Best AI tools for< Build Pipeline >
20 - AI tool Sites
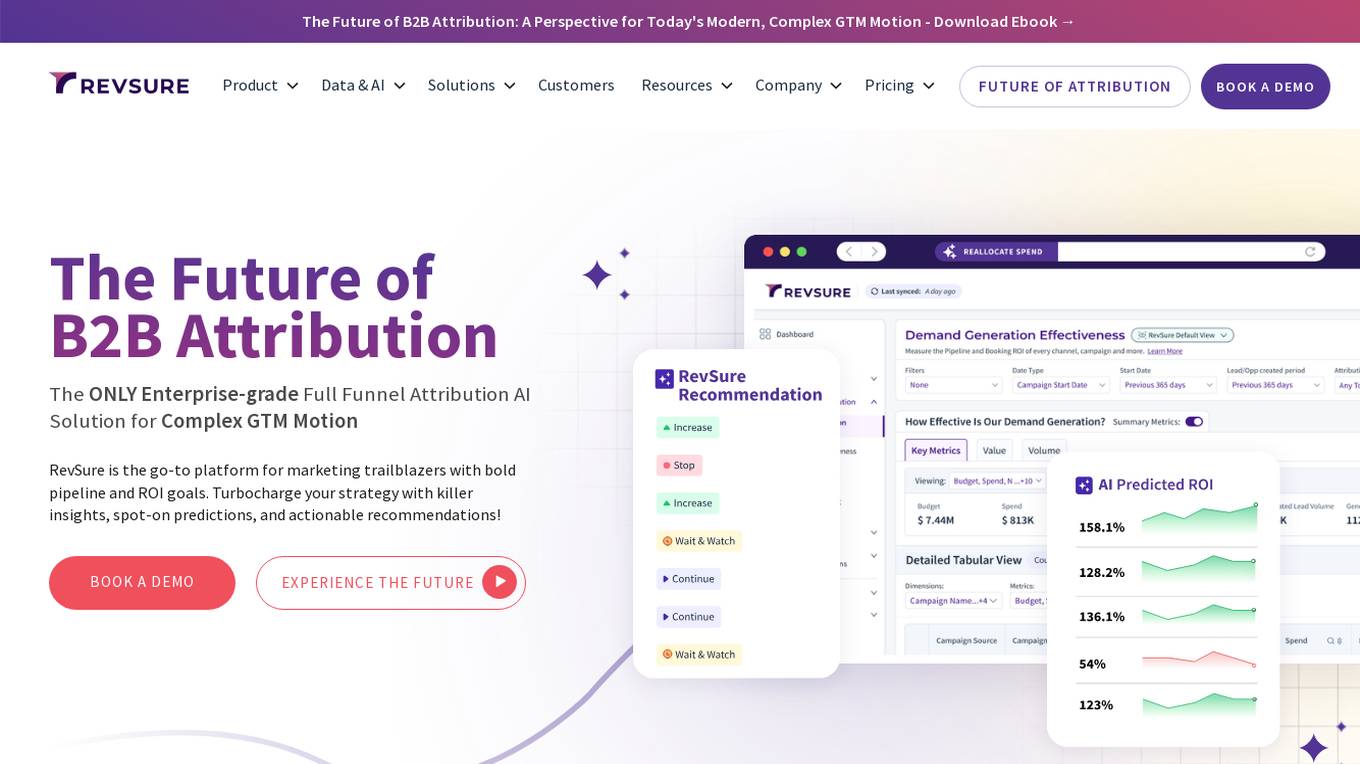
RevSure
RevSure is an AI-powered platform designed for high-growth marketing teams to optimize marketing ROI and attribution. It offers full-funnel attribution, deep funnel optimization, predictive insights, and campaign performance tracking. The platform integrates with various data sources to provide unified funnel reporting and personalized recommendations for improving pipeline health and conversion rates. RevSure's AI engine powers features like campaign spend reallocation, next-best touch analysis, and journey timeline construction, enabling users to make data-driven decisions and accelerate revenue growth.
Fetcher
Fetcher is an AI candidate sourcing tool designed for recruiters to streamline the talent acquisition process. It leverages advanced AI technology and expert teams to efficiently source high-quality candidate profiles that match specific hiring requirements. The tool also provides smart recruitment analytics, personalized diversity search criteria, and verified contact information to enhance candidate engagement and streamline the recruitment process. With robust technology integrations and a focus on automating processes, Fetcher aims to help companies of all sizes attract top talent and optimize their recruitment strategies.
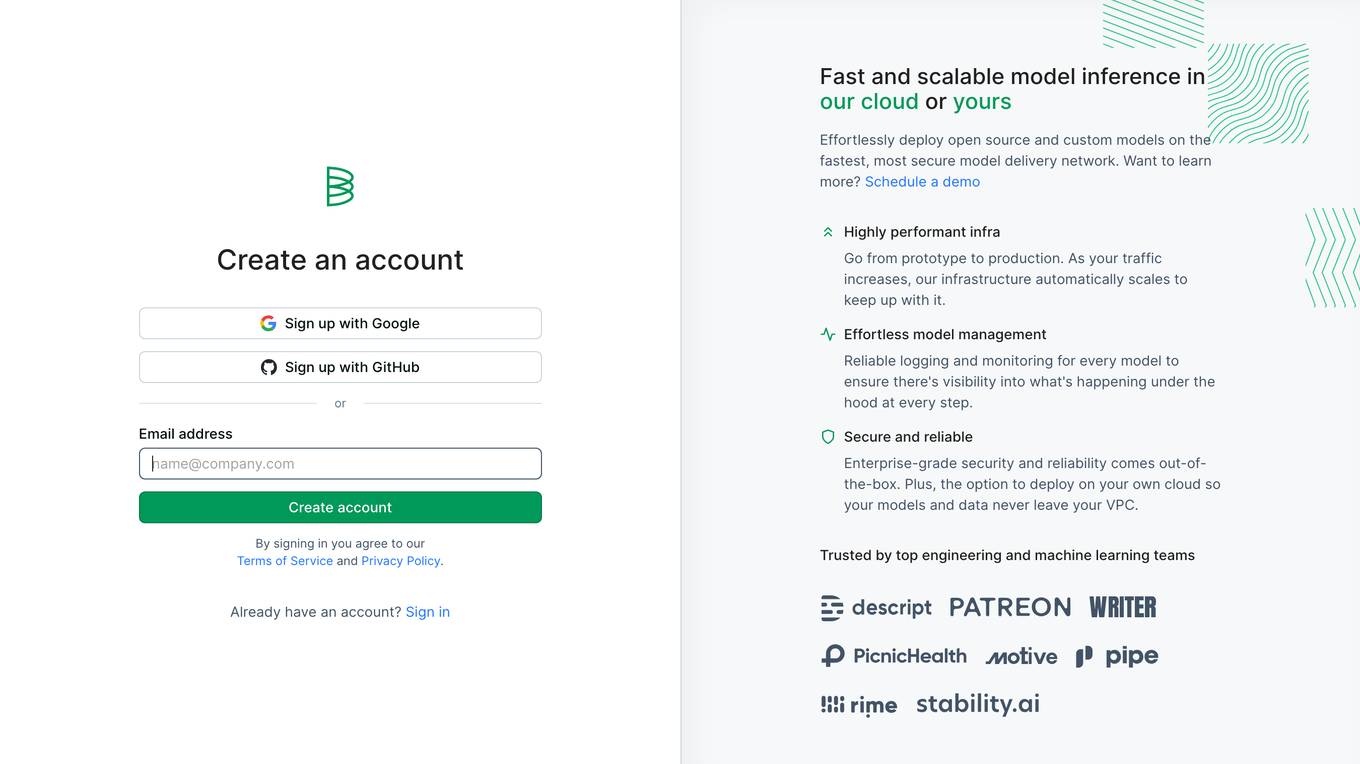
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
DVC
DVC is an open-source version control system for machine learning projects. It allows users to track and manage their data, models, and code in a single place. DVC also provides a number of features that make it easy to collaborate on machine learning projects, such as experiment tracking, model registration, and pipeline management.
Lume AI
Lume AI is an AI-powered data mapping suite that automates the process of mapping, cleaning, and validating data in various workflows. It offers a comprehensive solution for building pipelines, onboarding customer data, and more. With AI-driven insights, users can streamline data analysis, mapper generation, deployment, and maintenance. Lume AI provides both a no-code platform and API integration options for seamless data mapping. Trusted by market leaders and startups, Lume AI ensures data security with enterprise-grade encryption and compliance standards.
Tablesmith
Tablesmith is a free, privacy-first, and intuitive spreadsheet automation tool that allows users to build reusable data flows, effortlessly sort, filter, group, format, or split data across files/sheets based on cell values. It is designed to be easy to learn and use, with a focus on privacy and cross-platform compatibility. Tablesmith also offers an AI autofill feature that suggests and fills in information based on the user's prompt.
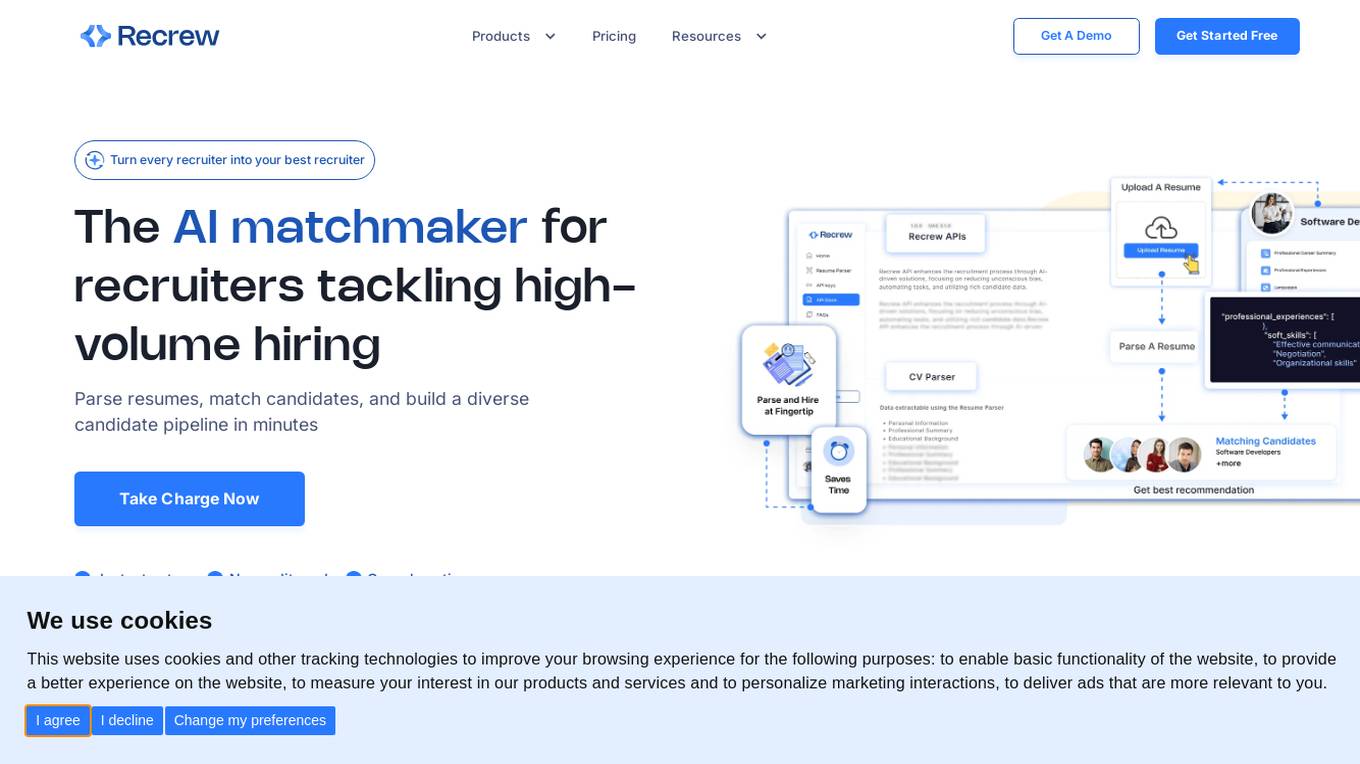
Recrew AI
Recrew AI is an AI-powered recruitment tool that revolutionizes the hiring process by leveraging artificial intelligence to parse resumes, match candidates, and build a diverse candidate pipeline in minutes. It helps recruiters overcome challenges such as sorting profiles, extracting accurate data, reducing lean time, identifying top talent, expanding talent pools, and making data-driven hiring decisions. Recrew AI aims to streamline recruitment processes, eliminate manual errors, reduce bias, and enhance overall efficiency in the recruitment industry.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.
Nektar
Nektar is an AI-driven GTM automation platform that offers comprehensive control over customer data synchronization, including contacts, opportunity contact roles, GTM activities, and activity insights. It helps in matching sales processes and security needs efficiently. Trusted by high-performing global revenue teams, Nektar enables users to build more pipeline, win deals faster, and renew and expand customers. The platform leverages AI to transform buyer data at scale, providing visibility into buying groups, meeting quality, and contact roles. Nektar is designed to enhance customer success journeys, drive better renewal outcomes, and improve pipeline inspection using high-quality engagement data.
ColdIQ
ColdIQ is an AI-powered sales prospecting tool that helps B2B companies with revenue above $100k/month to build outbound systems that sell for them. The tool offers end-to-end cold outreach campaign setup and management, email infrastructure setup and warmup, audience research and targeting, data scraping and enrichment, campaigns optimization, sending automation, sales systems implementation, training on tools best practices, sales tools recommendations, free gap analysis, sales consulting, and copywriting frameworks. ColdIQ leverages AI to tailor messaging to each prospect, automate outreach, and flood calendars with opportunities.
Gem
Gem is an AI recruiting platform that helps talent acquisition teams maximize productivity, hire faster, and save money. It offers solutions tailored to the needs of startups, growth companies, and enterprises, with features such as AI-powered CRM, sourcing, scheduling, analytics, and more. Gem unifies the recruiting tech stack, achieves outcome-driven recruitment, and proactively builds high-quality pipelines. The platform enhances productivity with ethical AI, improves equity in the hiring process, and drives predictability and efficiency in recruiting operations.
Global Blockchain Show
The Global Blockchain Show is an annual event that brings together experts and enthusiasts in the blockchain and AI industries. The event features a variety of speakers, workshops, and exhibitions, and provides a platform for attendees to learn about the latest developments in these fields. The 2024 Global Blockchain Show will be held in Dubai, UAE, from April 16-17. The event will feature a keynote address from Sophia, the world's most famous humanoid robot, as well as presentations from other leading experts in the blockchain and AI fields. Attendees will also have the opportunity to network with other professionals in the industry and learn about the latest products and services from leading companies. The Global Blockchain Show is a must-attend event for anyone interested in the latest developments in blockchain and AI.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.
Glozo
Glozo is an AI-powered sourcing platform designed to streamline recruitment processes by matching job requirements to suitable candidates efficiently. The platform utilizes AI to enhance sourcing accuracy, reduce time-to-hire, and minimize costs for recruiters. Glozo offers features such as AI-powered candidate search, automated screening, and access to a vast talent database from various sources. The platform caters to recruiters in the tech industry, finance sector, and other fields, helping them build stronger talent pipelines and make informed hiring decisions.
ML Clever
ML Clever is a no-code machine learning platform that empowers users to build powerful ML models with one click, explore what-if scenarios to guide decisions, and create interactive dashboards to explain results. It combines automated machine learning, interactive dashboards, and flexible prediction tools in one platform, allowing users to transform data into business insights without the need for data scientists or coding skills.

Haystack
Haystack is a production-ready open-source AI framework designed to facilitate building AI applications. It offers a flexible components and pipelines architecture, allowing users to customize and build applications according to their specific requirements. With partnerships with leading LLM providers and AI tools, Haystack provides freedom of choice for users. The framework is built for production, with fully serializable pipelines, logging, monitoring integrations, and deployment guides for full-scale deployments on various platforms. Users can build Haystack apps faster using deepset Studio, a platform for drag-and-drop construction of pipelines, testing, debugging, and sharing prototypes.
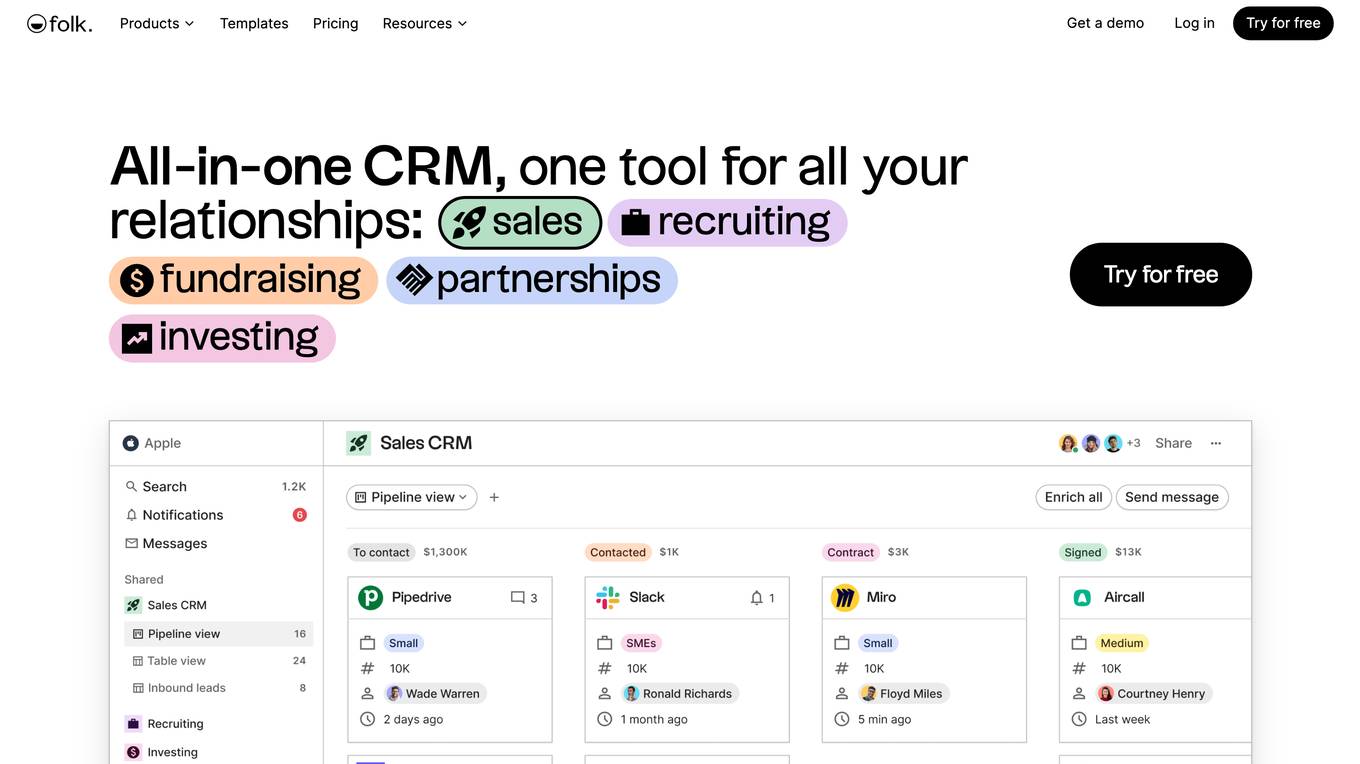
folk
folk is a CRM tool designed to help users build real relationships to close winning deals. It offers features such as 1-click enrichment, messages & sequences, dashboards, pipeline management, and integrations. With folk, users can connect their CRM to LinkedIn, Gmail, and Outlook, access workspace templates, customize pipeline views, and benefit from social media prospecting. The tool also provides email and calendar sync, 1-click enrichment for finding emails, and over 6000 integrations for syncing with favorite tools. Additionally, folk offers AI-generated variables, conversation templates, actionable insights for team collaboration, smart fields, message analytics, and customizable dashboards.

Amazon Bedrock
Amazon Bedrock is a cloud-based platform that enables developers to build, deploy, and manage serverless applications. It provides a fully managed environment that takes care of the infrastructure and operations, so developers can focus on writing code. Bedrock also offers a variety of tools and services to help developers build and deploy their applications, including a code editor, a debugger, and a deployment pipeline.
Plumb
Plumb is a no-code, node-based builder that empowers product, design, and engineering teams to create AI features together. It enables users to build, test, and deploy AI features with confidence, fostering collaboration across different disciplines. With Plumb, teams can ship prototypes directly to production, ensuring that the best prompts from the playground are the exact versions that go to production. It goes beyond automation, allowing users to build complex multi-tenant pipelines, transform data, and leverage validated JSON schema to create reliable, high-quality AI features that deliver real value to users. Plumb also makes it easy to compare prompt and model performance, enabling users to spot degradations, debug them, and ship fixes quickly. It is designed for SaaS teams, helping ambitious product teams collaborate to deliver state-of-the-art AI-powered experiences to their users at scale.
Rocket
Rocket is an AI-powered platform that allows users to build production-ready mobile apps and websites without the need for coding. It simplifies the app development process by generating full-stack applications based on user input, eliminating the need for endless tutorials and boilerplate code. Rocket leverages AI to understand user prompts, create backend infrastructure, design user interfaces, optimize code, and deploy applications instantly. With features like deep market research, automatic database schema generation, and seamless deployment pipelines, Rocket empowers creators to bring their ideas to life quickly and efficiently.
0 - Open Source AI Tools
20 - OpenAI Gpts

Fundraising GPT
Auto Fundraising is trained on 1000+ VCs info and is expert in building investor pipelines. It can help you in finding the best VCs in your field, can build up a complete investor pipeline and can give you tailored pitching advice to get deals faster.
Data Engineer
A Data Engineer assistant offering advice on data pipelines and data-related tasks.
Tech Guru
Meet Tech Guru, your go-to AI for data engineering, coding expertise, and graph databases. Combining humor, reliability, and approachability to simplify tech with a personal touch.


Data Engineer Consultant
Guides in data engineering tasks with a focus on practical solutions.



Build a Brand
Unique custom images based on your input. Just type ideas and the brand image is created.
Beam Eye Tracker Extension Copilot
Build extensions using the Eyeware Beam eye tracking SDK


Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model