Best AI tools for< Computer Vision Specialist >
Infographic
16 - AI tool Sites
Max Planck Institute for Informatics
The Max Planck Institute for Informatics focuses on Visual Computing and Artificial Intelligence, conducting research at the intersection of Computer Graphics, Computer Vision, and Artificial Intelligence. The institute aims to develop innovative methods to capture, represent, synthesize, and simulate real-world models with high detail, robustness, and efficiency. By combining concepts from Computer Graphics, Computer Vision, and Artificial Intelligence, the institute lays the groundwork for advanced computing systems that can interact intelligently with humans and the environment.
Labellerr
Labellerr is a data labeling software that helps AI teams prepare high-quality labels 99 times faster for Vision, NLP, and LLM models. The platform offers automated annotation, advanced analytics, and smart QA to process millions of images and thousands of hours of videos in just a few weeks. Labellerr's powerful analytics provides full control over output quality and project management, making it a valuable tool for AI labeling partners.
OpenTrain AI
OpenTrain AI is a data labeling marketplace that leverages artificial intelligence to streamline the process of labeling data for machine learning models. It provides a platform where users can crowdsource data labeling tasks to a global community of annotators, ensuring high-quality labeled datasets for training AI algorithms. With advanced AI algorithms and human-in-the-loop validation, OpenTrain AI offers efficient and accurate data labeling services for various industries such as autonomous vehicles, healthcare, and natural language processing.
Encord
Encord is a complete data development platform designed for AI applications, specifically tailored for computer vision and multimodal AI teams. It offers tools to intelligently manage, clean, and curate data, streamline labeling and workflow management, and evaluate model performance. Encord aims to unlock the potential of AI for organizations by simplifying data-centric AI pipelines, enabling the building of better models and deploying high-quality production AI faster.
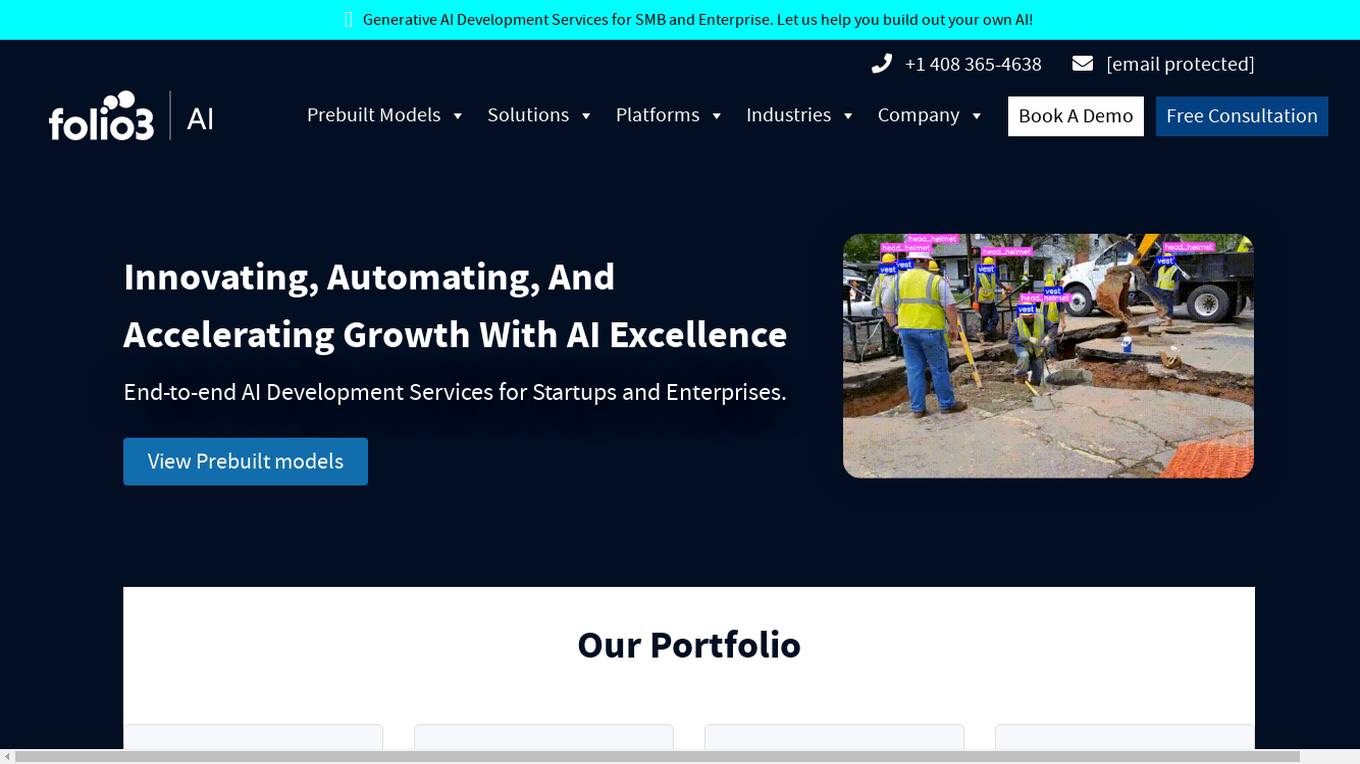
Folio3.Ai
Folio3.Ai is an end-to-end AI development company specializing in machine learning and artificial intelligence solutions for startups and enterprises. With over 15 years of experience, Folio3 offers services such as generative AI development, computer vision technology, large language models, natural language processing, predictive analytics, and more. The company empowers businesses across diverse industries with custom AI solutions and pre-built models, enabling them to innovate and thrive in today's dynamic landscape.

