users can streamline their interview process, save time, and improve the overall efficiency of candidate evaluation.
AI-Responder for HostAway
AI-Responder for HostAway is a Chrome extension powered by Kortex Invest AI that significantly reduces writing time by 98%. It offers automated responses based on property-specific knowledge documents, guest data, and previous chat history. The AI tool is designed to provide high-quality responses, with a focus on accuracy and efficiency, particularly in the gambling industry. It helps users navigate complex topics, such as evaluating online casino platforms, by offering quick solutions and convenient workflow. The tool aims to save time and enhance decision-making processes by leveraging advanced AI models.
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
myInterview
myInterview is an AI tool designed for intelligent candidate video screening. It utilizes artificial intelligence to streamline the recruitment process by analyzing video interviews. The tool helps employers efficiently evaluate candidates' communication skills, personality traits, and overall suitability for the job role. With myInterview, organizations can save time and resources typically spent on traditional screening methods, leading to faster hiring decisions and improved candidate experience.
Kerplunk
Kerplunk is an AI-powered video interviewing tool designed to streamline the recruitment process. It leverages artificial intelligence to analyze candidate responses, body language, and facial expressions, providing valuable insights to recruiters. With Kerplunk, organizations can conduct remote interviews efficiently and make data-driven hiring decisions. The platform offers a user-friendly interface and customizable features to meet the unique needs of each organization.
JobSynergy
JobSynergy is an AI-powered platform that revolutionizes the hiring process by automating and conducting interviews at scale. It offers a real-world interview simulator that adapts dynamically to candidates' responses, custom questions and metrics evaluation, cheating detection using eye, voice, and screen, and detailed reports for better hiring decisions. The platform enhances efficiency, candidate experience, and ensures security and integrity in the hiring process.
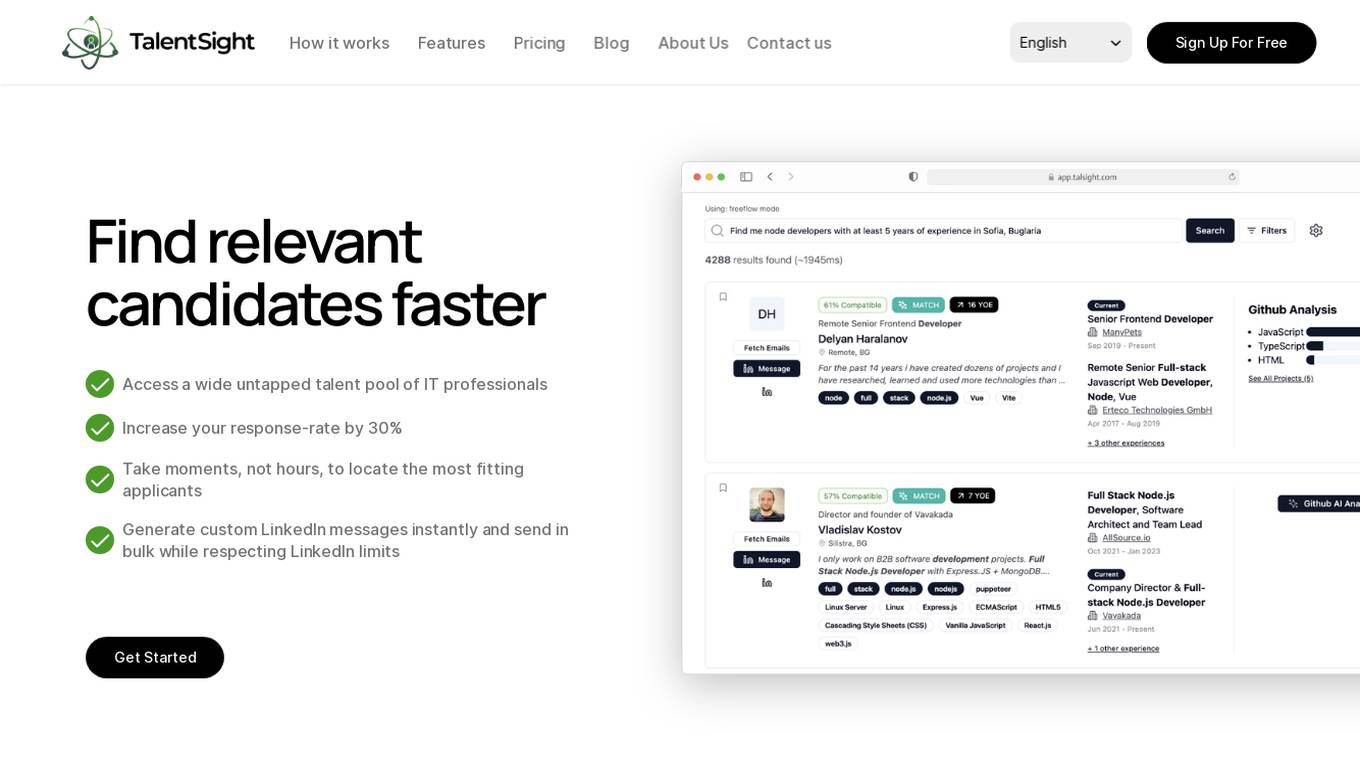
TalentSight
TalentSight is an AI-powered recruitment tool that revolutionizes the hiring process by providing access to a wide untapped talent pool of IT professionals. It helps recruiters find and engage with top talent tailored to specific requirements efficiently and effectively. The platform offers features like seamless integration with LinkedIn, personalized messaging, AI-assisted candidate evaluation, and comprehensive candidate management. TalentSight aims to streamline recruitment operations, optimize time-to-hire, and improve response rates, making it a valuable asset for recruitment agencies and HR departments.
Conversational Finance
Vianai's Conversational Finance is an AI application that revolutionizes financial analysis by providing real-time insights through generative AI. It empowers finance teams to make informed decisions swiftly and confidently by scanning vast amounts of data, generating accurate responses, and streamlining processes. The platform offers unparalleled speed, precision, and user experience, making it easier to navigate complex financial landscapes and accomplish more in less time.
Prolific
Prolific is a platform that allows users to quickly find research participants they can trust. It offers a diverse participant pool, including domain experts and API integration. Prolific ensures high-quality human-powered datasets in less than 2 hours, trusted by over 3000 organizations. The platform is designed for ease of use, with self-serve options and scalability. It provides rich, accurate, and comprehensive responses from engaged participants, verified through manual and algorithmic quality checks.
Fairo
Fairo is a platform that facilitates Responsible AI Governance, offering tools for reducing AI hallucinations, managing AI agents and assets, evaluating AI systems, and ensuring compliance with various regulations. It provides a comprehensive solution for organizations to align their AI systems ethically and strategically, automate governance processes, and mitigate risks. Fairo aims to make responsible AI transformation accessible to organizations of all sizes, enabling them to build technology that is profitable, ethical, and transformative.
Lumenova AI
Lumenova AI is an AI platform that focuses on making AI ethical, transparent, and compliant. It provides solutions for AI governance, assessment, risk management, and compliance. The platform offers comprehensive evaluation and assessment of AI models, proactive risk management solutions, and simplified compliance management. Lumenova AI aims to help enterprises navigate the future confidently by ensuring responsible AI practices and compliance with regulations.
AI Alliance
The AI Alliance is a community dedicated to building and advancing open-source AI agents, data, models, evaluation, safety, applications, and advocacy to ensure everyone can benefit. They focus on various areas such as skills and education, trust and safety, applications and tools, hardware enablement, foundation models, and advocacy. The organization supports global AI skill-building, education, and exploratory research, creates benchmarks and tools for safe generative AI, builds capable tools for AI model builders and developers, fosters AI hardware accelerator ecosystem, enables open foundation models and datasets, and advocates for regulatory policies for healthy AI ecosystems.

Persado Motivation AI
Persado Motivation AI is an Enterprise AI platform that generates, optimizes, and personalizes marketing language at scale. It offers a full stack GenAI platform with integrations for governance, security, and privacy capabilities. Persado caters to various industries such as Financial Services, Retail & Ecommerce, Telecommunications, and Travel & Hospitality, providing personalized outputs and superior outcomes at scale without risk.
Frontier Model Forum
The Frontier Model Forum (FMF) is a collaborative effort among leading AI companies to advance AI safety and responsibility. The FMF brings together technical and operational expertise to identify best practices, conduct research, and support the development of AI applications that meet society's most pressing needs. The FMF's core objectives include advancing AI safety research, identifying best practices, collaborating across sectors, and helping AI meet society's greatest challenges.

AI Security Institute (AISI)
The AI Security Institute (AISI) is a state-backed organization dedicated to advancing AI governance and safety. They conduct rigorous AI research to understand the impacts of advanced AI, develop risk mitigations, and collaborate with AI developers and governments to shape global policymaking. The institute aims to equip governments with a scientific understanding of the risks posed by advanced AI, monitor AI development, evaluate national security risks, and promote responsible AI development. With a team of top technical staff and partnerships with leading research organizations, AISI is at the forefront of AI governance.
1 - Open Source AI Tools

pocketgroq
PocketGroq is a tool that provides advanced functionalities for text generation, web scraping, web search, and AI response evaluation. It includes features like an Autonomous Agent for answering questions, web crawling and scraping capabilities, enhanced web search functionality, and flexible integration with Ollama server. Users can customize the agent's behavior, evaluate responses using AI, and utilize various methods for text generation, conversation management, and Chain of Thought reasoning. The tool offers comprehensive methods for different tasks, such as initializing RAG, error handling, and tool management. PocketGroq is designed to enhance development processes and enable the creation of AI-powered applications with ease.
20 - OpenAI Gpts
Environmental Disaster Analyst
Simulates and analyzes potential environmental disaster scenarios for preparedness.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.

Global Health Oracle
Leading AI expert in Global Health & Pandemic Response, offering unparalleled insights and solutions.
Course Architect
Assists in course design, offering expandable responses based on user input.

Learn about Responsible Innovation
A personal guide to socially responsible and beneficial innovation

Emergency Training
Provides emergency training assistance with a focus on safety and clear guidelines.


Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms


