
scaleapi-python-client
The official Python SDK for Scale API, the Data Platform for AI
Stars: 58
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.
README:
Scale AI | Python SDK
If you use earlier versions of the SDK, please refer to v1.0.4 documentation <https://github.com/scaleapi/scaleapi-python-client/blob/release-1.0.4/README.rst>_.
If you are migrating from earlier versions to v2, please refer to Migration Guide to v2 <https://github.com/scaleapi/scaleapi-python-client/blob/master/docs/migration_guide.md>_.
|pic1| |pic2| |pic3|
.. |pic1| image:: https://pepy.tech/badge/scaleapi/month :alt: Downloads :target: https://pepy.tech/project/scaleapi .. |pic2| image:: https://img.shields.io/pypi/pyversions/scaleapi.svg :alt: Supported Versions :target: https://pypi.org/project/scaleapi .. |pic3| image:: https://img.shields.io/github/contributors/scaleapi/scaleapi-python-client.svg :alt: Contributors :target: https://github.com/scaleapi/scaleapi-python-client/graphs/contributors
{kind=link}
{kind=link}
Installation
Install with PyPI (pip)
.. code-block:: bash
$ pip install --upgrade scaleapi
or install with Anaconda (conda)
.. code-block:: bash
$ conda install -c conda-forge scaleapi
Usage
.. code-block:: python
import scaleapi
client = scaleapi.ScaleClient("YOUR_API_KEY_HERE")
If you need to use a proxy to connect Scale API, you can feed proxies, cert and verify attributes of the python requests package during the client initialization.
Proxy support is available with SDK version 2.14.0 and beyond.
Documentation of Proxies usage in requests package__
__ https://requests.readthedocs.io/en/latest/user/advanced/#proxies
.. code-block:: python
proxies = { 'https': 'http://10.10.1.10:1080' }
client = scaleapi.ScaleClient(
api_key="YOUR_API_KEY_HERE",
proxies=proxies,
cert='/path/client.cert',
verify=True
)
Tasks
Most of these methods will return a scaleapi.Task object, which will contain information
about the json response (task_id, status, params, response, etc.).
Any parameter available in Scale's API documentation__ can be passed as an argument option with the corresponding type.
__ https://scale.com/docs/api-reference/data-engine-reference#tasks-object-overview
The following endpoints for tasks are available:
Create Task ^^^^^^^^^^^
This method can be used for any Scale supported task type using the following format:
.. code-block:: python
client.create_task(TaskType, ...task parameters...)
Passing in the applicable values into the function definition. The applicable fields and further information for each task type can be found in Scale's API documentation__.
__ https://scale.com/docs/api-reference
.. code-block:: python
from scaleapi.tasks import TaskType
from scaleapi.exceptions import ScaleDuplicateResource
payload = dict(
project = "test_project",
callback_url = "http://www.example.com/callback",
instruction = "Draw a box around each baby cow and big cow.",
attachment_type = "image",
attachment = "http://i.imgur.com/v4cBreD.jpg",
unique_id = "c235d023af73",
geometries = {
"box": {
"objects_to_annotate": ["Baby Cow", "Big Cow"],
"min_height": 10,
"min_width": 10,
}
},
)
try:
client.create_task(TaskType.ImageAnnotation, **payload)
except ScaleDuplicateResource as err:
print(err.message) # If unique_id is already used for a different task
Retrieve a task ^^^^^^^^^^^^^^^
Retrieve a task given its id. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#retrieve-a-task
.. code-block :: python
task = client.get_task("30553edd0b6a93f8f05f0fee")
print(task.status) # Task status ("pending", "completed", "error", "canceled")
print(task.response) # If task is complete
Task Attributes ^^^^^^^^^^^^^^^
The older param_dict attribute is now replaced with a method as_dict() to return a task's all attributes as a dictionary (JSON).
.. code-block :: python
task.as_dict()
# {
# 'task_id': '30553edd0b6a93f8f05f0fee',
# 'created_at': '2021-06-17T21:46:36.359Z',
# 'type': 'imageannotation',
# 'status': 'pending',
# ....
# 'params': {
# 'attachment': 'http://i.imgur.com/v4cBreD.jpg',
# 'attachment_type': 'image',
# 'geometries': {
# 'box': {
# 'objects_to_annotate': ['Baby Cow', 'Big Cow'],
# 'min_height': 10,
# 'min_width': 10,
# ...
# },
# 'project': 'My Project',
# ...
# }
First-level attributes of Task are also accessible with . annotation as the following:
.. code-block :: python
task.status # same as task.as_dict()["status"]
task.params["geometries"] # same as task.as_dict()["params"]["geometries"]
task.response["annotations"] # same as task.as_dict()["response"]["annotations"]
Accessing task.params child objects directly at task level is deprecated. Instead of task.attribute, you should use task.params["attribute"] for accessing objects under params.
.. code-block :: python
task.params["geometries"] # task.geometries is DEPRECATED
task.params["attachment"] # task.attachment is DEPRECATED
If you use the limited_response = True filter in get_tasks(), you will only receive the following attributes: task_id, status, metadata, project and otherVersion.
Retrieve List of Tasks ^^^^^^^^^^^^^^^^^^^^^^
Retrieve a list of Task objects, with filters for: project_name, batch_name, type, status,
review_status, unique_id, completed_after, completed_before, updated_after, updated_before,
created_after, created_before, tags, limited_response and limit.
get_tasks() is a generator method and yields Task objects.
A generator is another type of function, returns an iterable that you can loop over like a list. However, unlike lists, generators do not store the content in the memory. That helps you to process a large number of objects without increasing memory usage.
If you will iterate through the tasks and process them once, using a generator is the most efficient method.
However, if you need to process the list of tasks multiple times, you can wrap the generator in a list(...)
statement, which returns a list of Tasks by loading them into the memory.
Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#retrieve-multiple-tasks
.. code-block :: python
from scaleapi.tasks import TaskReviewStatus, TaskStatus
tasks = client.get_tasks(
project_name = "My Project",
created_after = "2020-09-08",
completed_before = "2021-04-01",
status = TaskStatus.Completed,
review_status = TaskReviewStatus.Accepted
)
# Iterating through the generator
for task in tasks:
# Download task or do something!
print(task.task_id)
# For retrieving results as a Task list
task_list = list(tasks)
print(f"{len(task_list)} tasks retrieved")
Get Tasks Count ^^^^^^^^^^^^^^^
get_tasks_count() method returns the number of tasks with the given optional parameters for: project_name, batch_name, type, status,
review_status, unique_id, completed_after, completed_before, updated_after, updated_before,
created_after, created_before and tags.
.. code-block :: python
from scaleapi.tasks import TaskReviewStatus, TaskStatus
task_count = client.get_tasks_count(
project_name = "My Project",
created_after = "2020-09-08",
completed_before = "2021-04-01",
status = TaskStatus.Completed,
review_status = TaskReviewStatus.Accepted
)
print(task_count) # 1923
Cancel Task ^^^^^^^^^^^
Cancel a task given its id if work has not started on the task (task status is Queued in the UI). Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#cancel-task
.. code-block :: python
task = client.cancel_task('30553edd0b6a93f8f05f0fee')
# If you also want to clear 'unique_id' of a task while canceling
task = client.cancel_task('30553edd0b6a93f8f05f0fee', clear_unique_id=True)
# cancel() is also available on task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
task.cancel()
# If you also want to clear 'unique_id' of a task while canceling
task.cancel(clear_unique_id=True)
Audit a Task ^^^^^^^^^^^^
This method allows you to accept or reject completed tasks, along with support for adding comments about the reason for the given audit status, mirroring our Audit UI.
Check out Scale's API documentation__ for more information.
__ https://docs.scale.com/reference/audit-a-task
.. code-block :: python
# Accept a completed task by submitting an audit
client.audit_task('30553edd0b6a93f8f05f0fee', True)
# Reject a completed task by submitting a comment with the audit
client.audit_task('30553edd0b6a93f8f05f0fee', False, 'Rejected due to quality')
# audit() is also available on Task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
task.audit(True)
Update A Task's Unique Id ^^^^^^^^^^^^^^^^^^^^^^^^^
Update a given task's unique_id. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#update-unique_id
.. code-block :: python
task = client.update_task_unique_id('30553edd0b6a93f8f05f0fee', "new_unique_id")
# update_unique_id() is also available on task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
task.update_unique_id("new_unique_id")
Clear A Task's Unique Id ^^^^^^^^^^^^^^^^^^^^^^^^^
Clear a given task's unique_id. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#delete-unique_id
.. code-block :: python
task = client.clear_task_unique_id('30553edd0b6a93f8f05f0fee')
# clear_unique_id() is also available on task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
task.clear_unique_id()
Set A Task's Metadata ^^^^^^^^^^^^^^^^^^^^^^^^^
Set a given task's metadata. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#set-task-metadata
.. code-block :: python
# set metadata on a task by specifying task id
new_metadata = {'myKey': 'myValue'}
task = client.set_task_metadata('30553edd0b6a93f8f05f0fee', new_metadata)
# set metadata on a task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
new_metadata = {'myKey': 'myValue'}
task.set_metadata(new_metadata)
Set A Task's Tags ^^^^^^^^^^^^^^^^^^^^^^^^^
Set a given task's tags. This will replace all existing tags on a task. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#set-task-tag
.. code-block :: python
# set a list of tags on a task by specifying task id
new_tags = ["tag1", "tag2", "tag3"]
task = client.set_task_tags('30553edd0b6a93f8f05f0fee', new_tags)
# set a list of tags on a task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
new_tags = ["tag1", "tag2", "tag3"]
task.set_tags(new_tags)
Add Tags to A Task ^^^^^^^^^^^^^^^^^^^^^^^^^
Add tags to a given task. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#delete-task-tag
.. code-block :: python
# add a list of tags on a task by specifying task id
tags_to_add = ["tag4", "tag5"]
task = client.add_task_tags('30553edd0b6a93f8f05f0fee', tags_to_add)
# add a list of tags on a task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
tags_to_add = ["tag4", "tag5"]
task.add_tags(tags_to_add)
Delete Tags from A Task ^^^^^^^^^^^^^^^^^^^^^^^^^
Delete tags from a given task. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/tasks#delete-task-tag
.. code-block :: python
# delete a list of tags on a task by specifying task id
tags_to_delete = ["tag1", "tag2"]
task = client.delete_task_tags('30553edd0b6a93f8f05f0fee', tags_to_delete)
# delete a list of tags on a task object
task = client.get_task('30553edd0b6a93f8f05f0fee')
tags_to_delete = ["tag1", "tag2"]
task.delete_tags(tags_to_delete)
Batches
Create Batch ^^^^^^^^^^^^
Create a new Batch. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/batches#create-a-batch
.. code-block:: python
batch = client.create_batch(
project = "test_project",
callback = "http://www.example.com/callback",
batch_name = "batch_name_01_07_2021"
)
print(batch.name) # batch_name_01_07_2021
Throws ScaleDuplicateResource exception if a batch with the same name already exists.
Finalize Batch ^^^^^^^^^^^^^^^
Finalize a Batch. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/batches#finalize-batch
.. code-block:: python
client.finalize_batch(batch_name="batch_name_01_07_2021")
# Alternative method
batch = client.get_batch(batch_name="batch_name_01_07_2021")
batch.finalize()
Check Batch Status ^^^^^^^^^^^^^^^^^^
Get the status of a Batch. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/batches#batch-status
.. code-block:: python
client.batch_status(batch_name = "batch_name_01_07_2021")
# Alternative via Batch.get_status()
batch = client.get_batch("batch_name_01_07_2021")
batch.get_status() # Refreshes tasks_{status} attributes of Batch
print(batch.tasks_pending, batch.tasks_completed)
Retrieve A Batch ^^^^^^^^^^^^^^^^
Retrieve a single Batch. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/batches#batch-retrieval
.. code-block:: python
batch = client.get_batch(batch_name = "batch_name_01_07_2021")
The older param_dict attribute is now replaced with a method batch.as_dict() to return a batch's all attributes as a dictionary (JSON).
List Batches ^^^^^^^^^^^^
Retrieve a list of Batches. Optional parameters are project_name, batch_status, exclude_archived, created_after and created_before.
get_batches() is a generator method and yields Batch objects.
A generator is another type of function, returns an iterable that you can loop over like a list. However, unlike lists, generators do not store the content in the memory. That helps you to process a large number of objects without increasing memory usage.
When wrapped in a list(...) statement, it returns a list of Batches by loading them into the memory.
Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/batches#list-all-batches
.. code-block :: python
from scaleapi.batches import BatchStatus
batches = client.get_batches(
batch_status=BatchStatus.Completed,
created_after = "2020-09-08"
)
counter = 0
for batch in batches:
counter += 1
print(f"Downloading batch {counter} | {batch.name} | {batch.project}")
# Alternative for accessing as a Batch list
batch_list = list(batches)
print(f"{len(batch_list))} batches retrieved")
Projects
Create Project ^^^^^^^^^^^^^^
Create a new Project. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/projects#create-project
.. code-block:: python
from scaleapi.tasks import TaskType
project = client.create_project(
project_name = "Test_Project",
task_type = TaskType.ImageAnnotation,
params = {"instruction": "Please label the kittens"},
)
print(project.name) # Test_Project
Specify rapid=true for Rapid projects and studio=true for Studio projects. Throws ScaleDuplicateResource exception if a project with the same name already exists.
Retrieve Project ^^^^^^^^^^^^^^^^
Retrieve a single Project. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/projects#project-retrieval
.. code-block:: python
project = client.get_project(project_name = "test_project")
The older param_dict attribute is now replaced with a method project.as_dict() to return a project's all attributes as a dictionary (JSON).
List Projects ^^^^^^^^^^^^^
This function does not take any arguments. Retrieve a list of every Project.
Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/projects#list-all-projects
.. code-block :: python
counter = 0
projects = client.projects()
for project in projects:
counter += 1
print(f'Downloading project {counter} | {project.name} | {project.type}')
Update Project ^^^^^^^^^^^^^^
Creates a new version of the Project. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/projects#update-project-parameters
.. code-block :: python
data = client.update_project(
project_name="test_project",
patch=False,
instruction="update: Please label all the stuff",
)
Files
Files are a way of uploading local files directly to Scale storage or importing files before creating tasks.
Upload Files ^^^^^^^^^^^^^^
Upload a file. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/file-endpoints#file-upload
.. code-block:: python
with open(file_name, 'rb') as f:
my_file = client.upload_file(
file=f,
project_name = "test_project",
)
The file.attachment_url can be used in place of attachments in task payload.
.. code-block:: python
my_file.as_dict()
# {
# 'attachment_url': 'scaledata://606e2a0a46102303a130949/8ac09a90-c143-4154-9a9b-6c35121396d1f',
# 'created_at': '2021-06-17T21:56:53.825Z',
# 'id': '8ac09d70-ca43-4354-9a4b-6c3591396d1f',
# 'mime_type': 'image/png',
# 'project_names': ['test_project'],
# 'size': 340714,
# 'updated_at': '2021-06-17T21:56:53.825Z'
# }
Import Files ^^^^^^^^^^^^^^
Import a file from a URL. Check out Scale's API documentation__ for more information.
__ https://scale.com/docs/api-reference/file-endpoints#file-import
.. code-block:: python
my_file = client.import_file(
file_url="http://i.imgur.com/v4cBreD.jpg",
project_name = "test_project",
)
After the files are successfully uploaded to Scale's storage, you can access the URL as my_file.attachment_url, which will have a prefix like scaledata://.
The attribute can be passed to the task payloads, in the attachment parameter.
.. code-block:: python
task_payload = dict( ... ... attachment_type = "image", attachment = my_file.attachment_url, # scaledata://606e2a30949/89a90-c143-4154-9a9b-6c36d1f ... ... )
Manage Teammates
Manage the members of your Scale team via API. Check out Scale Team API Documentation__ for more information.
__ https://scale.com/docs/team-getting-started
List Teammates ^^^^^^^^^^^^^^
Lists all teammates in your Scale team. Returns all teammates in a List of Teammate objects.
.. code-block:: python
teammates = client.list_teammates()
Invite Teammate ^^^^^^^^^^^^^^^
Invites a list of email strings to your team with the provided role. The available teammate roles are: 'labeler', 'member', or 'manager'. Returns all teammates in a List of Teammate objects.
.. code-block:: python
from scaleapi import TeammateRole
teammates = client.invite_teammates(['[email protected]', '[email protected]'], TeammateRole.Member)
Update Teammate Role ^^^^^^^^^^^^^^^^^^^^^
Updates a list of emails of your Scale team members with the new role. The available teammate roles are: 'labeler', 'member', or 'manager'. Returns all teammates in a List of Teammate objects.
.. code-block python
from scaleapi import TeammateRole
teammates = client.update_teammates_role(['[email protected]', '[email protected]'], TeammateRole.Manager)
Example Scripts
A list of examples scripts for use.
-
cancel_batch.py__ to concurrently cancel tasks in batches
__ https://github.com/scaleapi/scaleapi-python-client/blob/master/examples/cancel_batch.py
Evaluation tasks (For Scale Rapid projects only)
Evaluation tasks are tasks that we know the answer to and are used to measure workers' performance internally to ensure the quality
Create Evaluation Task ^^^^^^^^^^^^^^^^^^^^^^
Create an evaluation task.
.. code-block:: python
client.create_evaluation_task(TaskType, ...task parameters...)
Passing in the applicable values into the function definition. The applicable fields are the same as for create_task. Applicable fields for each task type can be found in Scale's API documentation__. Additionally an expected_response is required. An optional initial_response can be provided if it's for a review phase evaluation task.
__ https://scale.com/docs/api-reference
.. code-block:: python
from scaleapi.tasks import TaskType
expected_response = {
"annotations": {
"answer_reasonable": {
"type": "category",
"field_id": "answer_reasonable",
"response": [
[
"no"
]
]
}
}
}
initial_response = {
"annotations": {
"answer_reasonable": {
"type": "category",
"field_id": "answer_reasonable",
"response": [
[
"yes"
]
]
}
}
}
attachments = [
{"type": "image", "content": "https://i.imgur.com/bGjrNzl.jpeg"}
]
payload = dict(
project = "test_project",
attachments,
initial_response=initial_response,
expected_response=expected_response,
)
client.create_evaluation_task(TaskType.TextCollection, **payload)
Training tasks (For Scale Rapid projects only)
Training tasks are used to onboard taskers onto your project
Create Training Task ^^^^^^^^^^^^^^^^^^^^^^
Create a training task.
.. code-block:: python
client.create_training_task(TaskType, ...task parameters...)
Studio Assignments (For Scale Studio only)
Manage project assignments for your labelers.
List All Assignments ^^^^^^^^^^^^^^^^^^^^
Lists all your Scale team members and the projects they are assigned to. Returns a dictionary of all teammate assignments with keys as 'emails' of each teammate, and values as a list of project names the teammate are assigned to.
.. code-block:: python
assignments = client.list_studio_assignments()
my_assignment = assignments.get('[email protected]')
Add Studio Assignment ^^^^^^^^^^^^^^^^^^^^^
Assigns provided projects to specified teammate emails.
Accepts a list of emails and a list of projects.
Returns a dictionary of all teammate assignments with keys as 'emails' of each teammate, and values as a list of project names the teammate are assigned to.
.. code-block:: python
assignments = client.add_studio_assignments(['[email protected]', '[email protected]'], ['project 1', 'project 2'])
Remove Studio Assignment ^^^^^^^^^^^^^^^^^^^^^^^^
Removes provided projects from specified teammate emails.
Accepts a list of emails and a list of projects.
Returns a dictionary of all teammate assignments with keys as 'emails' of each teammate, and values as a list of project names the teammate are assigned to.
.. code-block:: python
assignments = client.remove_studio_assignments(['[email protected]', '[email protected]'], ['project 1', 'project 2'])
Studio Project Groups (For Scale Studio Only)
Manage groups of labelers in our project by using Studio Project Groups.
List Studio Project Groups ^^^^^^^^^^^^^^^^^^^^^^^^^^^
Returns all labeler groups for the specified project.
.. code-block:: python
list_project_group = client.list_project_groups('project_name')
Add Studio Project Group ^^^^^^^^^^^^^^^^^^^^^^^^
Creates a project group with the provided group_name for the specified project and adds the provided teammate emails to the new project group. The team members must be assigned to the specified project in order to be added to the new group.
Returns the created StudioProjectGroup object.
.. code-block:: python
added_project_group = client.create_project_group(
'project_name', ['[email protected]'], 'project_group_name'
)
Update Studio Project Group ^^^^^^^^^^^^^^^^^^^^^^^^^^^
Assign or remove teammates from a project group.
Returns the updated StudioProjectGroup object.
.. code-block:: python
updated_project_group = client.update_project_group(
'project_name', 'project_group_name', ['emails_to_add'], ['emails_to_remove']
)
Studio Batches (For Scale Studio Only)
Get information about your pending Studio batches.
List Studio Batches ^^^^^^^^^^^^^^^^^^^
Returns a list of StudioBatch objects for all pending Studio batches.
.. code-block:: python
studio_batches = client.list_studio_batches()
Assign Studio Batches ^^^^^^^^^^^^^^^^^^^^^^
Sets labeler group assignment for the specified batch.
Returns a StudioBatch object for the specified batch.
.. code-block:: python
assigned_studio_batch = client.assign_studio_batches('batch_name', ['project_group_name'])
Set Studio Batches Priority ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Sets the order to prioritize your pending Studio batches. You must include all pending studio batches in the List.
Returns a List of StudioBatch objects in the new order.
.. code-block:: python
studio_batch_priority = client.set_studio_batches_priorities(
['pending_batch_1', 'pending_batch_2', 'pending_batch_3']
)
Reset Studio Batches Priority ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Resets the order of your Studio batches to the default order, which prioritizes older batches first.
Returns a List of StudioBatch objects in the new order.
.. code-block:: python
reset_studio_batch_prioprity = client.reset_studio_batches_priorities()
Error handling
If something went wrong while making API calls, then exceptions will be raised automatically
as a ScaleException parent type and child exceptions:
-
ScaleInvalidRequest: 400 - Bad Request -- The request was unacceptable, often due to missing a required parameter. -
ScaleUnauthorized: 401 - Unauthorized -- No valid API key provided. -
ScaleNotEnabled: 402 - Not enabled -- Please contact [email protected] before creating this type of task. -
ScaleResourceNotFound: 404 - Not Found -- The requested resource doesn't exist. -
ScaleDuplicateResource: 409 - Conflict -- Object already exists with same name, idempotency key or unique_id. -
ScaleTooManyRequests: 429 - Too Many Requests -- Too many requests hit the API too quickly. -
ScaleInternalError: 500 - Internal Server Error -- We had a problem with our server. Try again later. -
ScaleServiceUnavailable: 503 - Server Timeout From Request Queueing -- Try again later. -
ScaleTimeoutError: 504 - Server Timeout Error -- Try again later.
Check out Scale's API documentation <https://scale.com/docs/api-reference/errors>_ for more details.
For example:
.. code-block:: python
from scaleapi.exceptions import ScaleException
try:
client.create_task(TaskType.TextCollection, attachment="Some parameters are missing.")
except ScaleException as err:
print(err.code) # 400
print(err.message) # Parameter is invalid, reason: "attachments" is required
Troubleshooting
If you notice any problems, please contact our support via Intercom by logging into your dashboard, or, if you are Enterprise, by contacting your Engagement Manager.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for scaleapi-python-client
Similar Open Source Tools
scaleapi-python-client
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

CEO-Agentic-AI-Framework
CEO-Agentic-AI-Framework is an ultra-lightweight Agentic AI framework based on the ReAct paradigm. It supports mainstream LLMs and is stronger than Swarm. The framework allows users to build their own agents, assign tasks, and interact with them through a set of predefined abilities. Users can customize agent personalities, grant and deprive abilities, and assign queries for specific tasks. CEO also supports multi-agent collaboration scenarios, where different agents with distinct capabilities can work together to achieve complex tasks. The framework provides a quick start guide, examples, and detailed documentation for seamless integration into research projects.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.
gfm-rag
The GFM-RAG is a graph foundation model-powered pipeline that combines graph neural networks to reason over knowledge graphs and retrieve relevant documents for question answering. It features a knowledge graph index, efficiency in multi-hop reasoning, generalizability to unseen datasets, transferability for fine-tuning, compatibility with agent-based frameworks, and interpretability of reasoning paths. The tool can be used for conducting retrieval and question answering tasks using pre-trained models or fine-tuning on custom datasets.
redis-vl-python
The Python Redis Vector Library (RedisVL) is a tailor-made client for AI applications leveraging Redis. It enhances applications with Redis' speed, flexibility, and reliability, incorporating capabilities like vector-based semantic search, full-text search, and geo-spatial search. The library bridges the gap between the emerging AI-native developer ecosystem and the capabilities of Redis by providing a lightweight, elegant, and intuitive interface. It abstracts the features of Redis into a grammar that is more aligned to the needs of today's AI/ML Engineers or Data Scientists.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
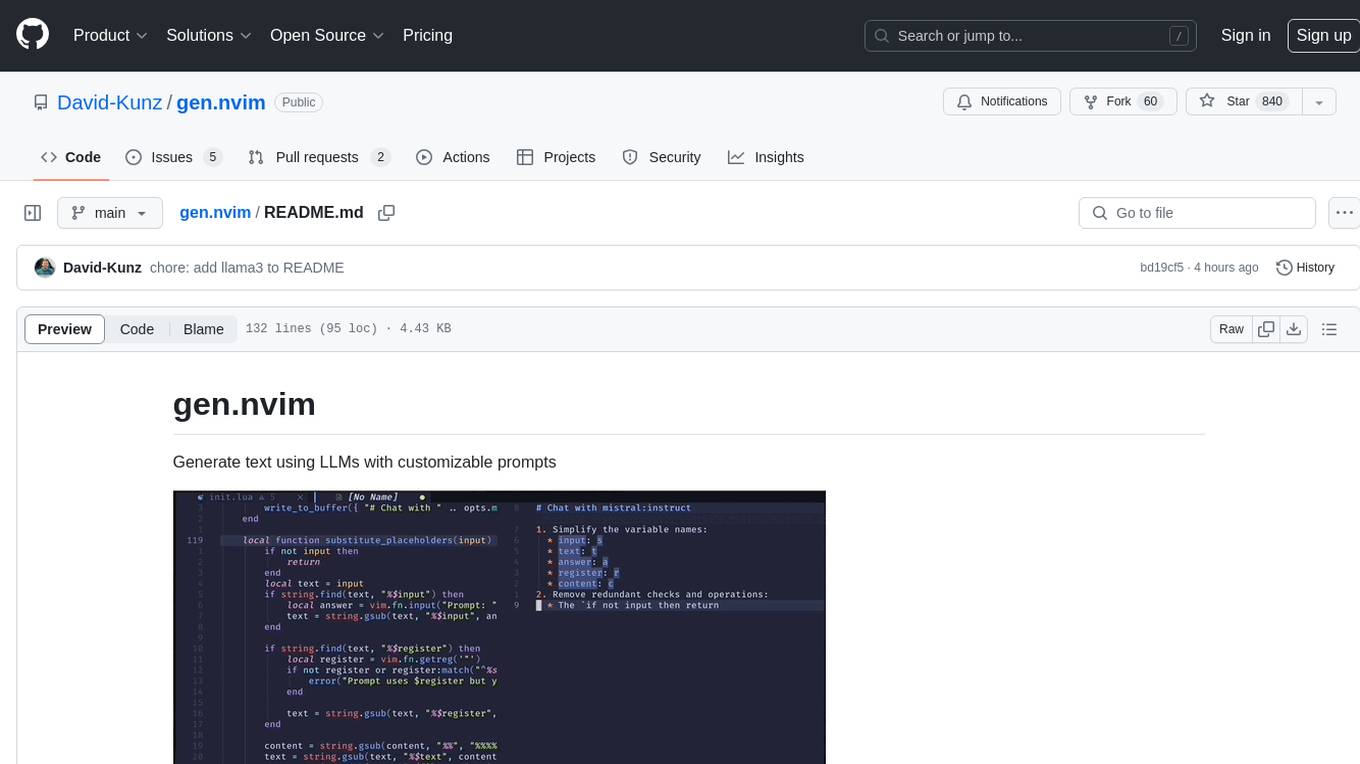
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.
redisvl
Redis Vector Library (RedisVL) is a Python client library for building AI applications on top of Redis. It provides a high-level interface for managing vector indexes, performing vector search, and integrating with popular embedding models and providers. RedisVL is designed to make it easy for developers to build and deploy AI applications that leverage the speed, flexibility, and reliability of Redis.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
pg_vectorize
pg_vectorize is a Postgres extension that automates text to embeddings transformation, enabling vector search and LLM applications with minimal function calls. It integrates with popular LLMs, provides workflows for vector search and RAG, and automates Postgres triggers for updating embeddings. The tool is part of the VectorDB Stack on Tembo Cloud, offering high-level APIs for easy initialization and search.
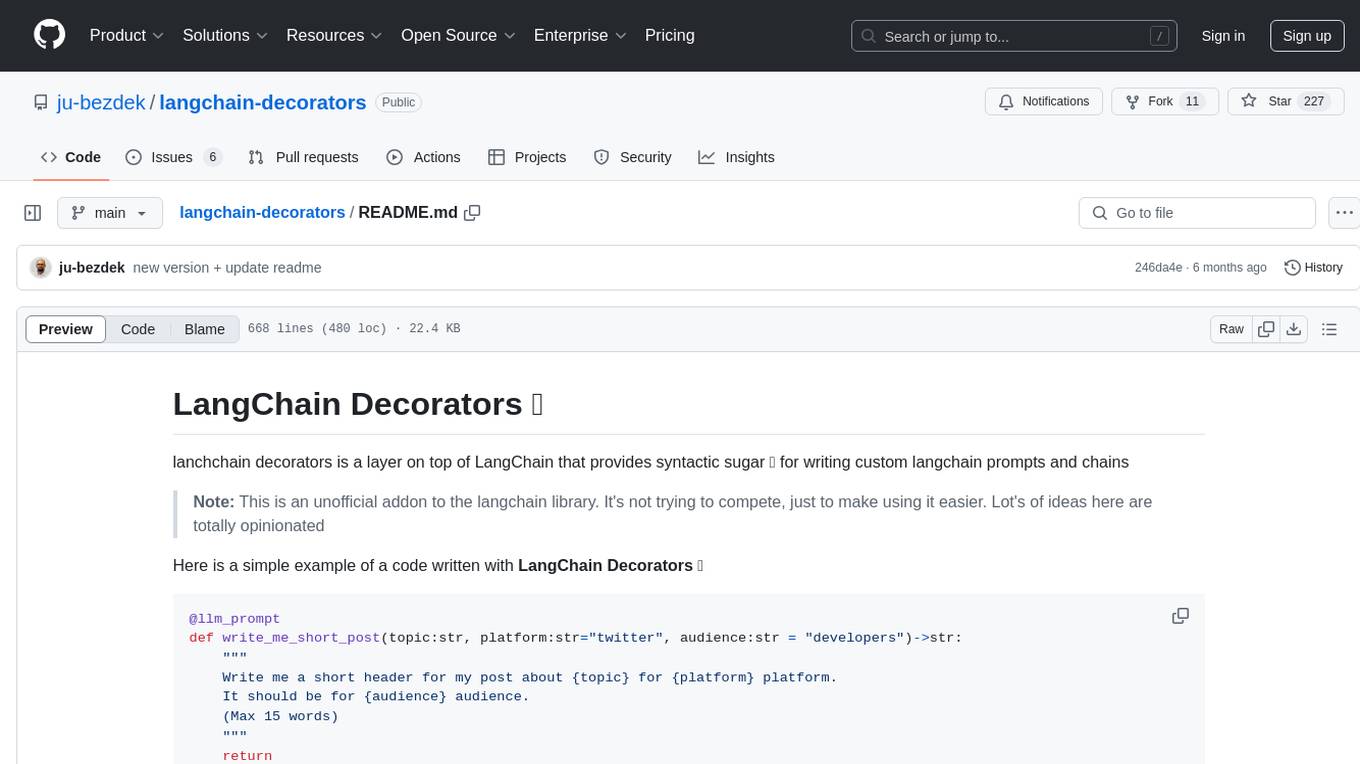
langchain-decorators
LangChain Decorators is a layer on top of LangChain that provides syntactic sugar for writing custom langchain prompts and chains. It offers a more pythonic way of writing code, multiline prompts without breaking code flow, IDE support for hinting and type checking, leveraging LangChain ecosystem, support for optional parameters, and sharing parameters between prompts. It simplifies streaming, automatic LLM selection, defining custom settings, debugging, and passing memory, callback, stop, etc. It also provides functions provider, dynamic function schemas, binding prompts to objects, defining custom settings, and debugging options. The project aims to enhance the LangChain library by making it easier to use and more efficient for writing custom prompts and chains.
For similar tasks
scaleapi-python-client
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.
atlas-mcp-server
ATLAS (Adaptive Task & Logic Automation System) is a high-performance Model Context Protocol server designed for LLMs to manage complex task hierarchies. Built with TypeScript, it features ACID-compliant storage, efficient task tracking, and intelligent template management. ATLAS provides LLM Agents task management through a clean, flexible tool interface. The server implements the Model Context Protocol (MCP) for standardized communication between LLMs and external systems, offering hierarchical task organization, task state management, smart templates, enterprise features, and performance optimization.
Backlog.md
Backlog.md is a Markdown-native Task Manager & Kanban visualizer for any Git repository. It turns any folder with a Git repo into a self-contained project board powered by plain Markdown files and a zero-config CLI. Features include managing tasks as plain .md files, private & offline usage, instant terminal Kanban visualization, board export, modern web interface, AI-ready CLI, rich query commands, cross-platform support, and MIT-licensed open-source. Users can create tasks, view board, assign tasks to AI, manage documentation, make decisions, and configure settings easily.
For similar jobs
Thor
Thor is a powerful AI model management tool designed for unified management and usage of various AI models. It offers features such as user, channel, and token management, data statistics preview, log viewing, system settings, external chat link integration, and Alipay account balance purchase. Thor supports multiple AI models including OpenAI, Kimi, Starfire, Claudia, Zhilu AI, Ollama, Tongyi Qianwen, AzureOpenAI, and Tencent Hybrid models. It also supports various databases like SqlServer, PostgreSql, Sqlite, and MySql, allowing users to choose the appropriate database based on their needs.
redbox
Redbox is a retrieval augmented generation (RAG) app that uses GenAI to chat with and summarise civil service documents. It increases organisational memory by indexing documents and can summarise reports read months ago, supplement them with current work, and produce a first draft that lets civil servants focus on what they do best. The project uses a microservice architecture with each microservice running in its own container defined by a Dockerfile. Dependencies are managed using Python Poetry. Contributions are welcome, and the project is licensed under the MIT License. Security measures are in place to ensure user data privacy and considerations are being made to make the core-api secure.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.
MLE-agent
MLE-Agent is an intelligent companion designed for machine learning engineers and researchers. It features autonomous baseline creation, integration with Arxiv and Papers with Code, smart debugging, file system organization, comprehensive tools integration, and an interactive CLI chat interface for seamless AI engineering and research workflows.

LynxHub
LynxHub is a platform that allows users to seamlessly install, configure, launch, and manage all their AI interfaces from a single, intuitive dashboard. It offers features like AI interface management, arguments manager, custom run commands, pre-launch actions, extension management, in-app tools like terminal and web browser, AI information dashboard, Discord integration, and additional features like theme options and favorite interface pinning. The platform supports modular design for custom AI modules and upcoming extensions system for complete customization. LynxHub aims to streamline AI workflow and enhance user experience with a user-friendly interface and comprehensive functionalities.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
VoAPI
VoAPI is a new high-value/high-performance AI model interface management and distribution system. It is a closed-source tool for personal learning use only, not for commercial purposes. Users must comply with upstream AI model service providers and legal regulations. The system offers a visually appealing interface with features such as independent development documentation page support, service monitoring page configuration support, and third-party login support. Users can manage user registration time, optimize interface elements, and support features like online recharge, model pricing display, and sensitive word filtering. VoAPI also provides support for various AI models and platforms, with the ability to configure homepage templates, model information, and manufacturer information.