Vize.ai
Vize.ai is a custom image recognition API provided by Ximilar, a leading company in Visual AI and Search. The tool offers powerful artificial intelligence capabilities with high accuracy using deep learning algorithms. It allows users to easily set up and implement cutting-edge vision automation without any development costs. Vize.ai enables users to train custom neural networks to recognize specific images and provides a scalable solution with continuous improvements in machine learning algorithms. The tool features an intuitive interface that requires no machine learning or coding knowledge, making it accessible for a wide range of users across industries.
Voxel51
Voxel51 is an AI tool that provides open-source computer vision tools for machine learning. It offers solutions for various industries such as agriculture, aviation, driving, healthcare, manufacturing, retail, robotics, and security. Voxel51's main product, FiftyOne, helps users explore, visualize, and curate visual data to improve model performance and accelerate the development of visual AI applications. The platform is trusted by thousands of users and companies, offering both open-source and enterprise-ready solutions to manage and refine data and models for visual AI.
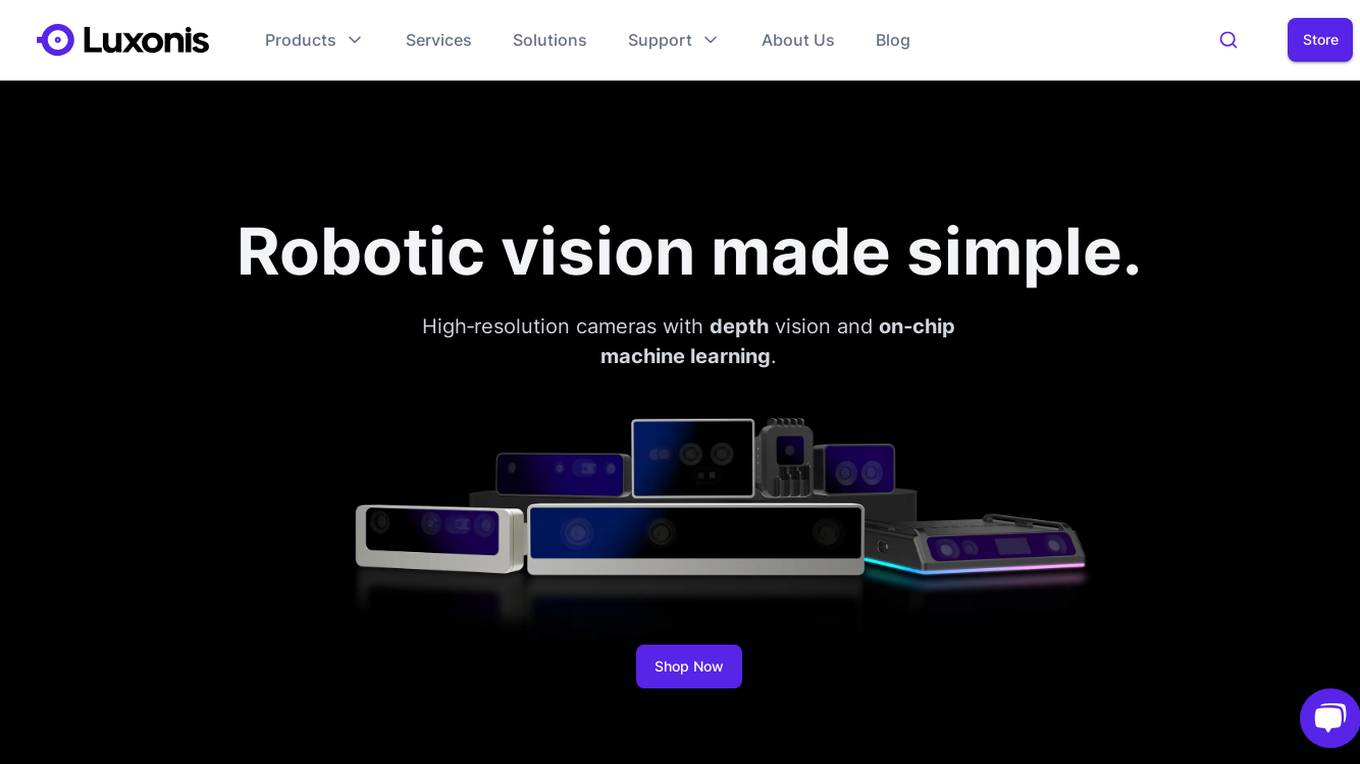
Luxonis
Luxonis is a platform that offers robotic vision solutions through high-resolution cameras with depth vision and on-chip machine learning capabilities. Their products include OAK Cameras and Modules, providing features like Stereo Depth Sensing, Computer Vision, Artificial Intelligence, and Cloud Management. Luxonis enables the development of computer vision products and companies by offering performant and affordable hardware solutions. The platform caters to enterprises and hobbyists, empowering them to easily build embedded vision systems.
Fyne AI
Fyne AI is an AI application that applies AI research in computer vision, generative AI, and machine learning to develop innovative products. The focus of the application is on automating analysis, generating insights from image and video datasets, enhancing creativity and productivity, and building prediction models. Users can subscribe to the Fyne AI newsletter to stay updated on product news and updates.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

Edge AI and Vision Alliance
The Edge AI and Vision Alliance is a platform that provides practical technical insights and expert advice for developers building AI or vision-enabled products. It offers information on the latest vision, AI, and deep learning technologies, standards, market research, and applications. The Alliance aims to help users incorporate visual and artificial intelligence into their products effectively and efficiently.
Bifrost AI
Bifrost AI is a data generation engine designed for AI and robotics applications. It enables users to train and validate AI models faster by generating physically accurate synthetic datasets in 3D simulations, eliminating the need for real-world data. The platform offers pixel-perfect labels, scenario metadata, and a simulated 3D world to enhance AI understanding. Bifrost AI empowers users to create new scenarios and datasets rapidly, stress test AI perception, and improve model performance. It is built for teams at every stage of AI development, offering features like automated labeling, class imbalance correction, and performance enhancement.
Digital Sense
Digital Sense is an AI tool that offers a wide range of AI, Machine Learning, and Computer Vision services. The company specializes in custom AI development, AI consulting services, biometrics solutions, NLP & LLMs development services, data science consulting services, remote sensing services, machine learning development services, generative AI development services, and computer vision development services. With over a decade of experience, Digital Sense helps businesses leverage cutting-edge AI technologies to solve complex technological challenges.
Hasty
CloudFactory's AI Data Platform, including the GenAI Model Oversight Platform, integrates Hasty as a powerful tool for computer vision annotation and model development. Hasty's annotation capabilities enhance AI-driven workflows within the platform, offering comprehensive solutions for data labeling, computer vision, NLP, and more.

DeepRec.ai
DeepRec.ai is a specialized recruitment platform focusing on AI and ML professionals. The platform offers hiring services for various AI specialisms such as Research GenAI, Machine Learning, Computer Vision, AI Infrastructure, Quantum Computing, Robotics & Embodied AI, and AI4Science. DeepRec.ai provides hiring solutions like Embedded Hiring, Retained Search, Contingent Contract & Flexible Resource, tailored to scale with businesses and address high-volume hiring challenges. The platform boasts positive feedback from both clients and candidates, emphasizing the quality of communication, candidate selection, and support throughout the recruitment process.
6 - Open Source Tools

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.
Awesome-Embodied-AI-Job
Awesome Embodied AI Job is a curated list of resources related to jobs in the field of Embodied Artificial Intelligence. It includes job boards, companies hiring, and resources for job seekers interested in roles such as robotics engineer, computer vision specialist, AI researcher, machine learning engineer, and data scientist.
awesome-robotics-ai-companies
A curated list of companies in the robotics and artificially intelligent agents industry, including large companies, stable start-ups, non-profits, and government research labs. The list covers companies working on autonomous vehicles, robotics, artificial intelligence, machine learning, computer vision, and more. It aims to showcase industry innovators and important players in the field of robotics and AI.
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.
20 - OpenAI Gpts
Counterfeit Detector
Specialist in authenticating products using the latest computer vision technology by Cypheme.
Detail-Oriented Image and Face Specialist
Specialist in detailed images and facial features

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie


Jimmy madman
This AI is specifically for Computer Vision usage, specifically realated to PCB component identification
Street Sign Recognition GPT
Friendly and professional guide for street sign app development.

Media AI Visionary
Leading AI & Media Expert: In-depth, Ethical, Insightful, developed on OpenAI
AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles